This guest blog was written in collaboration with Ali Erdengiz, senior technical marketing manager at Ampere Computing.
Oracle A1 compute-based on Ampere’s cloud native processors
With the introduction of its cloud native processors, Ampere Computing has introduced a whole new category of products that are ideal for running cloud applications. Oracle Cloud Infrastructure (OCI) has been using Arm-based Ampere Altra processors for its A1 Compute shapes to apply the advantages of this innovative, easy-to-deploy product family with broad software support and a rich application catalog growing rapidly.
By exclusively focusing on cloud workload requirements and eliminating unnecessary legacy features, Oracle Ampere A1 offers twice the number of cores that run at 60% lower power compared to the x86 architecture under high-workload utilization. The higher number of single-threaded cores enable you to flexibly configure your workloads based on the exact needs of your applications and reduce or eliminate noisy neighbor effects. The result is higher and more predictable performance at a lower power consumption and a lower total cost of ownership (TCO).
AI workloads on Ampere cloud instances
One of the major workload categories in the cloud includes machine learning (ML) and artificial intelligence (AI) applications. We differentiate between ML and AI based on the nature of the applications and the software development packages that they require. ML consists mostly of Big Data analysis using methodologies that are more mature, while AI consists primarily of deep learning as applied to computer vision and natural language processing (NLP).
Running inference effectively in the cloud means meeting the performance requirements of the application. An essential criterion for real-time inference is the latency with which a prediction is made. The latency—the elapsed time between the data’s arrival and the prediction’s delivery—is critical for real-time applications. Similarly, throughput is another parameter that is essential for inferencing applications. You can improve throughput by batching inferencing tasks together and applying the effect of pipelining.
The easily scalable multicore architecture of Ampere Altra delivers unprecedented flexibility in adapting compute resources to the workload for best results while minimizing $/CPU hours. You can improve latency linearly by deploying more cores. On the other hand, throughput for small batch sizes (1–4) is easily maximized with only 4–8 cores. You can sustain throughput performance by adding more cores as the batch size grows.
An example of inference in a computer vision application is monitoring the traffic at an intersection, detecting vehicles, counting them, analyzing traffic flows, and recording their license plates if warranted. This task needs to be performed in real time and requires excellent performance. Ampere’s Altra processors can handle this workload without any need for hardware acceleration by running on one of its industry-standard Ampere optimized frameworks, such as TensorFlow, PyTorch, or ONNX-RT.
Power consumption is also an important factor to consider for AI inference tasks. Data center power consumption remains a major energy sustainability challenge. To that effect, Ampere’s Altra CPUs deliver the highest performance per watt for the cloud workloads, including AI inference.
Ampere optimized frameworks
Ampere’s performance advantage in AI inference workloads in the cloud is made possible by its software stack that maps the popular AI development frameworks, such as TensorFlow, PyTorch and ONNX-RT, to Ampere’s cloud native architecture to achieve the highest level of operational efficiencies and run speeds.
The optimization stack between the open standards AI development frameworks and Ampere CPUs’ hardware execution layer consists of the following layers:
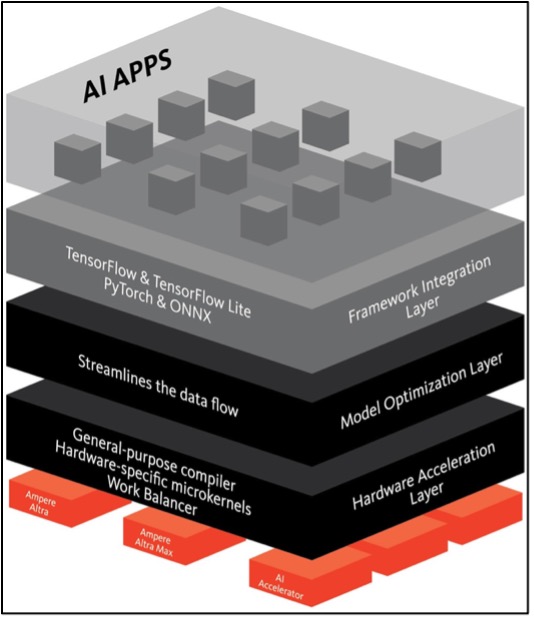
Figure 1: Ampere AI optimized framework software stack
-
Framework integration: Provides full compatibility with popular developer frameworks. The software works with the trained networks as is. No conversions or approximations are needed.
-
Model optimization: Implements techniques, such as structural network enhancements, changes to the processing order for efficiency, and data flow optimizations without accuracy degradation.
-
Hardware acceleration: Includes a just-in-time optimization compiler that uses a small number of micro-kernels tailored for Ampere processors. This approach allows the inference engine to deliver high-performance while supporting multiple frameworks.
Running Ampere optimized frameworks, Ampere’s AI team has benchmarked many popular neural network models in computer vision and NLP domains and has consistently come ahead of legacy x86 CPUs and Amazon Web Service (AWS)’s Arm-based Graviton processors. You can find these benchmark results on the Ampere AI solutions page.
The Ampere AI team also provides a model library. Our customers can download these models ready to run on Ampere platforms, reproduce the published benchmark results and run their own benchmarks based on their specific constraints. They can also easily incorporate them into their applications. Ampere’s library expands its model option going forward.
Accessing Ampere AI tools
Customers interested in Ampere AI on OCI can get started today with Oracle Cloud Free Tier. You can create your own Oracle A1 Compute instance, download Ampere’s optimized frameworks from Ampere Optimized Framework for TensorFlow and Ampere Optimized Framework for PyTorch pages and install them onto their Oracle A1 instances.
Access to the Ampere Model Library is also enabled on the Ampere AI solutions page with other information on running AI inference with Ampere CPUs.
Resources to get started
Oracle Cloud has been using Arm-based Ampere Altra processors for its A1 Compute shapes. Ampere’s Altra Processors deliver an exceptional value proposition for AI inferencing tasks. Combined with cloud native architecture’s intrinsic benefits in scalability, predictability, and energy efficiency, while delivering a higher performance than its competitors, Ampere AI’s optimized software tools deliver best-in-class performance with a significantly lower TCO.
We invite you to try OCI Ampere A1 compute with the Ampere Optimized AI. See the following resources to get you started:
