Introduction
Modern applications rarely receive perfectly predictable traffic. Message volumes rise during business peaks, drop during idle periods, and often arrive in bursts that are difficult to handle with static infrastructure. When Kubernetes workloads are scaled only through fixed replica counts or manual intervention, teams usually face two problems: under-provisioning during spikes or over-provisioning during quiet periods.
Kubernetes Event-driven Autoscaling, or KEDA, solves this problem by allowing workloads to scale based on external event sources rather than only CPU or memory. When combined with Oracle Container Engine for Kubernetes, OCI Queue, and lightweight Python services, KEDA provides a reusable pattern for demand-driven, cost-efficient, and resilient event processing.
The Challenge: Static Scaling Does Not Reflect Real Workload Pressure
Many enterprise workloads process events asynchronously. Producers generate messages, queues buffer them, and consumer services process them in Kubernetes. However, traditional Kubernetes autoscaling often depends on CPU and memory metrics. These metrics do not always represent the actual pressure on the system.
For queue-based workloads, the more meaningful signal is backlog depth: how many visible messages are waiting to be processed.
Without event-driven scaling, teams must manually monitor message volume, tune replica counts, and adjust deployments during peak and low-load periods. This increases operational overhead and can affect throughput, reliability, and infrastructure cost.
The Solution: Queue-Driven Autoscaling with KEDA
The solution uses OCI Queue as the event backbone and KEDA on OKE to dynamically scale consumer workloads based on visible queue messages.
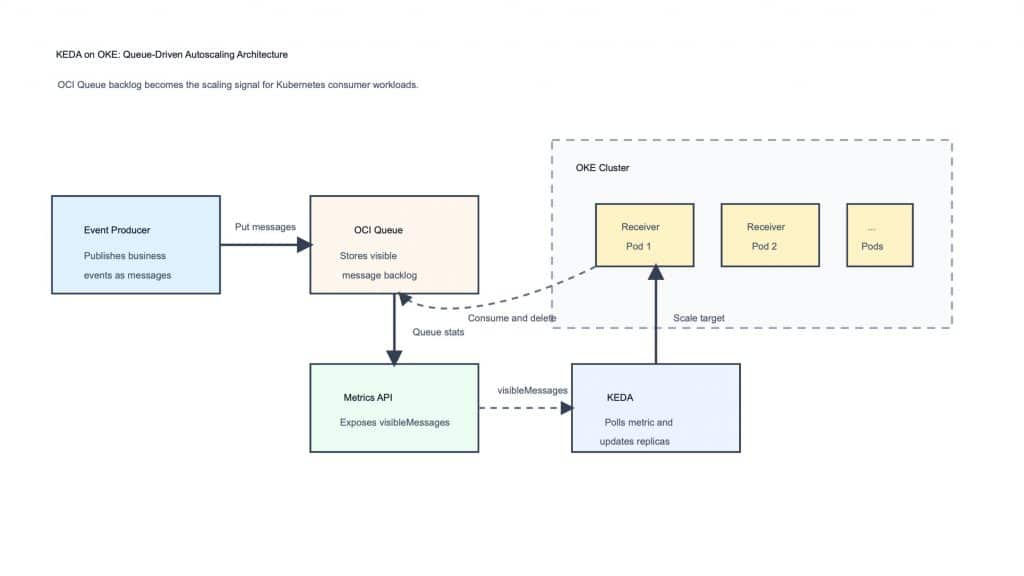
Figure 1. Architecture overview for queue-driven autoscaling with OCI Queue, KEDA, and OKE.
The architecture includes four main components:
- Event producers send messages to OCI Queue.
- OCI Queue stores messages until they are consumed.
- A metrics API exposes the queue’s visible message count.
- KEDA polls the metric and scales OKE consumer pods up or down.
In this implementation, a Python Flask service calls OCI Queue statistics and exposes a metric endpoint. The endpoint returns a visibleMessages value. KEDA then uses a ScaledObject with the metrics-api trigger to read that value and scale the receiver deployment.
How the Runtime Flow Works
When an event producer sends messages to OCI Queue, those messages become visible until a consumer retrieves them. The receiver service running on OKE continuously polls the queue, processes messages, and deletes them after successful handling.
At the same time, KEDA checks the visible message count at a defined polling interval. If the queue backlog rises above the configured threshold, KEDA increases the number of receiver pods. When the backlog drops, KEDA waits for the cooldown period and then scales down the deployment.
This creates a controlled autoscaling loop:
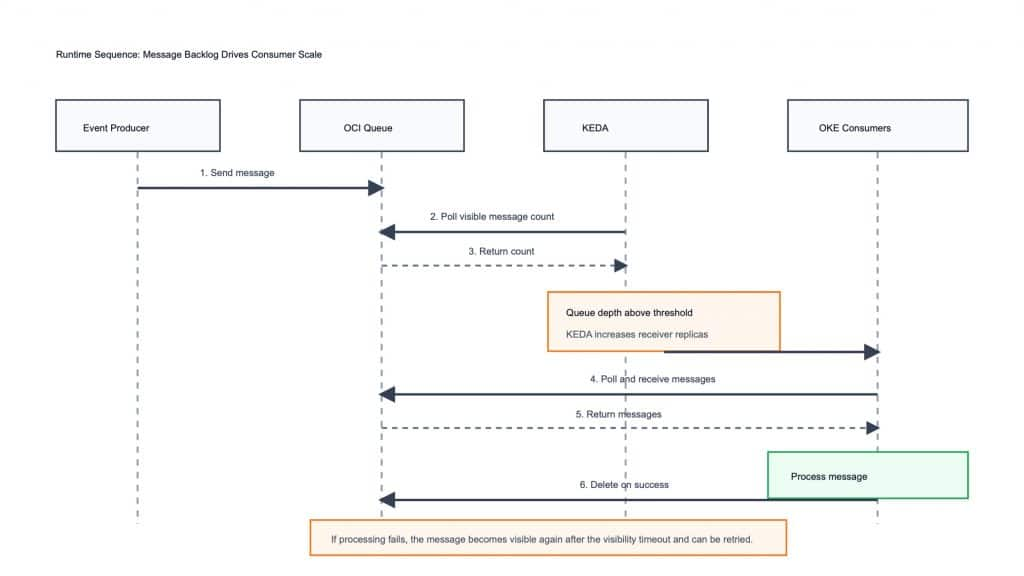
Figure 2. Runtime sequence from message production through queue polling, scaling, consumption, and retry behavior.
- More visible messages means more consumer replicas.
- Fewer visible messages means fewer replicas.
- Idle periods can run with a minimal pod count.
- Scaling behaviour remains predictable through polling and cooldown settings.
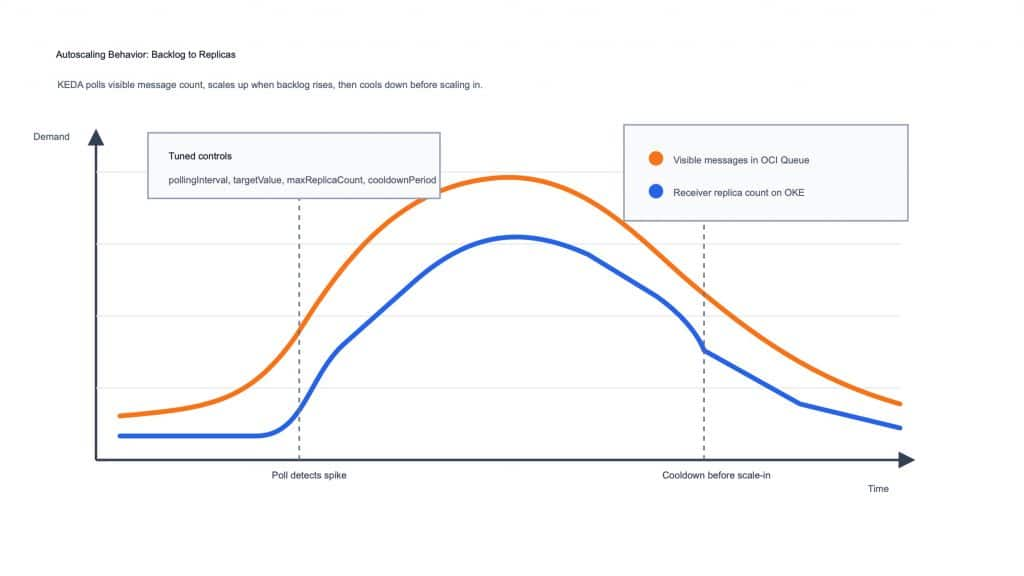
Figure 3. Scaling behavior: KEDA reacts to backlog growth and applies cooldown before reducing replicas.
Example KEDA Configuration
The included ScaledObject targets the receiver deployment and uses a metrics API endpoint for scaling:
pollingInterval: 5
minReplicaCount: 1
maxReplicaCount: 30
cooldownPeriod: 120
triggers:
- type: metrics-api
metadata:
targetValue: "1"
url: http://quemsg-service.aicue.svc.cluster.local:5003/getAppQueue
valueLocation: visibleMessages
This means KEDA checks the metric every five seconds, scales the receiver deployment up to thirty replicas, and waits 120 seconds before scaling down after demand reduces.
Advantages
This architecture provides several practical benefits:
- Automatic scaling based on real queue demand
- Lower compute cost during low-volume periods
- Better throughput during message spikes
- Decoupled producer and consumer services
- Improved reliability through asynchronous processing
- Reusable deployment pattern for OKE-based workloads
- Reduced manual scaling and operational tuning
For delivery teams, the main value is repeatability. The same pattern can be reused across workloads that rely on queue-based processing, with only queue details, thresholds, image names, and business logic adjusted per application.
Conclusion
KEDA brings true event-driven autoscaling to Kubernetes workloads. By using OCI Queue visible message count as the scaling signal, teams can move beyond static replica sizing and CPU-only autoscaling. On OKE, this creates a scalable, resilient, and cost-aware architecture for asynchronous workloads.
For organizations building cloud-native systems on OCI, this pattern provides a practical accelerator: producers remain decoupled, consumers scale with real demand, and platform teams gain a standardized approach for queue-driven autoscaling.
