しばちょう先生の試して納得!DBAへの道 indexページ▶▶
みなさん、こんにちは。夏だ!夏です!夏ですね!こんな暑い日が続くと、データセンター内での業務が少しだけ恋しくなる、”しばちょう”こと柴田長(しばた つかさ)です。
気付けばこの連載を開始して4回目の夏を迎えました。そして、今回で第40回目という節目の回となりました。これだけの回数を続けられたのは、日頃ご愛読して頂いている皆様のお陰でございます。本当に感謝しております。この一年間のアクセス数も14万ページ・ビューに迫っており、多くのデータベース技術者の方にとって少しでもお役に立てているのであれば、嬉しい限りです。

さて、その40回目の今回は・・・(特別感を出したかったのですが)前回に引き続き、今回はAWRレポートを読めるようになる為の第二ステップとして『アクセス数が多い表領域とセグメントの特定』を体験形式で学習してみたいと思います。
データベースのパフォーマンス問題が発生した際に(もちろん、平常運用時のヘルスチェックの目的もありますが)、ほとんどのDBAの皆様がお世話になるのがAWRレポートやStatspackレポートでしょう。そこに絶妙なタッチで描かれている待機イベントや統計情報の意味が分からなければ、宝の持ち腐れになってしまいますし、問題を解決することは出来ません。
と言う事で、ちょいとひねったAWRレポートを用意させて頂きましたので、どのようなWorkload(SQL)が実行されているのかの分析にチャレンジして頂けると嬉しいです。以下の演習をOracle Database 11g Release 2以降のデータベースで試してみてください。
(補足:今回扱うAWRレポートはあくまで私の検証環境での数字であり、理解を補助する目的の為に掲載させて頂いています。実行する環境や設定によって異なりますし、この数値を保証するものではありません。)
- 【今回ご紹介するネタ一覧(逆引き)】
- * AWRレポートでまず確認しておくべき項目(演習1)
- * Top5待機イベントの特徴を確認(演習2)
- * SQL Statisticsの読み方(演習3)
- * Segment Statisticsの読み方(演習4)
- * Tablespae IO Statsの読み方(演習5)
- * Flashback Loggingが有効であることを知るための一つの待機イベント(演習6)
1. 次のAWRレポート(先頭部分だけ抜き出したもの)を確認し、どのようなWorkload(SQL)が実行されているのかを推測してみてください。
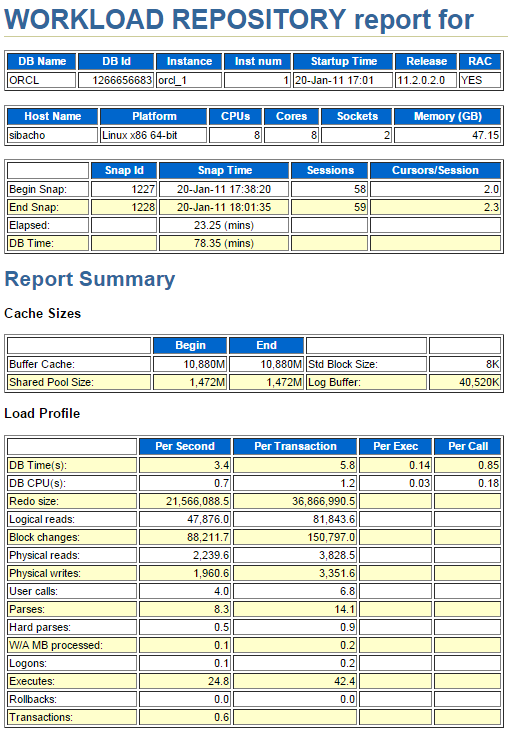
前回の復習となりますね。今回も前回同様に、私のPCから引っ張り出してきたOracle Database 11g Enterprise Edition Release 11.2.0.2 を使用してある機能を検証した際のAWRレポート(前回とは異なるもの)を使わせて頂きます。ある機能が何なのかは最後の最後に判明すると思いますので、是非お楽しみに。
私であれば、まずは次のような必要最低限の情報と特徴的な値を理解します。
- A) Oracle Database 11g Release 11.2.0.2.0
- B) Real Application Clusters構成
- C) CPUコア数は8、物理メモリは約48GB
- D) このAWRレポートの期間は約23分間
- E) バッファ・キャッシュのサイズは約10GB、共有プールのサイズは1.4GB
- F) 標準ブロック・サイズは8KB
- G) Redo生成量は20MB/secで、それなりに多い
- H) 秒間で9万回近くのブロック変更が発生している
- I) 秒間のトランザクション数が0.6回で非常に少ない
上記のG)~I) の情報からは「更新処理が多い、実行されたSQL数は少ない」という傾向が読みとれますから、さて如何でしょう?そうですね。「バッチ処理で大量データを一括更新するようなWorkloadではないか?」と推測出来ますね。と言う事を頭に入れた上で、次の演習でTop5待機イベントを見て行きましょう。
2. 次のTop5待機イベントを確認し、どのようなWorkload(SQL)が実行されているのかを推測してみてください。
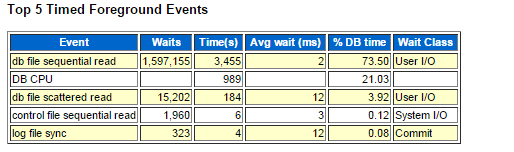
はい、非常に分かりやすいと言うか、良く目にする傾向のTop5待機イベントだと思います。
db file sequential read待機イベントが圧倒的に一番多くの待機時間(Time(s))と待機回数(Waits)を記録していますね。データベース全体の処理時間(DB time)に対して73.5% という非常に大きな割合を占めていますから、もし現状のパフォーマンスに不満があるのであれば、このdb file sequential read待機イベントを発生させているSQL文を特定してSQLチューニングをしたり、アクセスしている表や索引オブジェクトが格納されている表領域のデータファイルが配置されているディスク領域の高速化を施す必要があります。
その前に、この待機イベントはどのような処理がされたことを意味していたでしょうか?そうですよね。ディスクからバッファ・キャッシュ上へシングル・ブロック読込みで待機したことを意味しますから、このAWRレポートの期間である約23分間で160万個のブロックを読んだ事が理解できます。演習1で標準ブロックサイズが8KBであると確認しましたから、ちょっと乱暴ですけど、160万ブロックは約12GB(=160万 x 8KB)のデータ量をディスクから読んだのかーとも理解出来ます。ちなみに、「ちょっと乱暴」と言うのは、この待機イベントが発生した表領域のブロックサイズが8KBだと決めつけてしまった事です。もしかしたら、標準ブロックサイズではない可能性が残されていますからね。
2番目に多いDB CPUは飛ばして、3番目に待機時間が多い待機イベントはdb file scattered readですが、こちらの意味も覚えていますか?はい、ディスクからバッファ・キャッシュ上へマルチ・ブロック読込みで待機したことを意味しますね。Table Access Fullと言った表のフルスキャンを行った際に発生したり、前回扱ったPre-Warming機能が動作した際に発生する待機イベントですね。ちなみに、この待機イベントの待機回数は約1万5千回ですから、先ほどと同様に8KBを掛けて「120MB(=15202 x 8KB)のデータ量をディスクから読み込みましたー」って宣言しちゃダメですよ!!マルチ・ブロック読込みですから1回の待機で複数のブロックを読んだということですから、単純に回数に8KBをかけてはいけませんよね。一回で何ブロックを読み込んだのかを把握する方法は、後の演習で扱わせて頂きますので、ちょっとお待ちを。
4番目、5番目の待機イベントはDB timeに対する割合が非常に小さいので、今回は注目しないこととします。もちろん、状況によっては注目すべきケースもありますので、あくまで『一般的に』という前提となりますのでご注意ください。
さてさて、演習1での推測結果と組み合わせて考えてみると、何か矛盾を感じませんでしょうか? もしも感じてしまった方は確実にエキスパートな方なので、ご自身の持つスキルに自信を持って頂いて良いと思います。素晴らしいですね。感じられていない方も大丈夫です。この連載を体験して頂くことで、着実にエキスパートに近づいて行けると信じていますから。では、この段階で何が矛盾しているのかを解説しておきますね。
演習1での推測は「バッチ処理で大量データを一括更新するようなWorkloadではないか?」でしたが、これだとTable Access Fullのような大量データをマルチ・ブロックで一気に読み込んで更新する処理がイメージできますが、演習2のTop5待機イベントから見えてきたのは、シングル・ブロック読込みが多発する処理が流れている?あれ?矛盾している?
と言う事で、次の演習では具体的に実行されているSQL文を確認していきましょう。
3. 次のSQL Statisticsセクションから適切な情報を選択し、ディスクから読み込んだブロック数が多いSQL文を特定して下さい。
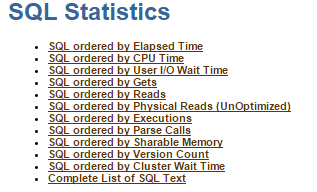
SQL Statisticsセクションには上記の通り幾つかの情報が用意されていて、それぞれの情報は任意のデータを使用してSQL文をソートしたものです。例えば、実行時間が長い順にSQL文を並べた情報が「SQL ordered by Elapsed Time」、CPU使用時間が長い順にSQL文を並べた情報が「SQL ordered by CPU Time」となります。分析したい目的に合わせて使い分けるスキルを身につけたいですね。
でもって、今回の演習ではディスクI/Oに着目して分析をしてきていますから、ディスクから読み込んだブロック数が多い順にSQL文を並べた情報である、「SQL ordered by Reads」を参照してみることになります。それが次ですね。

分かり易過ぎて何も言う必要は無いとは思いますが、技術記事ですから触れないわけにはいきませんよね。
はい、一つのUPDATE文だけで圧倒的に多くのブロックを読み込んでいることが一目瞭然ですね。そして、Executions列でUPDATE文の実行回数を確認してみると・・・「1」ですね。「1」ですよね。と言う事は、このUPDATE文は一度しか実行されていないことも理解できますから、演習1での推測である「バッチ処理で大量データを一括更新するようなWorkload(Table Access Fullのような大量データをマルチ・ブロックで一気に読み込んで更新する処理)ではないか?」が該当しそうですね。しかしながら、Top5待機イベントで確認したシングル・ブロック読込みの待機イベントdb file sequential readが多発している現象とツジツマを合わせることは未だ出来ませんね。
ここで少し脱線して、この「SQL ordered by Reads」セクションの情報の読み方を解説しておきます。
- ✓ Physical Reads:該当SQL文をExecutions列の回数分実行した際にディスクから読み込んだブロック数
- ✓ Executions:該当SQL文を実行した回数
- ✓ Reads per Exec: 該当SQL文を一回実行する為にディスクから読み込んだブロック数
- ✓ %Total:ディスクから読み込んだ合計ブロック数に対する、該当SQL文の割合
- ✓ Elapsed Time(s):該当SQL文をExecution列の回数文実行した際の合計実行時間
- ✓ %CPU:Elapsed Time(s)列の時間に対する、CPUで処理時間の割合
- ✓ %IO:Elapsed Time(s)列の時間に対する、IOしていた時間の割合
これらを理解した上で、改めてUPDATE文の特徴を書いてみますね。
今回のUPDATE文は一回だけ実行されていて、300万ブロック(300万 x 8KB = 約23GB)をディスクから読み込んでいます。ディスク読込み回数は全体の97%の割合を占めていることから、このUPDATE文がほぼ全てのディスクアクセスを発生させていたと理解出来ます。また、(ちょっと唐突過ぎてすいませんが・・・)このAWRレポート期間は23分間ですがUPDATE文は4500秒=75分間の実行時間を要していることから、一つのUPDATE文を複数のプロセスで複数のCPUコアを使用するパラレルDMLで実行されていると推測出来てしまいます。さらに、このUPDATE文の実行時間の約22%はCPU処理時間で消費していて、70%はディスクI/Oに時間を要していることが理解できますが、合計して92%にしかならないので残りの8%は何の処理で待たされたの?となります。今回は詳しく述べませんが、この残りはCPUもIOも使えていなかった時間なので、主にネットワークでの処理時間が該当します。
という感じで、このセクションをさらりと読めると、かっこいいですよねー!!
でもって、脱線する前に何を話していたのかを思い出すと・・・、そうですね。ディスクからデータを大量に読み込んでいたSQL文が一回のUPDATE処理だったことを突き止めました。ですが、未だツジツマが合わないので、もう少し分析してみることにしましょう。
4. 次のSegment Statisticsセクションから適切な情報を選択し、ディスクから読み込んだブロック数が多いセグメントを特定して下さい。

演習3のSQL Statisticsセクションと同様に、Segment Statisticsセクションにも上記の通り幾つかの情報が用意されていて、それぞれの情報は任意のデータを使用してセグメント(表や索引)をソートしたものです。この演習4ではディスクから読み込んだブロック数が多い順にセグメントを並べた情報である、「Segment by Physical Reads」を参照してみましょう。
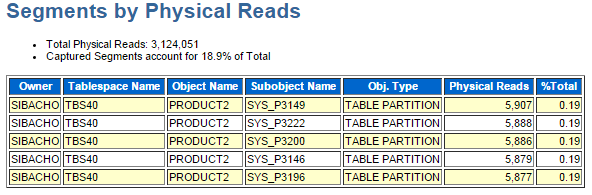
演習3において、既に問題のUPDATE文が特定されていますから、そのUPDATE文を見ればアクセスしている表名が確認できていますから、今回の演習ではこの情報の有り難さを噛み締めることは出来ないですね。しかしながら、数十、数百、数千のSQL文が同時に実行されるようなWorkloadにおいては、どのセグメントに対するアクセス数が多いのかは非常に大切な情報となりますので、今回は存在だけでも覚えておいて頂ければと思います。
もちろん、今回のケースでも小さいですけどメリットはあります。それは、UPDATE文から表名は分かりますが、アクセスしている索引名までは分かりませんし、パーティション表の場合には、どのパーティションへアクセスが集中しているのかは分かりませんよね。と言う事で、改めて見てみると如何でしょう?
TBS40表領域上に存在する、SIBACHOスキーマのPRODUCT2というパーティション表(TABLE PARTITION)の各パーティションへのPhysical Readsが均等になっていることが確認出来ます。ちなみに、この部分の情報が5行しか出力されない仕様なので、5つのパーティションにしかアクセスしていないわけではなく、実際にはもっと多くのパーティションへ均等にアクセスしています。
この演習4の情報からは、UPDATE処理の対象であったPRODUCT2表が格納されているTBS40表領域からのディスク読込みが多かったのかなー?と思いますよね。次に見たくなるのは、もちろん表領域毎のIO統計ですよね? あるのですよ。その素敵なセクションが!!
5. Tablespace IO Statsセクションを確認し、表領域毎のIO統計を確認して下さい。
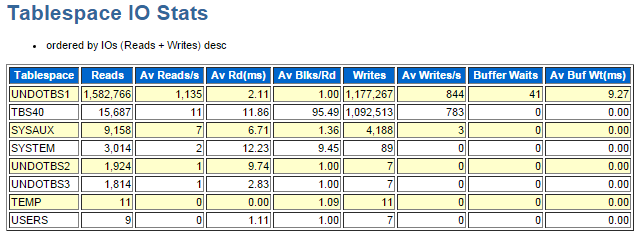
演習4で確認できたTBS40表領域に注目しようと思ったら・・・、あらららら?UNDOTBS1表領域のReads数の値にどうしても目が行ってしまいますよね。ここまで、繰り返しツジツマが合わないと言ってきた原因の尻尾を掴んだ!そんな感じです。詳しく見てみましょう。
まず、UNDOTBS1表領域のブロックをディスクから読み込んだ回数(ブロック数ではない)は約160万回です。おっとーこの数字に見覚えが無いですか?そうです。演習2で出てきましたよね。db file sequential read待機イベントの待機回数と一致しちゃいます。怪しいですよね。面白くなってきましたよね。本当に推理小説のようです。
しかも、Av Blks/Rd(Average Block per Readの略だと思います)の値が「1.00」となっていることから、一回のディスク読込み当たり1ブロックだったことが確認できるので、正にシングル・ブロック読込みであった事が証明され、db file sequential read待機イベントの意味である「ディスクからバッファ・キャッシュ上へシングル・ブロック読込みで待機」と、これまた合致します。確実に怪しい。本当に怪しい。db file sequential read待機イベントを発生させていたのは、UPDATE対象のPRODUCT2表が格納されているTBS40表領域ではなく、UNDO表領域だったのか?疑いが強まってきますね。
TBS40表領域の行も確認してみましょう。読込み回数は約1万5千回ですが、これも演習2で分析した待機イベントdb file scattered readの待機回数と一致します。そして、Av Blks/Rdの値が「95.49」と言う事から一回のディスク読込み当たり平均95ブロック、つまり、マルチ・ブロック読込みだった事も理解できます。db file scattered read待機イベントの意味である「ディスクからバッファ・キャッシュ上へマルチ・ブロック読込みで待機」とも一致します。
ちなみに、UNDOTBS1表領域からの読込みデータ量は約12GB(1,582,766 * 1.00 * 8 / 1024 / 1024)、TBS40表領域からの読込みデータ量は約11GB(15,687 * 95.49 * 8 / 1024 / 1024 )で、合計23GBです。この23GBも何処かで出てきましたよね?はい、演習3のSQL ordered by Readsセクションで確認して頂いた、「UPDATE文が300万ブロック(300万 x 8KB = 約23GB)をディスクから読み込んでいる」という部分に完全に一致します。
と言う事で、『一回のUPDATE文において、11GBの表データをマルチ・ブロックで読み込んで更新処理をしている。しかも、12GBのUNDOデータをシングル・ブロックで読み込んでいる』という結論になったので、演習2の解説部分に書かせて頂いた矛盾(演習1での推測は「バッチ処理で大量データを一括更新するようなWorkloadではないか?」でしたが、これだとTable Access Fullのような大量データをマルチ・ブロックで一気に読み込んで更新する処理がイメージできますが、演習2のTop5待機イベントから見えてきたのは、シングル・ブロック読込みが多発する処理が流れている?あれ?矛盾している?)は、事実、矛盾していなかったと言うことになるわけです。
でも何故、UPDATE処理でUNDO表領域のデータをシングル・ブロック読込みしているの?という疑問は残っていると思いますので、最後に次の演習を体験して頂きたいと思います。
6. Backgroup Wait Eventsセクションを確認し、UNDO表領域のシングル・ブロック読込みが発生している理由を推測して下さい。
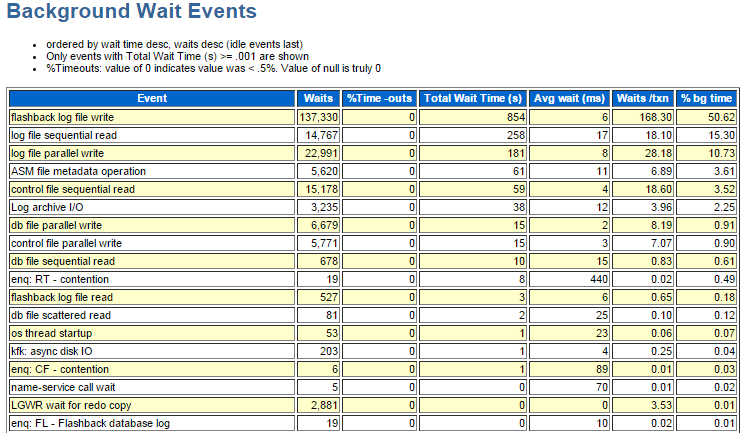
はい、これまた分かり易い傾向が出ていますね。一番長く待機した待機イベントとして「flashback log file write待機イベント」が確認できます。この待機イベントの意味は何でしょう?残念ながら、待機イベントの説明が記載されているリファレンス・マニュアルには説明が無いようですが、近しい名前の「flashback log file sync待機イベント」の記載はありますね。この説明文から、フラッシュバック・データベースのデータに関する待機イベントっぽいことが推測できるでしょうし、サポート契約をお持ちの方はMy Oracle Supportで検索して頂ければと思います。簡単に言えば、「flashback log file write待機イベント」は、フラッシュバック・データベースのデータ(Flashback Log)を書き出しで待機した回数ですね。さあ、答えが出ましたね。
今回皆様に体験して頂いたAWRレポートは、Flashback Loggingを有効化している環境でUPDATE処理を流した際のものでした。Flashback Loggingによって、UNDO表領域からのシングル・ブロック読込みが発生する理由は、第20回 フラッシュバック・データベースのオーバーヘッドでご紹介させて頂いているので、そちらを参考にしてみてくださいね。
さて、AWRレポートを読む為のステップ2として、アクセス数が多い表領域とセグメントの特定を体験頂きましたが、如何でしたでしょうか?「AWRレポートにはこのような情報が含まれている」という知識を身につけておけば、ある問題が発生した際に、どのセクションを見るべきだ。と言う分析ルートが自然に確立されていくと思います。その為には、数多くのAWRレポートを読むべきだと私は思いますし、ベテランDBAの方と一緒に分析するという事も非常にお薦めです。私も他人のAWRレポートの分析方法を教えてもらう事で新しい発見があるので、非常に奥深いです。前回の繰り返しになりますが、推理小説を読むように面白いと感じるようになってきたら、貴方はもうOracle Databaseから離れることは出来ないでしょう。
だだし、注意点としては、AWRレポートだけでは分析し切れない事もあります。なので、AWRレポートと共に、SQL監視レポートやActive Session History(ASH)、さらにはOSのvmstatやiostat、dstatのような統計情報も合わせて必要となるケースが多いですので、AWRレポートがあれば全て分かるとは思わないでくださいね。
と言う事、今回も最後まで体験して頂きましてありがとうございました。是非、感想や質問をお待ちしておりますね。次回以降もどうぞよろしくお願い致します。
(ご質問の方法はこちらにあります)
https://blogs.oracle.com/otnjp/shibacho-index
