Artificial intelligence (AI) and machine learning (ML) workloads are pushing the boundaries of what’s possible with data. As organizations scale up their compute clusters and embrace ever-larger datasets, performance bottlenecks are not limited to CPUs or GPUs, they can be in the network and storage layers. Equally important, GPU-heavy compute nodes are expensive. Keeping them waiting for data needlessly wastes time and money.
To address this problem, Oracle and Paradigm4 worked jointly to test flexFS on Oracle Cloud Infrastructure (OCI) to deliver exceptional I/O and price performance. flexFS is a cloud native, elastic file system that’s purpose-built to accelerate AI, ML, and high-performance computing (HPC) workloads.
Answering the AI/ML Storage Challenge
AI and ML workflows are notoriously data hungry. Consider a typical deep learning training run: dozens or hundreds of compute nodes, each needing to read terabytes of training data in parallel, checkpoint models, and write logs — all while minimizing idle time. The ideal storage system must deliver:
- High aggregate throughput for parallel reads and writes
- Low latency, especially for metadata and small files
- Elasticity to scale up or down with the workload
- Operational simplicity and cost efficiency
flexFS was designed from the ground up to meet these needs. It’s a fully POSIX-compliant, cloud native file system that leverages multiple storage technologies — memory, SSDs, data-proxy services, and hyperscale OCI Object Storage — to deliver the performance and semantics that AI/ML workloads demand.
flexFS on OCI Performance
By making efficient use of OCI resources, flexFS can enable file-I/O intense workloads to achieve around 290 Gbps throughput [sequential read or write] on a single volume (on flexFS converged with 4 nodes totaling 400 Gbps network bandwidth – see flexFS-converged on OCI section below) — bound by network bandwidth of the proxy servers. In addition, due to flexFS using OCI Object Storage, it helps you to get order-of-magnitude storage cost savings — typically translating to exceptional price performance.
How flexFS WorksflexFS on OCI Architecture
- Parallel File I/O: flexFS splits file data into fixed-size blocks, storing each as an object in the underlying object store. Compute nodes read and write these blocks in parallel, achieving aggregate throughput limited by network bandwidth — not by the number of storage servers or provisioned capacity.
- Low-Latency Metadata: Metadata operations (listing files, moving directories, etc.) are handled by a dedicated, low-latency metadata service outside the object store. This facilitates fast response times for operations that are typically slow on object storage alone.
- Proxy Group (Write-Back Cache): An optional distributed proxy group provides a write-back cache, further enabling reducing latency for workloads with many small files or frequent random I/O.
- Elasticity: Both capacity and throughput scale up and down independently and quickly without disruptive migrations or data movement.
- Cost Efficiency: Metered, usage-based billing means you pay for what you use. No over-provisioning storage merely to hit a throughput target.
flexFS on OCI Architecture
Figure 1 shows a typical production configuration for flexFS on OCI, combining a number of Proxy servers and multiple Metadata servers on dedicated nodes, and OCI Object Storage for high throughput, low latency, and HA (high availability). OCI DenseIO compute shapes (Baremetal and/or VM) which have different configurations of NVMe SSDs are recommended for flexFS dedicated architecture.
flexFS Dedicated Architecture
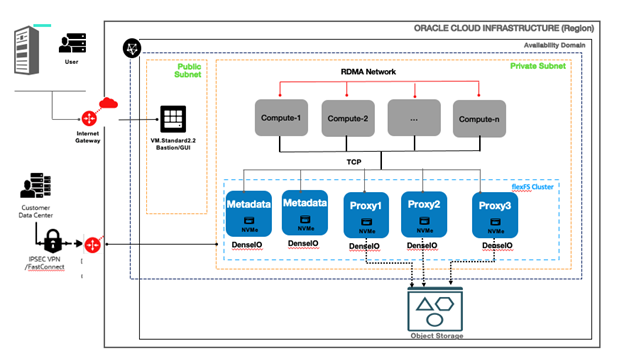
Figure 1: flexFS-dedicated on OCI
flexFS Converged Architecture
flexFS can run on GPU or general purpose CPU nodes with local NVMe SSDs to run a high performance cache backed by OCI Object storage. Figure 2 shows a converged production configuration with flexFS Proxy and client workloads running on GPU compute nodes (Compute-1,…, to Compute-n). The flexFS metadata services run on separate VMs (OCI Standard Compute shapes) with high available and redundant OCI Block Volumes.
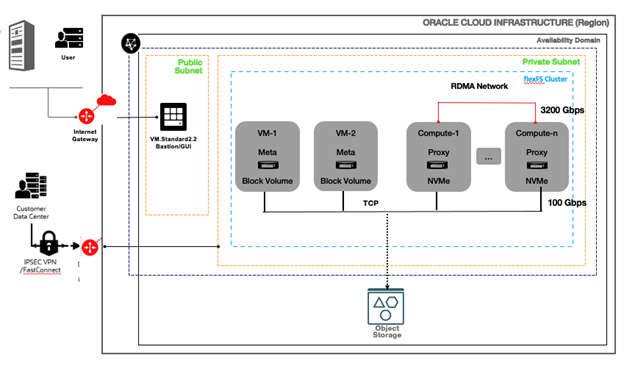
Figure 2: flexFS Converged Production Setup on OCI
Benchmarking
We tested flexFS on OCI in both configurations using proxy groups for both throughput and latency performance: a traditional setup with storage services running on dedicated hardware, and a converged setup with storage services running on client GPU nodes.
flexFS-dedicated on OCI
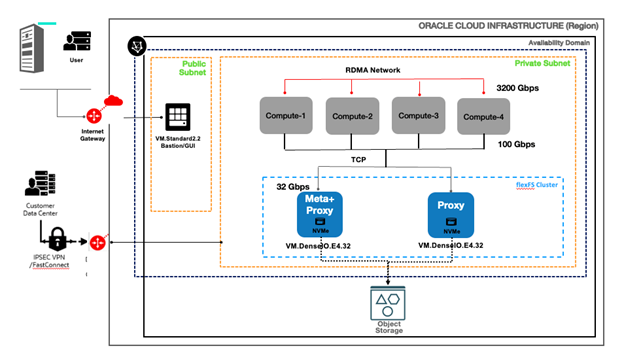
Figure 3: flexFS-dedicated on OCI
Storage:
- Two VM.DenseIO.E4.32 nodes; each with 32 OCPUs, 512 GB Mem, 4x 6.8 TB NVMe drives, 32 Gbps NIC. The 4 NVMe drives on each node are configured as a single RAID0 device. For higher capacity and higher network bandwidth, bare metal DenseIO E4 and E5 compute shapes are recommended.
- An OCI Object Storage bucket in the same region.
Clients:
- Four BM.GPU.H100.8 nodes. Each node has 8x H100 GPUs, 80 GB GPU Mem, 112 OCPUs, 2 TB Host Mem, 16x 3.84 TB NVMe drives, 8x2x200 Gbps RDMA, 1x 100 Gbps NIC.
flexFS-converged on OCI
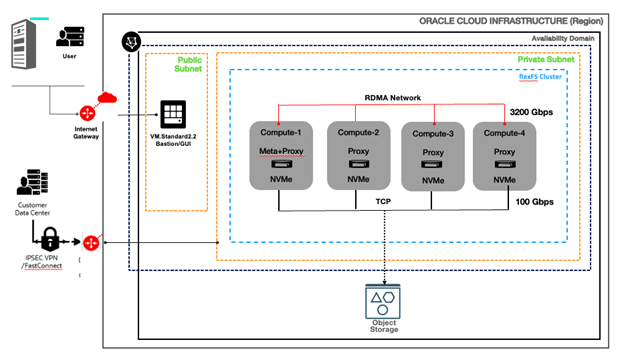
Figure 4: flexFS-converged on OCI
Storage & Clients:
- Four BM.GPU.H100.8 nodes. Each node has 8x H100 GPUs, 80 GB GPU Mem, 112 OCPUs, 2 TB Host Mem, 16x 3.84 TB NVMe drives, 8x2x200 Gbps RDMA, 1x 100 Gbps NIC. 15 NVMe drives on each node are configured as a single RAID0 device.
- An OCI Object Storage bucket in the same region.
Workloads Tested
- Linux DD command
- Write: copy files from RAM disk to test-target
- Read: copy files from test-target to the null device
- MLPerf ResNet-50 – image classification benchmark
Test Results
Basic Linux DD command
Sequential Write:
# dd if=/dev/shm/rand-10GiB of=/flexfs/hpc-gpu/rand-10GiB-n*-* bs=2M
Sequential Read:
# dd if=/flexfs/hpc-gpu/rand-10GiB-n*-* of=/dev/null bs=2M
Where the two “*” are respectively the node number, and the job number on each node. GNU Parallel tool was used to launch the jobs.
The following table shows sequential write and read performance.
| IO Type | flexFS-dedicated | flexFS-converged |
|---|---|---|
| Sequential Write | ||
| 1 node x 1 job x 40 GiB | 1,123 MB/s | 1,209 MB/s |
| 4 nodes x 1 job x 40 GiB | 4,452 MB/s | 4,490 MB/s |
| 4 nodes x 16 jobs x 10 GiB | 8,235 MB/s | 37,519 MB/s |
| Sequential Read | ||
| 1 node x 1 job x 40 GiB | 847 MB/s | 818 MB/s |
| 4 nodes x 1 job x 40 GiB | 3,388 MB/s | 3,308 MB/s |
| 4 nodes x 16 jobs x 10 GiB | 8,278 MB/s | 34,846 MB/s |
Table 1: Linux DD performance on flexFS-dedicated and flexFS-converged on OCI platform
In the one-job-per-node cases, flexFS-dedicated on OCI and flexFS-converged on OCI perform about the same and scale well from 1 node to 4 nodes.
In the heavier sixteen-job-per-node cases, the converged setup achieved much higher performance than the dedicated setup. There are two reasons for this. First, the network bandwidth of the 4 GPU nodes is 4x100Gbps=400Gbps (50 GB/s), while the two DenseIO nodes have 2x32Gbps=64Gbps (8 GB/s) total bandwidth. Second, the converged setup enables a portion of the I/O to be performed on the local NVMe drives.
MLPerf ResNet-50
This benchmark measures the amount of time required to train a ResNet-50 image classification model using a standard dataset. It was run on both flexFS-dedicated and flexFS-converged configurations on OCI.
The first three in the below table show results for the flexFS-dedicated setup. The fourth row shows results when local NVMes on the BM.GPU.H100.8 nodes are leveraged for flexFS proxy service file caching. In all tests, the training data have been loaded to the corresponding file systems (flexFS and Local NVMe respectively) before Resnet50 jobs get started.
| Setup | # of H100 GPU Nodes | flexFS Runtime (seconds) | Local NVMe Runtime (seconds) | Difference from Local NVMe |
|---|---|---|---|---|
| flexFS Dedicated |
1 | 843.6 | 843.19 |
-0.3% |
| 2 | 473.9 | 466.53 | +1.6% | |
| 4 | 309.3 | 290.37 | +6.5% | |
| flexFS Dedicated + GPU local NVMe SSD Cache | 4 | 290.9 | 290.37 | +0.2% |
Table 2: Performance of flexFS on OCI against local NVMe drives
Performance of accessing cached data on flexFS on OCI is extremely close to that of local NVMe disks. That’s not surprising in a converged configuration, because the file services — including write-back caching — are co-resident with the client workload. This dataset resides on OCI Object Storage and delivers performance on par with local NVMe disks.
OCI and flexFS: Elevating AI/ML & Life Sciences with Lightning-Fast File Storage
As organizations increasingly rely on Oracle Cloud Infrastructure (OCI) for high performance computing, AI, and large-scale analytics, the need for scalable, high performance, and cost-effective file storage continues to grow. For customers with especially demanding, data-intensive workloads, OCI and Paradigm4’s flexFS can offer a performance boost — delivering exceptional versatility, performance, elasticity, and operational simplicity, natively on OCI Object Storage.
To learn more, contact Pinkesh Valdria at Oracle or ask your Oracle Sales Account team to engage the OCI HPC GPU Storage team. Also, visit flexFS website or contact info@flexfs.io.
flexFS™ is a trademark of Paradigm4, Inc. All other trademarks are the property of their respective owners.


