Oracle Cloud Infrastructure has expanded cluster networking by enabling remote direct memory access (RDMA)-connected clusters of up to 20,000 cores on our BM.HPC2.36 instance type. Our groundbreaking, backend network fabric lets you use Mellanox’s ConnectX-5, 100-Gbps network interface cards with RDMA over Converged Ethernet (RoCE) v2 to create clusters with the same low-latency networking and application scalability that you expect on premises.
Oracle Cloud Infrastructure is leading the cloud high performance computing (HPC) battle in performance and price. Over the last few months, we have set new cloud standards for internode latency, cloud HPC benchmarks, and application performance. Oracle Cloud Infrastructure’s bare metal infrastructure lets you run on-premises performance in the cloud.
In addition to connecting bare metal nodes together through RDMA, cluster networking provides a fabric that will enable future instances and products to communicate at extremely low latencies.
Performance
Ultra-low node-to-node latency is expected on HPC systems. Partners like Exabyte.io have demonstrated Oracle Cloud Infrastructure’s leading edge with those metrics. But when you have applications running on thousands of cores, low node-to-node latency isn’t enough. The ability to scale models down to a very small size is more important. In computational fluid dynamics (CFD), users typically want to know the smallest amount of work they can do on a node before they hit a network bottleneck that limits the scalability of their cluster. This is the network efficiency of an HPC cluster or, in other words, getting the most “bang for your buck”!
The following chart shows the performance of Oracle’s cluster networking fabric. We scale above 100% below 10,000 simulation cells per core with popular CFD codes, the same performance that you would see on premises. It’s also important to note that without the penalty of virtualization, bare metal HPC machines can use all the cores on the node without having to reserve any cores for costly overhead.
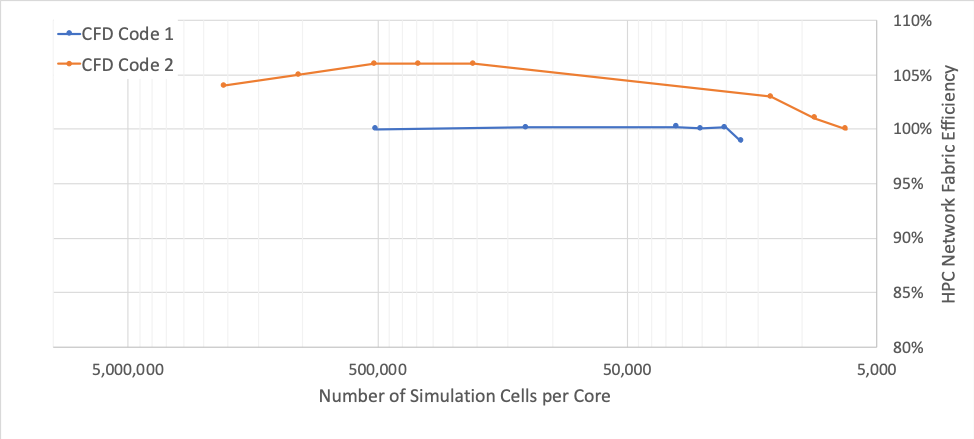
The ability for a simulation model to scale this way highlights two important design features. The first is the stability of the underlying network fabric, which can transfer data fast and consistently. The second important design feature is that there is no additional traffic or overhead on the network to limit throughput or latency. You can see this stability in the following chart, which compares on-premises HPC network efficiency to cloud HPC network efficiency.
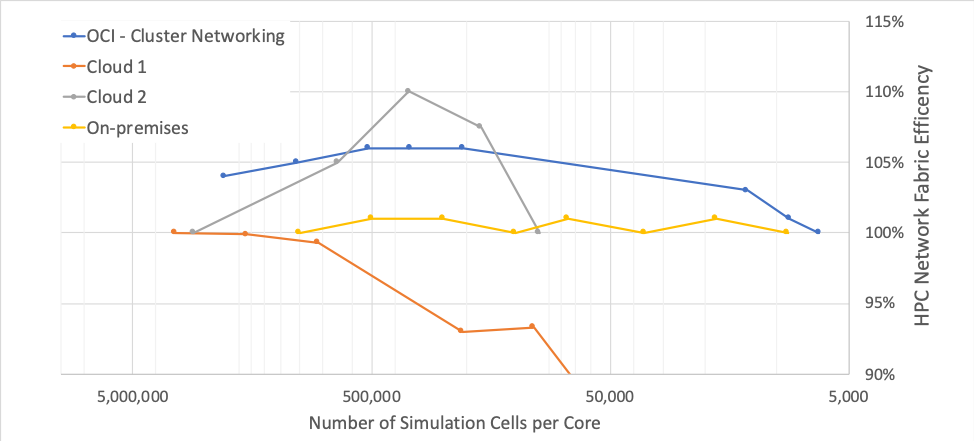
CFD is not the only type of simulation to benefit from using Oracle’s cluster networking. Crash simulations, like those run on Altair’s RADIOSS or LS-Dyna from LSTC, and financial matching simulations, like those offered by BJSS, also use cluster networking.
Price
Oracle Cloud Infrastructure offers the best performance by default. You don’t pay extra for performance of block storage, RDMA capability, or network bandwidth, and the first 10 TB of egress is free. Cluster networking follows that same paradigm—there is no additional charge for it.
Availability
Today, cluster networking is available in the regions that have our HPC instances: Ashburn, London, Frankfurt, and Tokyo. Cluster networking will continue to spread throughout all of our regions as cluster networking-enabled instances continue to roll out.
To deploy your HPC cluster using cluster networking, reach out to your Oracle rep or contact us directly.
Also, visit us at the ISC High Performance conference in Frankfurt June 16–20. We’re in booth H-730. Hope to see you there.
