しばちょう先生の試して納得!DBAへの道 indexページ▶▶
みなさん、こんにちは。しばちょう”こと柴田長(しばた つかさ)です。本年もよろしくお願いいたします。

贅沢にも年末年始に少し長いお休みを頂きまして気持ち良く出社してみたものの、パスワードを度忘れして会社PCにログイン出来ず、大量の冷や汗から始まった2014年です。皆様はいかがお過ごしでしょうか?
さて、今年初めに取り上げる機能はパーティションとなります。非常に良く使用されているオプション機能なのでベテランDBAの方々にとっては今更感があるかと予想されますが、本連載のタイトルにも含まれている「DBAへの道」を通る上でも必須な機能ですから、Oracle Database 11gで追加されたパーティションの新機能の紹介やこれまでの記事の復習も兼ねて、パーティション機能の魅力について複数回に渡って紹介させて頂きたいと考えています。
まず今回は、パーティション化による非常に大きなメリットである、パーティション・プルーニングによる問合せのパフォーマンス向上を体験して頂きたいと思います。以下の演習をOracle Database 11g Release 2 Enterprise Editionのデータベースで試してみてください。
1. 次のSQLを実行し、約1200MB(一ヵ月100MBの12ヶ月分)のレコードが格納されている表TAB25を作成してください。
$ sqlplus / as sysdba
SQL> -- TBS25表領域と、この表領域をデフォルト表領域とするTRYユーザーの作成
create tablespace TBS25 datafile '+DATA(DATAFILE)' size 2520m ;
create user TRY identified by TRY default tablespace TBS25 ;
grant connect, resource, dba to TRY ;
SQL> -- TAB25表の作成とデータ・ローディング
connect TRY/TRY
create table TAB25 (COL1 number not null, COL2 date, COL3 number, COL4 char(2000)) ;
insert /*+append */ into TAB25
select LEVEL,
to_date('2014/01/01','YYYY/MM/DD') + mod(LEVEL, 365),
dbms_random.value(1,100),
'hoge'
from DUAL connect by LEVEL <= 3 * 128 * 1200 ;
commit;
create unique index IDX_TAB25_COL1 on TAB25(COL1) ;
alter table TAB25 add primary key (COL1) using index ;
SQL> --TAB25表に格納されているレコードのCOL2列の最小日付、最大日付を確認
alter session set NLS_DATE_FORMAT='YYYY/MM/DD' ;
select min(COL2),max(COL2) from TAB25 ;
MIN(COL2) MAX(COL2)
---------- ----------
2014/01/01 2014/12/31
SQL> -- TRYスキーマ内のセグメント・サイズを確認
set linesize 150 pagesize 50000
col SEGMENT_NAME for a12
col PARTITION_NAME for a16
col TABLESPACE_NAME for a16
select SEGMENT_NAME, PARTITION_NAME, SEGMENT_TYPE, TABLESPACE_NAME, BYTES/1024/1024
from USER_SEGMENTS
where SEGMENT_NAME = 'TAB25' ;
SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE TABLESPACE_NAME BYTES/1024/1024
------------ ---------------- ------------------ ---------------- ---------------
TAB25 TABLE TBS25 1216
毎度お馴染みの準備運動となりますが、まずは通常表(非パーティション表)であるTAB25表を作成して頂きました。
TAB25表のCOL2列はDATE型としており、12ヶ月分のデータを生成している点は連載で初めてかもしれませんね。今回のINSERT文では「to_date(‘2014/01/01′,’YYYY/MM/DD’)」をベース日付として、「mod(LEVEL, 365)」の計算結果の日数を加えることで、12ヶ月分=365日分のデータを作成しています。LEVELには0~460800(=3x128x1200)の値が順番に入ってくるので、その値を365で割った際の余りが「mod(LEVEL, 365)」の結果として0~364となります。結果、COL2列のデータとしては、2014/01/01 ~ 2014/12/31までの日付が格納されていることが上記の回答例でも確認できていますよね。
ちなみに、何故460800(=3x128x1200)としたのかを簡単にご紹介しておきます。データブロックのサイズは8KB、TAB25表の列定義から一つのレコードは約2100バイト程度だと予想できるので、一つのブロックには 3 レコードが含まれることになります。次に、8KBのブロックが 128 個集まると1MBになります。1MBの固まりが 1200 個で1200MBとなりますからね。
2. TAB25表に格納されている2014年9月分のレコードのCOL3の合計値を求めるSELECT文を実行して、実行時間を測定してください。
$ sqlplus /nolog
SQL> connect / as sysdba
alter system flush buffer_cache ;
alter system flush shared_pool ;
SQL> connect TRY/TRY
set timing on
select /* practiceSQL */ sum(COL3) from TAB25
where COL2 >= to_date('2014/01/01','YYYY/MM/DD')
and COL2 < to_date('2014/02/01','YYYY/MM/DD') ;
SUM(COL3)
----------
1977798.69
Elapsed: 00:00:10.36
いかがでしょうか?私の環境では約10秒程度で結果が戻ってきていますね。
演習問題にある「2014年9月分のレコード」とは、日付型であるCOL2列の値が”2014/01/01 00:00:00″以上、かつ、”2014/02/01 00:00:00″未満の範囲に含まれるレコードを意味していることを理解できれば、SELECT文のWhere句の条件はそれほど難しくありませんよね?文字列を日付型へ変換するTO_DATE関数を使用することを忘れないように注意しましょう。
これだけでは面白くありませんので、次の演習2では少しだけ復習をしてみましょう。
3. 演習2で実行したSELECT文について、リアルタイムSQL監視のアクティブ・レポートを生成して下さい。
$ sqlplus / as sysdba
SQL> -- 対象SELECT文のSQL_IDを確認
set pagesize 100 linesize 120
col SQL_TEXT for a80
select SQL_ID, CHILD_NUMBER, SQL_TEXT
from V$SQL
where SQL_TEXT like 'select /* practiceSQL */ sum(COL3) from TAB25 %' ;
SQL_ID CHILD_NUMBER SQL_TEXT
------------- ------------ -----------------------------------------------------
7w1mh76rwvp56 0 select /* practiceSQL */ sum(COL3) from TAB25
where COL2 >= to_date('2014/01/01','YYYY/MM/DD')
and COL2 < to_date('2014/02/01','YYYY/MM/DD')
SQL> -- リアルタイムSQL監視のアクティブ・レポートの生成
set linesize 1000
set long 1000000
set longchunksize 1000000
set head off
spool sqlmon_active.html
select dbms_sqltune.report_sql_monitor(sql_id=>'7w1mh76rwvp56', type=>'active') from dual;
spool off
さて、覚えておりましたでしょうか?さらっと実行出来た方は私の連載など意味がないかもしれませんよ。。。忘れてしまっていた方は、このタイミングで復習してみてくださいね。リアルタイムSQL監視のアクティブ・レポートの生成方法については、第6回の連載でご紹介しています。
次が私の環境で生成したアクティブ・レポートとなりますので、ここで確認しておいて頂きたいポイントだけ抑えておきましょう。
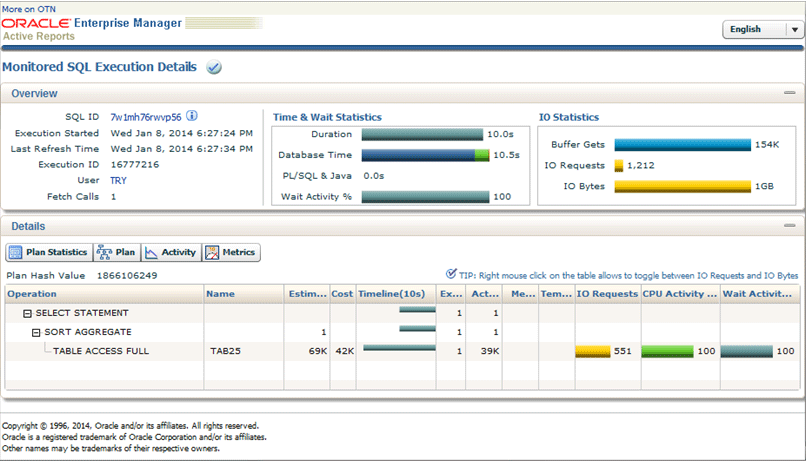
まず確認する部分としては、SQLの実行時間です。上段真ん中の「Time & Wait Statistics」枠の「Duration」の値が10.0sとなっていますので、SQL*Plusで確認した実行時間とほぼ一致します。また、「Database Time」部分でDatabase内での処理において、CPU時間とI/O時間の比率を確認することが可能です。青帯がI/O時間、緑帯がCPU時間です(皆さんのレポートでマウスを載せればコメント表示されます)ので、10秒間の約9割はディスクI/Oに要した時間と言う事が理解できます。
次に、どのような処理において、どのオブジェクトを、どの程度の量、ディスクI/Oしていたのか?を確認してみましょう。
SQL実行計画としては、TAB25表に対する全表スキャンであるオペレーション「TABLE ACCESS FULL」があることが特徴です。また、SQLを実行する直前にバッファ・キャッシュのフラッシュを実行しておいたので、全表スキャンによってTAB25表の全ブロック(約1200MB)をディスクから読み込んだことになります。これを示しているのが、右上の「IO Statistics」内の「IO Bytes」の「1GB」となります。少し誤差がありますが、セグメントの後方に並んでいるレコードが一件も格納されていない空のブ ロック(High Water Mark : HWM以降のブロック)が読み込まれなかった為と推測されます。
つまり、大雑把に表現してしまうと、TAB25表の1GBの全データを読んで集計する為に10秒要したという事になります。しかし、ここでSELECT文のWhere句の条件を思い出してください。2014年9月という一ヶ月分に限定していましたよね?それにも関わらず、一年間分の1GBをディスクIOすることは、何となく非効率だと思いませんか?
とは言え、この状態では、どうしようも無いことが事実です。前提としてOracle DatabaseがディスクI/Oを行う最小単位はデータブロックですよね。これは以前にもご紹介してあると思います。そして、ある任意のデータブロック内を想像してみてください。そのブロックには複数のレコードが格納されていますが、それらのレコードが何月分のレコードなのかは、実際にデータブロックの中身を読んでみないと解りませんよね?だから、とりあえず全部ディスクから読んでみて、9月分のレコードだけを抽出するしかないのです。
少し難しい解説となってしまいましたが、ここまでを理解して頂ければ、以降で体験して頂くパーティションのメリットについて心の底から感動して頂ける(?)と思っています!いよいよ、次の演習4からパーティションが登場します。
4. 表のオンライン再定義を使用して、表TAB25を次の条件に従ってパーティション化して下さい。
条件:日付型データが格納されているCOL2列をパーティション化キーとした月単位の時間隔パーティション化
$ sqlplus TRY/TRY
SQL>
-- オンライン再定義の実行可否の確認
BEGIN
DBMS_REDEFINITION.CAN_REDEF_TABLE('TRY', 'TAB25', DBMS_REDEFINITION.CONS_USE_PK, NULL);
END;
/
-- データ移行先となる仮表(時間隔パーティション表)の作成
create table TAB25_TMP (COL1 number not null, COL2 date, COL3 number, COL4 char(2000))
partition by range(COL2) interval(NUMTOYMINTERVAL(1, 'month'))
(partition P201401 values less than (to_date('2014/02/01', 'YYYY/MM/DD'))) ;
create unique index IDX_TAB25P_COL1_COL3 on TAB25_TMP(COL1, COL2) local ;
alter table TAB25_TMP add primary key(COL1, COL2) using index ;
-- オンライン再定義によるレコードのコピーを開始
BEGIN
DBMS_REDEFINITION.START_REDEF_TABLE(
uname => 'TRY',
orig_table => 'TAB25',
int_table => 'TAB25_TMP',
options_flag => DBMS_REDEFINITION.CONS_USE_PK);
END;
/
-- オンライン再定義による依存オブジェクトのクローニングを開始
/* 今回は省略*****
DECLARE
num_errors PLS_INTEGER;
BEGIN
DBMS_REDEFINITION.COPY_TABLE_DEPENDENTS(
uname => 'TRY',
orig_table => 'TAB25',
int_table => 'TAB25_TMP',
ignore_errors => TRUE,
num_errors => num_errors);
END;
/
***** */
-- オンライン再定義によるレコードの差分同期を実行
BEGIN
DBMS_REDEFINITION.SYNC_INTERIM_TABLE('TRY', 'TAB25', 'TAB25_TMP');
END;
/
-- オンライン再定義の完了処理(表名の付け替え)
BEGIN
DBMS_REDEFINITION.FINISH_REDEF_TABLE('TRY', 'TAB25', 'TAB25_TMP');
END;
/
通常一つの表は一つの入れ物のように扱われますが、パーティション表とは一つの表の中で複数の入れ物が存在するイメージです。その複数の入れ物をパーティションと呼び、各レコードの単一、もしくは複数の列データの値によって、格納先のパーティションを決定していきます。また、時間隔パーティションとは、従来からあるレンジ・パーティションのデメリットであった「DBAによるパーティションの手動追加作業」を「必要に応じてOracle Databaseが自動的に追加してくれる」ようにパーティション範囲の間隔を定義しておくレンジ・パーティションになります。DDL文を見て理解してみましょう。
create table TAB25_TMP (COL1 number not null, COL2 date, COL3 number, COL4 char(2000)) partition by range(COL2) interval(NUMTOYMINTERVAL(1, 'month')) (partition P201401 values less than (to_date('2014/02/01', 'YYYY/MM/DD'))) ;
緑文字の部分がパーティションの種類と、どの列の値(パーティション化キー)を元に格納先パーティションを決めるのかが定義されています。上記ではRANGE(値の範囲で分割)というパーティションの種類で、パーティション化キーはCOL2列と言う事になります。
赤文字部分のINTERVAL句が時間隔パーティションの「パーティション範囲の間隔を定義」しており、上記ではNUMTOYMINTERVAL関数を使用して1ヶ月間隔でパーティションが区切られるように指定しています。
最後の青文字部分は、起点となる一つ目のパーティションを定義しています。上記では「2014年2月1日よりも小さい日付」という範囲が指定されたパーティションP201401を作成しています。このパーティションP201401には、COL2列の値が「2014年2月1日よりも小さい日付」のレコードだけ、つまり、1月分のレコードだけが格納されることになります。
説明の順序的に非常に難しくなってしまい申し訳ないですが、現時点では何となくのイメージで良いと思います。以降の演習も含めて少しずつ明らかにしてきたいと考えています。もちろんマニュアルを参照頂いても良いと思います。今回の対象としては「VLDBおよびパーティショニング・ガイド」の「2パーティション化の概念」、「時間隔パーティション化」が良いと思います。
ちなみに、今回の回答例のように「表のオンライン再定義」を使用すれば、簡単に非パーティション表をパーティション化することが可能ですので、是非とも身につけておいて欲しい方法となります。第18回の連載にて体験して頂いているので、そちらも復習しておいて頂けると良いでしょう。
5. USER_PART_TABLESビューでパーティション表TAB25の情報を確認し、さらにUSER_PART_KEY_COLUMNSビューにおいてパーティション化キーの列名を確認してください。
$ sqlplus TRY/TRY SQL> set linesize 150 col TABLE_NAME for a10 col INTERVAL for a32 select TABLE_NAME, PARTITIONING_TYPE, PARTITION_COUNT, PARTITIONING_KEY_COUNT, INTERVAL from USER_PART_TABLES where TABLE_NAME = 'TAB25' ; TABLE_NAME PARTITION PARTITION_COUNT PARTITIONING_KEY_COUNT INTERVAL ---------- --------- --------------- ---------------------- -------------------------------- TAB25 RANGE 1048575 1 NUMTOYMINTERVAL(1, 'MONTH') col COLUMN_NAME for a24 select * from USER_PART_KEY_COLUMNS where NAME = 'TAB25' and OBJECT_TYPE = 'TABLE' ; NAME OBJEC COLUMN_NAME COLUMN_POSITION ------------------------------ ----- ------------------------ --------------- TAB25 TABLE COL2 1
この演習は、特に問題無いと思います。各種パーティション表の情報を確認していきましょう。
まずは、演習3で作成したパーティション表が正しく定義されているのかについて、USER_PART_TABLESビューでパーティションの種類やINVERVAL句で指定した範囲の間隔を確認してみましょう。問題無いですよね?ただ、このビューでは、どの列がパーティション化キーであるのかは分からない為、USER_PART_KEY_COLUMNSビューへの問合せが必要になります。
一点だけ補足しておくと、USER_PART_TABLESビューでは、パーティション表に含まれるパーティション数を確認できるPARTITION_COUNT列が存在するのですが、非常に大きな値「1048575」が出力されています。結論から言えば、TAB25表は12ケ月分、つまり12個のパーティションしか保持していない(これについては以降の演習で確認)ので、この値は正しくありません。恐らく、今回作成したパーティション表が時間隔パーティションであった為であると推測されますので、この値の扱いには注意が必要そうですね。
6. パーティション表TAB25に所属するセグメント数と各セグメントのサイズを確認してください。
$ sqlplus TRY/TRY SQL> set linesize 150 pagesize 50000 col SEGMENT_NAME for a12 col PARTITION_NAME for a16 col TABLESPACE_NAME for a16 select SEGMENT_NAME, PARTITION_NAME, SEGMENT_TYPE, TABLESPACE_NAME, BYTES/1024/1024 from USER_SEGMENTS where SEGMENT_NAME = 'TAB25' ; SEGMENT_NAME PARTITION_NAME SEGMENT_TYPE TABLESPACE_NAME BYTES/1024/1024 ------------ ---------------- ------------------ ---------------- --------------- TAB25 P201401 TABLE PARTITION TBS25 104 TAB25 SYS_P101 TABLE PARTITION TBS25 96 TAB25 SYS_P102 TABLE PARTITION TBS25 104 TAB25 SYS_P103 TABLE PARTITION TBS25 104 TAB25 SYS_P104 TABLE PARTITION TBS25 104 TAB25 SYS_P105 TABLE PARTITION TBS25 104 TAB25 SYS_P106 TABLE PARTITION TBS25 104 TAB25 SYS_P107 TABLE PARTITION TBS25 104 TAB25 SYS_P108 TABLE PARTITION TBS25 104 TAB25 SYS_P109 TABLE PARTITION TBS25 104 TAB25 SYS_P110 TABLE PARTITION TBS25 104 TAB25 SYS_P111 TABLE PARTITION TBS25 104
セグメントの情報なので、やはりUSER_SEGMENTSビューでしょう。改めてUSER_SEGMENTSビューで用意されている列名を確認して頂ければ、「PARTITION_NAME」という名称の列が存在していることに気付いたのではないでしょうか?
上記の実行結果からは、「TAB25」という名前のセグメントが12個も存在していますが、各セグメントのPARTITION_NAMEが異なる点が確認できたかと思います。そうなのです。通常の表(非パーティション表)は一つのセグメントで構成されていましたが、パーティション表は複数のセグメントで構成されるオブジェクトなのです。そして、各セグメントはパーティションと1対1で紐づいている点も重要ですね。このように各種ビューを確認していけば、私の下手な解説を読まなくても理解が一気に進んでいくと思います。
また、今回の演習シナリオでは、約1200MBの非パーティション表を1ヶ月単位で計12個のパーティションに分割したことになるので、各パーティションのセグメントは約100MB前後の値となっているのも興味深いですよね。しかし、パーティション表を作成する際に自分で命名したパーティション名である「P201401」に関しては、2014年1月分のレコードが格納されるパーティションだと理解出来ますが、それ以外のパーティション名は時間隔パーティションによって自動的にOracle Databaseが追加したパーティションの為、「SYS_P***」と命名されてしまい、何月分のレコードが格納されるパーティションなのかが解りませんね。と言う事で、次の演習7を体験してみてください。
7. USER_TAB_PARTITIONSビューへ問合せて、時間隔パーティション表TAB25に所属する各パーティションの範囲の定義を確認してください。
$ sqlplus TRY/TRY
SQL>
set linesize 150 pagesize 50000
col TABLE_NAME for a5
col PARTITION_NAME for a8
select TABLE_NAME, PARTITION_NAME, HIGH_VALUE
from USER_TAB_PARTITIONS
where TABLE_NAME = 'TAB25' ;
TABLE PARTITIO HIGH_VALUE
----- -------- --------------------------------------------------------------------------------
TAB25 P201401 TO_DATE(' 2014-02-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
TAB25 SYS_P101 TO_DATE(' 2014-03-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
TAB25 SYS_P102 TO_DATE(' 2014-04-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
TAB25 SYS_P103 TO_DATE(' 2014-05-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
TAB25 SYS_P104 TO_DATE(' 2014-06-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
TAB25 SYS_P105 TO_DATE(' 2014-07-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
TAB25 SYS_P106 TO_DATE(' 2014-08-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
TAB25 SYS_P107 TO_DATE(' 2014-09-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
TAB25 SYS_P108 TO_DATE(' 2014-10-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
TAB25 SYS_P109 TO_DATE(' 2014-11-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
TAB25 SYS_P110 TO_DATE(' 2014-12-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
TAB25 SYS_P111 TO_DATE(' 2015-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
はい、確認出来ましたね。USER_TAB_PARTITOINSビューには「HIGH_VALUE」という列があり、各パーティションに格納される最大値(パーティション化キー列の最大値)を確認することが可能です。
上記の例では、パーティション「SYS_P101」には、COL2列の値が2014年3月1日よりも小さいレコードが可能されることが解ります。ただし、2014年2月1日よりも小さいレコードは、パーティション「P201401」に格納されることになるので、パーティション「SYS_P101」に格納されるレコードは、2014年2月分のレコードと言う事になりますね。
また、COL2列の値が2015年1月1日よりも小さなレコードであれば、いずれかのパーティションに格納することができますが、2015年1月15日のレコードのINSERT処理が実行された場合、現時点のパーティションの構成ではその範囲を満たすパーティションは存在していません。従来のレンジ・パーティションではORAエラーが発生してINSERT処理が失敗してしまっていましたが、今回ご紹介してきた時間隔パーティションであれば自動的に適切な範囲のパーティションを追加してくれるので、ORAエラーは発生せずに、INSERT処理が成功するというDBAの管理面でのメリットがあるのですね。お時間がある方は、実際に2015 年1月15日のレコードをINSERTして頂ければ、自動的に新しいパーティションが追加される動作を確認して頂くことが出来ますよ。
8. 演習2で実行した2014年9月分のレコードのCOL3の合計値を求めるSELECT文に「MONITOR」ヒントを加えて再実行して、実行時間を測定してください。また、演習2と同様、リアルタイムSQL監視のアクティブ・レポートを生成して下さい。
$ sqlplus /nolog
SQL>
connect / as sysdba
alter system flush buffer_cache ;
alter system flush shared_pool ;
connect TRY/TRY
set timing on
select /* practiceSQL */ /*+MONITOR */ sum(COL3) from TAB25
where COL2 >= to_date('2014/01/01','YYYY/MM/DD')
and COL2 < to_date('2014/02/01','YYYY/MM/DD') ;
SUM(COL3)
----------
1977798.69
Elapsed: 00:00:01.03
connect / as sysdba
set pagesize 100 linesize 120
col SQL_TEXT for a80
select SQL_ID, CHILD_NUMBER, SQL_TEXT
from V$SQL
where SQL_TEXT like 'select /* practiceSQL */ %' ;
SQL_ID CHILD_NUMBER SQL_TEXT
------------- ------------ --------------------------------------------------------------------------------
bfm2d76cbd1p3 0 select /* practiceSQL */ /*+MONITOR */ sum(COL3) from TAB25 where COL2 >= to_da
te('2014/01/01','YYYY/MM/DD') and COL2 < to_date('2014/02/01','YYYY/MM/DD')
set linesize 1000
set long 1000000
set longchunksize 1000000
set head off
spool sqlmon_active_partition.html
select dbms_sqltune.report_sql_monitor(sql_id=>'bfm2d76cbd1p3', type=>'active') from dual;
spool off
まず先にMONITORヒント句について解説しておくと、以前にもご紹介しましたが、リアルタイムSQL監視は5秒以上の処理時間を要した場合に自動的に情報収集が行われます。言いかえれば、5秒以内のSQLに関しては情報収集されないので、レポートを生成しても何も出力されないことになってしまいます。今回のSELECT文は5秒を下回ると予想されたので、強制的に情報収集を実行させる為に、MONITORヒント句をSELECT文に追加して頂きました。
さて、実行の結果はどのようになりましたか?SQLの実行時間を測定するのは、いつでもワクワクしますよね。私の環境では約1秒まで高速化したことが確認できました。皆さんの環境でも恐らく、演習2において非パーティション表に対しての実行時間の約1/10程度まで高速化しているのではないでしょうか?では、最後にアクティブ・レポートを参照して、高速化の理由を考えてみましょう。
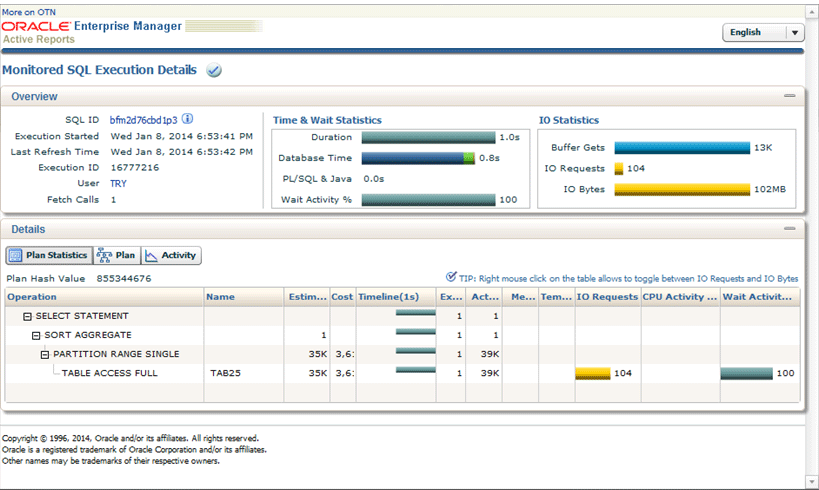
演習3での分析では、非パーティション表の場合、約1GBのデータをディスクから読み込む為に9割方の処理時間を要していることが確認出来ていたので、パーティション化によって、それがどのように変化したのかを見たいところですね。と言う事で、上段右側の「IO Statistics」枠の「IO Bytes」を確認してみると、102MBとなっているではないですか!非パーティション表の場合と比較して、1/10までディスクから読み込んだデータ量が小さくなっていますね。そして、SQLの実行時間の10秒から1秒へ高速化した数字とリンクしていることは誰が見ても明らかです。これがパーティション化の一つの大きなメリットなのです。
では何故、1GBではなく100MBのディスク読込み量で済んだのか?という点ですが、それはここまで読んで頂いた方であれば簡単ですよね。パーティション化によって、一ヵ月毎のパーティション=セグメントが完成しているので、全ブロックを読み込まなくてもどのブロックを読めば、今回のSELECT文で必要としている9月分のレコードが格納されているのかが把握できています。よって、9月分のパーティションである一つのセグメント約100MBだけをディスクから読めば良いのです。不要なレコードが含まれているブロックをディスクから読まなくて良いという、非常に効率的な処理が行えたことになります。このような動作を「パーティション・プルーニング」と呼びます。
さらに、SQLの実行計画からもこのパーティション・プルーニングが動作していることを理解出来ます。
TAB25表に対する「TABLE ACCESS FULL」は同じですが、その上部のオペレーションに「PARTITION RANGE SINGLE」とあります。これが、ある一つのパーティションへだけアクセスしていることを意味しているのですね。
さて、いかがでしたでしょうか? 新年早々にも関わらず、非常に難解な解説を書いてしまいまして申し訳なかったですが、まずは、パーティション化によるメリットである「パーティション・プルーニングによる問合せパフォーマンスの高速化」について体験して頂けたかと思います。次回もパーティション化によるメリットをご紹介できればと考えておりますので、お楽しみに。
今回はあくまで体験目的なので非常に効果の出やすい表定義、かつSQLでしたが、本番環境においてパーティション化を導入する際は、どのような問合せが多いのかというワークロードの特徴も充分考慮して、パーティションの種類やパーティション化キー列を決定していく必要がある為、安易なパーティション化は逆に性能劣化の可能性も含んでいるのでご注意ください。そのような場合に思い出して頂きたいのが、本ページの上部にリンクを掲載させて頂いている「【Oracle DBA & Developer Day 2011】どこまでチューニングできるのか?最新Oracle Database 高速化手法」でご紹介しているOracle Enterprise Managerでのアドバイザ機能になります。実際にDatabaseへ発行されたSQLを元にどのようなパーティション化が適切であるのかをアドバイスしてくれるので、是非機会があれば試して頂けると良いと思います。
今回も最後まで体験して頂きまして、ありがとうございました。そして、本年もコツコツと連載していきたいと思いますので、どうぞよろしくお願い致します。
