Introduction
This blog highlights innovative solutions from Oracle Cloud Infrastructure (OCI) and WEKA’s NeuralMesh storage that deliver high-throughput, low-latency converged storage, purpose-built to support the performance demands of modern AI and ML workloads. Oracle and WEKA conducted a joint proof-of-concept (POC) focused on achieving optimal performance using OCI’s H100 GPU compute shapes in combination with NeuralMesh’s high-performance, scalable storage software. The POC also validated key capabilities including tiered storage with OCI Object Storage, WEKA Augmented Memory Grid™, scalable deployment architecture, fault-tolerant data management, and multi-protocol compatibility to support diverse AI/ML workload requirements.
Architecture
We used the following OCI cloud resources and storage software stack from WEKA to perform the technical validation and performance benchmark:
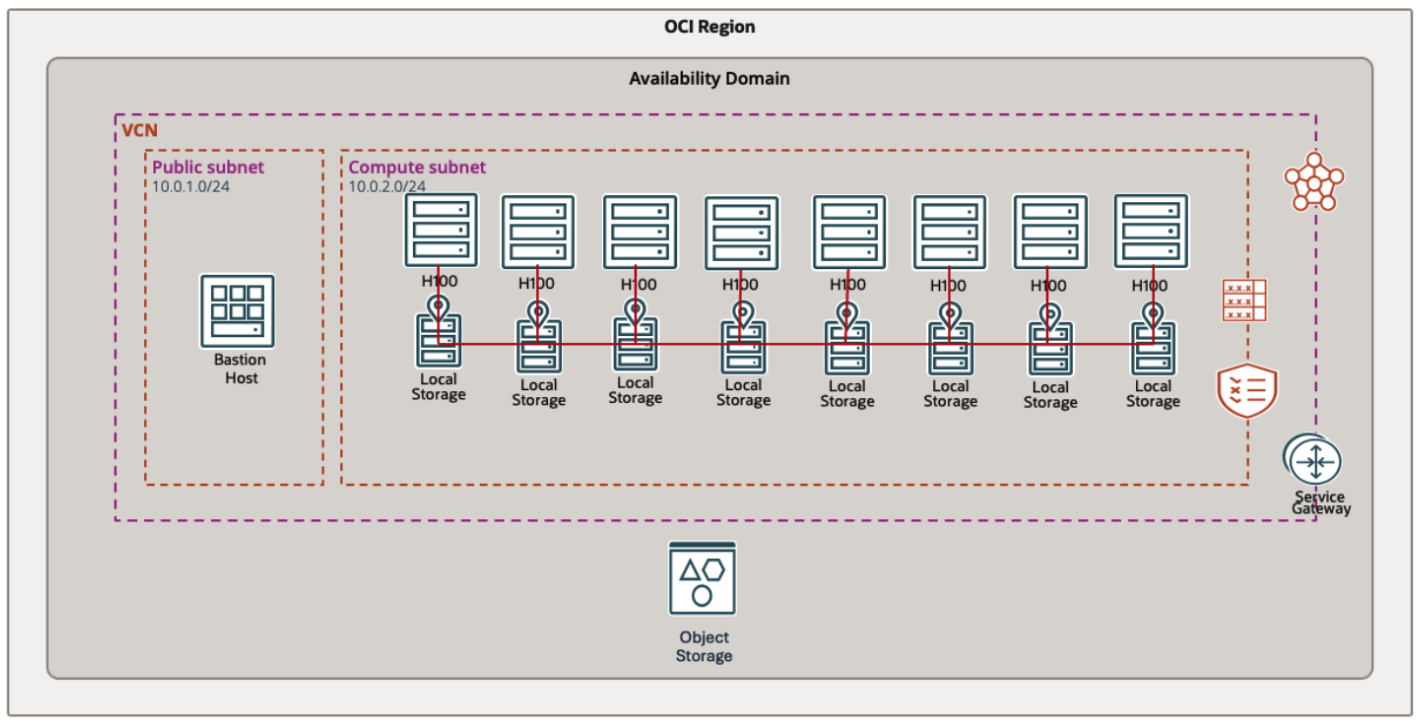
Compute Cluster: The architecture consists of eight OCI compute instances of type BM.GPU.H100.8, each equipped with eight NVIDIA H100 GPUs, forming a 64-GPU cluster. Each server node is also configured with eighteen 3.84TB NVMe SSDs, providing high-speed local storage. A SLURM stack is deployed to manage job scheduling and resource allocation across the cluster, efficiently coordinating workload distribution. The cluster leverages Remote Direct Memory Access (RDMA) to enable high-speed, low-latency communication and synchronization between nodes, ensuring rapid data transfer and optimal performance for distributed AI and HPC workloads.
Converged Storage: We deployed WEKA’s NeuralMesh Axon storage software on eight OCI BM.GPU.H100.8 instances to create a high-performance converged storage cluster. This solution a unique approach to high-performance storage. In this model, NeuralMesh Axon shares the same underlying compute, network, and storage resources with the application. The key innovation is that NeuralMesh Axon simply carves out a small portion of storage, networking, and CPUs for its use and only utilizes those resources, leaving the rest available for the application.
Workflow Integration: The architecture enables seamless interaction between GPU compute, NeuralMesh Axon storage, and OCI Object Storage. As LLM models are fine-tuned, checkpoints are generated and stored in tiered NeuralMesh, which combines local NVMe drives from OCI GPU nodes with OCI Object Storage. These checkpoints capture the model’s state at various stages, allowing the training process to be paused and resumed without data loss. This workflow demonstrates the scalability, performance, and reliability of the storage architecture for enterprise-level AI workloads.
Augmented Memory Grid™: WEKA’s Augmented Memory Grid™ is a breakthrough solution that extends GPU memory with a high-speed token warehouse. This innovation enables persistent storage and microsecond retrieval of tokens at exabyte scale. The Augmented Memory Grid leverages GPU Direct Storage, RDMA, and NVMe optimization to deliver microsecond latencies and massive parallel throughput, fundamentally redefining how AI systems manage and access tokenized data.
The following architecture diagram provides a comprehensive overview of this system, illustrating the integration of compute, storage, and orchestration layers.
Technical Validation and Performance Benchmark
The POC was conducted using eight OCI BM.GPU.H100.8 compute nodes deployed with WEKA’s NeuralMesh Axon storage software, validating key storage features and functionalities, including:
- Tiered storage integration with OCI Object Storage
- Augmented Memory Grid™ performance for accelerated I/O
- Multi-protocol compatibility for diverse workload requirements
- Scalable deployment and fault-tolerant data management
We used performance benchmarking tools such as FIO and GDSIO and also executed a fine-tuning job using the Llama3.1-70B model to evaluate NeuralMesh Axon storage performance and tiered storage capabilities. During the fine-tuning process, multiple checkpoints were generated and stored in the NeuralMesh Axon system. These checkpoints were asynchronously tiered to OCI Object Storage without any manual intervention.
Additionally, LLM workloads were able to access data directly from object storage, functioning as if it were a native file system—eliminating the need for manual hydration to local NVMe. The NeuralMesh CLI provided visibility into data residency, showing whether data resided in object storage, local NVMe, or both.
Performance Results:
Performance testing was conducted using FIO, with additional information about WEKAtester available at https://github.com/WEKA/tools/tree/master/WEKAtester.
Table 1 highlights the performance results captured from NeuralMesh Axon storage using FIO tool.
| Description |
Seq Read |
Seq Write |
Read IOPS |
Write IOPS |
Read Latency |
Write Latency |
| Per Host |
33.73 GiB/s |
15.97 GiB/s |
943,331 |
231,237 |
134 μs |
122 μs |
| Aggregate |
269.80 GiB/s |
127.80 GiB/s |
7,546,655 |
1,849,900 |
134 μs |
122 μs |
Table 1: FIO results from 8-node NeuralMesh Axon cluster running on OCI H100 GPU nodes
Additionally, we tested GPU Direct Storage (GDS) performance, achieving 192 GiB/s for sequential reads and 76 GiB/s for sequential writes on a single client. These results highlight NeuralMesh Axon’s ability to efficiently handle both large sequential transfers and small random operations simultaneously, making it ideal for the mixed workload patterns common in AI training and inference. Table 2 details throughput results achieved using GPU Direct Storage.
| Description |
Sequential Read |
Sequential Write |
| GDS Single Client Throughput |
192 GiB/s |
76 GiB/s |
Table 2: GDSIO results on 1 node from 8-node NeuralMesh Axon cluster running on H100 GPU nodes in OCI
WEKA Augmented Memory Grid™ Our benchmarking on OCI H100 GPU instances compared to standard vLLM execution showed a dramatic 20x improvement in Time to First Token on a 128K context window. The following table and accompanying graph illustrate the performance gains across different context sizes:
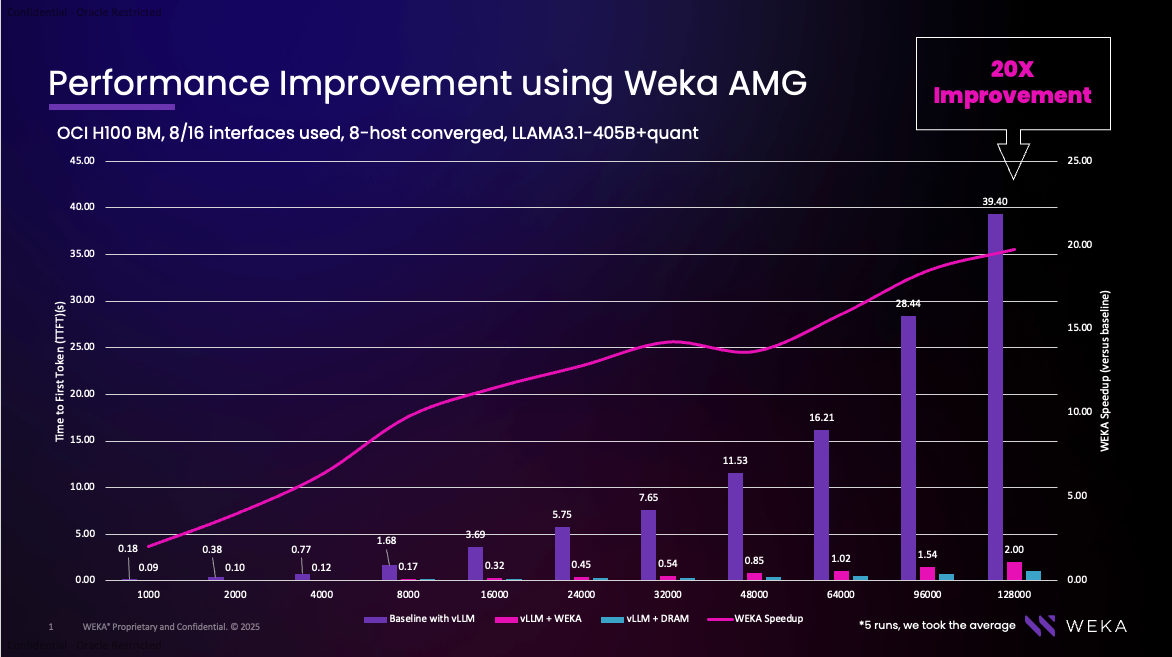
Graph 1: Time to First Token and WEKA AMG acceleration
The graph illustrates how WEKA’s Augmented Memory Grid accelerates performance as context window size increases, with the greatest gains at the largest context windows.
| Context Size |
1000 |
2000 |
4000 |
8000 |
16000 |
24000 |
3200 |
48000 |
64000 |
96000 |
128000 |
| Baseline with vLLM |
0.18 |
0.38 |
0.77 |
1.68 |
3.69 |
5.75 |
7.65 |
11.53 |
16.21 |
28.44 |
39.40 |
| vLLM + WEKA |
0.09 |
0.10 |
0.12 |
0.17 |
0.32 |
0.45 |
0.54 |
0.85 |
1.02 |
1.54 |
2.00 |
| vLLM + DRAM |
0.09 |
0.11 |
0.08 |
0.16 |
0.19 |
0.29 |
0.35 |
0.39 |
0.50 |
0.77 |
1.05 |
| WEKA Speedup |
2.02 |
3.94 |
6.31 |
9.76 |
11.48 |
12.79 |
14.20 |
13.64 |
15.86 |
18.46 |
19.72 |
Table 3: Time to First Token and WEKA AMG acceleration
This innovation eliminates inefficiencies in traditional inference pipelines by avoiding redundant token re-computation, significantly reducing latency and compute waste. By extending GPU memory to a distributed, high-performance token warehouse, the Augmented Memory Grid enables AI systems to store and retrieve tokens with unprecedented efficiency—particularly valuable for handling the mixed read/write patterns common in token-based AI workloads.
Conclusion
The joint proof of concept between Oracle Cloud Infrastructure (OCI) and WEKA demonstrates a powerful, scalable, and high-performance solution tailored for the evolving demands of AI, ML, and HPC workloads. By combining OCI’s next-generation GPU compute infrastructure with WEKA’s NeuralMesh Axon, software-defined storage platform, enterprises can achieve exceptional throughput, ultra-low latency, and seamless data tiering—all while simplifying management and reducing total cost of ownership. This collaboration not only validates the technical strengths of both platforms but also sets a strong foundation for future-ready AI infrastructure that can support everything from large language model training to real-time inference at scale.
To learn more about NeuralMesh Axon for Oracle Cloud Infrastructure, visit the WEKA website. To get started with NeuralMesh Axon for your OCI workloads, visit The WEKA on OCI marketplace listing.

