As AI models move beyond trillion-parameter scales, progress increasingly depends on larger GPU clusters and faster, more predictable networking. At extreme scale, however, traditional non-blocking RDMA fabrics begin to encounter hard physical limits. Switch ASIC buffer capacity, port density, optics, power, and cost ultimately constrain how far a single flat fabric can scale.
To push GPU clusters beyond these limits, two architectural directions have emerged.
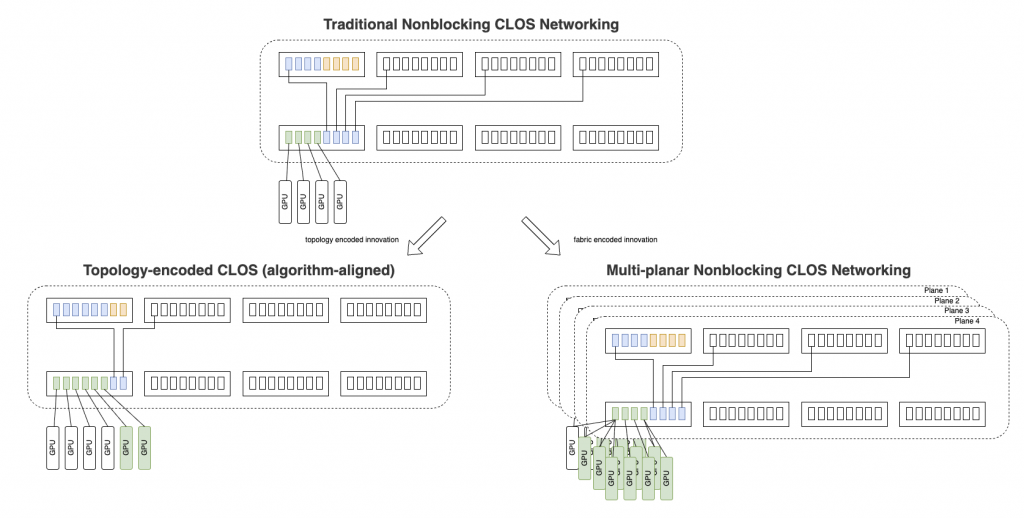
The first is topology-encoded, blocking RDMA networking, which scales by embedding collective communication assumptions directly into hardware topology—often described as fractal or hierarchical designs. This approach favors specialization and fixed communication patterns to extend scale.
The second is multi-planar, non-blocking fabric-encoded networking, which preserves non-blocking semantics while extending scale through system-level innovation. Rather than hard-coding assumptions into topology, it introduces additional planes and coordination mechanisms to maintain predictable performance as clusters grow.
In this blog, we examine both approaches and explain how OCI addresses this challenge. We show how multi-plane networking, together with purpose-built Acceleron RoCE hardware, enables scaling beyond single-fabric limits—while preserving flexibility, predictability, and operational stability for the next generation of AI workloads.
Fig. 1. Architectural paths for scaling AI networking beyond single-fabric limits.
Background
As AI models advance into trillion-parameter regimes, progress no longer comes from raw compute scale alone. Pretraining increasingly consumes more data than humanity can generate, and the modern scaling law is shifting toward scale combined with algorithmic innovation—a transition that fundamentally reshapes the role of infrastructure. [ref 1, 2].
AI research has entered an iteration-driven phase. Frontier models are no longer trained once per generation; they are continuously retrained, refined, and re-architected on compressed cycles. According to the 2025 Stanford AI Index Report, the performance gap between leading models has narrowed to just 0.7% in skill scores, intensifying competitive pressure and accelerating release cadence. Major foundation models are now updated roughly every five to six months, with training compute requirements continuing to double on a similar timescale. Researchers exploring new model architectures, parallelism strategies, and training dynamics increasingly depend on access to larger and more flexible GPU clusters to sustain progress and compress the research timeline [ref 4].
As a result, cluster scale directly translates into scientific velocity. Scaling is no longer about peak throughput alone; it is about reducing time-to-discovery—enabling more experiments, broader exploration, and faster convergence.
Sustaining this pace requires AI infrastructure to scale beyond traditional limits. Advancing GPU cluster size—and the interconnect networking that binds those GPUs together—has become a foundational requirement for the next era of AI research.
At hyperscale, communication—not compute—sets the pace. GPUs no longer behave as isolated accelerators; they operate as nodes in tightly synchronized distributed systems. Latency, bandwidth, congestion behavior, and packet loss translate directly into training efficiency, cost, and time-to-solution [ref 3].
In practice, scaling AI networking encounters hard physical constraints. Switch port density, ASIC buffer capacity, optics, power, and cost make it increasingly difficult to expand a single, flat, fully non-blocking fabric indefinitely. Once these limits are reached, two fundamentally different architectural paths emerge—across both scale-up and scale-out domains.
Some systems scale by encoding topology-aware (fractal) structures that mirror expected collective communication patterns, constraining traffic to reduce pressure on the fabric. Others pursue flexible, fabric-encoded networking, pushing complexity into the network itself rather than embedding assumptions into topology. OCI deliberately takes the second path.
This blog first examines why fractal (topology-encoded) AI networking has emerged as a response to physical scaling limits—and where its constraints appear as workloads, algorithms, and placement assumptions become less predictable at frontier scale. It then explains why flexible, fabric-encoded networking is better aligned with the needs of cloud and research AI. Finally, it explores OCI’s approach to scaling beyond physical limits, detailing how multi-plane networking and system-level hardware innovation—shaped by real Zettascale operational experience—extend lossless RDMA scalability while preserving flexibility and predictable performance.
Fractal (Topology-Encoded) AI Networking
Modern AI training relies heavily on collective communication operations such as AllReduce, ReduceScatter, and AllGather. Libraries like NCCL implement these collectives using structured patterns—rings, trees, and hierarchical combinations—to balance bandwidth utilization, synchronization cost, and GPU efficiency.
Fig. 2. Collective Communication Basics.
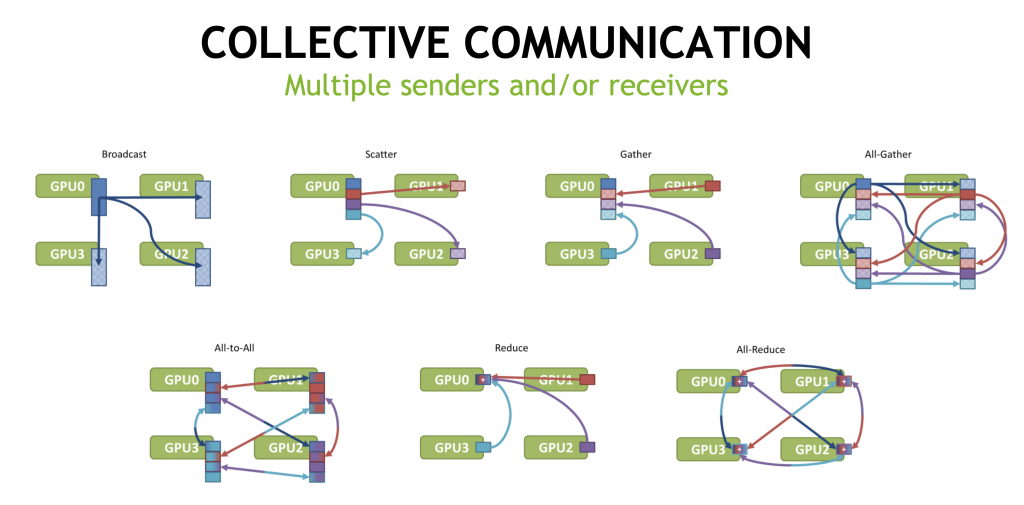
Image from https://images.nvidia.com/events/sc15/pdfs/NCCL-Woolley.pdf
These collective algorithms implicitly define a communication graph: a structured, repeating pattern of data exchange executed at every training step.
Fractal, or topology-encoded, AI networking emerges when this communication graph is materialized directly in hardware topology. GPUs are organized into tightly coupled local domains, and those domains are recursively composed into larger structures. Global collectives are decomposed into staged operations that closely follow this physical hierarchy, minimizing long-distance traffic and concentrating communication along predefined paths [ref 4, 5, 9–12].
In this model, topology follows the algorithm.
This approach is a rational response to physical constraints. As GPU clusters grow, building a single, flat, fully non-blocking RDMA fabric becomes increasingly difficult. Switch ASIC buffers must absorb in-flight packets to preserve lossless behavior, and buffering requirements scale with bandwidth × latency × hop count. At extreme scale, these requirements exceed what a single fabric can practically provide.
To address this, some systems intentionally introduce blocking CLOS behavior, using topology and scheduling to constrain traffic patterns rather than allowing unconstrained all-to-all communication. By shaping the network to match expected collective behavior, fractal designs reduce contention, lower buffer pressure, and improve efficiency for large-scale language model training.
The term fractal reflects this recursive geometry: small, tightly connected groups repeat at multiple scales, mirroring both the structure of collective algorithms and the hierarchical decomposition of communication.
When workloads are stable, parallelism strategies are fixed, and placement is predictable, fractal networking can be extremely efficient—often enabling scale beyond what a flat non-blocking fabric could support.
Where the Limits of Fractal Networking Appear
The effectiveness of topology-encoded networking rests on a critical assumption:
The relationship between model structure, collective algorithms, and physical placement remains stable over time.
This corresponds to operating within a small flexibility ratio—limited freedom to remap workloads, change parallelism strategies, or introduce new communication patterns without performance penalties.
In tightly controlled environments—such as fixed-purpose training clusters running homogeneous workloads—this assumption often holds. However, cloud AI infrastructure, and especially frontier AI research, operates under very different conditions:
- Multiple tenants share the same physical fabric
- Job sizes and parallelism strategies change dynamically
- Training and inference coexist
- New model architectures and communication patterns emerge continuously
In these environments, communication behavior frequently diverges from the assumptions encoded into topology. Performance degradation is not a failure of implementation; it is the natural consequence of reduced flexibility.
Blocking behavior, staged collectives, and topology-constrained routing that work well for one model or parallelization strategy may become suboptimal—or even pathological—for another. Rebalancing often requires careful placement, rigid scheduling, or topology-aware orchestration, narrowing the space of feasible workloads.
As a result, fractal AI networking scales efficiently within a narrow operating envelope, but becomes increasingly restrictive as AI research moves into unexplored territory—where neither workloads nor algorithms are known in advance [ref 5].
Flexible, Fabric-Encoded Networking for Cloud AI
Cloud AI infrastructure must optimize for a fundamentally different objective: freedom of exploration at scale.
Workloads are dynamic by nature. Model architectures evolve, parallelism strategies change, training and inference coexist, and job sizes shift continuously. In this environment, embedding assumptions directly into topology becomes a constraint rather than an advantage.
OCI therefore adopts a flexibility-first architectural approach. Instead of encoding communication patterns into topology—whether in scale-up or scale-out designs—OCI builds fabric-encoded, non-blocking, lossless RDMA networks that deliver predictable performance across a wide range of workloads.
In a fabric-encoded design, any GPU can communicate efficiently with any other GPU, workload placement remains flexible, and new parallel algorithms can be adopted without redesigning the network. This preserves a large operating envelope, allowing customers to evolve models and strategies without being constrained by network structure [ref 3].
However, flexibility alone is not sufficient. At extreme scale, even the best non-blocking fabric eventually encounters hard physical limits. To continue scaling, flexibility itself must scale beyond a single fabric.
Scaling Beyond Physical Limits: Multi-Plane Networking
As AI clusters grow toward hundreds of thousands—and eventually millions—of GPUs, a fundamental limitation emerges: switch ASIC buffer capacity.
Lossless RDMA requires buffering in-flight packets. Buffer demand increases with bandwidth, latency, and hop count. Beyond a certain scale, no single switch ASIC can provide enough buffering to sustain lossless behavior—regardless of topology [ref 3].
OCI’s answer is multi-plane networking.
Fig. 3. Multi-planar Network.
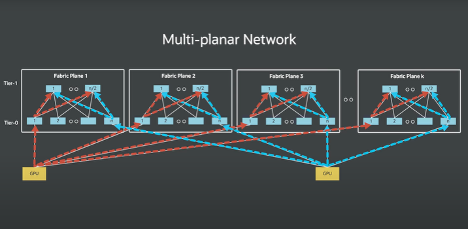
Image from: https://blogs.oracle.com/cloud-infrastructure/first-principles-oracle-acceleron-multiplanar
Rather than forcing all traffic through a single logical fabric, OCI distributes traffic across multiple independent network planes. Each plane operates as its own non-blocking, lossless fabric with independent buffering, congestion control, and fault domains.
From a system perspective, this achieves a critical outcome: buffering capacity scales with the number of planes, rather than being capped by a single ASIC.
This is not a simple “add more links” solution. Multi-plane networking introduces real challenges, including traffic distribution and packet ordering across planes, preserving lossless semantics end-to-end, preventing congestion coupling, and maintaining predictable latency under dynamic, multi-tenant workloads. These challenges must be solved holistically—across hardware, firmware, and software—to behave as a single coherent system.
Zettascale10 and Acceleron: Innovation Informed by Experience
Zettascale10 is not a theoretical design. It is a system-level innovation shaped by years of operating some of the largest AI clusters in production cloud environments.
Through real-world operation, OCI identified a critical insight: at scale, switch ASIC buffer limits—not link bandwidth—become the dominant constraint on lossless RDMA scalability.
Zettascale10 applies this insight directly. By coordinating traffic across multiple planes and managing behavior end-to-end, OCI extends lossless RDMA scalability beyond what any single fabric—or single ASIC—can support, without sacrificing predictability or reliability.
This architecture is enabled by Oracle’s Acceleron RoCE NICs, which act as system-aware endpoints rather than generic network interfaces. Acceleron provides hardware-accelerated multi-plane traffic steering, precise congestion control and packet ordering, and lower power and cost per bit compared to conventional NICs.
Acceleron is not simply a faster NIC. It is a core part of the system architecture, designed to cooperate with the fabric to push scaling limits outward.
With Zettascale10, OCI delivers approximately 4× practical scaling headroom today, while maintaining lossless RDMA semantics, predictable latency, and operational stability in multi-tenant environments. At this scale, size itself becomes an advantage: larger fabrics improve utilization across diverse workloads, lowering per-job networking cost, while purpose-built components ensure that power and cost efficiency improve alongside growth [ref 3, 13].
Conclusion
In this blog, we first explored the emergence of fractal (topology-encoded) networking—why it exists, what problems it solves, and where its limits surface as AI workloads become more dynamic and less predictable. We then presented OCI’s answer to these scaling challenges: a system-level approach that avoids hard-coding assumptions into topology and instead scales the fabric itself.
Through Zettascale10 and Acceleron, OCI extends non-blocking RDMA beyond single-fabric limits using multi-plane networking, enabling AI clusters to grow larger while remaining flexible, predictable, and cost-efficient. For the next wave of AI researchers, this translates into faster iteration cycles, freedom to explore new model architectures and parallelism strategies, and infrastructure that scales with research ambition—without forcing tradeoffs between scale, performance, and adaptability.
At zettascale, flexibility is not optional. It is the enabler.
References
- https://www.youtube.com/watch?v=aR20FWCCjAs
- https://www.businessinsider.com/openai-cofounder-ilya-sutskever-scaling-ai-age-of-research-dwarkesh-2025-11
- https://blogs.oracle.com/cloud-infrastructure/zettascale-osu-nccl-benchmark-h100-ai-workloads
- https://hai.stanford.edu/ai-index/2025-ai-index-report
- https://run-ai-docs.nvidia.com/saas/platform-management/aiinitiatives/resources/topology-aware-scheduling
- https://www.datacenterdynamics.com/en/news/oracle-unveils-zettascale10-ai-supercomputer-claims-it-will-be-largest-in-the-cloud/
- https://blogs.oracle.com/cloud-infrastructure/post/oci-accelerates-hpc-ai-db-roce-nvidia-connectx
- https://engineering.fb.com/2024/08/05/data-center-engineering/roce-network-distributed-ai-training-at-scale/
- https://developer.nvidia.com/nccl
- https://techshinobi.hashnode.dev/network-engineers-introductory-guide-to-nccl
- https://developer.nvidia.com/blog/massively-scale-deep-learning-training-nccl-2-4
- https://developer.nvidia.com/blog/doubling-all2all-performance-with-nvidia-collective-communication-library-2-12/
- https://blogs.oracle.com/cloud-infrastructure/first-principles-oracle-acceleron-multiplanar
