[Update from 4/18] OCI Data Science released AI Quick Actions, a no-code solution to fine-tune, deploy, and evaluate popular Large Language Models. You can open a notebook session to try it out. This blog post will guide you on how to work with LLMs via code, for optimal customization and flexibility.
Llama 2 is one of the most potent and most widely fine-tuned large language models (LLMs) with a license, enabling commercial use. Meta released a collection of Llama 2 pretrained and finely tuned generative text models with a parameter range spanning from 7, 13, and 70 billion. These pretrained models in Llama 2 come with substantial enhancements compared to the previous Llama1 release, including training on 40% more tokens, boasting an extended context length of up to 4,000 tokens, and various other improvements. Furthermore, the fine-tuned models within Llama 2-chat have been meticulously optimized for dialogue applications through reinforcement learning from human feedback (RLHF). This optimization sets them apart, enabling them to outperform most open models in dialogue generation.
In recent months, significant advancements have been made in the realm of fine-tuning LLMs, offering promising solutions for enterprise applications, with one of the most prominent approach the Parameter Efficient Fine-Tuning (PEFT) process. While highly potent, all-purpose language models offer immense capabilities, they can often prove excessive for the specific demands of numerous applications. For example, as seen in a blog post from anyscale if the objective involves a specialized task, the utilization of a model capable of crafting elaborate prose akin to Shakespeare is unnecessary. Deploying very large language models for such tasks is “akin to employing a space shuttle for a short cross-town commute.” Using these models can be very expensive, and often because of data security concerns, customers prefer to be in control of the model optimizations and look for opportunities to reduce the cost of the fine-tuning and deployment by utilizing smaller LLMs but tuned on specialized set of tasks.
Fine-tuning Llama 2 on OCI Data Science
In this blog post, we demonstrate a seamless process of fine-tuning Llama 2 models on multi-GPU multinode infrastructure by the Oracle Cloud Infrastructure (OCI) Data Science service using the NVIDIA A10 GPUs. For the fine-tuning operation, a single A10 with its 24-GB memory is insufficient. So, we employ multiple A10 GPUs across various VM.GPU.A10.2 instances, using PyTorch FSDP to achieve the task. Access the full scripts and tutorial from our GitHub repository.
The main challenge in running a distributed fine-tuning process is the synchronization and utilization of multiple machines at the same time, which usually must be started with specific set of configurations and sometimes in a specific order, depending on the framework used. In our example, we use the fine-tuning process as described by Meta on their Llama 2 repository. We made the running of the multinode process seamless without adding any proprietary code based on OCI Data Science and the Accelerated Data Science (ADS) Library. You can directly utilize the examples from their repository for PEFT, Fully Sharded Data Parallel (FSDP), and PEFT+FSDP training without the need to modify the code.
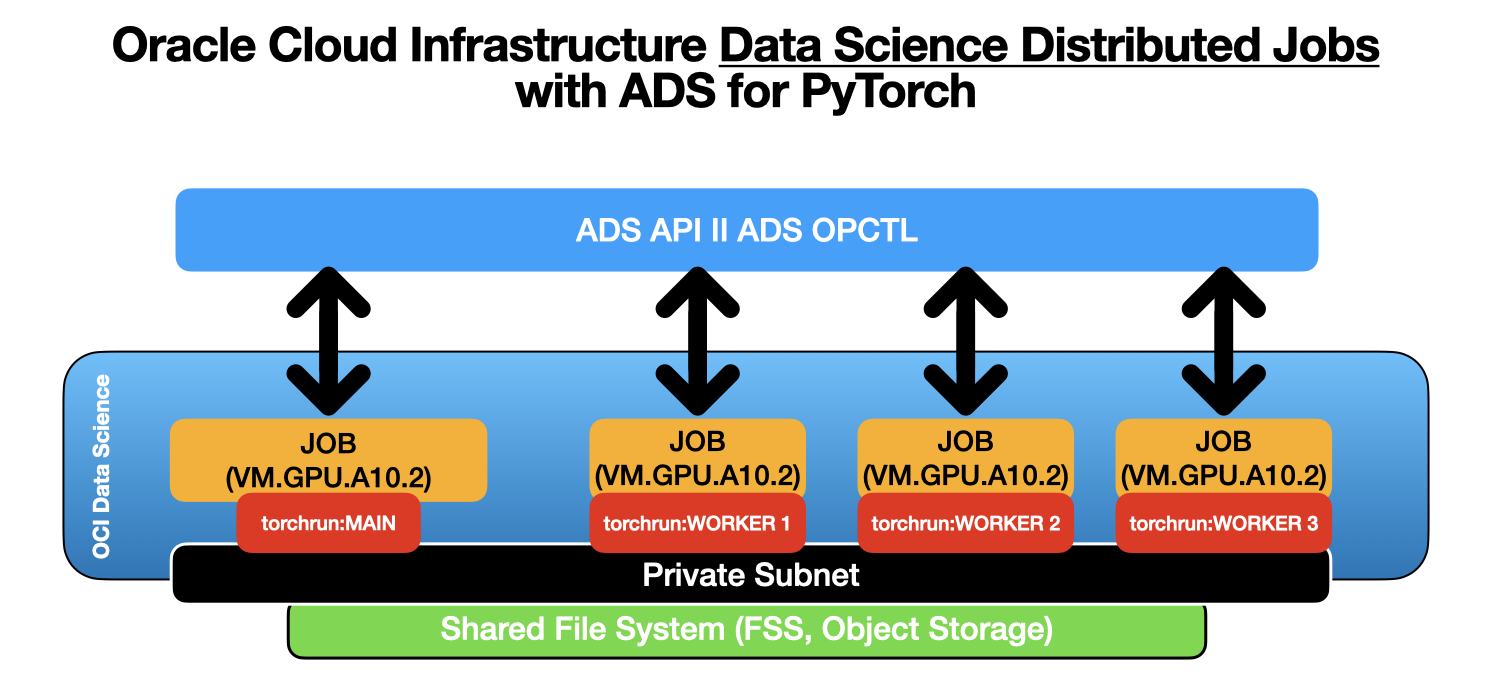
Figure 1 shows the high-level architecture representation of how the distributed training for fine-tuning runs with the help of the OCI ADS Library, utilizing the OCI Data Science jobs.
Prerequisites
Our GitHub example repo describes some key prerequisites. For more information, see Llama 2 Distributed Training and review the Prerequisites section.
Fine-tuning the Llama 2 model
We’re using OCI VM.GPU.A10.2 instances for this example. We recommend these instances because the GPU memory required for the fine-tuning must be at least four times the size of the model in full precision. Our experiments show that the actual memory consumption ends up larger when account for the memory consumption by the optimizer states, gradients, forward activations, and more. We’re also using four A10 (two VM.GPU.A10.2) instances for the 7b model, and 12 A10 (six VM.GPU.A10.2) for the 13b model. A single A10 GPU has 24GB of memory per node. Hugging Face provides a Model Memory Calculator, and check out this great article on the topic from Eleuther explaining the basic math behind the memory usage for transformers.
You can proceed with fine-tuning in one of two ways: Using the ADS Python APIs directly or creating an YAML file with the required configuration and running it with the ADS OPCTL CLI. Let’s start with the YAML approach first.
YAML
Prepare a YAML file that describes the infrastructure and the job parameters. Use the following template and customize it with the resource IDs under infrastructure block. The shape name provided should be an instance with A10 or A100.
The following YAML is an example for meta-llama/Llama-2-13b-hf fine-tuning. With six VM.GPU.A10.2 nodes, the 13b Llama2 parameter model takes about 2.5 hours to complete for three epochs. Save the YAML file as llama2-13b-hf-ft-job.yaml.
kind: job
apiVersion: v1.0
spec:
name: LLAMA2-Fine-Tuning-v13b-hf-v1
infrastructure:
kind: infrastructure
spec:
blockStorageSize: 512
logGroupId: ocid1.loggroup.<>
logId: ocid1.log.<>
subnetId: ocid1.subnet.<>
shapeName: VM.GPU.A10.2
type: dataScienceJob
runtime:
kind: runtime
type: pyTorchDistributed
spec:
git:
url: https://github.com/facebookresearch/llama-recipes.git
commit: 1aecd00924738239f8d86f342b36bacad180d2b3
command: >-
torchrun examples/finetuning.py
--enable_fsdp
--use_peft
--peft_method lora
--pure_bf16
--mixed_precision
--batch_size_training 4
--model_name $MODEL_NAME
--output_dir /home/datascience/outputs
--num_epochs 1
--save_model
replicas: 6
conda:
type: service
slug: pytorch20_p39_gpu_v2
dependencies:
pipPackages: >-
--extra-index-url https://download.pytorch.org/whl/cu118 torch==2.1.0
’accelerate>=0.21.0’
appdirs==1.4.4
loralib==0.1.2
bitsandbytes==0.39.1
datasets==2.12.0
fire==0.5.0
’git+https://github.com/huggingface/peft.git@15a013af5ff5660b9377af24d3eee358213d72d4’
’llama-recipes==0.0.1’
’transformers>=4.31.0,<4.34’
sentencepiece==0.1.99
py7zr==0.20.6
scipy==1.10.0
optimum==1.13.1
outputDir: /home/datascience/outputs
outputUri: oci://<bucket-for-finetuned-model>@<namespace>/$JOB_OCID
env:
- name: MODEL_NAME
value: meta-llama/Llama-2-13b-hf
- name: HUGGING_FACE_HUB_TOKEN
value: <your-hugging-face-token>
- name: LD_LIBRARY_PATH
value: /usr/local/nvidia/lib:/usr/local/nvidia/lib64:/opt/conda/lib
- name: OCI__METRICS_NAMESPACE
value: finetune_llama2_13b_hf_peft_loraReplace the spec variables like compartmentId, logGroupId, and logId with the one from your OCI tenancy. The outputUri should point to your OCI Object Storage bucket where the fine-tuned model is stored. Replace the <your-huggingface-token> with your token to access the Llama2 model from HuggingFace.
In this example, we set up the OCI__METRICS_NAMESPACE to closely monitor the GPU utilization with the OCI Monitoring service. The replicas specify the number of instances that are used, in our case 6xVM.GPU.A10.2, which results in 12 A10 GPUs. We used directly the finetuning.py example as provided from the Meta Llama2 repository without other configurations. So, all the fine-tuning examples in the repository work without modifications required.
To launch the distributed fine-tuning, open a terminal in your OCI Data Science notebook, install and activate a Conda environment with the latest Oracle ADS Library, and then run the ADS OPCTL CLI:
-
odsc conda install -s pytorch20_p39_gpu_v2
-
activate /home/datascience/conda/pytorch20_p39_gpu_v2
-
ads opctl run -f llama2-ft-job.yaml
When the job is submitted, six run jobs are created under the job name, Llama2-Fine-Tuning-lora-samsum-13b. Check the progress of the training by running the command, ads opctl watch <job run ocid>, in the notebook terminal.
ADS Python API
You can also run the fine-tuning process directly through the ADS Python API. The following code block shows examples for fine-tuning full parameters of the 7B model using FSDP.
from ads.jobs import Job, DataScienceJob, PyTorchDistributedRuntime
job = (
Job(name="LLAMA2-Fine-Tuning")
.with_infrastructure(
DataScienceJob()
.with_log_group_id("<log_group_ocid>")
.with_log_id("<log_ocid>")
.with_compartment_id("<compartment_ocid>")
.with_project_id("<project_ocid>")
.with_subnet_id("<subnet_ocid>")
.with_shape_name("VM.GPU.A10.2")
.with_block_storage_size(256)
)
.with_runtime(
PyTorchDistributedRuntime()
.with_service_conda("pytorch20_p39_gpu_v2")
.with_git(
url="https://github.com/facebookresearch/llama-recipes.git",
commit: "1aecd00924738239f8d86f342b36bacad180d2b3"
)
.with_dependency(
pip_pkg=" ".join([
"--extra-index-url https://download.pytorch.org/whl/cu118 torch==2.1.0",
"accelerate>=0.21.0",
"appdirs==1.4.4",
"loralib==0.1.2",
"bitsandbytes==0.39.1",
"datasets==2.12.0",
"fire==0.5.0",
"git+https://github.com/huggingface/peft.git@15a013af5ff5660b9377af24d3eee358213d72d4",
"llama-recipes==0.0.1",
"transformers>=4.31.0,<4.34",
"sentencepiece==0.1.99",
"py7zr==0.20.6",
"scipy==1.10.0",
"optimum==1.13.1"
])
)
.with_output("/home/datascience/outputs", "oci://bucket@namespace/outputs/")
.with_command(" ".join([
"torchrun examples/finetuning.py",
"--enable_fsdp",
"--pure_bf16",
"--batch_size_training 1",
"--micro_batch_size 1",
"--model_name $MODEL_NAME",
"--dist_checkpoint_root_folder /home/datascience/outputs",
"--dist_checkpoint_folder fine-tuned"
]))
.with_replica(3)
.with_environment_variable(
MODEL_NAME="meta-llama/Llama-2-7b-hf",
HUGGING_FACE_HUB_TOKEN="<access_token>",
LD_LIBRARY_PATH="/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/opt/conda/lib",
OCI__METRICS_NAMESPACE="finetune_llama2_7b_hf_peft_lora"
)
)
)Replace the IDs with the one from your tenancy, and specify the location of the bucket where the model is stored, which we highlighted in bold. To create and start running the job with the ADS Python API, run the following command:
# Create the job on OCI Data Science
job.create()
# Start a job run
run = job.run()
# Stream the job run outputs (from the first node)
run.watch()The process
Regardless of which approach you used, the distributed job runs achieve the following goals:
-
Set up the PyTorch Conda environment and install other dependencies.
-
Fetch the source code from GitHub and checkout the specific commit.
-
Run the training script with the specific arguments, which includes downloading the model and dataset.
-
Save the outputs to OCI Object Storage when the training finishes.
In the torchrun training command, you don’t need to specify the number of nodes or the number of GPUs and the IP address of the main job. ADS automatically configures those bases on the replica and shape you specified, as shown in Figure 2.
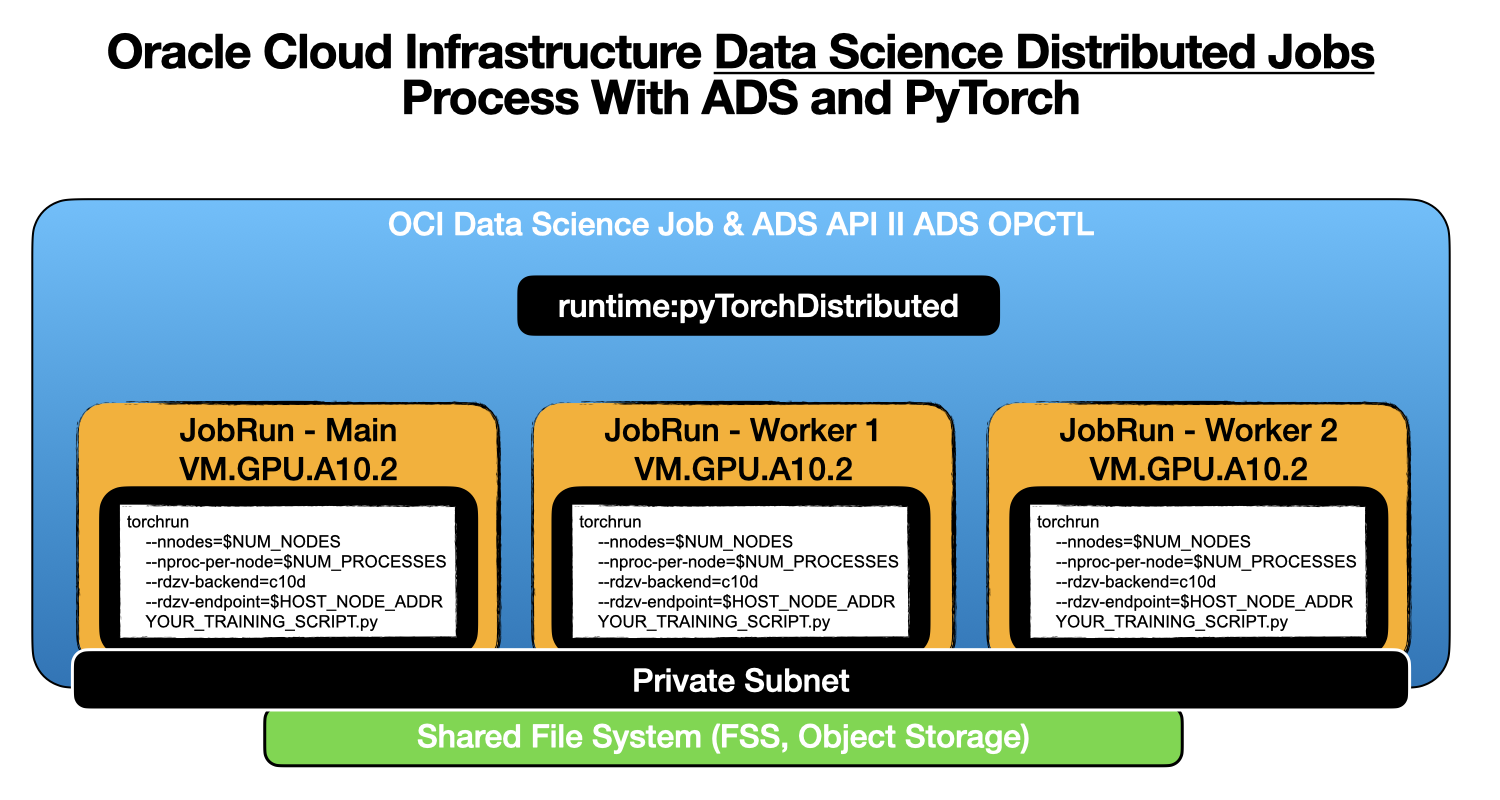
The fine-tuning uses the default dataset. You can also add your custom datasets. You can find a description of how to use your own dataset and how to add custom datasets in Dataset.md. The same training script also supports PEFT. You can change the command to the following for PEFT with LoRA, for example:
torchrun examples/finetuning.py --enable_fsdp --use_peft --peft_method lora \
--pure_bf16 --batch_size_training 1 --micro_batch_size 1 \
--model_name /home/datascience/llama --output_dir /home/datascience/outputs
Merge the fine-tuned model
After the fine-tuning process is complete, to test the new model, we must merge the weights to the base model and upload to the OCI Data Science Model Catalog. For detailed information, check this GitHub script.
-
Create a notebook session with the VM.GPU.A10.2 shape or higher. Specify the object storage location where the fine-tuned weights are saved in the mount path while creating the notebook session.
-
Upload the lora-model-merge.ipynb notebook to the notebook session.
-
Run the notebook for verifying and merge the fine-tuned weights.
-
The notebook example has code to upload the fine-tuned model to OCI Data Science Model Catalog.
FSDP weight merging
For merging FSDP weights, use the following steps:
-
Create a notebook session with VM.GPU.A10.2 shape or higher. Specify the object storage location where the fine-tuned weights are saved in the mount path while creating the notebook session.
-
Upload the load-back-FSDP-checkpoints.ipynb notebook to the notebook session and follow the instructions.
Deployment
We recommend using the vLLM-based inference container for serving the fine-tuned model. vLLM offers various optimizations for efficient usage of GPU and offers good throughput out of the box. For more information, check our blog post on deploying Llama2 on OCI Data Science and our deployment example on our GitHub repository.
Conclusion
With effortless multi-GPU, multinode fine-tuning with Llama2, the OCI Data Science service makes it easy to harness the potential of large open language models. It provides a robust, scalable, and secure approach without the need for proprietary code. Leveraging the intuitive Oracle ADS Library, fine-tuning and deployment become seamless, all powered by the high-performance, scalable GPUs on OCI.
In future posts, we demonstrate how to fine-tune the 70b Llama2 model with NVIDIA A10 GPUs.
Try Oracle Cloud Free Trial! A 30-day trial with US$300 in free credits gives you access to Oracle Cloud Infrastructure Data Science service. For more information, see the following resources:
-
Full sample, including all files in OCI Data Science sample repository on GitHub.
-
Visit our service documentation.
-
Try one of our LiveLabs. Search for “data science.”
-
Got questions? Reach out to us at ask-oci-data-science_grp@oracle.com


