この記事はDavid Cordobaによる”Why use Full Stack Disaster Recovery service on OCI?“の日本語翻訳版です。
2023年9月15日
個々のアプリケーション・コンポーネントやリージョン全体へのアクセスを中断するサービス停止など、ビジネスの継続性に影響するイベントからビジネスを保護する場合は障害回復のための信頼できるソリューションを準備しておくことが不可欠です。
ITチームにとって、サービスまたはエンドツーエンド・アプリケーションのリカバリは重要な課題であり、リカバリ計画に定義されているすべての操作の調整処理が必要になってきます。これらのタスクは、リカバリ時間目標(RTO)およびリカバリ・ポイント目標(RPO)に影響を与える可能性のある人的エラーおよび反応時間の遅い原因となります。
このため、Oracle Cloudコンソールなどの単一画面からモニター、監査、自動化およびトラブルシューティングを行うツールを使用して、障害時リカバリ計画を改善することが重要です。OCI Full Stack Disaster Recoveryは、Oracle Cloud Infrastructure (OCI)に組み込まれているサービスであり、これらの各課題に対処できます。FSDRは個々のコンポーネントを一度に1つずつリカバリするのではなく、アプリケーション・スタック全体の完全なリカバリを提供し、自動化されたワークフローを使用してリカバリ時間を最小限に抑えることで人的エラーの要素を減らすことができます。
OCI Full Stack Disaster Recovery(FSDR)の概念
OCI Full Stack Disaster Recovery(FSDR)の動作を理解するために、いくつかの重要な概念を見てみましょう。
- コールド・スタンバイ・モデル: このディザスタ・リカバリ・デプロイメント・モデルでは、アプリケーション・コンポーネントはプライマリ・リージョンにのみ存在します。しかし、ストレージ・ボリュームはセカンダリ・リージョンにレプリケートされるためディザスタ・リカバリ・イベントでは、仮想マシン(VM)はそれらのボリュームからデプロイされます。このモデルは、運用コストを低く抑えつつ、高いRTOを実現します。
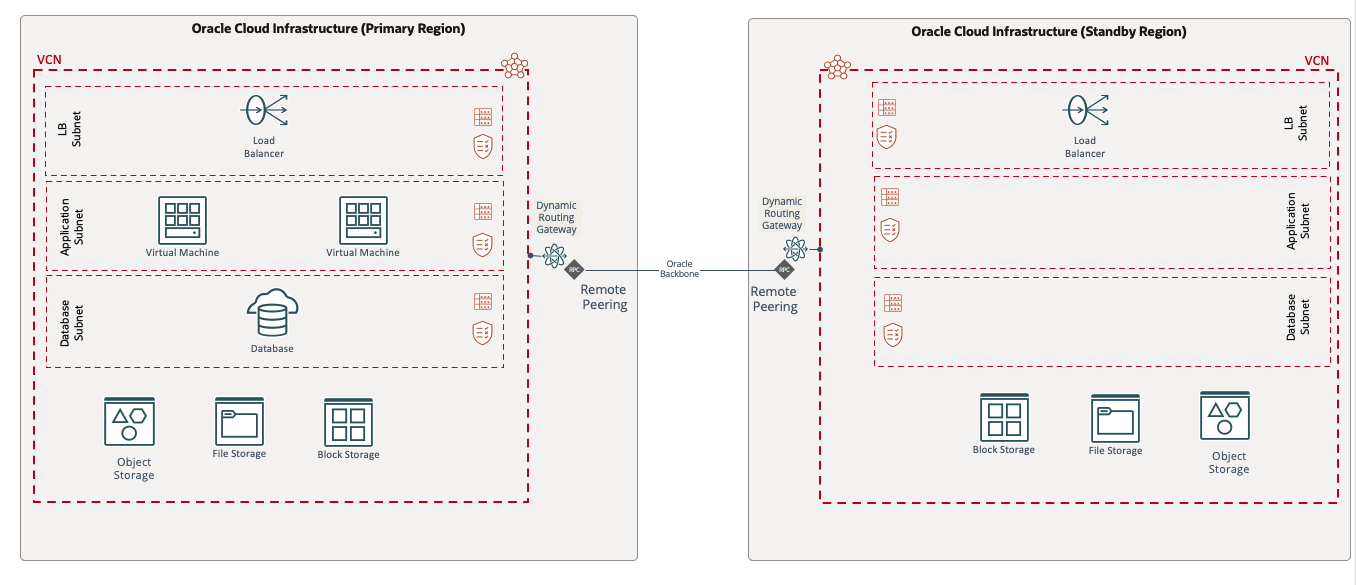
- ウォーム・スタンバイ・モデル: このモデルでは、アプリケーション・コンポーネントが一意のホスト名と割り当てられたIPアドレスを使用してプライマリ・リージョンとスタンバイ・リージョンにプロビジョニングされます。アプリケーションVMの電源は切断されていますが、データベースは対応するレプリケーション・メカニズムを使用して両方のリージョンで電源を投入する必要があります。このモデルは、コールド・スタンバイ・モデルよりも高い運用コストと低いRTOを実現します。
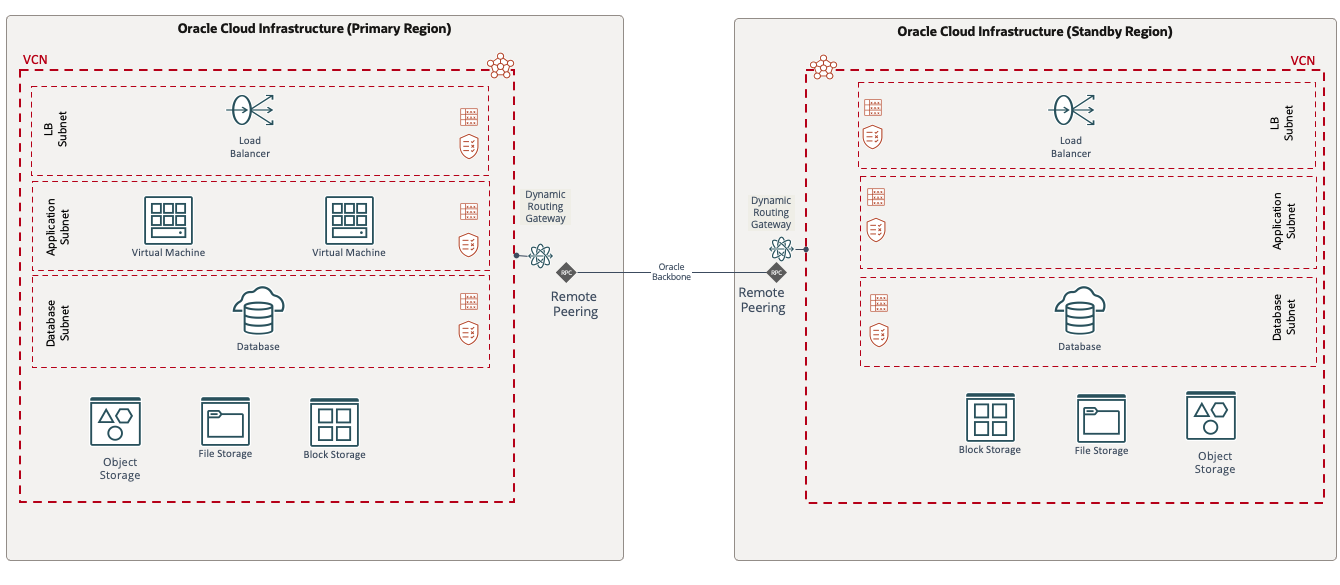
- ホット・スタンバイ: このディザスタ・リカバリ・デプロイメント・モデルでは、すべてのアプリケーション・コンポーネントが存在し、プライマリ・リージョンとセカンダリ・リージョンの両方で一意のホスト名、割り当てられたIPアドレスおよび対応するレプリケーション・メカニズムを使用して電源が投入されます。このモデルでは、他のデプロイメント・モデルよりも運用コストが高く、RTOが最小になります。
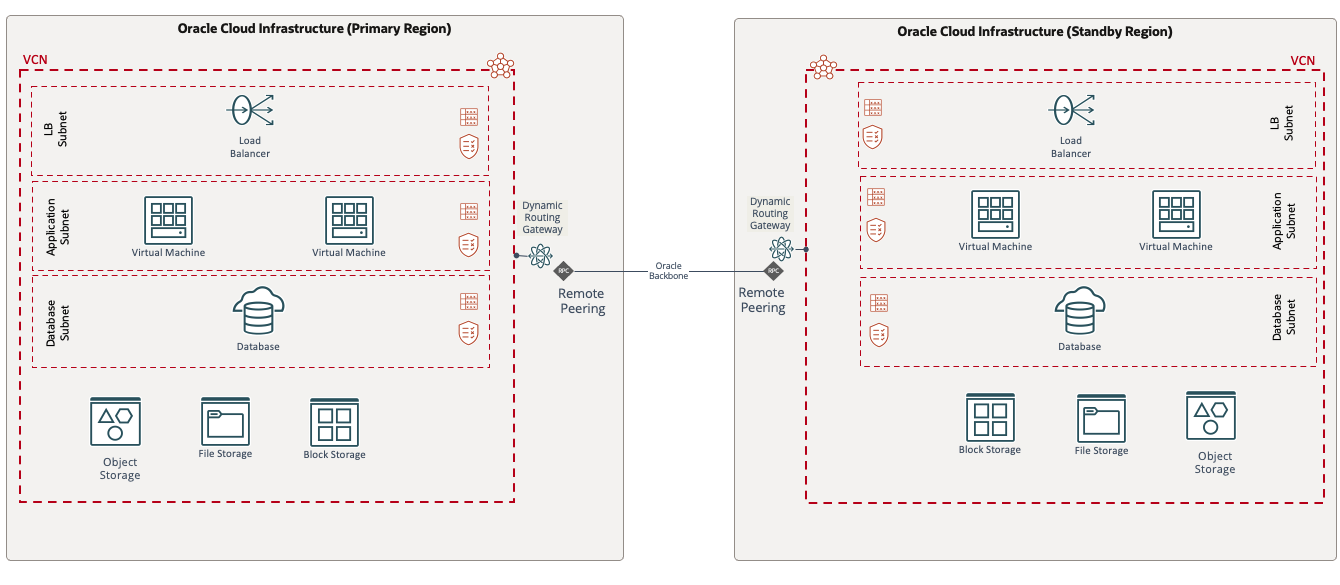
- スイッチオーバー: このタイプの障害回復計画は、プライマリ・サイトからスタンバイ・サイトへのサービスの計画的な移行を可能にします。
- フェイルオーバー: プライマリ・サイトからスタンバイ・サイトへのサービスの計画外遷移をトリガーする、このタイプの障害時リカバリ計画。
OCI Full Stack Disaster Recovery(FSDR)の動作
OCI Full Stack Disaster Recovery(FSDR)では、次のOCIリソースのリカバリがサポートされています。
- コンピュート・インスタンス
- ブート・ボリュームとブロック・ボリューム
- Oracle Exadata Databaseサービス
- Oracle Base Databaseサービス
- Oracle Autonomous Database Serverless
OCI Full Stack Disaster Recovery(FSDR)を開始するには、ディザスタ・リカバリ用にアプリケーション・コンポーネントがすでにデプロイされている必要があります。今回は2つのVMとウォーム・スタンバイ・モデルにデプロイされたデータベースで構成されるアプリケーション・スタックのOCI Full Stack Disaster Recovery(FSDR)構成を例としてご紹介します。
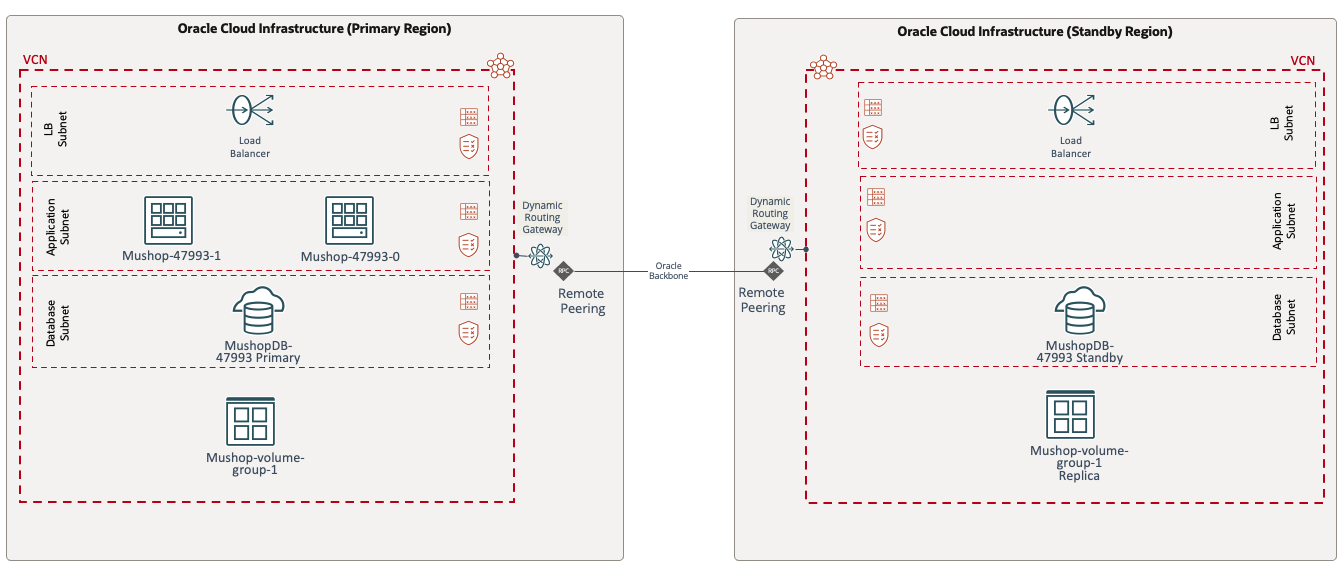
まず、アプリケーション・スタック(この場合はVM、データベースおよびボリューム・グループ)のすべてのコンポーネントと依存関係を識別します。次に、プライマリ(アッシュバーン)およびスタンバイ(フェニックス)リージョンにディザスタ・リカバリ保護グループを作成します。ディザスタ・リカバリ保護グループは、リカバリ・プロシージャの実行時にフル・スタックとして扱われる必要がある、アプリケーション内のOCIリソースのグループです。次の画像は、アッシュバーンおよびフェニックスで作成されたディザスタ・リカバリ保護グループを示しています。
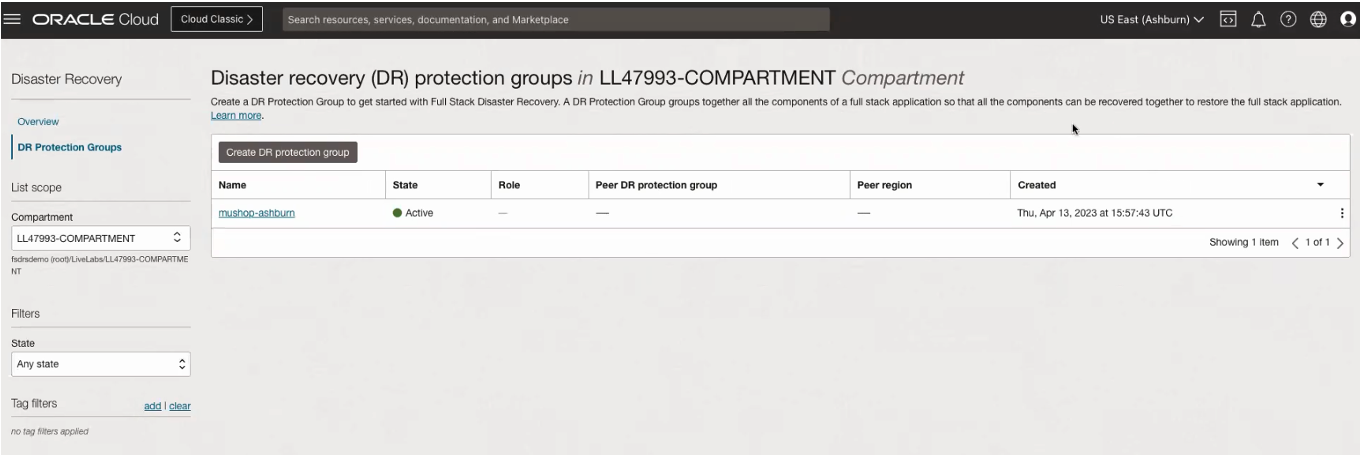
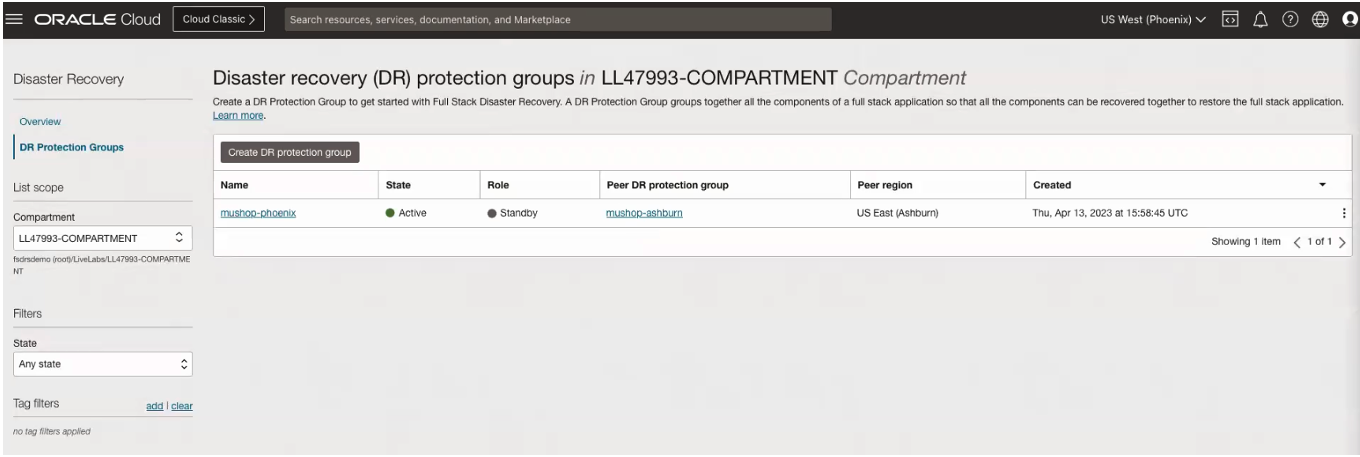
次に、障害回復保護グループを関連付け、各リージョンのコンポーネントを対応するグループのメンバーとしてグループ化します。
このデプロイメントではウォーム・スタンバイ・モデルを使用したため、プライマリ・リージョンでは保護グループのメンバーとしてコンピュート、データベースおよびボリューム・グループ・インスタンスを選択し、セカンダリ・リージョンでは、次の図に示すように、データベースのみをメンバーとして含めました。
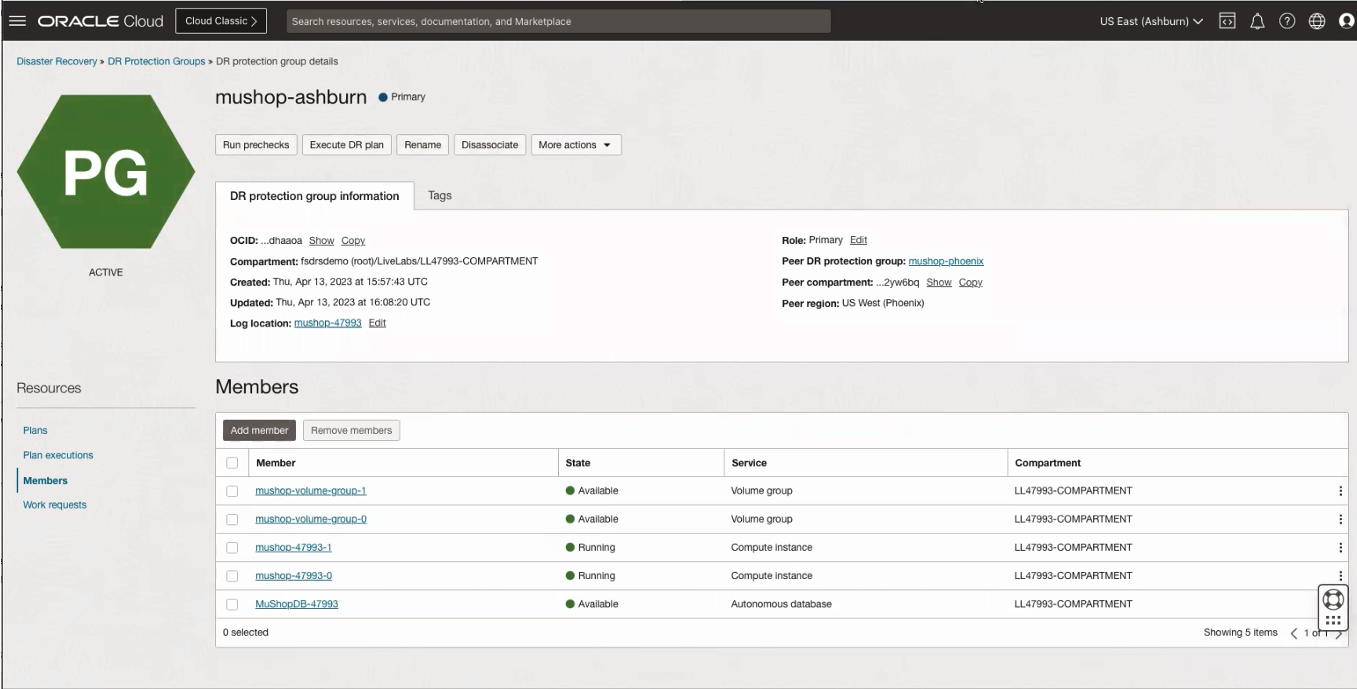
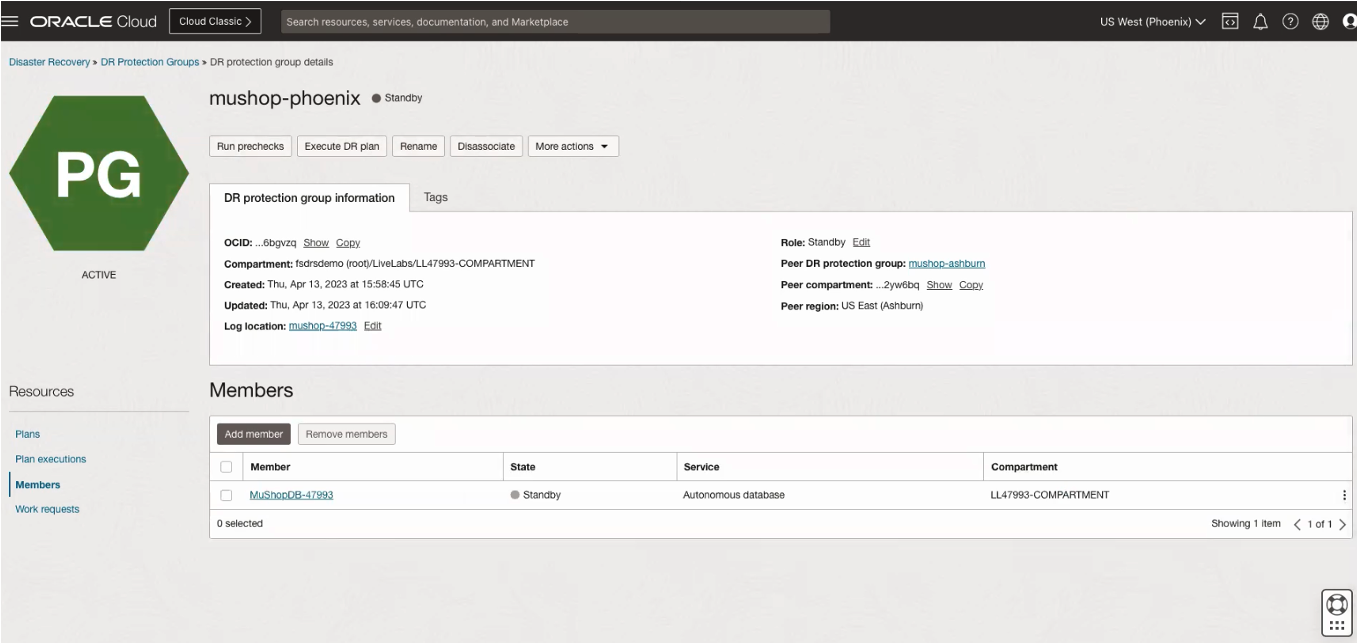
次に、ディザスタ・リカバリ・プランを作成してスイッチオーバーを実行します。障害回復計画は、障害回復保護グループのペアに関連付けられたワークフローを表す一連の計画グループです。プラン・グループは、コンピュート・インスタンスのプロビジョニングやデータベース・スイッチオーバーの実行など、自動または自分が作成できるステップのグループです。障害時リカバリ計画は、スタンバイ・ロールを持つ障害時リカバリ保護グループでのみ作成できます。
今回の例では、プランによってプライマリ・サイトのインスタンスを停止し、データベースとボリューム・グループをスイッチオーバーし、スタンバイ・リージョンのインスタンスの電源を投入するステップが自動的に生成されています。
次の図は、生成された障害回復計画を示しています。
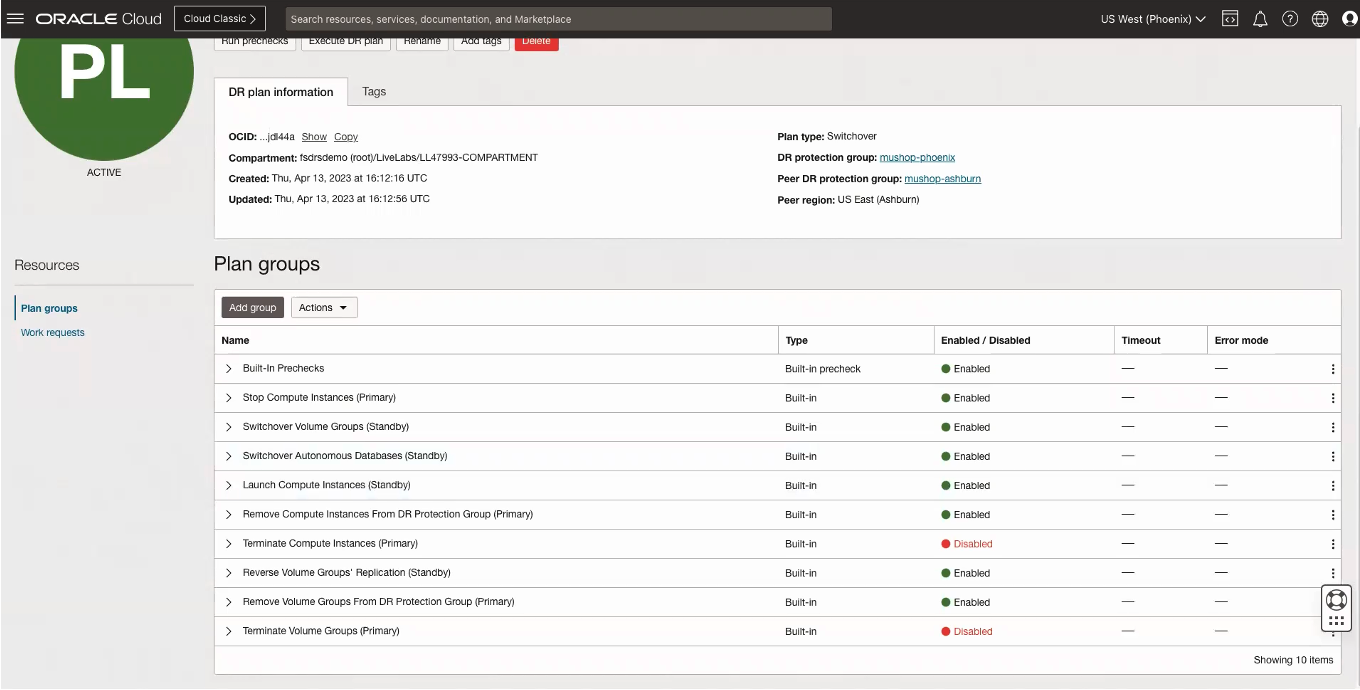
ディザスタ・リカバリ計画の作成後に、事前チェックを実行します。事前チェックは、プランが正しく実行されることを確認するための検証のグループです。スイッチオーバーを実行するワークフローは、事前チェックの実行後に開始されます。
次の図は、プラン処理ステップとその正常な完了を示しています。
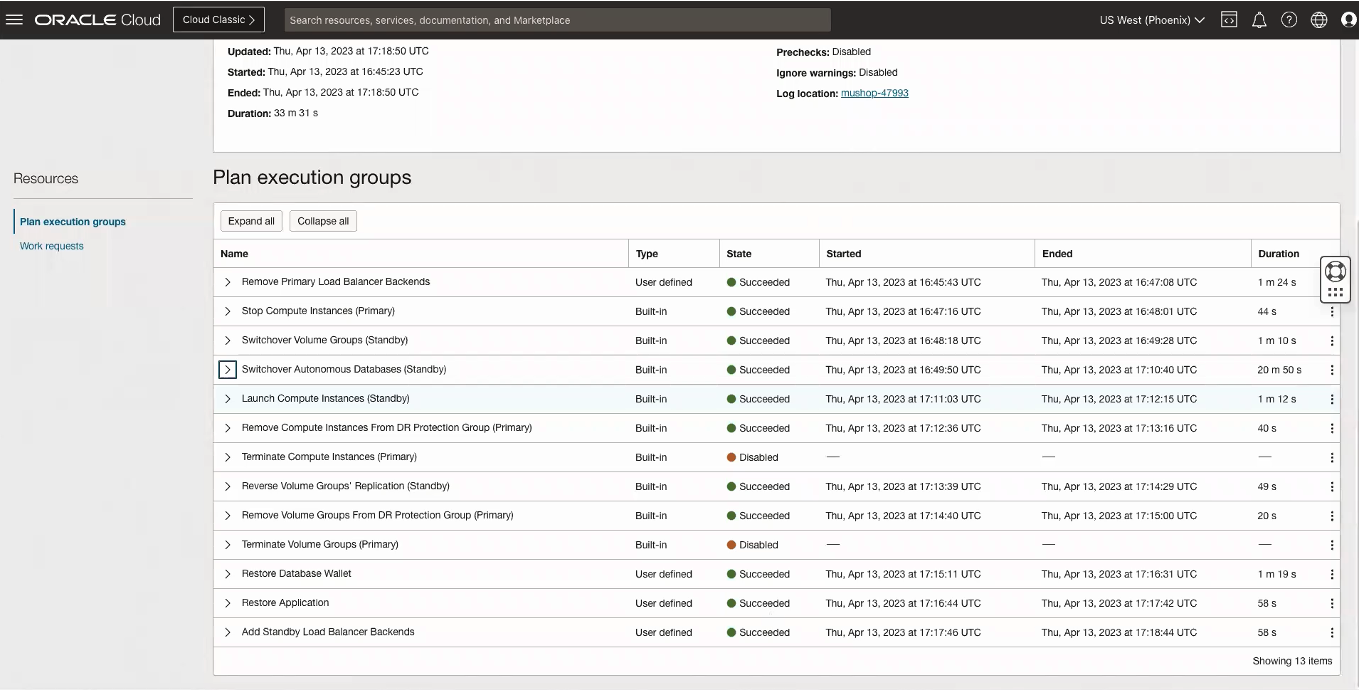
スイッチオーバーを実行すると、次のことが行われます。
- スイッチオーバー計画が機能することを検証します。
- スイッチオーバーが完了すると、プライマリ保護グループの役割がスタンバイに自動的に変更されます。
スイッチオーバー計画は、現在スタンバイであるので最初のリージョンに作成できます。新しいスイッチオーバー計画では、いつでも元のプライマリ・リージョンに戻すことができます。(これらの計画の作成は1回かぎりのタスクです。)
これらを使用して、リージョンの作成後にリージョンを切り替えることができます。リージョンを切り替えるには、両方のディザスタ・リカバリ保護グループのスイッチオーバーおよびフェイルオーバー・プランを作成する必要があります。
最後に、アプリケーションがプライマリ・リージョンで実行されていることを確認した後、スタンバイ・リージョンでも同じことをテストできます。
実際に試してみる
是非、この機会にOCI Full Stack Disaster Recovery Service(FSDR)を活用して、現在のアーキテクチャ・デプロイメントでのディザスタ・リカバリ計画を試して見てください。
今回ご紹介した内容は、「 Move a virtual machine between OCI regions using Full Stack Disaster Recovery」のチュートリアルで詳しくご確認いただけます。
また、このサービスの技術的な詳細は、OCI Full Stack Disaster Recovery Service製品ページと製品ドキュメントをご参照ください。
