Data Flow Cache Overview
Imagine you have an Oracle Analytics Data Flow that ingests a dataset pulling from your database on a daily schedule. This data flow is business-critical because it populates a dataset used in a workbook report that stakeholders rely on. On a busy day, however, the source database might be overwhelmed by multiple processes competing for resources, causing your data flow to take longer to complete. Or, you’re dealing with a dataset created from a complex query and as a result, data flow execution time is increased. These delays don’t just affect reporting—they can stall crucial decision-making and slow down your entire analytics pipeline.
That’s where caching comes in. Data flows can pull data from already-cached sources, dramatically accelerating execution times. By caching your input dataset(s) and setting the Use Source Cache When Available flag, your data flow leverages the caching system in Oracle Analytics Cloud (OAC). Under the hood, this system uses ADW tables, which bring additional performance benefits such as high-speed query execution.
Let’s look at how this works through a real use case…
I’ve created a dataset in Oracle Analytics using a manual SQL query that calculates profit (revenue minus supply cost) by year and product brand. The query joins three tables to align order dates with product details, grouping by year and brand and ordering the results by year and descending profit. Because this query is relatively complex, I set the dataset to Automatic Caching so that a new cache table is created in the backend with the necessary columns already materialized. Without the cache, every query would have to go back to the source database to perform the same joins and grouping. By caching, we effectively create a materialized view of the data, allowing faster access when using the dataset in a workbook or data flow.
If you need the most recent data, be sure to refresh your cached dataset periodically—either on a set schedule or manually—to keep your queries up to date. You can also include dataset refreshes in a scheduled sequence, so the dataset is updated just before the data flow runs.
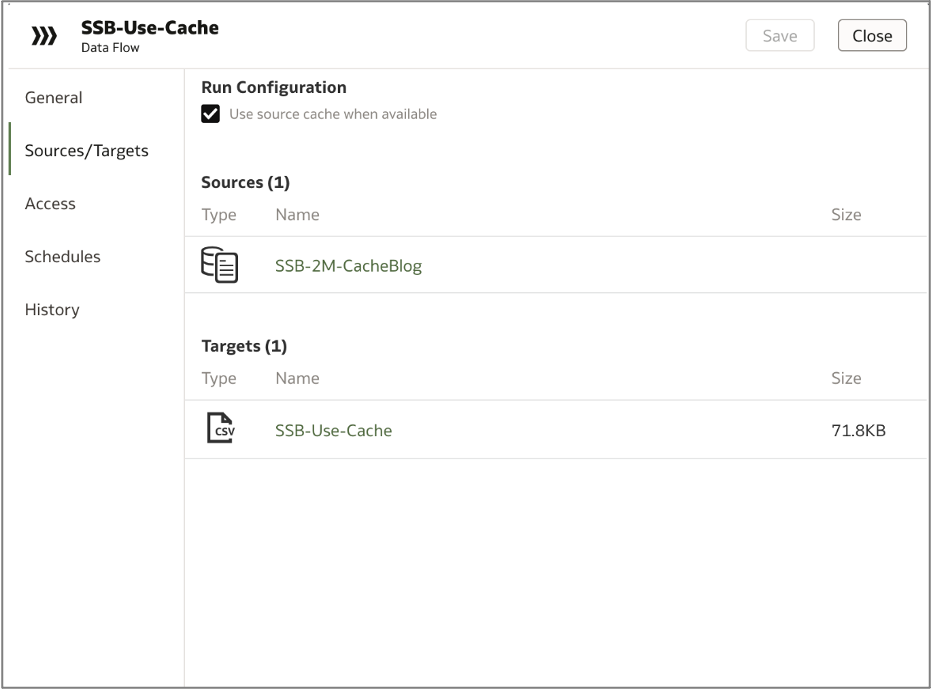
Let’s imagine we want to use this dataset in a data flow to join the data with other sources, apply additional transformations, etc. By default, the data flow will use the dataset’s cache rather than querying the live source. You can verify this in the Sources/Targets tab of the data flow Inspector—when the Use Source Cache When Available box is checked, the data flow will pull from the cache if it exists. If you’d prefer to bypass the cache, simply uncheck the box.
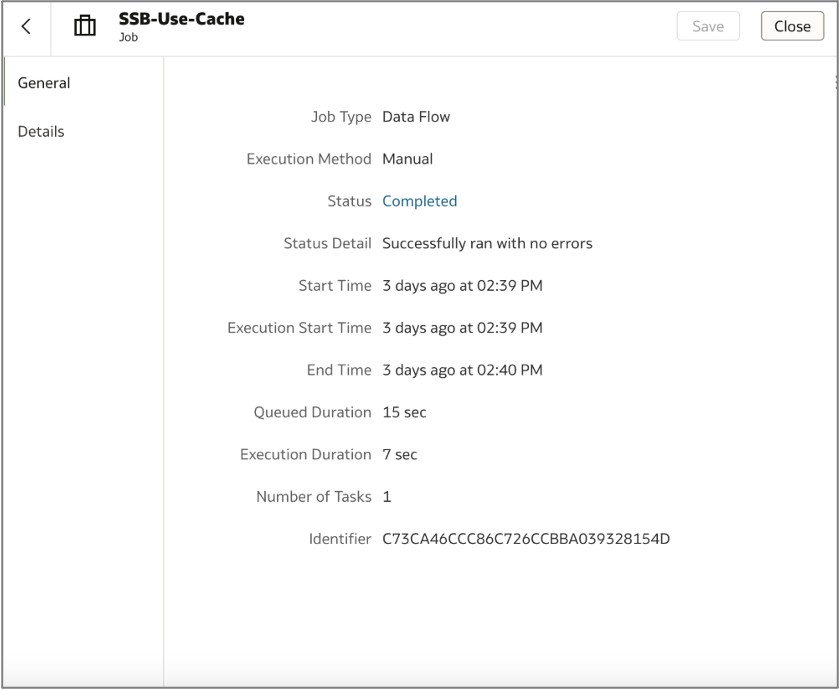
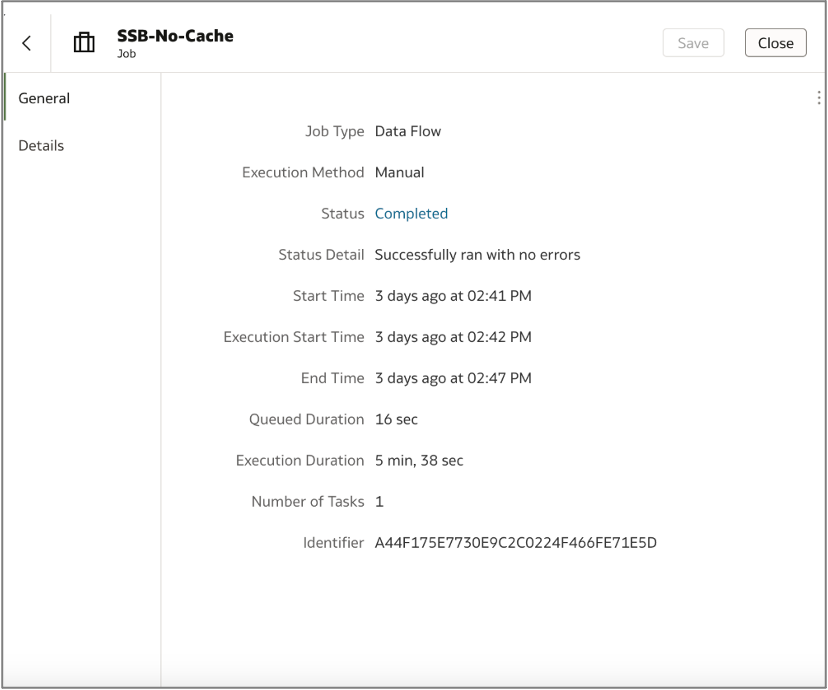
I created two data flows using the same dataset: one with caching enabled and one without. After running both, the cached data flow finished in just 7 seconds, while the flow pulling directly from the live database took 5 minutes and 38 seconds.
Additional Benefits
Using a cached dataset clearly improves performance and execution time, but the benefits go beyond speed. For example, if you’re using a data flow to fine-tune a machine learning model, it’s crucial to train and evaluate it on a consistent dataset. By relying on cache, you ensure the data remains the same for each run, preventing discrepancies that could arise if new data is added to the live source. Another key advantage of using cache is that it accommodates incrementally reloaded datasets. Rather than repeatedly pulling a full load from the live source, the cache can integrate partial updates, ensuring you always have the most up-to-date snapshot without incurring heavy resource usage. This also promotes consistency across multiple data flows: when several flows reference the same cached dataset, they all draw from the same snapshot of data, eliminating discrepancies that could arise from querying a live source at different times.
Call to Action
Caching is a powerful way to speed up your data flows and ensure consistency. By leveraging cached datasets, you minimize database load, reduce query times, and gain reliable snapshots for critical tasks like machine learning model training. However, remember to refresh the cache regularly to keep your data current. Combining data flow runs from cache with features like incremental reload can further boost overall performance. For more details on these features, check out the following resources:
Documentation: Incremental Data Reload
Documentation: Configure a Data Flow to Read Cached Data
