Distributed databases are gaining increasing popularity and significance due to their capacity to manage large and intricate datasets, scalability, flexibility, and compatibility with contemporary application designs and architectures. As organizations embrace cloud-based solutions and microservices-based architectures, there is an anticipated surge in the demand for distributed databases. Businesses are on a continual quest for innovative database solutions that facilitate horizontal scalability, ensure data durability, and maintain high availability while adopting more adaptable strategies.
Scaling databases is imperative for handling transactional volume and ensuring optimal performance. Additionally, in an increasingly global business landscape, geographic scaling is crucial to tailor services to customers located in different parts of the world.
Resilience is a vital consideration when scaling databases, as businesses strive to guarantee survival in the event of the failure of an entire Availability Zone/Availability Domain (AZ/AD) or cloud provider.
The escalating demand for distributed databases, coupled with the necessity for horizontal and geographic scaling, is propelling businesses toward adopting next-generation methodologies such as Oracle Distributed Database. This ensures efficient performance and resilience, meeting the expectations of modern consumers. Oracle Distributed Database functions as a data distribution system, employing advanced techniques to partition data across multiple servers or shards, thereby delivering exceptional performance, availability, and scalability.
Oracle Database 23ai introduces a noteworthy feature in the form of Raft replication, a consensus-based replication protocol that facilitates automatic configuration of replication across all shards. Raft replication seamlessly integrates with applications, providing transparency in its operation. In case of shard host failures or dynamic changes in the distributed database’s composition, Raft replication automatically reconfigures replication settings. The system takes a declarative approach to configure the replication factor, ensuring a specified number of replicas are consistently available.
Swift failover is a key attribute of Raft replication, enabling all nodes to remain active even in the event of a node failure. Notably, this feature incorporates an automatic sub-second failover mechanism, reinforcing both data integrity and operational continuity. Such capabilities make this feature well-suited for organizations seeking a highly available and scalable database system.
When Raft replication is enabled, a distributed database contains multiple replication units. A replication unit (RU) is a set of chunks that have the same replication topology. Each RU has multiple replicas placed on different shards. The Raft consensus protocol is used to maintain consistency between the replicas in case of failures, network partitioning, message loss, or delay.
Replication Unit
When Raft replication is enabled, a distributed database contains multiple replication units. A replication unit (RU) is a set of chunks that have the same replication topology. Each RU has three replicas placed on different shards. The Raft consensus protocol is used to maintain consistency between the replicas in case of failures, network partitioning, message loss, or delay.
Each shard contains replicas from multiple RUs. Some of these replicas are leaders and some are followers. Raft replication tries to maintain a balanced distribution of leaders and followers across shards. By default each shard is a leader for two RUs and is a follower for four other RUs. This makes all shards active and provides optimal utilization of hardware resources.
Raft Group
Each replication unit contains exactly one chunk set and has a leader and a set of followers, and these members form a raft group. The leader and its followers for a replication unit contain replicas of the same chunk set in different shards as shown below. A shard can be the leader for some replication units and a follower for other replication units.
All DMLs for a particular subset of data are executed in the leader first, and then are replicated to its followers.
Replication Factor
The replication factor (RF) determines the number of participants in a RAFT group. This number includes the leader and its followers.
The RU needs a majority of replicas available for write.
- RF = 3: tolerates one replica failure
- RF = 5: tolerates two replica failures
In Oracle Globally Distributed Database , the replication factor is specified for the entire database, that is all replication units in the database have the same RF. The number of followers is limited to two, thus the replication factor is three.
Raft Log
Each RU is associated with a set of Raft logs and OS processes that maintain the logs and replicate changes from the leader to followers. This allows multiple RUs to operate independently and in parallel within a single shard and across multiple shards. It also makes it possible to scale the replication up and down by changing the number of RUs.
Changes to data made by a DML are recorded in the Raft log. A commit record is also recorded at the end of each user transaction. Raft logs are maintained independently from redo logs and contain logical changes to rows. Logical replication reduces failover time because followers are open to incoming transactions and can quickly become the leader.
The Raft protocol guarantees that followers receive log records in the same order they are generated by the leader. A user transaction is committed on the leader as soon as half of the followers acknowledge the receipt of the commit record and writes it to the Raft log.
Transactions
On a busy system, multiple commits are acknowledged at the same time. The synchronous propagation of transaction commit records provides zero data loss. The application of DML change records to followers, however, is done asynchronously to minimize the impact on transaction latency.
Leader Election Process
Per Raft protocol, if followers do not receive data or heartbeat from the leader for a specified period of time, then a new leader election process begins.
The default heartbeat interval is 150 milliseconds, with randomized election timeouts (up to 150 milliseconds) to prevent multiple shards from triggering elections at the same time, leading to split votes.
Node Failure
Node failure and recovery are handled in an automated way with minimal impact on the application.
The failover time is sub-3 seconds with less than 10 millisecond network latencies between Availability Zones. This includes failure detection, shard failover, change of leadership, application reconnecting to new leader, and continuing business transactions as before.
The impact of the failure on the application can further be abstracted by configuring retries in JDBC driver and end customer experience will be that a particular request took longer rather than getting an error.
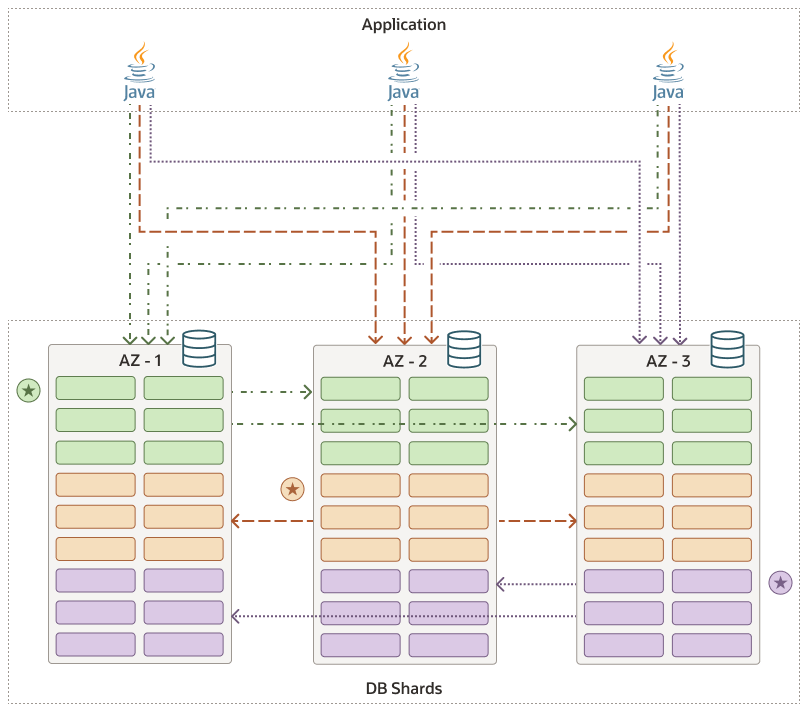
The following is an illustration of a distributed database with all three shards in a healthy state. Applications requests are able to reach all three shards, and replication between the leaders and followers is ongoing between the shards.
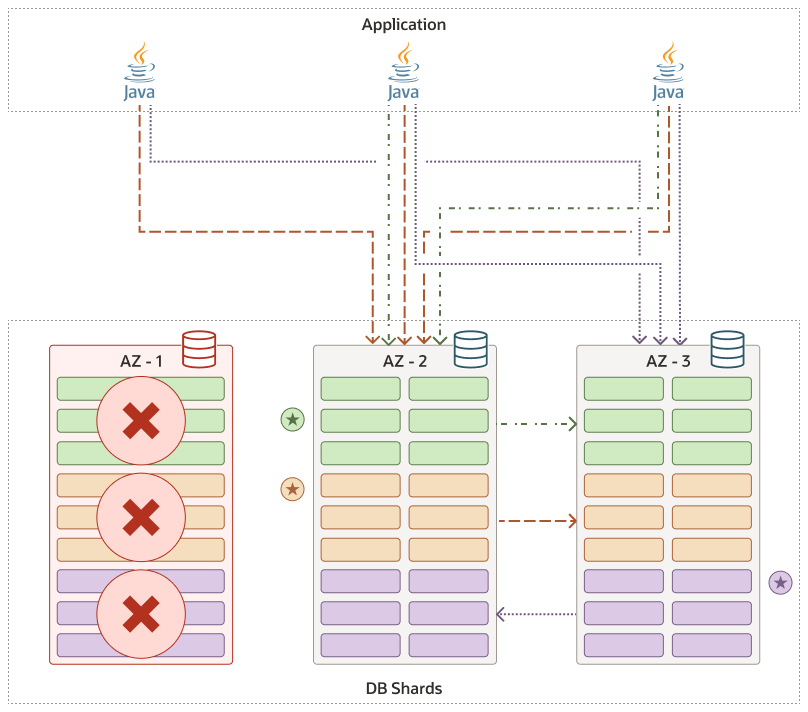
Leader Node Failure
When the leader for a replication unit becomes unavailable, followers will initiate a new leader election process using the Raft protocol.
As long as a majority of the nodes (quorum) are still healthy, the Raft protocol will ensure that a new leader is elected from the available nodes.
When one of the followers succeeds in becoming the new leader, proactive notifications are sent from the shard to the client driver of leadership change. The client driver starts routing the request to the new leader shard. Routing clients (such as UCP) are notified using ONS notifications to update their shard and chunk mapping, ensuring that they route traffic to the leader.
During this failover and reconnection period, the application could be configured to wait and retry with the retry interval and retry counts settings at the JDBC driver configuration. These are very similar to the present RAC instance failover configuration.
Upon connecting to new leader, the application will continue to function as before.
The following diagram shows that the first shard failed, and that a new leader for the replication unit whose leader was once on that first shard has been replaced by a new leader in the second shard.
Oracle Globally Distributed Database provides commands and options in the GDSCTL CLI to enable and manage Raft replication in a system-managed sharded database.
See Raft Replication Configuration and Management for topics about configuring and managing Raft replication.
To learn more about Oracle Distributed Database, visit : https://www.oracle.com/database/distributed-database/
