Running production workloads on Oracle Cloud Infrastructure (OCI) Container Instances (CI) is a great way to get the simplicity of serverless containers while still integrating with core OCI services. For many customers, the next step is resilience: ensuring applications operating in one OCI region can transition to another region during a regional outage or major service disruption. To establish a robust disaster recovery (DR) plan for applications running on OCI CI, it’s essential to ensure that applications operating in one region can seamlessly transition to another in the event of a disruption.
This blog outlines practical, common patterns and steps you can take to build a multi-region disaster recovery (DR) approach for OCI Container Instances, so they can fail over quickly with minimal downtime and controlled data loss.
Introduction
At a high level, DR for containerized workloads comes down to four core capabilities:
- Recreate compute capacity quickly (container instances, networking, IAM, policies, secrets).
- Ensure the same container images exist in the DR region for artifact availability.
- Keep data and state synchronized (database, object storage, external dependencies).
- Shift traffic safely (DNS and load balancing with tested run-books).
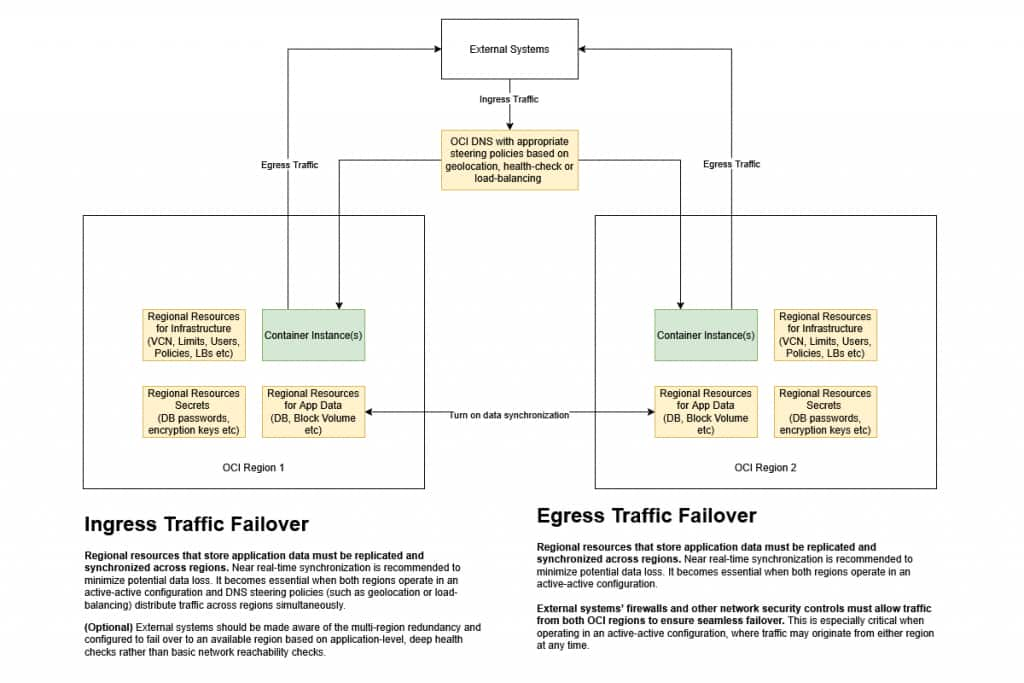
Prerequisites
OCI CI depends on other OCI resources to operate. You will need to identify the core dependencies that your containers rely on before starting. These resources include:
- OCI Networking (VCNs/subnets, security lists/NSGs, load balancers)
- Container images (OCIR or external registry)
- Secrets/config (Vault, environment variables, configs)
- Persistent data stores (Autonomous Database, MySQL, NoSQL, Object Storage, block/file storage via app-level patterns)
- Observability (Logging, Monitoring, Alarms)
- DNS/traffic steering (OCI DNS)
To make fail-over predictable, ensure both regions are configured identically for all “environment prerequisites” that CI depends on:
Networking
- Virtual Cloud Networks (VCNs): Ensure required subnets exist in both regions (CIDRs, public/private placement, regional AD/FD strategy as applicable).
- Subnets: Align Security Lists and/or NSGs with least-privilege rules for CI ingress/egress
- Routing & gateways: Ensure route tables and required gateways are present (IGW/NAT/SGW), plus service endpoints where applicable.
- Load balancers: Pre-provision regional LBs (even in Active/Passive) to reduce RTO and simplify testing.
- Private DNS (if used): Replicate private DNS zones/records and resolution paths in the DR region
IAM Policies
- Ensure any regional policies needed for access management are created in the secondary region as well.
- Make sure dynamic groups, policies, and compartment structure support CI in both regions.
Limits Configuration
- Validate that the service limits (container instances, compute core and memory count, networking, load balancers, etc.) are sufficient in both regions—especially if the DR region must handle full production load during a failover.
Secrets
- Plan how secrets are stored and retrieved in each region (for example, OCI Vault and associated keys/secrets).
- Ensure applications can securely access the correct region’s secrets at runtime.
This inventory determines what must be replicated, what can be rebuilt, and what needs multi-region capabilities.
Step 1: Deploy Across Multiple Regions
Preparing OCI CI Disaster Recovery begins with planning for where your workloads will run. Choose geographically separated OCI regions to host your primary and secondary deployments. Your choice of DR topology typically falls into one of these two models:
- Active/Passive (warm standby), where the primary region serves all traffic, with the secondary region pre-provisioned (or partially pre-provisioned) and becoming active only during fail-over.
- Pros: simpler operations, lower cost
- Cons: some downtime during fail-over; potential data loss depending on replication lag
- Active/Active, where both regions serve live traffic continuously, with data replication and traffic distribution across regions.
- Pros: fastest recovery, can reduce latency for global users
- Cons: more complex data consistency, operational overhead, higher cost
Step 2: Replicate Container Images
During a regional failover, deployments can only start if the target region can pull the required container images. Ensure the same image versions exist in both regions. We recommend using OCI Container Registry (OCIR) as the system of record for container images. If using OCIR, configure cross-region replication rules so images remain synchronized between regions. For production deployments, prefer immutable references (image digests) where possible; tags are convenient but can introduce ambiguity during incident response. This helps ensure:
- Identical image versions exist in both regions,
- Fail-over doesn’t stall because the DR region is missing the required tags/digests,
- Deployment automation can reference consistent image names.
Step 3: Replicate Data and State Across Regions
Containers are stateless by design, but applications rarely are. A resilient cross-region architecture requires deliberate planning for data replication and state synchronization.
For Database Replication, utilize OCI database services with cross-region replication capabilities to keep data synchronized. The right approach depends on the database type and the customer’s Recovery Point Objectives/Recovery Time Objective (RPO/RTO) targets, for example:
- Asynchronous replication for cost-effective DR,
- Synchronous/near-sync patterns when low data loss is required (often with added complexity/constraints).
For Object Storage, enable cross-region replication for OCI Object Storage buckets that contain application data (uploads, artifacts, media, exports, etc.). This is especially helpful for workloads that:
- Write files as part of request handling,
- Depend on stored configuration or models,
- Generate reports or archives consumed later.
Also worth considering:
- Whether replication should be one-way or bi-directional (bi-directional is more complex),
- How you handle deletes and versioning during replication.
Step 4: Configure Load Balancing and DNS
Your disaster recovery setup will want to deploy load balancers in both regions to distribute traffic to CI endpoints. Even in Active/Passive designs, having the DR load balancer ready reduces recovery time and makes testing easier. Common patterns include configuring each region with a regional load balancer fronting CI services, and health checks to validate that the application is genuinely available (not just “port open”).
For DNS, use OCI DNS to manage domain names.
- Active/Passive replication: implement DNS failover policies that redirect traffic to the secondary region during a primary region outage.
- Ensure DNS TTLs align with recovery goals: a lower TTL can speed failover but may increase DNS query volume and operational sensitivity.
Important: DNS-based failover is simple and widely used, but it’s not instantaneous. Make sure you understand realistic propagation behaviors and plan accordingly.
Step 5: Regular Testing and Validation
A DR plan that hasn’t been tested is a hypothesis. To ensure your cross-region migration works, conduct periodic DR drills to ensure:
- Fail-over mechanisms work as intended,
- Deployment automation can stand up the full stack in the secondary region,
- Replication and data integrity meet RPO requirements,
- On-call teams can execute run-books under pressure.
We recommend running these drills:
- Planned fail-over (controlled, during a maintenance window)
- Unplanned simulation (tabletop exercise + partial technical execution)
- Region isolation tests (validate assumptions about external dependencies)
Additional Recommendation: Implement Infrastructure as Code (IaC)
Using Infrastructure as Code solutions, such as Terraform, to define and manage infrastructure will make the secondary region reproducible and help reduce “tribal knowledge” during an incident. Structure Terraform into reusable modules (network, IAM, registry, CI deployment, load balancing), and parameterize the region so you can deploy the same blueprint twice with minimal drift. This way, you can be confident that:
- VCNs/subnets/security policies are consistent,
- IAM policies and dynamic groups are kept in sync,
- CI deployments can be recreated predictably,
- environment differences are controlled via variables (region, CIDRs, OCIDs).
Closing Thoughts
OCI Container Instances can support a practical multi-region DR architecture when failover is designed into the full stack, not just the container runtime. That means keeping infrastructure and artifacts aligned across regions, protecting stateful dependencies, and validating traffic failover through regular testing so applications can recover with minimal downtime and controlled data loss.
