Today, 95 percent of all traditional high-performance computing (HPC) is still done in traditional on-premises deployments. The sporadic demand cycles and rapid evolution of specialized HPC technologies make flexible cloud deployment a great fit for enterprise usage. But other cloud providers simply haven’t been able to penetrate this market for a range of reasons, from performance to cost to a lack of key features, such as remote direct memory access (RDMA) capability. Over the last 12 months, we have invested significantly, in both technology and partnerships, to make Oracle Cloud Infrastructure the best place to run your Big Compute and HPC workloads.
At OpenWorld 2018, Larry announced clustered networking, which lets customers run their Message-Passing Interface (MPI) workloads with performance comparable to, and in some cases better than, on-premises HPC clusters. This was the first, and is still the only, bare metal HPC offering with 100G RDMA in a public cloud.* It’s in limited availability today, and we expect it to be generally available later in the year. Even further out, we’re working on a truly flexible and scalable architecture in which you can have bare metal GPUs, HPC instances, and even Exadata on a clustered network. This opens up use cases such as running a distributed training job on a cluster of GPUs that pull data from an Exadata, and then deploying the model on a set of compute nodes, all over the clustered network.
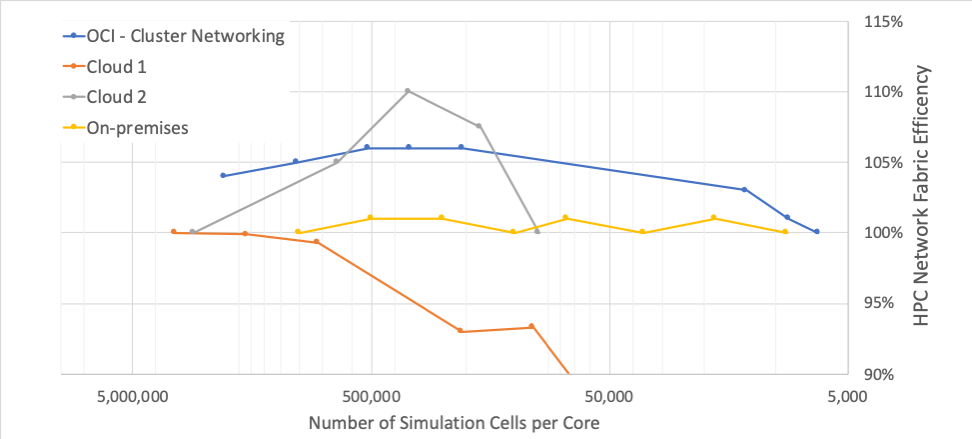
We pushed the boundaries on this new offering with the ability to scale to up to 20,000 cores for a single job. This is far beyond what any other cloud can offer today for MPI workloads while maintaining efficiency and performance. To see the benchmarks that compare us and other providers, see the blog post that we published this week. Here’s a peek:
We also partnered with Altair last year at OpenWorld to launch their Hyperworks CFD unlimited running our bare metal NVIDIA GPU offerings. We recently started working with them on their crash application, called Altair Radioss, and how clustered networking can help reduce the time and cost for these crash simulation jobs. For details, including benchmarks, read the blog post.
This week we’re in Frankfurt at ISC 2019, along with our partners, showcasing some of these capabilities. You can talk to our engineering teams and try out some of the technologies at our booth, located at H-730.
Some other things you’ll want to catch during the week:
- Vendor Showdown on Monday, June17, at Panorama 2, starting at 1:15 p.m.
- Exhibitor Forum Session on Tuesday, June 18, at Booth N-210, starting at 11:20 a.m.
- Blog: Accelerating DEM Simulations with Rocky on Oracle Cloud and NVIDIA
- Blog: Making Cars Safer with Oracle Cloud and Altair Radioss
- Blog: Large Clusters, Lowest Latency: Clustered Networking on Oracle Cloud Infrastructure
- Hands-on demos and labs at our booth H-730
Looking forward to seeing you there!
Karan
* Based on comparison to AWS, Azure, and Google Cloud Platform as of June 3, 2019.
