※ 本記事は、Kailas Jawadekarによる”Exceptional AI Inference performance using Oracle A1 Compute with Ampere optimized frameworks“を翻訳したものです。
2022年9月30日
このゲスト・ブログは、Ampere Computingのsenior technical marketing managerであるAli Erdengizと協力して書かれたものです。
Ampereのクラウド・ネイティブ・プロセッサに基づくOracle A1コンピュート
Ampere Computingでは、クラウド・ネイティブ・プロセッサの導入により、クラウド・アプリケーションの実行に最適なまったく新しいカテゴリの製品が導入されました。Oracle Cloud Infrastructure(OCI)は、ArmベースのAmpere AltraプロセッサをA1 Computeシェイプに使用して、幅広いソフトウェア・サポートと豊富なアプリケーション・カタログが急速に拡大する、この革新的な導入しやすい製品ファミリの利点を適用しています。
Oracle Ampere A1は、クラウドのワークロード要件に専念し、不要なレガシー機能を排除することで、ワークロード使用率が高いx86アーキテクチャと比較して、60%低い電力で実行されるコア数の2倍を提供します。シングルスレッドのコア数が多いほど、アプリケーションの正確なニーズに基づいてワークロードを柔軟に構成でき、ノイジー・ネイバーの影響を軽減または排除できます。その結果、消費電力の削減と総所有コスト(TCO)の削減により、パフォーマンスが向上し、予測も可能になります。
Ampereクラウド・インスタンスでのAIワークロード
クラウドの主要なワークロード・カテゴリの1つに、機械学習(ML)アプリケーションと人工知能(AI)アプリケーションがあります。アプリケーションの性質と必要なソフトウェア開発パッケージに基づいて、MLとAIを区別します。MLは、より成熟した方法論を使用したビッグ・データ分析のほとんどを占めますが、AIは主にコンピュータ・ビジョンおよび自然言語処理(NLP)に適用されるディープ・ラーニングで構成されます。
クラウドで効果的に推論を行うことは、アプリケーションのパフォーマンス要件を満たすことを意味します。リアルタイム推論の重要な基準は、予測が行われる待機時間です。リアルタイム・アプリケーションでは、待機時間(データの到着から予測の配信までの経過時間)が重要です。同様に、スループットは、アプリケーションの推論に不可欠な別のパラメータです。推論タスクをまとめてバッチ化し、パイプラインの影響を適用することで、スループットを向上できます。
Ampere Altraの簡単に拡張できるマルチコア・アーキテクチャは、$/CPU時間を最小限に抑えながら、ワークロードにコンピュート・リソースを適応させる、かつてない柔軟性を提供します。より多くのコアをデプロイすることで、レイテンシを直線的に改善できます。一方、小規模バッチ・サイズ(1-4)のスループットは4-8コアのみで簡単に最大化できます。バッチ・サイズが大きくなるにつれてコアを追加することで、スループット・パフォーマンスを維持できます。
コンピュータ・ビジョン・アプリケーションにおける推論の例として、交差点でのトラフィックの監視、車両の検出、カウント、トラフィック・フローの分析、ライセンス・プレート(保証されている場合)の記録があります。このタスクはリアルタイムで実行する必要があり、優れたパフォーマンスが必要です。AmpereのAltraプロセッサは、TensorFlow、PyTorch、ONNX-RTなどの業界標準のAmpere最適化フレームワークのいずれかで実行することで、ハードウェア・アクセラレーションを必要とせずにこのワークロードを処理できます。
また、消費電力もAI推論タスクで考慮すべき重要な要素です。データ・センターの消費電力は依然としてエネルギー持続可能性の主要な課題です。その効果を得るために、AmpereのAltra CPUは、AI推論を含むクラウド・ワークロードに対して1ワット当たりの最高のパフォーマンスを提供します。
Ampereの最適化されたフレームワーク
クラウドにおけるAI推論ワークロードにおけるAmpereのパフォーマンス上の利点は、TensorFlow、PyTorch、ONNX-RTなどの一般的なAI開発フレームワークをAmpereのクラウド・ネイティブ・アーキテクチャにマップするソフトウェア・スタックによって実現され、最高レベルの運用効率と実行速度を実現します。
オープン標準のAI開発フレームワークとAmpere CPUのハードウェア実行レイヤーの間の最適化スタックは、次のレイヤーで構成されます。:
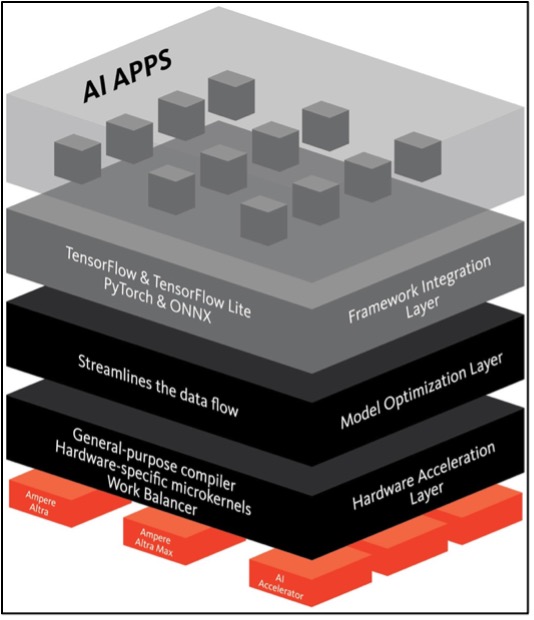
- フレームワークの統合: 一般的な開発者フレームワークとの完全な互換性を提供します。ソフトウェアは訓練を受けたネットワークと同様に動作します。変換や近似は必要ありません。
- モデル最適化: 構造的なネットワーク拡張、効率化のための処理順序の変更、正確性の低下のないデータ・フロー最適化などの手法を実装します。
- ハードウェア・アクセラレーション: Ampereプロセッサ用に調整された少数のマイクロカーネルを使用するジャストインタイム最適化コンパイラが含まれます。このアプローチにより、推論エンジンは複数のフレームワークをサポートしながら高パフォーマンスを実現できます。
Ampereの最適化フレームワークを実行することで、AmpereのAIチームは、コンピュータ・ビジョンとNLPドメインで多くの人気のあるニューラル・ネットワーク・モデルをベンチマークし、従来のx86 CPUとAmazon Web Service(AWS)のArmベースのGravitonプロセッサを常に上回っています。これらのベンチマークの結果は、Ampere AIソリューションのページで確認できます。
Ampere AIチームはモデル・ライブラリも提供しています。Ampereプラットフォームで実行可能なこれらのモデルをダウンロードし、公開されたベンチマーク結果を再現し、特定の制約に基づいて独自のベンチマークを実行できます。アプリケーションに簡単に組み込むこともできます。Ampereのライブラリは、そのモデル・オプションを拡張します。
Ampere AIツールへのアクセス
OCI上のAmpere AIに関心のあるお客様は、Oracle Cloud Free Tierを今すぐ開始できます。独自のOracle A1 Computeインスタンスを作成し、Ampereの最適化されたフレームワークをTensorFlow用のAmpere Optimized FrameworkおよびPyTorchページのAmpere Optimized Frameworkからダウンロードして、Oracle A1インスタンスにインストールできます。
Ampereモデル・ライブラリへのアクセスは、Ampere CPUでのAI推論の実行に関するその他の情報とともに、Ampere AIソリューション・ページで有効になっています。
始めるためのリソース
Oracle Cloudでは、ArmベースのAmpere AltraプロセッサをA1 Computeシェイプに使用しています。AmpereのAltraプロセッサは、AI推論タスクのための優れた価値提案を提供します。Ampere AIの最適化されたソフトウェア・ツールは、スケーラビリティ、予測可能性、エネルギー効率に関するクラウド・ネイティブ・アーキテクチャの固有のメリットと組み合わせることで、競合他社よりも高いパフォーマンスを実現し、TCOを大幅に削減しながらクラス最高のパフォーマンスを実現します。
Ampere Optimized AIでOCI Ampere A1 Computeをお試しください。開始するには、次のリソースを参照してください:
