※ 本記事は、Pankaj Chandiramani による”Oracle Globally Distributed Database supports RAFT Replication in Oracle Database 23ai“を翻訳したものです。
2024年5月2日
分散型データベースは、大規模で複雑なデータセット、スケーラビリティ、柔軟性、および現代のアプリケーション設計やアーキテクチャとの互換性を管理する能力により、人気と意義を高めています。組織は、クラウドベースのソリューションとマイクロサービスベースのアーキテクチャを採用しているため、分散型データベースの需要が急増すると予想されています。企業は、より適応性の高い戦略を採用しながら、水平方向のスケーラビリティを促進し、データの耐久性を確保し、高可用性を維持する革新的なデータベース・ソリューションを絶えず探しています。
トランザクション・ボリュームを処理し、最適なパフォーマンスを確保するには、データベースのスケーリングが不可欠です。さらに、地理的なスケーリングはグローバルなビジネス環境において、世界のさまざまな地域にある顧客のニーズに合わせてサービスを利用するために重要です。
アベイラビリティ・ゾーン/アベイラビリティ・ドメイン(AZ/AD)またはクラウド・プロバイダ全体に障害が発生した場合の存続を保証するために企業が努力しているため、データベースをスケーリングする際には、自己回復性も非常に重要です。
水平および地理的なスケーリングの必要性と相まって、分散データベースの需要の高まりは、Oracle Distributed Databaseなどの次世代メソドロジの採用に向けてビジネスを推進しています。これにより、効率的なパフォーマンスと自己回復性が確保され、現代の消費者の期待に応えることができます。Oracle Distributed Databaseはデータ分散システムとして機能し、複数のサーバーまたはシャード間でデータをパーティション化するための高度な技術を採用しているため、優れたパフォーマンス、可用性およびスケーラビリティを実現します。
Oracle Database 23aiでは、すべてのシャード間のレプリケーションの自動構成を容易にするコンセンサスベースのレプリケーション・プロトコルであるRaftレプリケーションという形で注目すべき機能が導入されています。Raftレプリケーションはアプリケーションとシームレスに統合され、その操作の透明性を提供します。シャード・ホストの障害または分散データベースの構成の動的な変更の場合、Raftレプリケーションはレプリケーション設定を自動的に再構成します。システムは、レプリケーション係数を構成するために宣言的なアプローチをとり、指定した数のレプリカを一貫して使用できるようにします。
Swiftフェイルオーバーは、Raftレプリケーションの重要な属性であり、ノード障害が発生した場合でも、すべてのノードをアクティブなままにできます。特に、この機能には自動サブセカンド・フェイルオーバー・メカニズムが組み込まれており、データの整合性と運用の継続性が強化されています。この機能は、可用性が高くスケーラブルなデータベース・システムを求める組織に適しています。
レプリケーション・ユニット
Raftレプリケーションが有効な場合、分散データベースには複数のレプリケーション・ユニットが含まれます。レプリケーション・ユニット(RU)は、同じレプリケーション・トポロジを持つ一連のチャンクです。各RUには、異なるシャードに配置された3つのレプリカがあります。Raftコンセンサス・プロトコルは、障害、ネットワーク・パーティショニング、メッセージ損失または遅延が発生した場合にレプリカ間で一貫性を維持するために使用されます。
各シャードには、複数のRUからのレプリカが含まれます。これらのレプリカの一部はリーダーで、一部はフォロワです。Raftレプリケーションは、シャード間でリーダーとフォロワのバランスのとれた分散を維持しようとします。デフォルトでは、各シャードは2つのRUのリーダーであり、他の4つのRUのフォロワです。これにより、すべてのシャードがアクティブになり、ハードウェア・リソースの最適な使用が可能になります。
Raftグループ
各レプリケーション・ユニットには、1つのチャンク・セットのみが含まれ、リーダーとフォロワのセットがあり、これらのメンバーはRaftグループを形成します。レプリケーション・ユニットのリーダーとそのフォロワには、次に示すように、異なるシャード内の同じチャンク・セットのレプリカが含まれます。シャードは、一部のレプリケーション・ユニットのリーダーと、他のレプリケーション・ユニットのフォロワになります。
データの特定のサブセットに対するすべてのDMLは、最初にリーダーで実行され、次にそのフォロワにレプリケートされます。
レプリケーション・ファクタ
レプリケーション・ファクタ(RF)は、RAFTグループの参加者の数を決定します。この数字には、リーダーとそのフォロワが含まれます。
RUには、書込みに使用できる大多数のレプリカが必要です。
- RF = 3: 1つのレプリカ障害を許容
- RF = 5: 2つのレプリカ障害を許容
Oracle Globally Distributed Databaseでは、データベース全体に対してレプリケーション・ファクタが指定されます。つまり、データベース内のすべてのレプリケーション単位が同じRFを持ちます。フォロワの数は2に制限されているため、レプリケーション・ファクタは3です。
Raftログ
各RUは、ログを保持し、リーダーからフォロワへの変更をレプリケートする一連のRaftログおよびOSプロセスに関連付けられています。これにより、複数のRUを1つのシャード内および複数のシャード間で独立してパラレルに操作できます。また、RUの数を変更することで、レプリケーションをスケール・アップおよびスケール・ダウンできます。
DMLによって行われたデータへの変更は、Raftログに記録されます。コミット・レコードは、各ユーザー・トランザクションの最後にも記録されます。ラフト・ログは、REDOログとは別に保持され、行に対する論理的な変更が含まれます。論理レプリケーションは、フォロワが受信トランザクションに対してオープンであり、すぐにリーダーになる可能性があるため、フェイルオーバー時間を短縮します。
Raftプロトコルは、フォロワがリーダーによって生成された順序と同じ順序でログ・レコードを受信することを保証します。ユーザー・トランザクションは、フォロワの半分がコミット・レコードの受信を確認してRaftログに書き込むとすぐにリーダーでコミットされます。
トランザクション
ビジー状態のシステムでは、複数のコミットが同時に確認されます。トランザクション・コミット・レコードの同期伝播によって、データ損失はゼロになります。ただし、DML変更レコードのフォロワへの適用は、トランザクションの待機時間への影響を最小限に抑えるために非同期に行われます。
リーダー選定プロセス
Raftプロトコルによると、フォロワが特定の期間リーダーからデータまたはハートビートを受信しない場合、新しいリーダー選定プロセスが開始されます。
デフォルトのハートビート間隔は150ミリ秒で、ランダム化された選択タイムアウト(最大150ミリ秒)を使用して、複数のシャードが同時に選択をトリガーすることを防ぎ、票を分割します。
ノード障害
ノードの障害およびリカバリは、アプリケーションへの影響を最小限に抑えながら、自動化された方法で処理されます。
フェイルオーバー時間は3秒未満で、可用性ゾーン間のネットワーク待機時間は10ミリ秒未満です。これには、障害検出、シャード・フェイルオーバー、リーダーシップの変更、新しいリーダーへのアプリケーションの再接続、および以前のようにビジネス・トランザクションの継続が含まれます。
アプリケーションに対する障害の影響をさらに抽象化するには、JDBCドライバで再試行を構成し、エンド・カスタマ・エクスペリエンスを設定すると、特定のリクエストがエラーになるのではなく、時間がかかることになります。
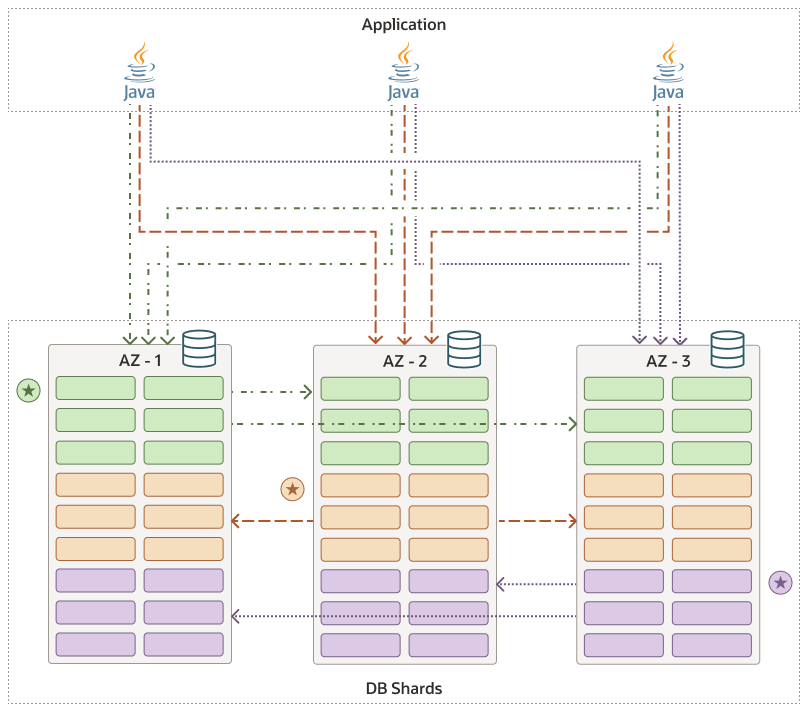
次に、3つすべてのシャードが正常な状態である分散データベースの図を示します。アプリケーション・リクエストは3つのシャードすべてに到達でき、リーダーとフォロワ間のレプリケーションはシャード間で進行します。
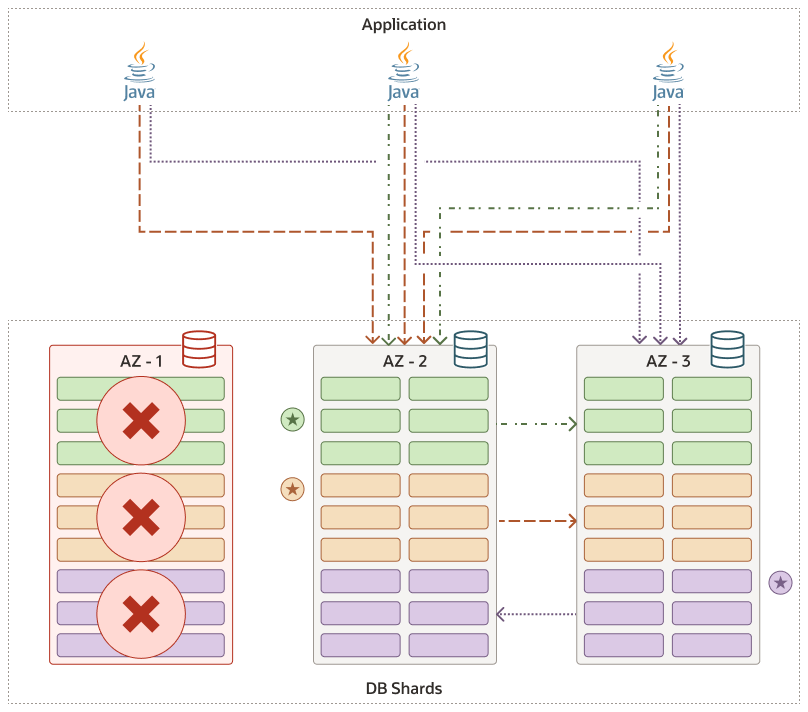
リーダーノード障害
レプリケーション・ユニットのリーダーが使用不可になると、フォロワはRaftプロトコルを使用して新しいリーダー選定プロセスを開始します。
大部分のノード(定足数)がまだ健全であるかぎり、Raftプロトコルは、使用可能なノードから新しいリーダーが選択されるようにします。
フォロワの1人が新しいリーダーになることに成功すると、先を見越した通知がシャードからリーダーシップの変化のクライアント・ドライバに送信されます。クライアント・ドライバは、新しいリーダー・シャードへのリクエストのルーティングを開始します。ルーティング・クライアント(UCPなど)は、ONS通知を使用してシャードおよびチャンク・マッピングを更新し、トラフィックをリーダーにルーティングするように通知されます。
このフェイルオーバーおよび再接続期間中に、JDBCドライバ構成で再試行間隔および再試行回数の設定で待機および再試行するようにアプリケーションを構成できます。これらは、現在のRACインスタンスのフェイルオーバー構成と非常によく似ています。
新しいリーダーに接続すると、アプリケーションは以前と同様に機能し続けます。
次の図は、最初のシャードが失敗し、その最初のシャードでリーダーがかつて存在していたレプリケーション・ユニットの新しいリーダーが、2番目のシャードで新しいリーダーに置換されたことを示しています。
Oracle Globally Distributed Databaseは、システム管理のシャード・データベースでRaftレプリケーションを有効化および管理するためのコマンドとオプションをGDSCTL CLIで提供します。
Raftレプリケーションに関する詳細は、Oracle Globally Disributed DatabaseマニュアルのRaftレプリケーションの構成および管理をご確認ください。
