Text-to-SQL, (also referred to as NL2SQL) refers to a system that generates SQL queries from text-based instructions. This can be achieved using generative AI models and agentic workflows. It offers numerous benefits in the real world, allowing organizations to harness the power of data in relational databases (DBs) more efficiently, gain valuable insights, and develop workflows that would otherwise demand extensive manual processes. The fundamental concept is shown in Figure 1.
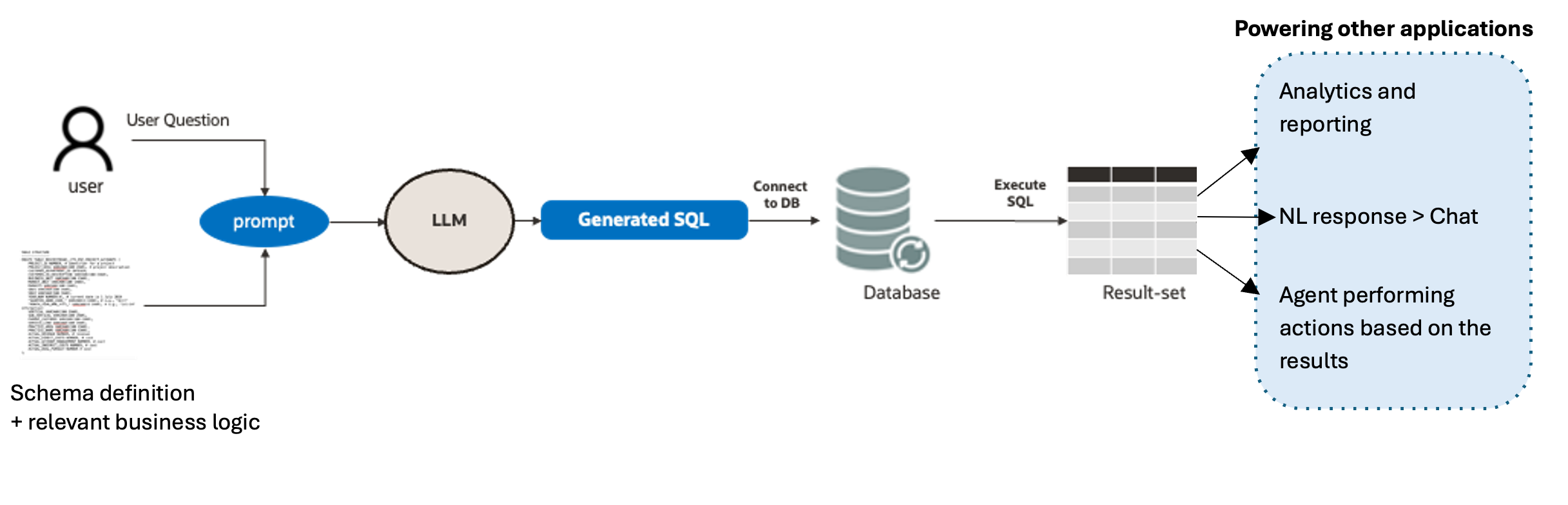
The field of Generative AI and Large Language Models (LLMs) has seen significant advancements in the recent years, However, when it comes to SQL generation for real world applications, specific challenges arise that highlight the inadequacy of relying solely on a single LLM call for Text-to-SQL generation, which can result in potential inaccuracies. Some of these challenges are as follows.
Challenges
Unclear schema details
The names of tables and columns may lack clarity. The same field may be referred to by different names in different tables. A description of the columns and tables in such cases may be required to provide the models with the necessary context to understand the data better.
Large schemas
Some database setups comprise a large number of tables which then require the selection of relevant tables for generating SQL and/or multiple table-JOINs to answer basic user queries. Additionally, there could be hundreds or even thousands of columns, which significantly increases the complexity of the problem. The challenges also include the context window limits of LLMs and their ability to retrieve relevant information to address user questions.
Unclear context for joining tables
A user who is familiar with the business and DB may be aware of the required table join constraints. It may not be obvious to the LLM from just the schema definition, and additional context may be required for it to produce the desired output.
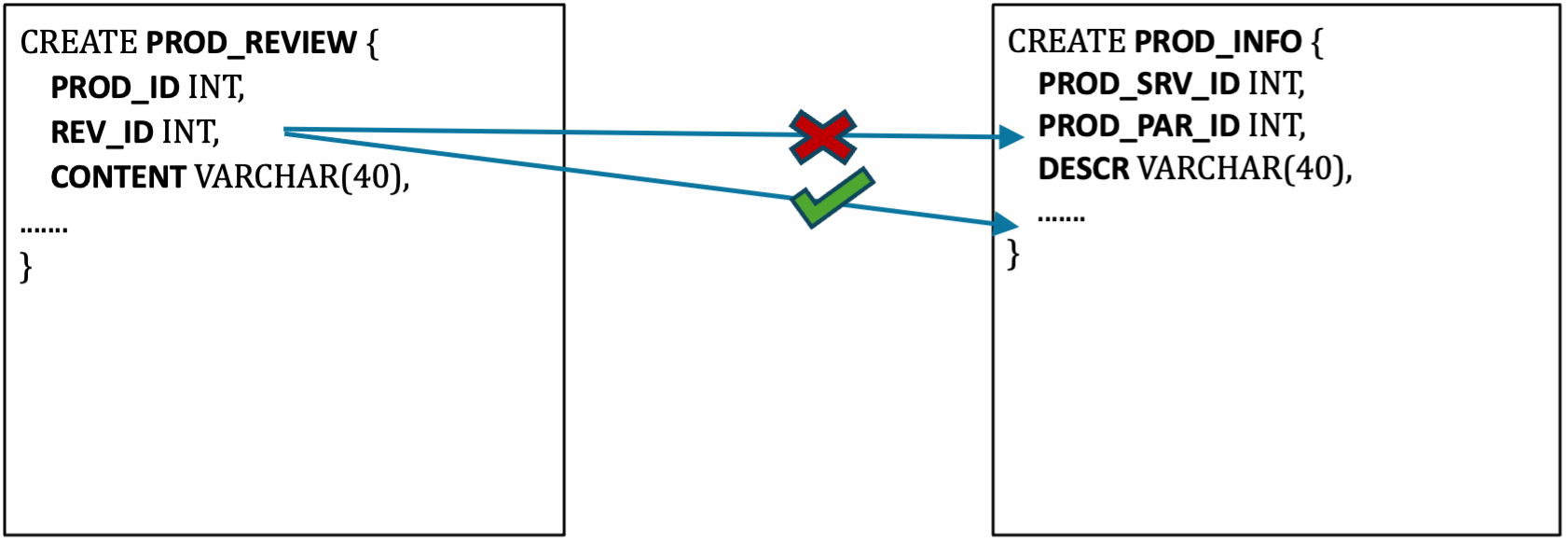
Requiring data manipulations
In some instances, the existing columns might not provide the user with the desired outcome directly, thus necessitating various manipulations for queries to retrieve the correct information.
For instance, let’s consider a table called “ProductInformation” that stores information about various products in an e-commerce database. The table includes two columns: ProductID (unique identifier for each product) and ProductDescription (a string that contains various information about the product, including its features, color, size, material, etc.). Here’s an example of what the table might look like:
| ProductID | ProductDescription |
| 1 | “Laptop, 15.6 inches, Intel Core i7, 16 GB RAM, 512 GB SSD, Color: Silver, Material: Aluminum” |
| 2 | “Smartphone, 6.1 inches, Quad Camera, 12 GB RAM, 128 GB Storage, Color: Space Gray, Material: Glass” |
| 3 | “Tablet, 10.1 inches, Quad Core Processor, 4 GB RAM, 64 GB Storage, Color: White, Material: Plastic” |
Now, let’s say a user wants to query the database to find all products that have a screen size greater than 14 inches, have at least 8 GB of RAM, and are made of a material that is not plastic.
To answer this query, we would need to manipulate the ProductDescription column to extract the relevant information. This includes extracting the screen size and RAM size from the ProductDescription column using a regular expression, and converting it to a numeric value for comparison, checking if the material is not plastic using a regular expression to search for the word “Plastic” in the ProductDescription column and negating the result. Here’s an example of what the query might look like:
SELECT ProductID, ProductDescription
FROM ProductInformation
WHERE
CAST(REGEXP_SUBSTR(ProductDescription, '[0-9.]+ inches') AS DECIMAL) > 14
AND CAST(REGEXP_SUBSTR(ProductDescription, '[0-9]+ GB RAM') AS DECIMAL) >= 8
AND ProductDescription NOT LIKE '%Material: Plastic%';
For some businesses and applications, this may be a task that needs to be repeated across queries made against the DB. The generation of more complex queries, which demand custom logic and knowledge, heightens the likelihood of the LLM underperforming with other pertinent details in the query.
Missing business logic context
Certain words may be custom to a business, domain, or application. A model may not inherently know all of these, which means some more input would need to be added to model’s context for it to be able to more appropriately answer user questions.
Example: “How many superusers visited the showroom in 2023?”
What is superuser and how to define it, especially if that’s not clear from the schema?
Ambiguity in user question
Let’s consider an example where the user question is “what is the company’s revenue?”, and the database includes multiple companies. Which company the user is referring to presents ambiguity. Without further context, the task is open to the LLM’s interpretation, and without it clearly defined, the LLM may assume a different definition of “the company” in different questions, or try to query a column or term that is not present in the DB. Additionally ‘revenues’ may be a derived attribute from existing columns, and the LLM might not know how to compute it.
Complexity of conversational applications
A chat-based system where you can converse with your DB has many components working behind the scenes, from SQL generation to DB execution, as well as framing the answer appropriately in natural language to answer the user’s question. These systems may additionally require the system to remember the context of past conversations in the same chat, thereby increasing the context the system must remember. Furthermore, in these applications, detecting query inaccuracies can be challenging, as the model might generate an executable query that is logically flawed. The issue arises because the final answer is converted to text before the user sees it, which could appear legitimate on the surface, even if the query is incorrect.
Solutions
A misinterpretation or underperformance at any stage of the system can render the application less useful, as reliability and accuracy are paramount to trust such a system. Some solutions for addressing these challenges are as follows:
Improved LLMs
New LLMs and development in the field are yielding models less prone to some of the challenges described above. With time, more improvements can be expected.
Human-in-the-loop
Given so many pieces that fit into the task of SQL generation and how dependent it is on the DB setup, it is important for someone with the knowledge of the DB and the business to review the outputs, correct where needed, and for this feedback to be sent back to the system for further improvements.
Schema selection
Especially when the schema is too large, filtering down the tables and columns relevant to a user question and only sending this filtered schema to the LLM helps keep the context limited while removing unnecessary noise/potential confusion elements.
Business logic curation and selection
It is important to know about any special definitions and requirements relevant to the business and the application. A process for curating these from the user, inferring these from past interactions, and then filtering down the relevant business logic statements to pass to the LLM along with the schema can help limit context and add relevant information for the LLM to do its job with better chances of doing well.
Disambiguation
Detection of any ambiguity and seeking clarifications from the end user can provide the system with the context it needs to produce a successful SQL query.
Creating views where applicable
Creating views can be helpful in cleaning up ambiguous DBs and precomputing any columns or new fields that are required repeatedly. This also helps reduce the query execution time and helps by having fewer complexities for the LLM to navigate.
Logging
It is useful to preserve question-query pairs during the experimentation process. The absence of such data is a prevalent issue when initiating the development of Text-to-SQL systems. By retaining logs of these pairs, one can construct a robust test dataset and explore the possibility of employing some of the data as few-shot examples within the prompt. This approach facilitates continuous enhancement and refinement of the SQL generation process.
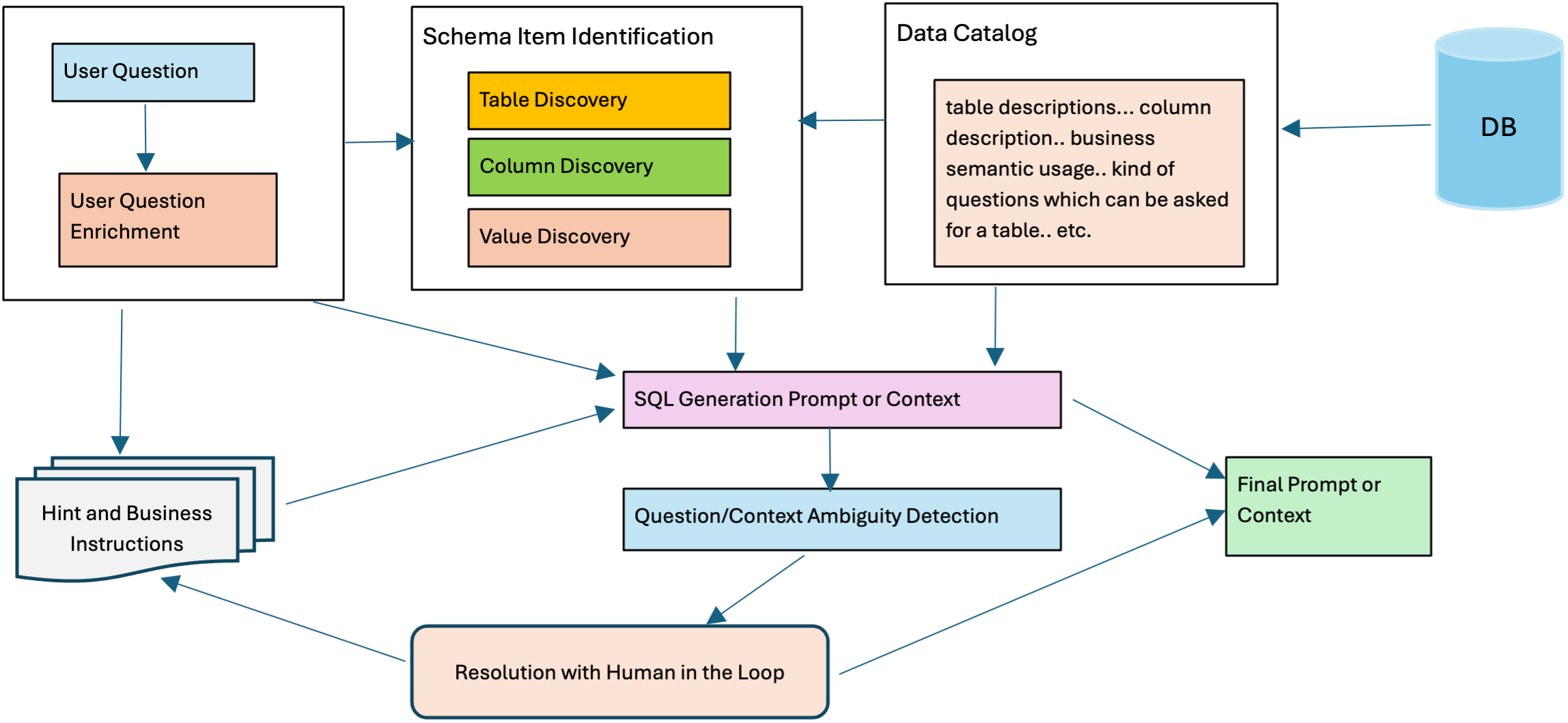
The implementation of Text-to-SQL systems can transform the way companies engage with their databases, but their effectiveness is currently limited by the intricacies of corporate data, and its setup and usage. However, as Generative AI continues to evolve, substantial enhancements to this technology are anticipated. Overcoming the obstacles to successful Text-to-SQL system deployment requires recognizing the challenges and driving the development of solutions that prioritize accuracy, dependability, and trust.
At Oracle, we are not only building services and products to enable seamless implementation of such applications but also understand the gaps in technology and are actively working towards bridging them.
Try Oracle Cloud Free Trial, a free 30-day trial with US$300 in credits. For more information, see the following resources:



