The Intel Xeon CPU is highly capable of running generative AI (GenAI) inference workloads. Oracle and Intel have jointly validated GenAI inference performance using Oracle Cloud Infrastructure (OCI) Compute shapes with Intel Xeon processors. To maximize hardware utilization on OCI, right-sizing GenAI workloads based on specific use cases is important. A high-level list of use cases mapped to types of CPU instances can help AI developers navigate deployments more easily. This blog post aims to map various industries and their representative workloads to Intel Xeon CPU instances on OCI.
The compute requirements for a GenAI model can vary depending on the use case and can include following dimensions:
- Throughput and latency requirements: Throughput and latency depend on whether the workload runs as a background batch process or an interactive API-based service.
- Number of input and output tokens: Refers to the volume of tokens processed in each request.
- Number of simultaneous users or batch sizes: Involves the number of concurrent users or the size of batches being processed.
- Size of the GenAI model: Indicates the number of neurons or parameters in the model.
Each of these dimensions must be evaluated to determine the appropriate instance sizing.
In collaboration with our partner Intel, we evaluated the Llama2-7B, and Llama2-13B models for running large language model (LLM) workloads on two types of OCI instances: A virtual machine (VM) instance and a bare metal (BM) instance. We used Intel Extensions for PyTorch (IPEX) and the Intel OpenVINO toolkit (OpenVINO) as frameworks for testing. Performance optimization of GeAI models using these frameworks helps achieve promising results by balancing model latency for user requests with server efficiency.
Performance methodology and use cases
The models were hosted using IPEX and accessed through Python scripts outlined in the IPEX examples. We used the Intel OpenVINO Model Server (OVMS) was used to host the models and make them accessible to software components through standard network protocols. The models were hosted on OVMS, and requests were sent using generic Remote Procedure Calls (gRPC) protocols.
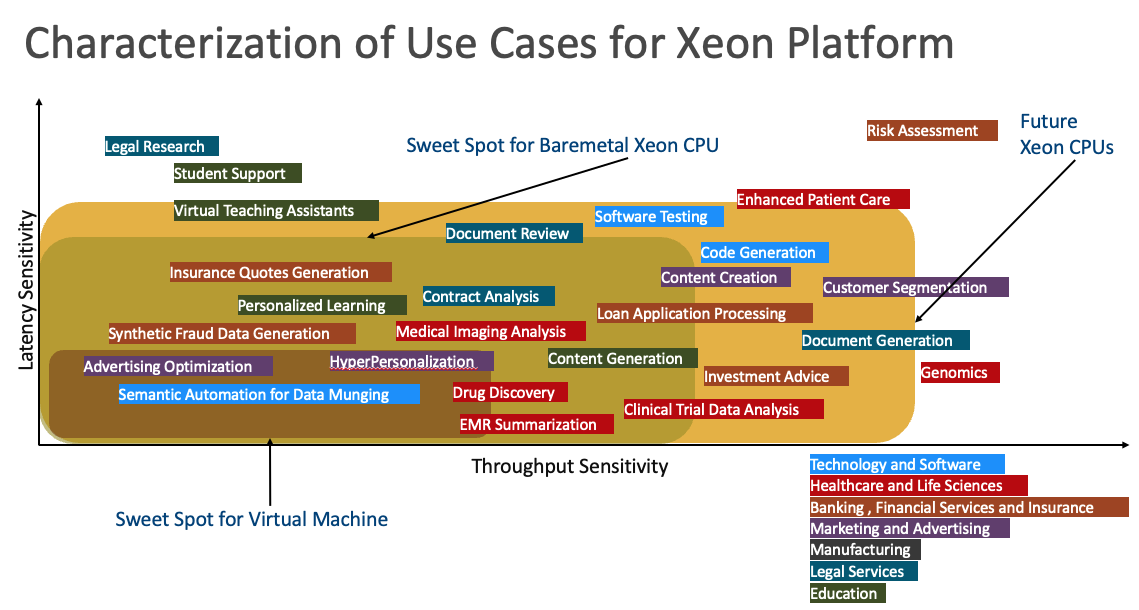
This figure illustrates a range of use cases across different industries, plotted with throughput sensitivity on the x-axis (indicating the required throughput level for each use case) and latency sensitivity on the y-axis (indicating the required latency for each use case). These use cases are ideally suited for both type of OCI instances VM.Standard3.Flex and BM.Standard3.64.
The use cases with high latency sensitivity, such as legal research, require fast responses based on pre-trained models specialized in Legalese. On the other end of the spectrum are use cases with high throughput sensitivity, like Genomics. Some use cases are sensitive to both latency and throughput, such as Financial Risk Assessment, whereas others have low latency and throughput sensitivity, such as semantic automation for data munging.
Based on these parameters, virtual machine instances can effectively manage use cases with lower latency and throughput sensitivity, such as advertising and hyper-personalization. Use cases with slightly higher latency and throughput sensitivity, like insurance quotes generation, contract analysis, and synthetic fraud data generation, might be better suited for bare metal instances. For even higher sensitivities, future CPUs might handle tasks like code generation, customer segmentation, and investment advice. Finally, use cases with the highest sensitivities, such as financial risk assessment and genomics, might require GPUs.
Performance observations
We conducted the performance benchmark using both the bare metal and VM OCI instances. We observed that bare metal Instances perform better for the use case requiring a higher throughput profile, such as content generation and loan application processing. Bare metal instances also perform better for the use cases needing a lower latency profile, such as insurance quote generation or legal contract analysis.
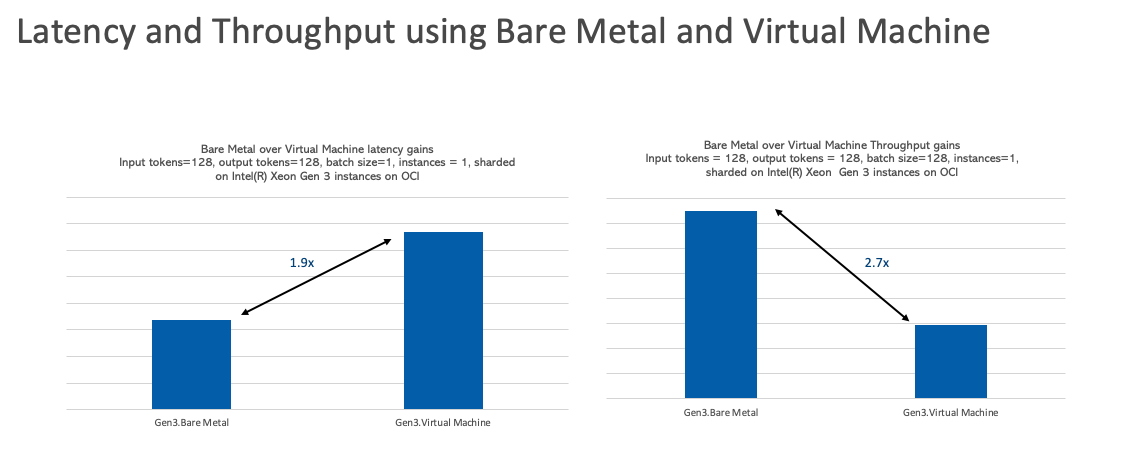
Input and output tokens
For natural language-based workloads where sensitivity to the number tokens processed and generated is important, VM nodes are well-suited for short question-and-answer use cases with a low volume of tokens, such as specific queries about a product feature. For use cases that involve generating larger answers or summarizing and understanding a greater volume of text, bare metal OCI instances are more appropriate, such as for summarizing or reviewing legal documents or for code generation.

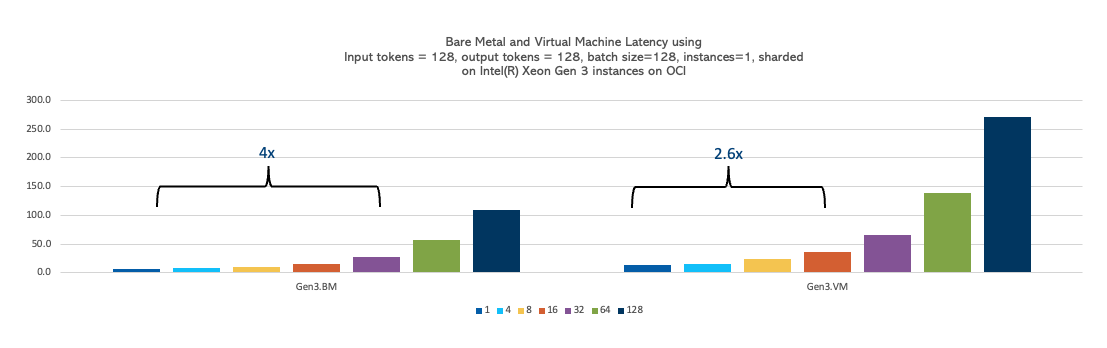
Concurrent users or batch sizes
We performed several experiments varying the batch size from 1 to 128, while keeping the input and output tokens constant at 128. We observed that the OCI Compute VM instance scales up to a batch size of 16, whereas the bare metal instance scales up to a batch size of 32. So, use cases requiring the simultaneous processing of larger data volume (larger batch size) are better suited for bare metal instances, while use cases without this requirement can effectively run on VM instances.
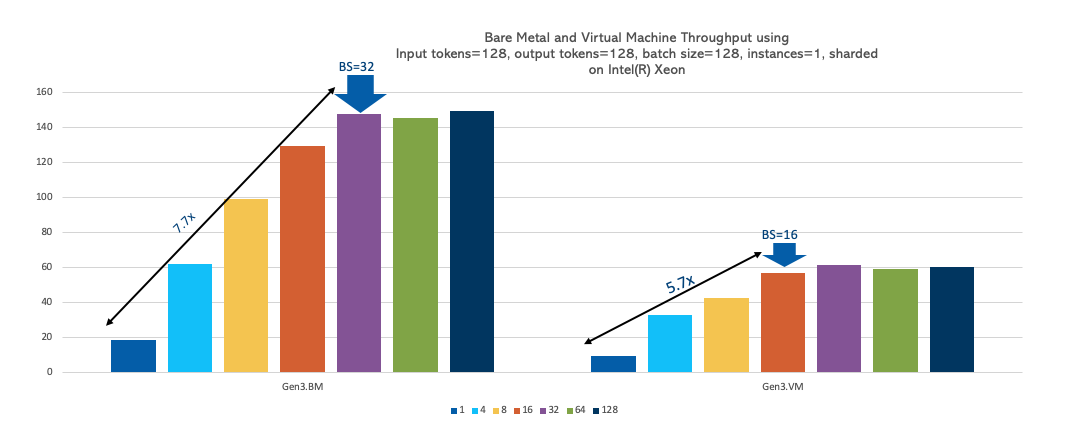
Size of the model
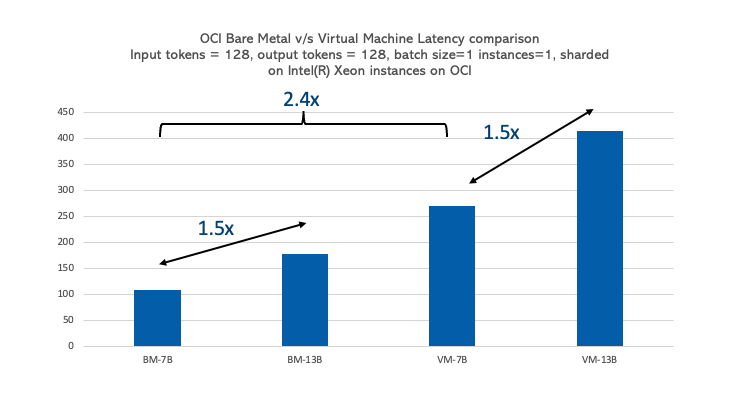
The size of the model has a proportional effect of its performance on the CPU. When the model size is increased by 1.8 times from 7- 13 billion parameters, latency increases by 1.5 times for both the OCI Compute bare metal and VM instances, with the bare metal instance being 2.4 times faster than the VM instance. Larger model sizes introduce a nearly equivalent latency increase because of the higher compute requirements. However, bare metal handles larger sized models better than expected due to reduced overhead. So, you can host smaller models like Gemma-1B, Phi-3-Mini, opt-125, Llama2-7B could be hosted on the VM instance, while hosting larger models on the bare metal instance.
Conclusion
Both the OCI VM and bare metal instances with Intel Xeon processors can run GenAI inference workloads. Generative AI natural language inference workloads with smaller token sizes and smaller batch sizes, can be effectively handled by virtual machines. In contrast, workloads with larger input and output token sizes and larger batch sizes, are better suited for bare metal instances. Certain use cases are particularly well-suited for Intel Xeon VM, such as advertising optimization and hyper-personalization in the marketing and advertising sector, and semantic automation in the technology sector. Bare metal instances can handle a broader range of use cases, including insurance quotes generation and synthetic fraud data generation in the banking and insurance sectors, medical image analysis and drug discovery in the healthcare sector, and personalized learning and content generation in the education sector.
For more information, see the following resources:
https://docs.oracle.com/en-us/iaas/Content/Compute/References/computeshapes.htm#bm-standard
https://docs.openvino.ai/2023.3/ovms_what_is_openvino_model_server.html


