Creating a reliable solution for disaster recovery is imperative when protecting your business from events that impact business continuity, such as service outages that interrupt access to individual application components or even an entire region. Recovering a service or end-to-end application is another challenge for the IT team, requiring coordinated processing of all operations defined in the recovery plan. These tasks are subject to human error and slow reaction times that can affect the recovery time objective (RTO) and recovery point objective (RPO).
For this reason, improving your disaster recovery plan with tools to monitor, audit, automate, and troubleshoot through a single pane of glass, such as the Oracle Cloud Console, is important. Full Stack Disaster Recovery is a native Oracle Cloud Infrastructure (OCI) service that enables you to face each of these challenges. It provides a complete recovery of the entire application stack, instead of recovering individual components one at a time, and it minimizes recovery time using automated workflows, which helps reduce the element of human errors.
Full Stack Disaster Recovery concepts
Let’s look at some important concepts to understand the operation of Full Stack Disaster Recovery.
-
Cold-standby model: In this disaster recovery deployment model, application components only exist in the primary region, although the storage volumes are replicated to the secondary region, so in a disaster recovery event, virtual machines (VMs) are deployed from those volumes. This model implies low operating costs, but a high RTO.
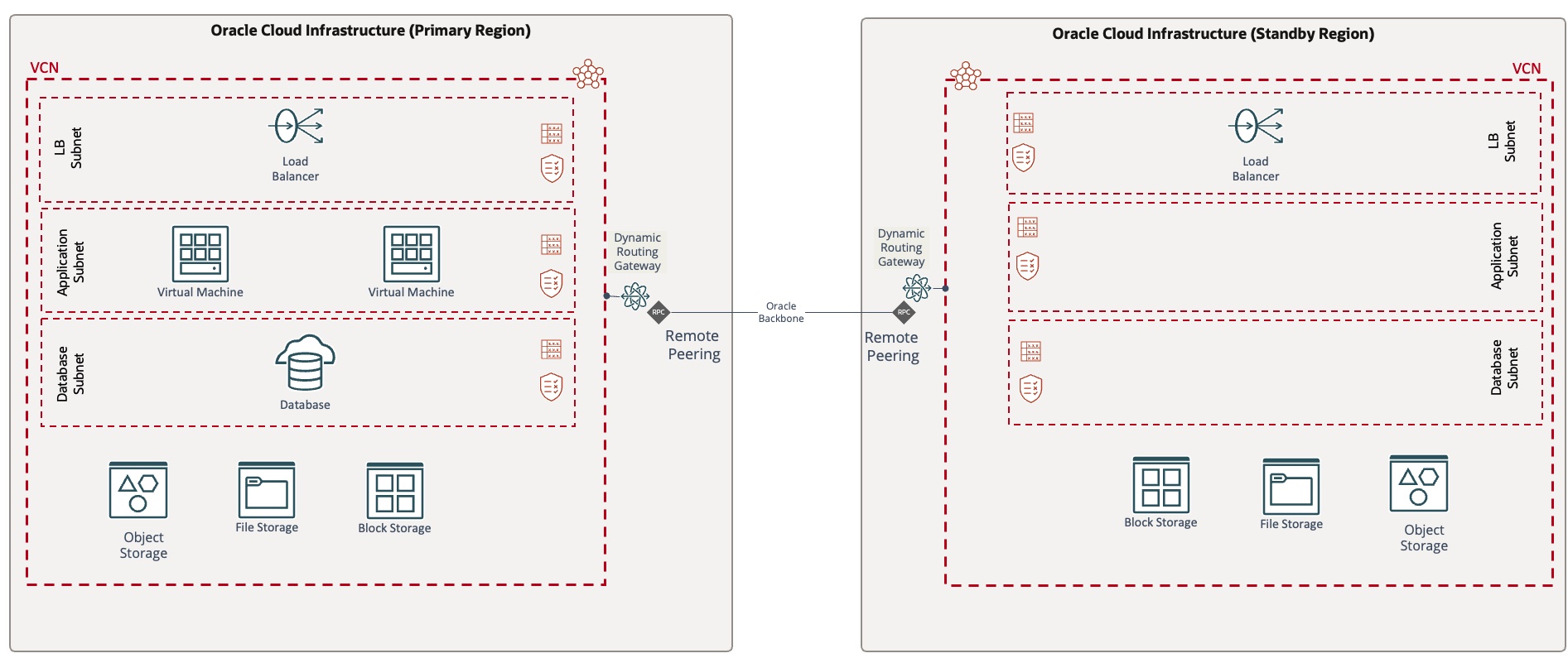
-
Warm-standby model: In this model, application components are provisioned in the primary and standby regions with unique hostnames and assigned IP addresses. The application VMs are powered off, but the databases must be powered on in both regions with their corresponding replication mechanisms. This model implies higher operating costs than the cold-standby model and lower RTO.
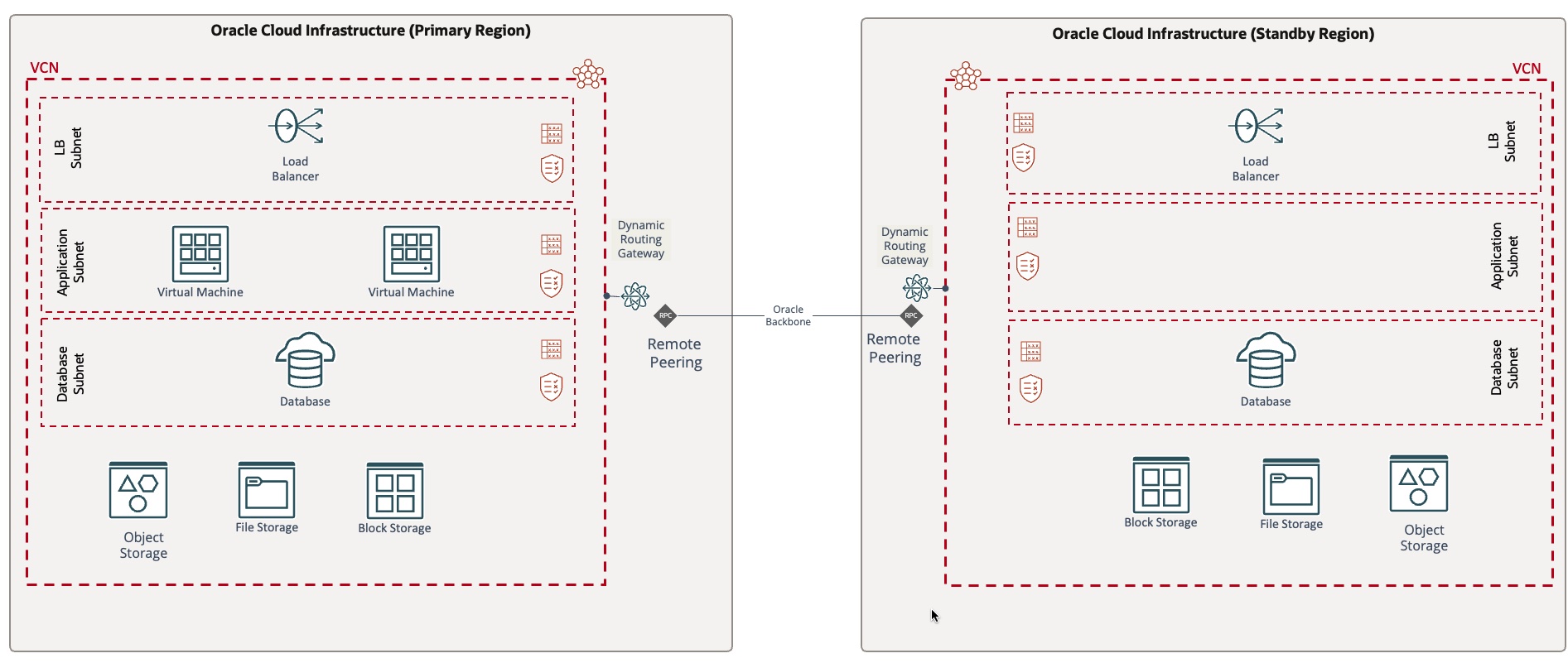
-
Hot-standby: In this disaster recovery deployment model, all application components exist and are powered on in both regions, primary and secondary region, with unique hostnames, assigned IP addresses, and corresponding replication mechanisms. This model incurs higher operating costs than the other deployment models and the lowest RTO.
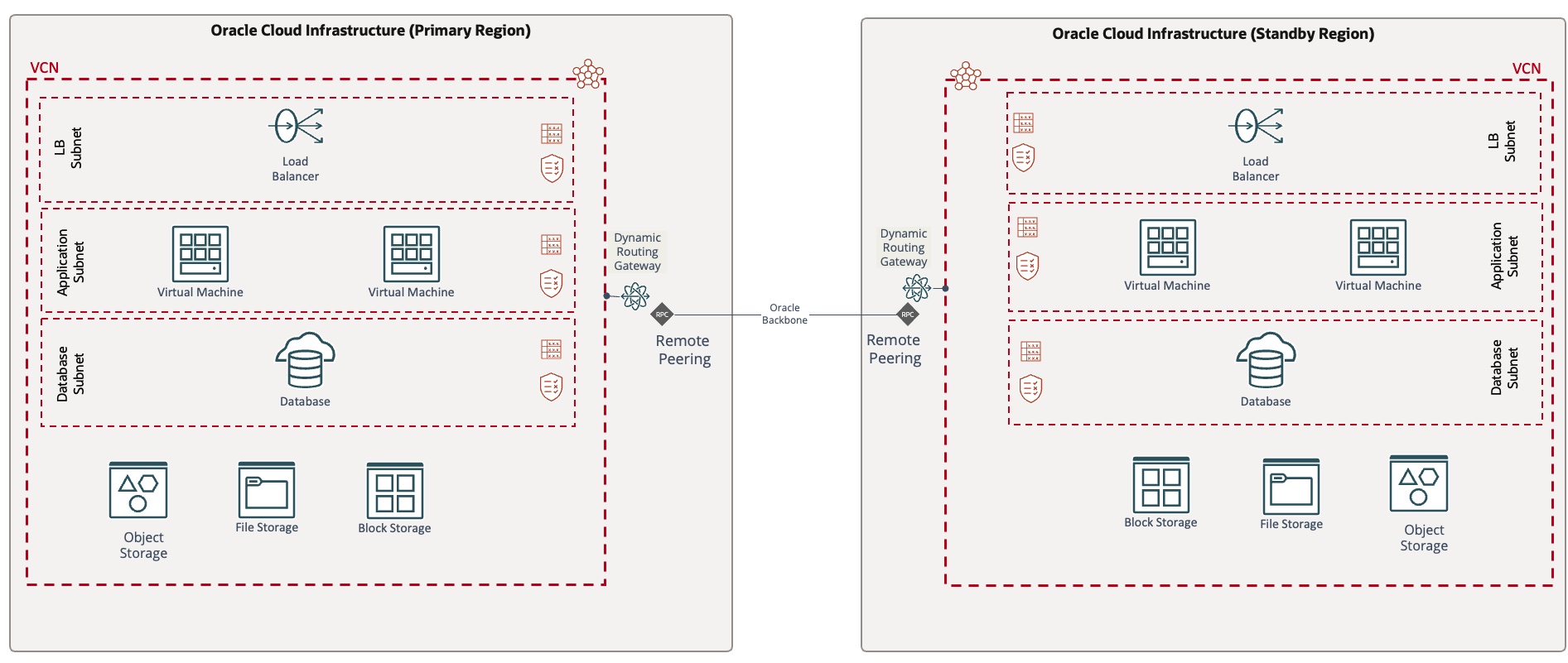
-
Switchover: This type of disaster recovery plan enables a planned transition of services from the primary site to the standby site.
-
Failover: This type of disaster recovery plan that triggers an unplanned transition of services from the primary to the standby site.
How Full Stack Disaster Recovery works
Full Stack Disaster Recovery supports recovery for the following OCI resources:
-
Compute instances
-
Boot and block volumes
-
Oracle Exadata Database service
-
Oracle Base Database service
-
Oracle Autonomous Database Serverless
To get started with Full Stack Disaster Recovery, your application components must already be deployed for disaster recovery. As an example, let’s set up a Full Stack Disaster Recovery configuration for the stack of an application consisting of two VMs and a database deployed in a warm-standby model.
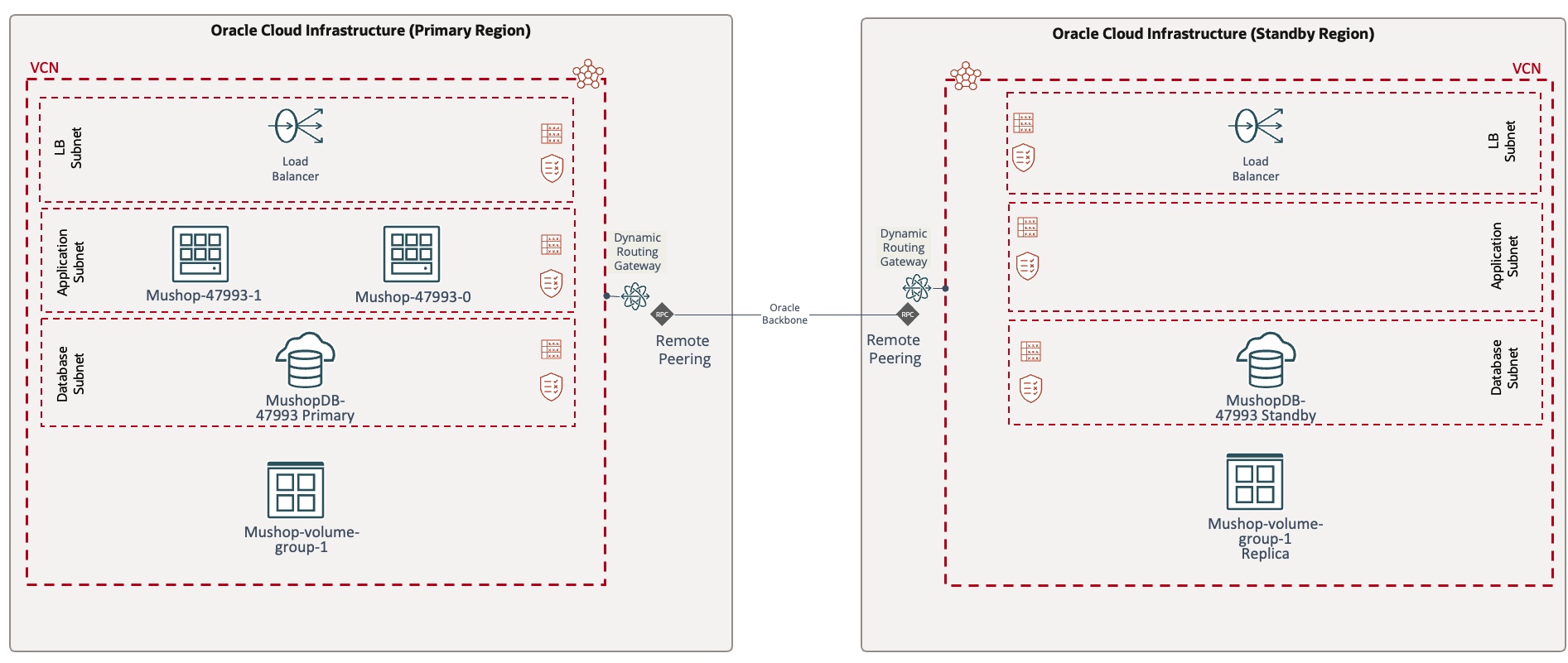
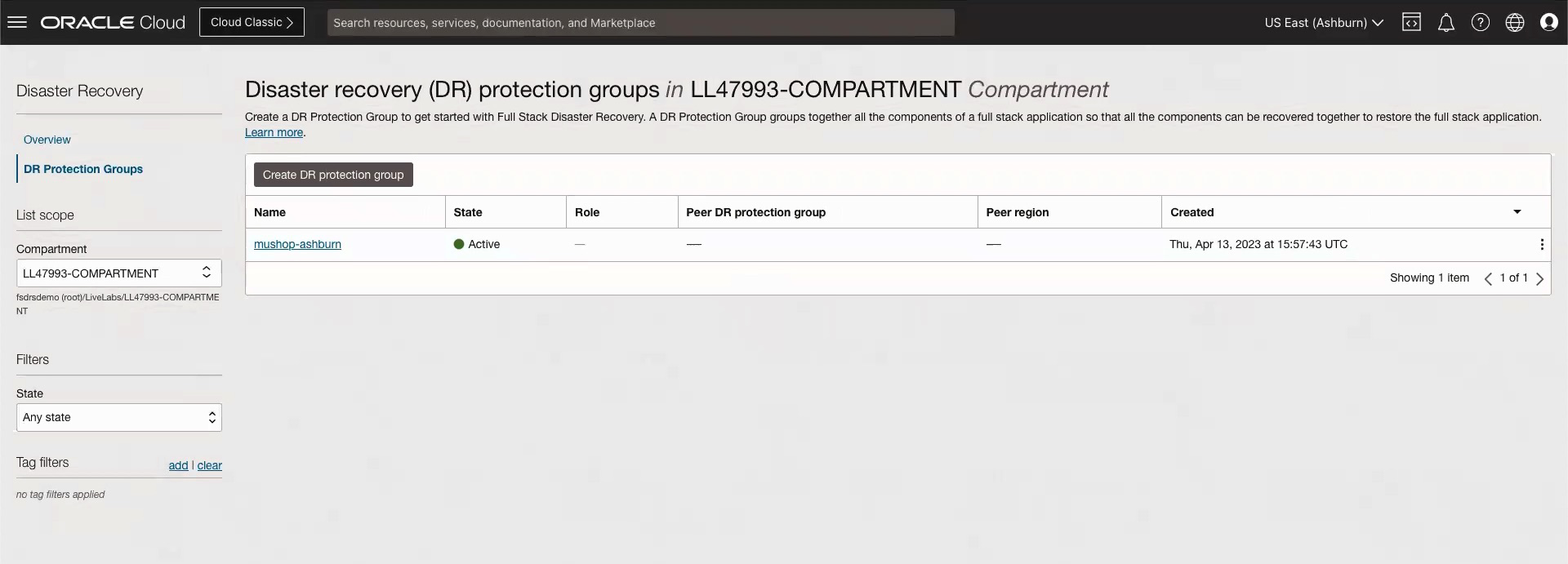
First, we identify all the components and dependencies of the application stack, in this case, VMs, database, and volume groups. Next, create disaster recovery protection groups in the primary (Ashburn) and standby (Phoenix) regions. A disaster recovery protection group is a grouping of OCI resources in the application that must be treated as a full stack when you run a recovery procedure. The following images show the disaster recovery protection groups created in Ashburn and Phoenix.

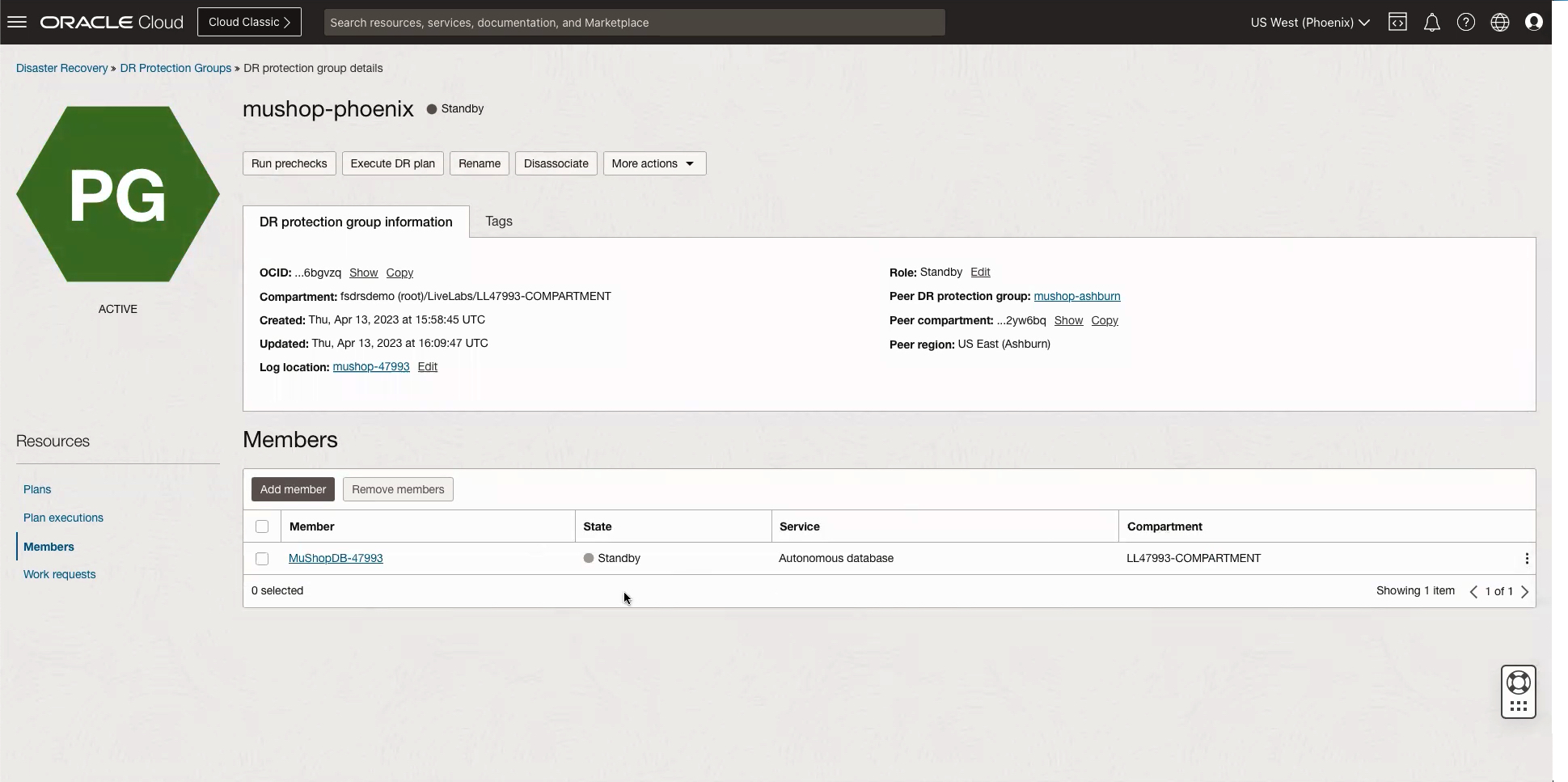
Then, we associate the disaster recovery protection groups and group the components in each region as members of the corresponding group. Because this deployment used a warm-standby model, in the primary region, I chose compute, database, and volume group instances as members of the protection group, and in the secondary region I only included the database as a member, as shown in the following graphics:

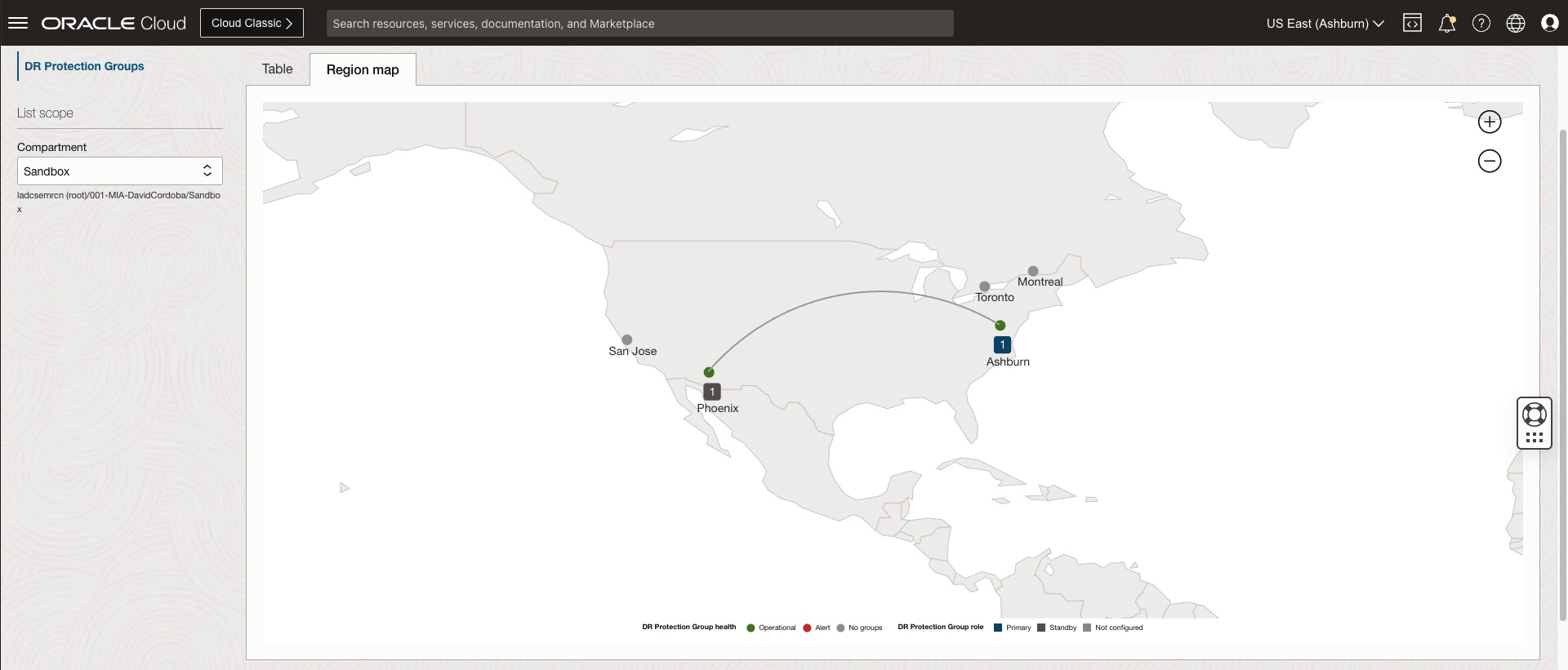
We can also see on the region map, the regions associated to the disaster recovery protection groups, the active and standby roles and the health status of these protection groups.
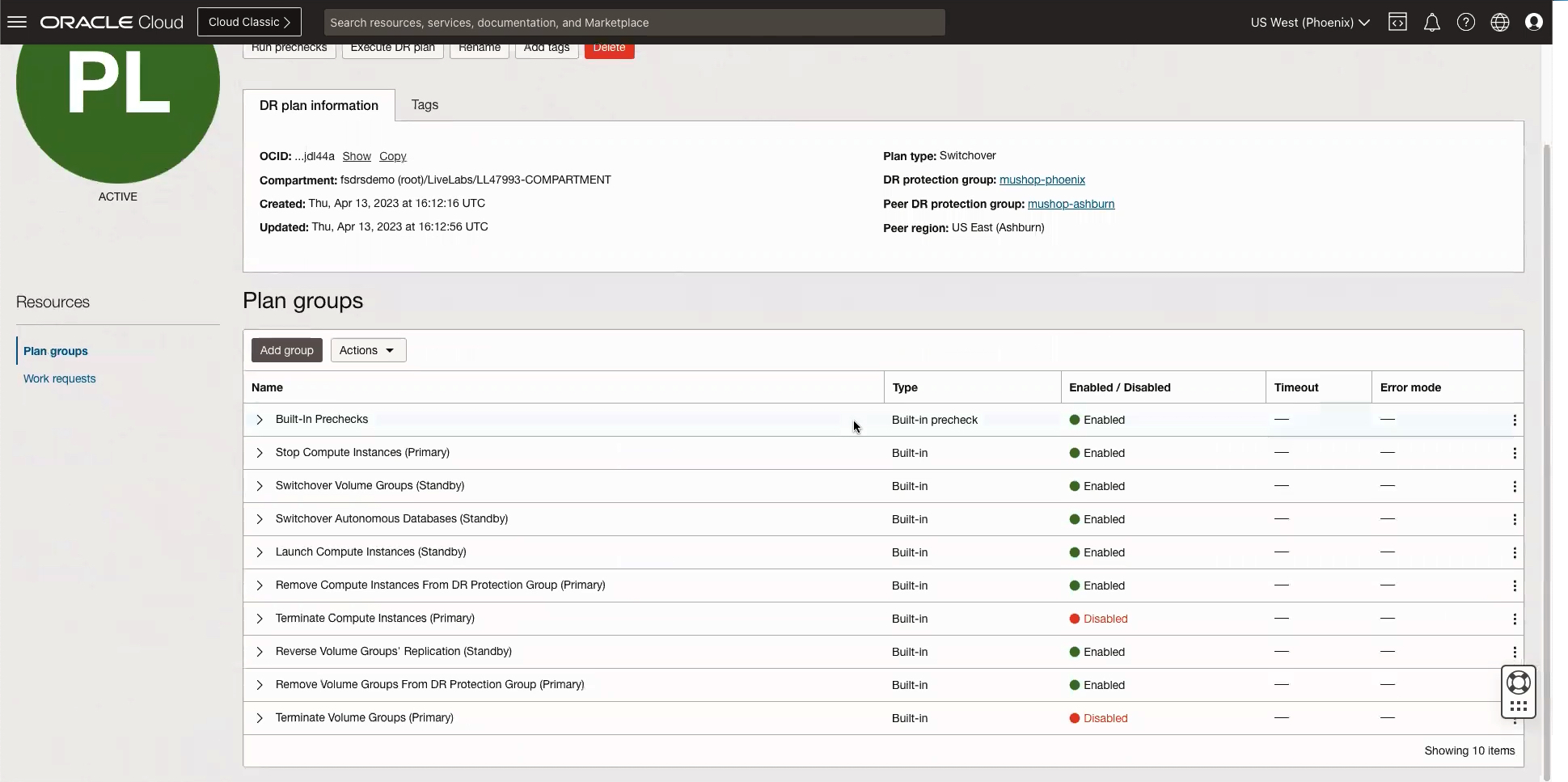
Next, create disaster recovery plans to run the switchover. The disaster recovery plan represents the workflow associated with a pair of disaster recovery protection groups and is a sequence of plan groups. Plan groups are groups of steps that can be created automatically or by you, such as provisioning Compute instances or running a database switchover. The disaster recovery plan can only be created in a disaster recovery protection group that has a standby role.
In this example, the plan automatically generated the steps to stop instances at the primary site, switch over the database and volume groups, and power on the instances in the standby region. The following image shows the generated disaster recovery plan.
After disaster recovery plan creation, run the prechecks. Prechecks are a group of validations to ensure that the plan is going to run correctly. The workflow that runs the switchover starts after we run the prechecks. The following image shows the plan processing steps and its successful completion.
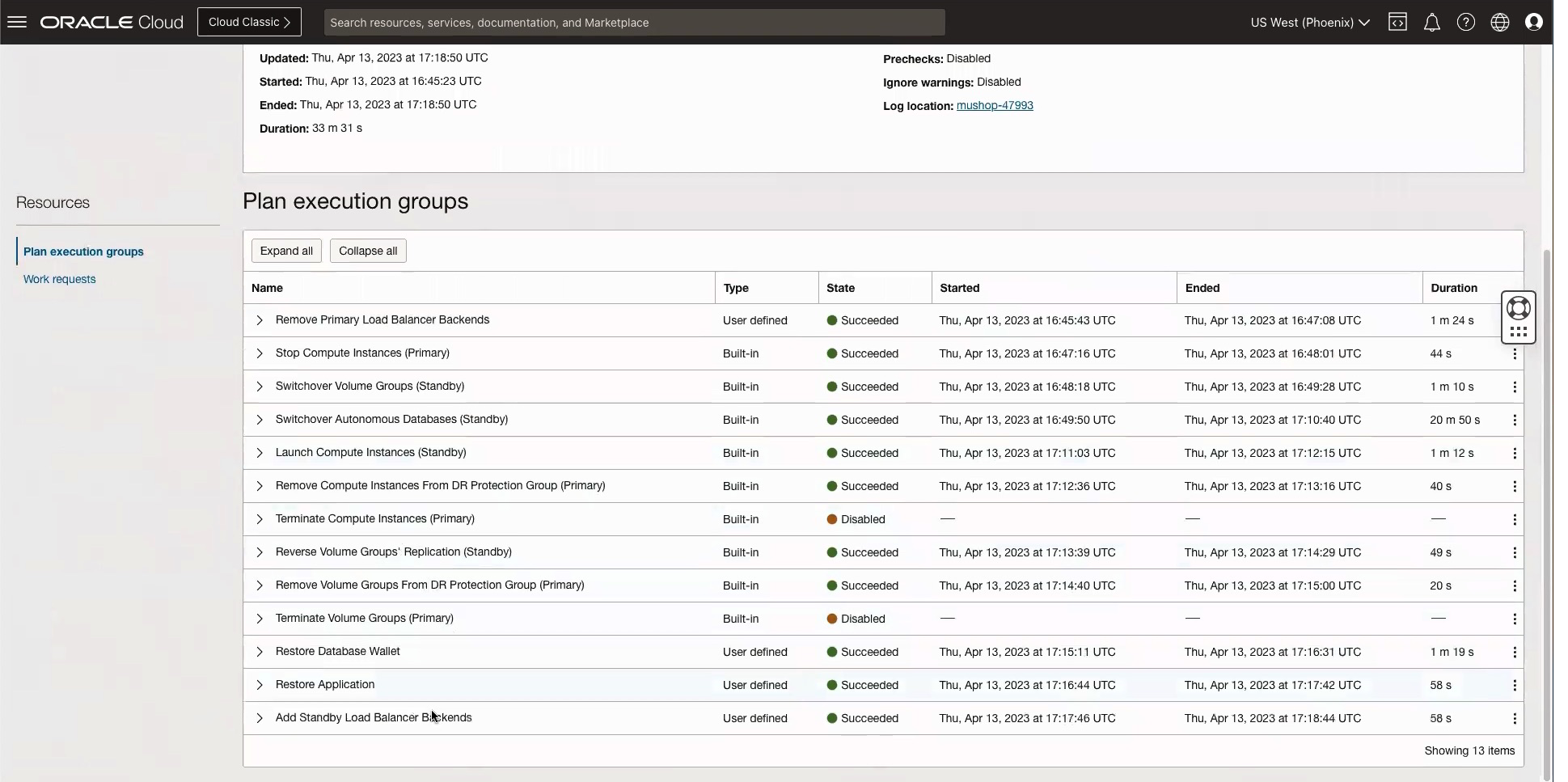
Running the switchover accomplishes the following important things:
- It validates that the switchover plan works.
- It automatically changes the role of the primary protection group to standby after the switchover has completed.
You can create the switchover plan in the first region because it’s now the standby. The new switchover plan then allows you to switch back to the original primary region at any time. Creating these plans is a one-time task. You can keep using them to switch back and forth between regions after you create them. To switch between regions, you must create a switchover and failover plan for both disaster recovery protection groups.
Finally, after verifying that the application is running in the primary region, we can test the same in the standby region.
Try it yourself
You can keep exploring the OCI Full Stack Disaster Recovery service to achieve your current architecture deployment. For a full tutorial on a similar subject, see Move a virtual machine between OCI regions using Full Stack Disaster Recovery. For more information about the service, you can visit Full Stack Disaster Recovery website, and check out the Oracle Cloud Infrastructure Full Stack Disaster Recovery documentation.
