Running Nextflow on a static cluster can be a good choice for predictable performance and reproducible results. The downside is cost: clusters inevitably sit idle between stages and between pipeline runs, especially for bursty HPC‑style workloads. Moving Nextflow pipelines to the cloud can reduce that idle cost, but it introduces a new set of operational problems: dynamic resource scheduling across stages, capacity/spot interruptions, and the ongoing work of tuning instance types and storage for each workload.
This blog shows how OCI Compute and OCI Object Storage, paired with an Infrastructure as Code (IaC) execution model, address these challenges. In our apples‑to‑apples PoC (same pipeline, comparable CPU/memory shapes), OCI delivered up to 70% lower batch compute cost than another cloud’s dynamic batch service—while keeping end‑to‑end runtime comparable and avoiding the burst‑time queueing and spot/preemptible uncertainty that can affect completion time.
In this post we:
- Show how OCI Compute and OCI Object Storage, paired with an Infrastructure as Code (IaC) executor for Nextflow, turn pipelines into a dynamic, per‑task execution model that closely matches resource demand.
- Use real pipeline metrics (CPU and memory histograms, time‑series usage, and two‑run comparisons) to illustrate how OCI handles highly variable shapes without stretching overall runtime.
- Explain how OCI’s transparent, pay‑as‑you‑go pricing model lets you capture these savings while keeping behavior deterministic and reproducible across runs.
- Finally, we use OCI Data Science tools to visualize resource usage over time, validating the highly dynamic behavior of a real, production-grade Nextflow pipeline and identifying optimization opportunities to further improve resource utilization.
Dynamic Nextflow Pipelines and OCI Infrastructure
Nextflow is a workflow engine widely used in genomics, bioinformatics, and data‑intensive AI. A single pipeline often contains dozens of stages with very different profiles:
- CPU‑heavy alignment, QC, or ETL steps.
- Memory‑intensive joins or aggregations.
- Occasional GPU‑accelerated tasks for deep learning or accelerated analytics.
Each stage can require different CPU, memory, and disk combinations, and those requirements change over time as the pipeline advances. On a traditional static cluster or a fixed pool of instances, you typically:
- Over‑provision nodes to handle the heaviest steps.
- Pay for idle capacity between bursts of activity.
- Spend time manually resizing or cleaning up VMs to keep costs in check.
Dynamic batch services can help improve resource utilization by scaling capacity up and down with demand. However, in bursty periods they can introduce queueing and capacity risks (for example, waiting for capacity or dealing with spot/preemptible interruptions), which makes end‑to‑end pipeline completion time less predictable.
OCI is a good fit for this pattern because it combines:
- High‑performance compute shapes (CPU and GPU) and flexible memory configurations.
- Durable, low‑cost OCI Object Storage for large intermediate datasets.
- Transparent, pay‑as‑you‑go pricing and consistent performance across regions and shapes.
Next, we will explore an architecture that makes use of these OCI advantages to run Nextflow pipelines efficiently at scale.
Technical Architecture on OCI
Architecturally, we combine OCI Compute and OCI Object Storage with an Infrastructure as Code executor for Nextflow (for example, the nf-iac executor) to glue the pieces together:
- We use infrastructure as code provisioning to create ephemeral OCI compute instances per task.
- OCI Object Storage and its S3‑compatible API endpoint provide a durable, low‑cost data backend.
- The IaC executor orchestrates provisioning and teardown so capacity closely follows task demand.
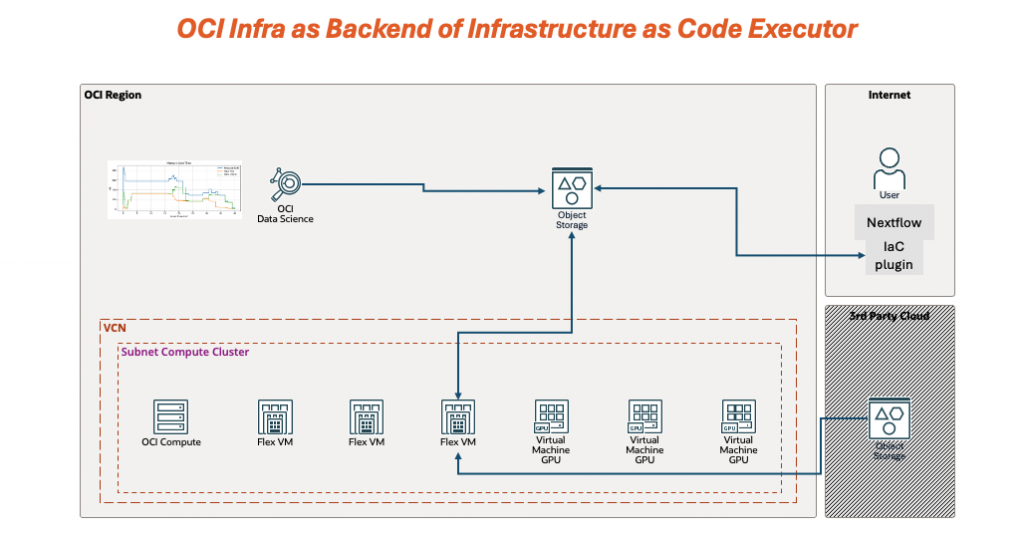
Figure 1 – Nextflow uses an IaC executor to provision per‑task OCI Compute instances, read/write data from OCI Object Storage, and tear down resources automatically when each task completes.
OCI configuration
A minimal example focusing on the OCI pieces (adapted from the sample config in the nf-iac repository):
iac {
// Public SSH key used to access provisioned nodes (optional but recommended)
sshAuthorizedKey = ‘<YOUR_SSH_PUBLIC_KEY>’
oci {
profile = ‘DEFAULT’ // profile in ~/.oci/config
compartment = ‘ocid1.compartment.oc1..aaaa…’ // target OCI compartment OCID
subnet = ‘ocid1.subnet.oc1..bbbb…’ // subnet OCID for instances
image = ‘ocid1.image.oc1..cccc…’ // base image OCID
defaultShape = ‘1 VM.Standard.E4.Flex’ // “<count> <shape>” format
defaultDisk = ‘1024 GB’ // boot volume size
}
}
OCI is designed with first-class support for Infrastructure as Code, enabling customers to implement fully customized execution models—such as their own Nextflow executors or plugins—using Terraform or similar IaC tools.
Results
In our PoC testing on production‑like Nextflow workloads, this architecture delivered up to 70% lower batch compute cost compared to equivalent runs on other cloud vendors, including their dynamic batch offerings, while maintaining similar end‑to‑end runtime and simplifying operations via infrastructure as code.
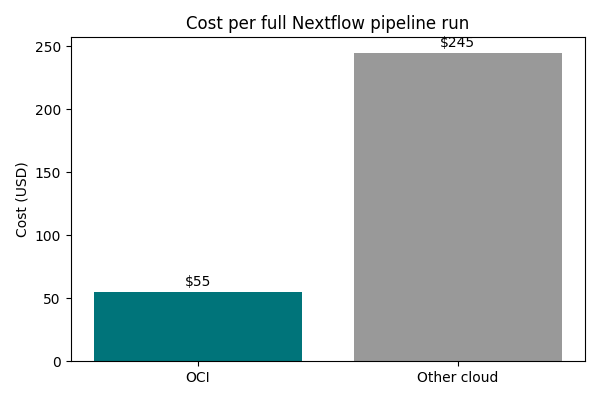
Figure 2 – Cost per full Nextflow pipeline run, comparing an apples‑to‑apples configuration: the same pipeline, using comparable CPU and memory shapes, on another cloud’s dynamic batch service versus on OCI with per‑task IaC‑based provisioning.
For this PoC, the pipeline ran for about 1 day 16 hours, costing $55 on OCI versus $245 on the other cloud’s dynamic batch service. Figure 2 summarizes the same result.
Next, we examine the resource and runtime behavior of the pipeline on OCI and explain what the plots reveal about its time‑varying demand.
OCI Compute Runtime Analysis
This section we use OCI data science tools notebook to analyze the result metric, which has three parts:
- Shape variety (Figures 3–4): what sizes the pipeline asks for.
- Resource over time (Figures 5–6): when the pipeline needs those resources and how that impacts completion time.
- Two‑run consistency (Figure 7): why consistent infrastructure and transparent pricing help keep timelines predictable.
1) Shapes variety: Nextflow resource demand is diverse
Figures 3 and 4 confirm what we stated earlier: within a single Nextflow run, tasks can request very different CPU and memory sizes. This is the nature of Nextflow pipelines, not an OCI‑specific feature.
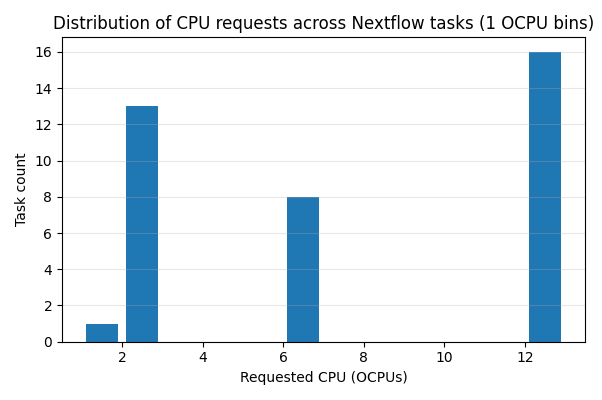
Figure 3 – CPU shape variety across tasks. The pipeline mixes small 1–2 OCPU stages with larger 12 OCPU stages.
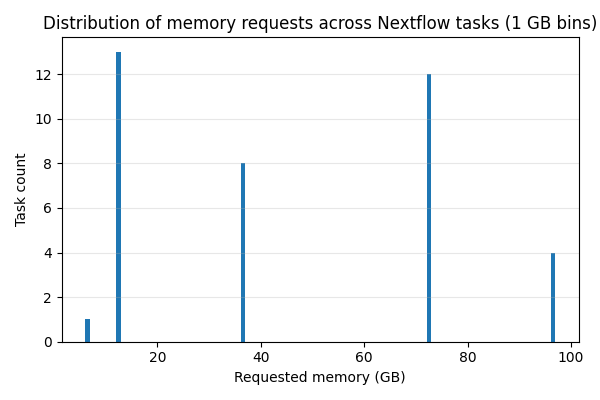
Figure 4 – Memory shape variety across tasks. Tasks range from compact 6–12 GB requests up to 72–96 GB.
This diversity is exactly why static, fixed‑shape environments are a poor fit for many pipelines: if you size for the biggest stage you pay for idle capacity during smaller stages; if you size for the median stage the heavy stages wait longer or run slower.
2) Resource over time: capacity availability affects pipeline completion time
Figures 5 and 6 show the same story in the time dimension. Even if you can improve utilization with dynamic batch scheduling, the pipeline still depends on the infrastructure layer to supply the right capacity at the right time.
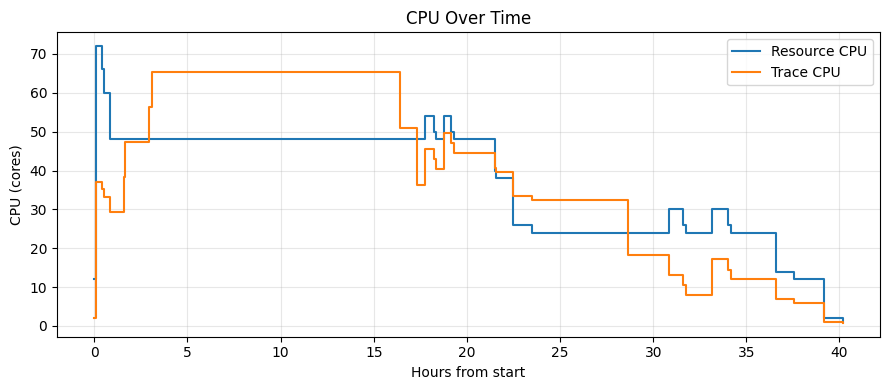
Figure 5 – CPU demand over time. Peaks occur when CPU‑heavy stages run; demand drops as stages complete.
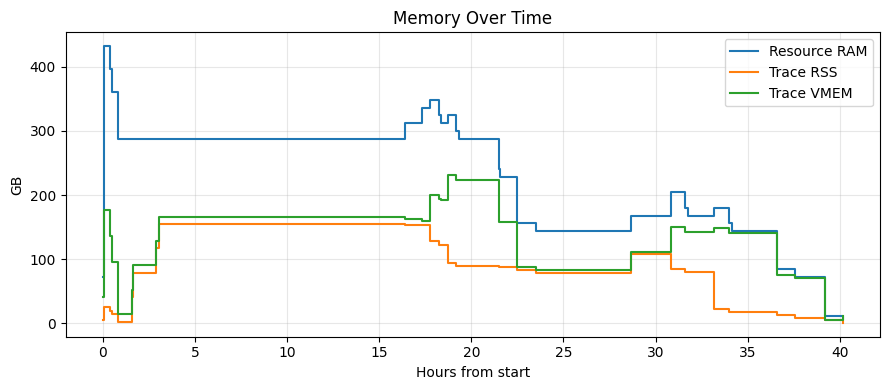
Figure 6 – Memory demand over time. Memory peaks are stage‑dependent and do not align perfectly with CPU peaks.
When the infrastructure layer cannot allocate capacity quickly (for example due to queueing, burst capacity shortages, or spot/preemptible reclaim), task start latency increases and end‑to‑end pipeline completion time becomes uncertain—especially in burst scenarios.
OCI’s transparent, pay‑as‑you‑go pricing helps here: you can scale to larger shapes for heavy stages without committing to reserved capacity, and cost remains straightforward to reason about because pricing is metered based on the resources you consume (such as OCPU and memory).
3) Two‑run consistency: predictable timelines and repeatable cost
Finally, Figure 7 compares two full runs of the same pipeline on OCI.
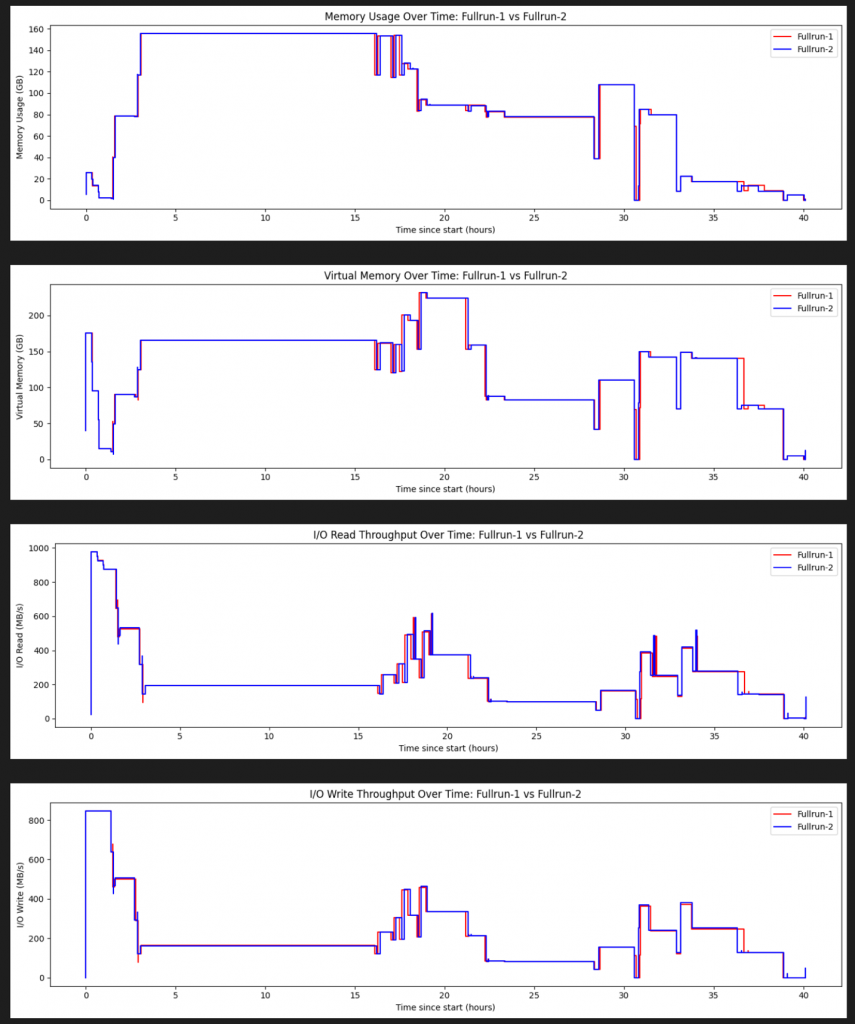
Figure 7 – Two independent runs of the same pipeline on OCI. The resource footprint is highly similar across runs, reflecting consistent infrastructure behavior.
In some dynamic batch systems, capacity availability and pricing mechanics can cause run‑to‑run variance in both start latency and total completion time. OCI’s consistent infrastructure performance and predictable pricing help keep Nextflow behavior more deterministic: with the same pipeline, inputs, and comparable shapes, you can expect similar resource footprints, similar timelines, and predictable cost.
Conclusion and Takeaways
This PoC shows that OCI is a strong fit for running Nextflow pipelines with dynamic, HPC‑style resource demand. With an IaC‑based execution model, you can match compute shapes to each task, keep data in OCI Object Storage, and turn pipeline execution into a transparent, auditable workflow rather than a black‑box batch system.
Key takeaways
- Apples‑to‑apples cost advantage: On the same pipeline with comparable CPU/memory shapes, OCI reduced batch compute cost by up to 70% versus another cloud’s dynamic batch service (Figure 2).
- Dynamic demand is the norm: A single run mixes many CPU/memory sizes (Figures 3–4) and demand changes over time (Figures 5–6), making fixed‑shape environments a poor fit.
- Predictable timelines without reservation complexity: OCI’s transparent, pay‑as‑you‑go pricing and consistent performance help you scale up for heavy stages without pre‑reserving large capacity, and without turning burst execution into unpredictable completion time.
- Reproducible behavior: Two full runs show highly similar resource footprints (Figure 7), supporting deterministic performance and repeatable cost.
This proof of concept was completed through collaboration between the JAPAC CoE and CE teams. Special thanks to Mohan Srinivasan, Ram Sivaram, Andre Wenas and Samuel Ong for their continued support.
