※本ページはLoad data into Oracle lakehouses with new release of Oracle Cloud Infrastructure Data Integrationの翻訳です
Oracle Cloud Infrastructure (OCI) Data Integrationの新しいリリースを発表しました。このリリースでは、HDFS、Hive、Influx DB、Amazon Auroraを使用した接続オプションの拡張、m:nデータエンティティのロードをサポートするバルクデータローダーの導入、データエンティティ名でのパラメータ指定が可能になりました。
Cloud native, serverless data integration
おさらいになりますが、OCI Data Integrationは、OCI上のクラウドネイティブでフルマネージドなサーバーレス抽出、変換、ロード(ETL)サービスです。アナリティクスやデータサイエンスのためのレイクハウス、OCI上のAIやML、オブジェクトストレージ、自律型データウェアハウスを構築する組織は、複数のデータサイロからのデータ統合を簡素化、自動化、高速化することでインサイトを迅速に提供することができます。
Data Integrationは、インタラクティブなデータ準備とプロファイリングを備えた、グラフィカルでコード不要のデザインインターフェイスを提供します。また、データエンジニアがスキーマの進化を処理するためのパターンとルールを使用してデータパイプラインを設計するのに役立ちます。Spark ETLとELTの両方がデータベースへのプッシュダウン実行をサポートします。この新サービスをご存じない方は、こちらのブログで詳細をご確認ください。:What is Oracle Cloud Infrastructure Data Integration?
Data Integrationは、すべてのOCIコマーシャルリージョンで利用可能です。
Bulk data loader
既存のデータローダータスクを拡張する形で、バルクデータローダを導入しました。バルク・データ・ローダー・タスクは、2つのシステム間で最小限の変換でn:nのデータロードが必要なユースケースを可能にします。このタスクは、データ準備、データ移行、またはOCI Object Storageのようなデータレイクへの多様なデータのロードに必要とされます。
バルクデータローダタスクを使用すると、基本的な手順の複雑さを気にすることなく、数回のクリックですべてのプロセスを完了することができます。データローダータスクを作成し、ソースとターゲットを指定し、変換を指定し、属性をマッピングし、公開し、実行する必要があるだけです。
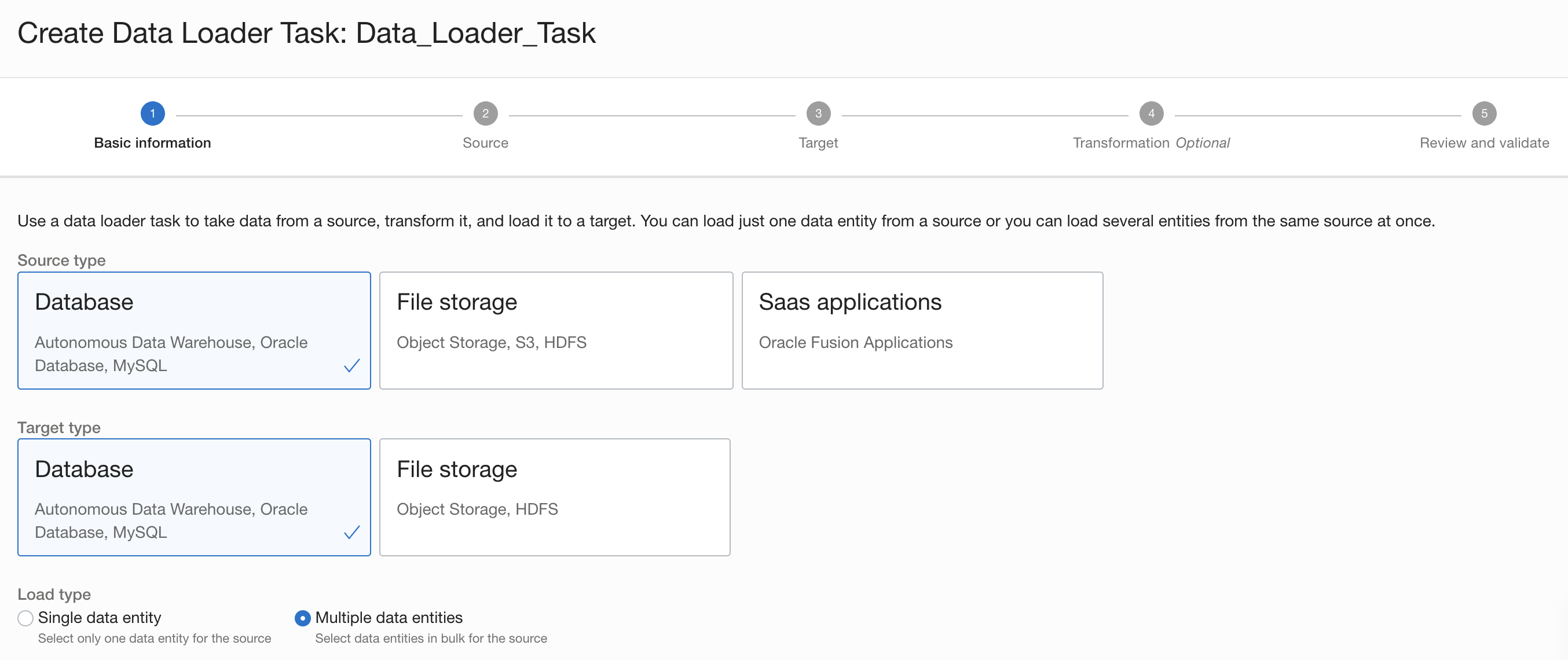
Figure 1: Bulk data loader
More features
OCI Data Integrationで、OCI Object StorageとAWS S3に存在するファイルのメタデータをフェッチできるようになりました。OCI Data IntegrationでRESTタスクを使用中に、長時間稼働するAPI操作を呼び出すRESTタスクに対して、ポーリングと削除の設定を指定することができます。また、ソースまたはターゲット演算子のデータエンティティを選択する際に、データエンティティ名でパラメータを使用することができます。
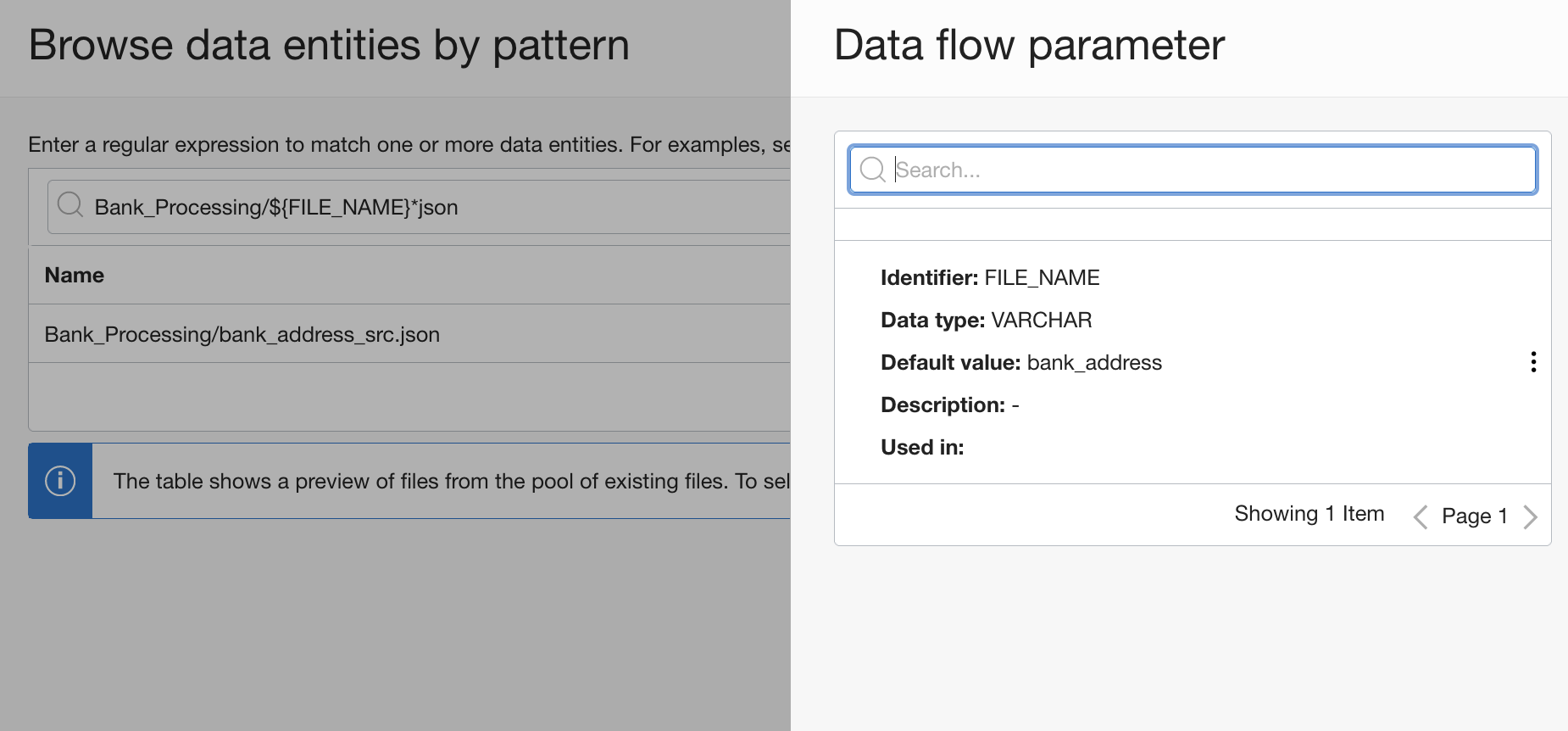
Figure 2: Parameters for source data entity
Want to know more?
組織は、Oracle Lake、自律型データベース、およびクラウドでの人工知能と機械学習による高度な分析によって、次世代分析の旅に乗り出そうとしています。この旅を成功させるには、Oracle Cloud Infrastructureにデータを迅速かつ容易に取り込み、準備し、変換し、ロードする必要があります。Data Integrationの旅は始まったばかりです。今すぐお試しください。
詳細については、Oracle Cloud Infrastructure Data Integrationのドキュメント、関連するチュートリアル、およびOracle Cloud Infrastructure Data Integrationのブログを参照してください。
