※ 本記事は、Niranjan Mohapatra, Shankar Ratneshwaran, Srinarayan Srikanthanによる”Generative AI inference workloads using OCI Compute with Intel Xeon CPU“を翻訳したものです。
2024年11月5日
Intel Xeon CPUは、生成AI(GenAI)推論ワークロードを実行できる能力が優れています。OracleとIntelは、Intel Xeonプロセッサを搭載したOracle Cloud Infrastructure (OCI) コンピュート・シェイプを使用して、GenAI推論パフォーマンスを共同で検証しました。OCIのハードウェア使用率を最大化するには、特定のユース・ケースに基づくGenAIワークロードの適切なサイズ設定が重要です。CPUインスタンスのタイプにマップされたユース・ケースの概要リストは、AI開発者がデプロイメントをより簡単にナビゲートするのに役立ちます。このブログ投稿は、さまざまな業界とその代表的なワークロードをOCI上のIntel Xeon CPUインスタンスにマッピングすることを目的としています。
GenAIモデルのコンピュート要件は、ユース・ケースによって異なり、次のディメンションを含めることができます:
- スループットとレイテンシの要件: スループットとレイテンシは、ワークロードがバックグラウンド・バッチ・プロセスとして実行されるか、対話型APIベースのサービスとして実行されるかによって異なります。
- 入力トークンと出力トークンの数: 各リクエストで処理されるトークンの量を示します。
- 同時ユーザーまたはバッチ・サイズの数: 同時ユーザー数または処理中のバッチのサイズが含まれます。
- GenAIモデルのサイズ: モデル内のニューロンまたはパラメータの数を示します。
これらの各ディメンションを評価して、適切なインスタンスのサイズを決定する必要があります。
パートナーのIntelと協力して、仮想マシン(VM)インスタンスとベア・メタル(BM)インスタンスの2つのタイプのOCIインスタンスで大規模な言語モデル(LLM)ワークロードを実行するためのLlama2-7BおよびLlama2-13Bモデルを評価しました。Intel Extensions for PyTorch (IPEX)およびIntel OpenVINOツールキット(OpenVINO)をテスト用のフレームワークとして使用しました。これらのフレームワークを使用したGeAIモデルのパフォーマンス最適化は、ユーザー・リクエストのモデル・レイテンシとサーバーの効率性をバランスさせることで、有望な結果を達成するのに役立ちます。
パフォーマンスの手法とユース・ケース
モデルはIPEXを使用してホストされ、IPEXの例で概説されているPythonスクリプトを介してアクセスされました。Intel OpenVINO Model Server (OVMS)を使用して、モデルをホストし、標準のネットワーク・プロトコルを介してソフトウェア・コンポーネントからアクセスできるようにしました。モデルはOVMSでホストされ、リクエストは汎用リモート・プロシージャ・コール(gRPC)プロトコルを使用して送信されました。
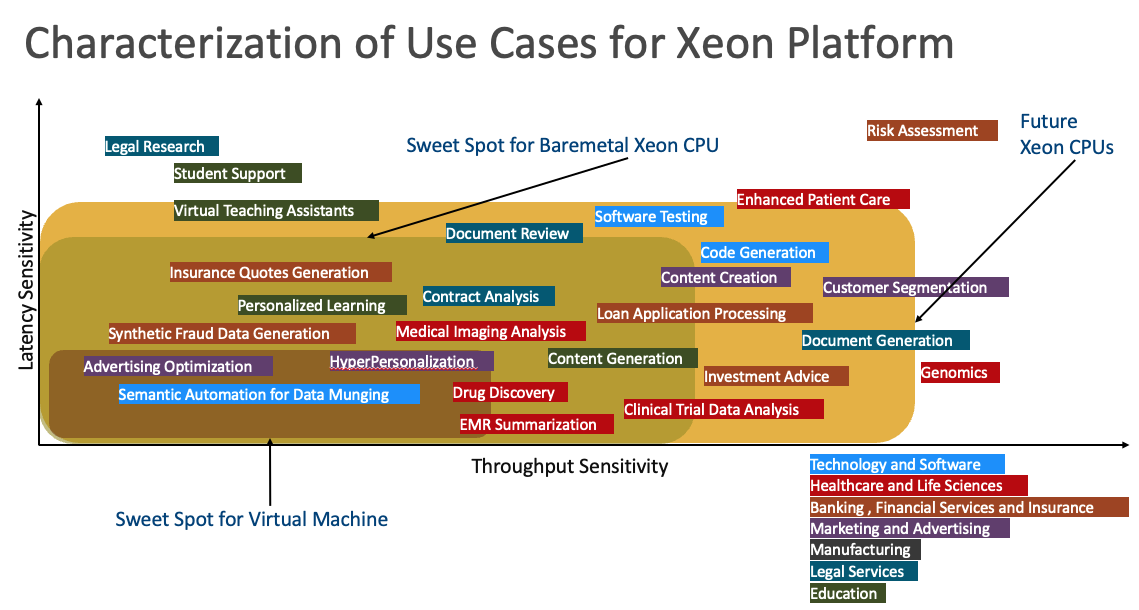
この図は、x軸のスループット感度(各ユース・ケースに必要なスループット・レベルを示す)およびy軸のレイテンシ感度(各ユース・ケースに必要なレイテンシを示す)を示す様々な業界のユース・ケースを示しています。これらのユース・ケースは、OCIインスタンスVM.Standard3.FlexとBM.Standard3.64の両方のタイプに最適です。
法的調査など、レイテンシに敏感なユース・ケースでは、Legaleseに特化した事前トレーニング済モデルに基づく迅速な対応が必要です。スペクトルのもう一方の端には、Genomicsのような高スループットの感度を持つユースケースがあります。Financial Risk Assessmentなど、レイテンシとスループットの両方に敏感なユース・ケースもありますが、データ・マングのセマンティック自動化など、レイテンシとスループットの機密性が低いユース・ケースもあります。
これらのパラメータに基づいて、仮想マシン・インスタンスは、広告やハイパーパーソナライゼーションなどの低レイテンシとスループットの機密性でユース・ケースを効果的に管理できます。保険見積りの生成、契約分析、合成不正データ生成など、レイテンシとスループットの機密性がわずかに高いユース・ケースは、ベア・メタル・インスタンスに適している可能性があります。さらに高いセンシティブ性のために、将来のCPUはコード生成、顧客セグメンテーション、投資助言などのタスクを処理する可能性があります。最後に、財務リスク評価やゲノミクスなど、感受性が最も高いユース・ケースでは、GPUが必要になる場合があります。
パフォーマンス監視
ベア・メタル・インスタンスとVM OCIインスタンスの両方を使用して、パフォーマンス・ベンチマークを実施しました。ベア・メタル・インスタンスは、コンテンツ生成やローン・アプリケーション処理など、より高いスループット・プロファイルを必要とするユース・ケースに対してパフォーマンスが向上していることがわかりました。ベア・メタル・インスタンスは、保険見積り生成や法的契約分析など、レイテンシが低いプロファイルを必要とするユース・ケースでも高いパフォーマンスを発揮します。
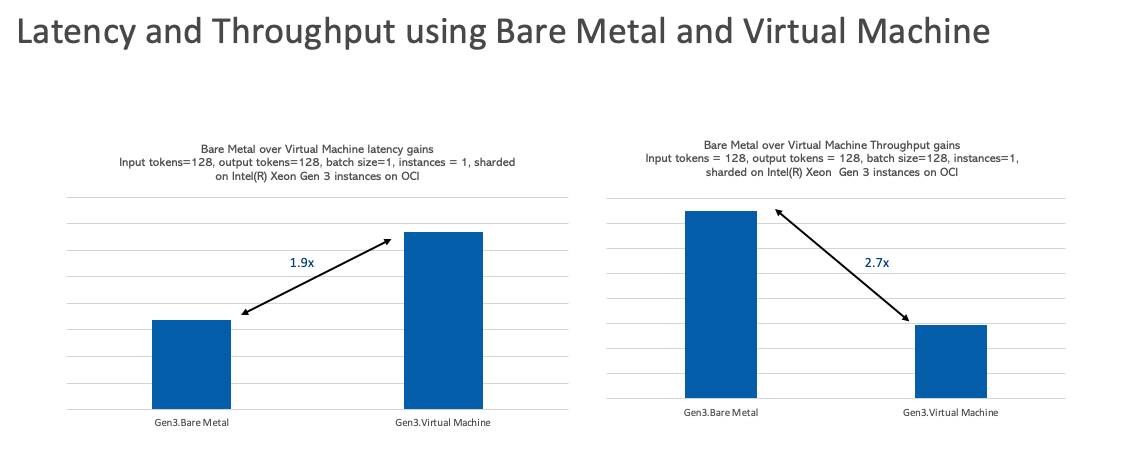
入力トークンと出力トークン
処理および生成された番号トークンに対する機密性が重要な自然言語ベースのワークロードの場合、VMノードは、製品機能に関する特定の問合せなど、トークンの量が少ない短い質問と回答のユース・ケースに適しています。より大きな回答を生成したり、大量のテキストを要約して理解するユース・ケースの場合、ベア・メタルOCIインスタンスは、法的文書の要約やレビューやコード生成など、より適切です。

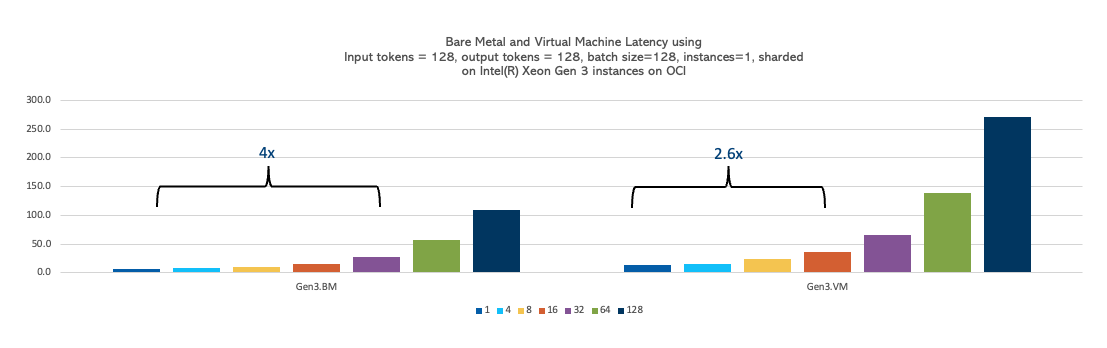
同時ユーザーまたはバッチ・サイズ
バッチ サイズを1から128に変更し、入力トークンと出力トークンを128に一定に保ちながら、いくつかの実験を行いました。OCI Compute VMインスタンスはバッチ・サイズ 16までスケーリングできるのに対し、ベア・メタル・インスタンスはバッチ・サイズ 32までスケーリングできることがわかりました。そのため、より大きなデータ・ボリューム(より大きなバッチ・サイズ)を同時に処理する必要があるユース・ケースはベア・メタル・インスタンスに適しており、この要件を満たさないユース・ケースはVMインスタンスで効果的に実行できます。
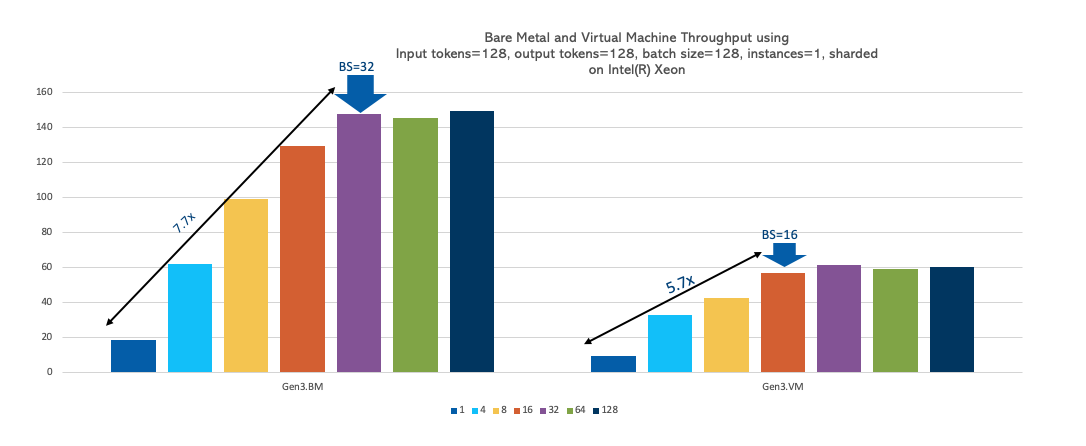
モデルのサイズ
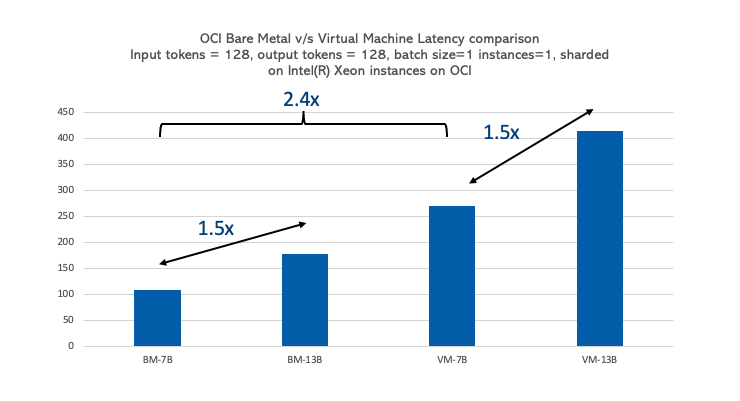
モデルのサイズは、そのパフォーマンスがCPUに比例して影響します。モデル・サイズが70億から130億のパラメータから1.8倍増加すると、OCI Computeベア・メタル・インスタンスとVMインスタンスの両方でレイテンシが1.5倍増加し、ベア・メタル・インスタンスはVMインスタンスより2.4倍高速になります。モデル・サイズが大きいほど、コンピュート要件が高くなるため、ほぼ同等のレイテンシが増加します。ただし、ベア・メタルは、オーバーヘッドの削減により、予想よりもサイズの大きいモデルを適切に処理します。そのため、Gemma-1B、Phi-3-Mini、opt-125、Llama2-7Bなどの小規模なモデルをVMインスタンスでホストし、ベア・メタル・インスタンスで大規模なモデルをホストできます。
まとめ
Intel Xeonプロセッサを搭載したOCI VMインスタンスとベア・メタル・インスタンスの両方で、GenAI推論ワークロードを実行できます。トークン・サイズが小さくバッチ・サイズが小さい生成AI自然言語推論ワークロードは、仮想マシンによって効果的に処理できます。一方、入力および出力トークンのサイズが大きく、バッチ・サイズが大きいワークロードは、ベア・メタル・インスタンスに適しています。マーケティングおよび広告分野における広告の最適化やハイパーパーソナライゼーション、テクノロジ分野におけるセマンティック・オートメーションなど、Intel Xeon VMに特に適しているユース・ケースがあります。ベア・メタル・インスタンスは、銀行および保険業界における保険見積りの生成と合成不正データの生成、医療分野における医療画像分析と創薬、教育分野でのパーソナライズされた学習とコンテンツ生成など、幅広いユース・ケースを処理できます。
詳細は、次のリソースを参照してください:
https://docs.oracle.com/iaas/Content/Compute/References/computeshapes.htm#bm-standard
https://docs.openvino.ai/2023.3/ovms_what_is_openvino_model_server.html
