※ 本記事は、Dhvani Shethによる”Running Ansys Fluent and LS-DYNA applications up to 30% faster using Oracle Cloud 3rd Generation Intel Xeon Scalable Processor“を翻訳したものです。
2022年6月16日
Oracleは、昨年、Intelの第3世代Xeon「Ice Lake」スケーラブル・プロセッサにより、新世代の高パフォーマンス・コンピューティング(HPC)インスタンスを立ち上げました。36コア、512GBのメモリー、3.2-TB NVMeおよび100GbpsのRDMAでは、これらのベア・メタル・マシンは、Skylakeに基づくOracleの以前のHPC製品よりも大幅に高速です。RDMA over converged ethernet (RoCE) v2ネットワークを介して相互接続され、待機時間は1.6μs以下になります。Oracle HPCおよび計算流体力学(CFD)アプリケーションの詳細は、CFDページを参照してください。
このブログでは、新しいHPCインスタンスのマルチノード・パフォーマンス、BM.Optimized3.36と前の世代、Ansys FluentやLS- DYNAなどのCFDアプリケーションのBM.HPC2.36を比較します。コンピュート・コア時間当たりの価格が2世代間で同じであるため、パフォーマンス向上は、コスト削減に直接移行し、HPCジョブ当たりの完了時間を短縮します。新しいBM.Optimized3.36インスタンスは、クラウドのIntelプロセッサ上でHPCワークロードを実行するための最適なオプションになります。
ベンチマークの設定
Oracle Cloud Infrastructure(OCI)Resource Manager内のスタックを使用して、ベア・メタルHPCインスタンス(BM.Optimized3.36)のクラスタを作成します。このスタックは、インスタンスのコレクションを機能的なHPCクラスタに変換するすべての部分を含むTerraformテンプレートです。スタックは、ネットワーク・ファイル共有(NFS)共有ボリューム、追加のブロック・ボリューム、OCI File Storageサービス、SLURMスケジューラなどの別のファイル・システムを追加できます。
テストでは、すべてのノード間で共有NFSボリュームとして3.2-TBローカルNVMeを使用しました。このブログのテストでは、LustreやSpectrumScaleなどのパラレル・ファイル・システムは必要ありません。
Ansys Fluent
ベンチマーク・モデルにIntel MPI 2019u12を使用して、Ansys Fluent Fluids 2022R1を実行しました。
f1_racecar_140mモデルは、Formula-1レース・カー上の外部フローで、約1億4000万個のHexコア・セルがあります。このモデルは、実現可能なk-プシロン乱流モデル、圧力ベースの結合ソルバ、最小二乗セルベース、疑似過渡ソルバを使用します。
次のグラフは、FluentテストのBM.Optimized3.36とBM.HPC2.36の比較を示しています。この場合、より高い評価が向上します。f1_racecar_140mモデルは、72- 576コア(2-16ノード)のほぼパーフェクト・スケーリングを使用したBM.HPC2.36と比較して、BM.Optimized3.36で約30%高速です。そのため、HPCユーザーは、30%安価で迅速な結果を得ることができます。
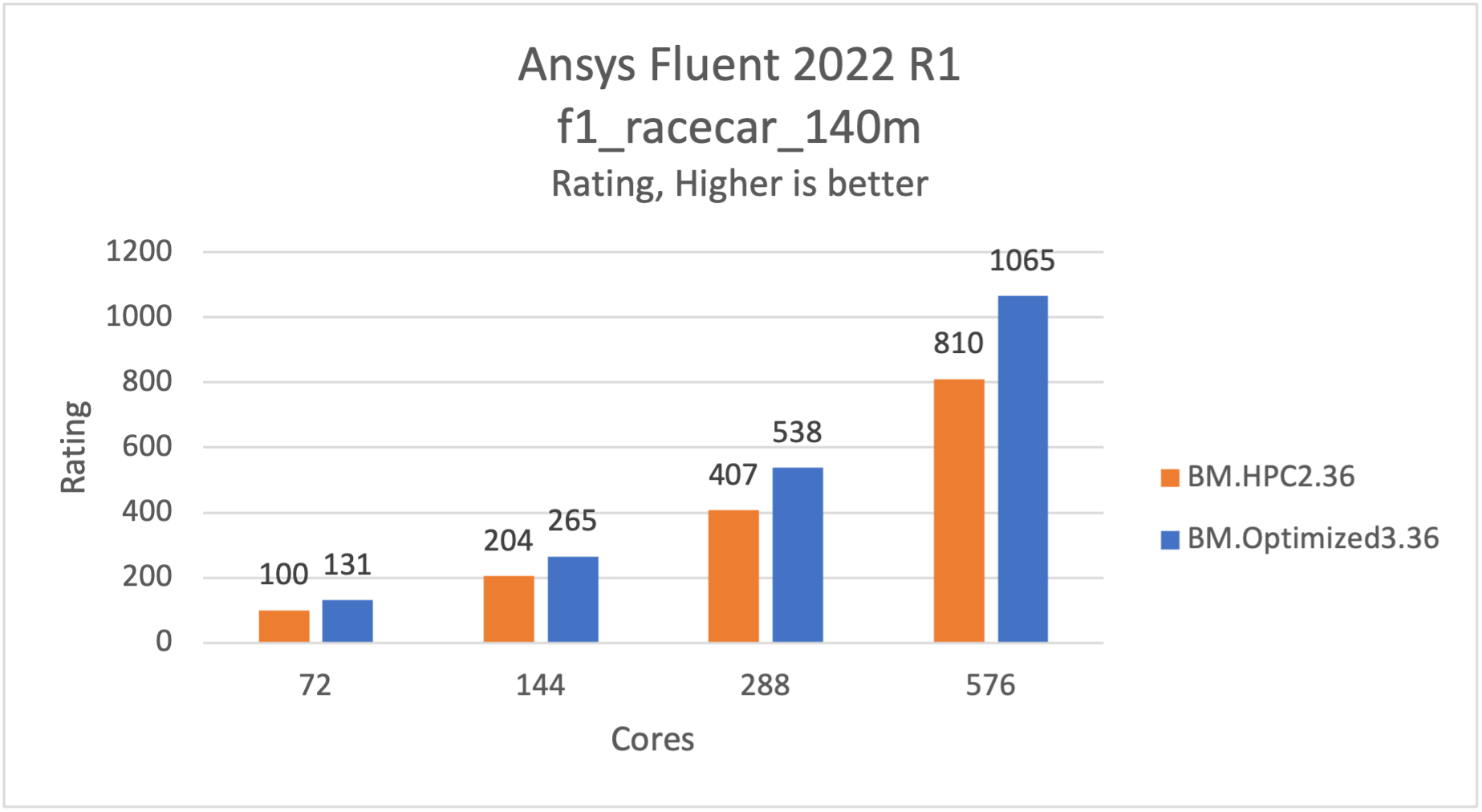
図 1: f1_racecar_140mはBM.Optimized3.36で最大30%高速
combustor_12mモデルは、コンバスターを通るフローです。症例には約1200万個の多面体があり、実現可能なk-epsilonターブレンス、SpeciesTransportモデルと圧力ベースの結合ソルバー、最小二乗セルベース、疑似過渡ソルを使用しています。
BM.Optimized3.36では、BM.HPC2.36より約26%高速で実行されます。
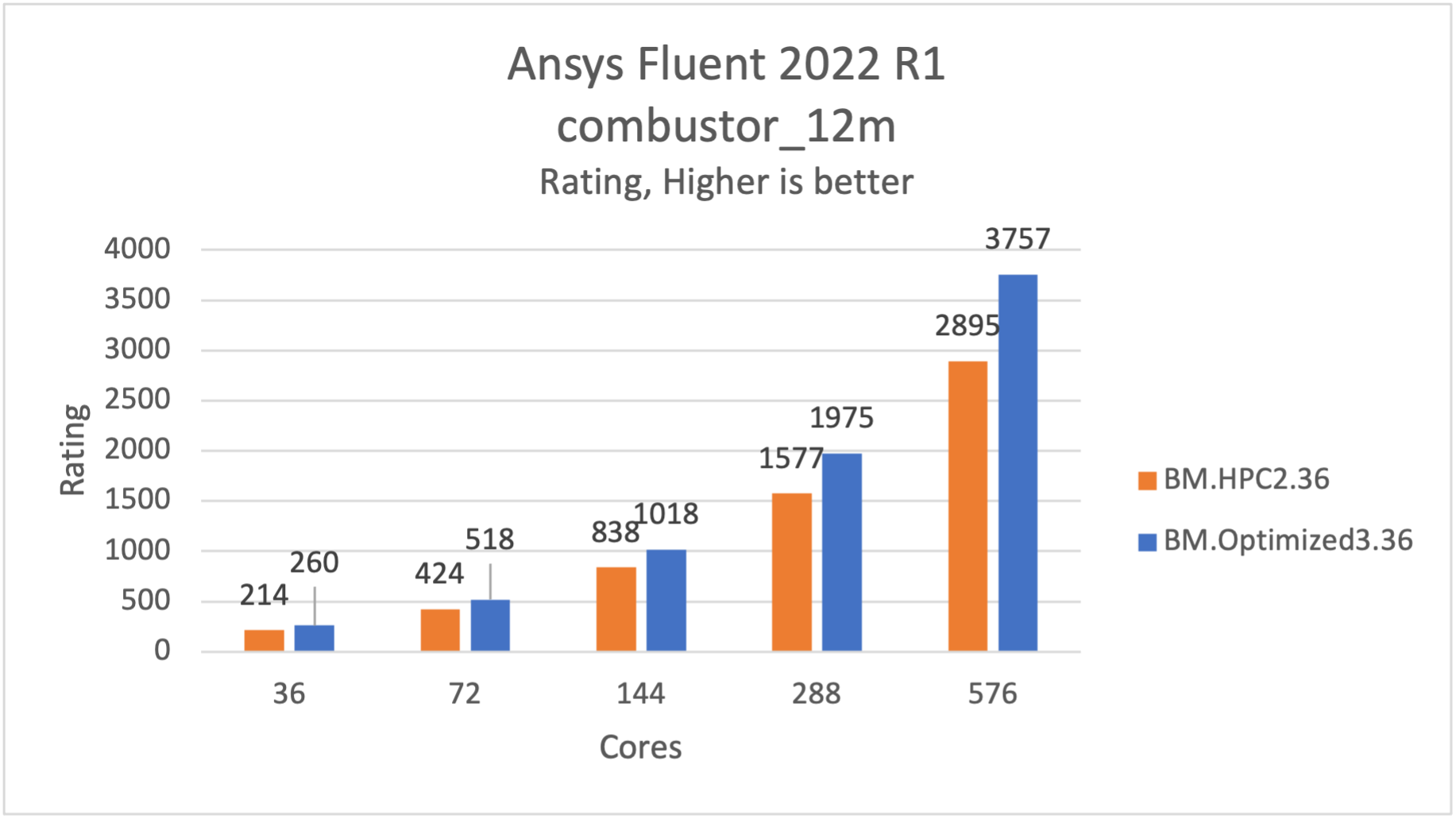
図 2: combustor_12mがBM.Optimized3.36で26%高速
combustor_71mモデルは、コンバスターを通るフローです。このケースには約7100万個のHexコアセルがあり、大型Eddy Simulation(LES)、Species Non-Premixed Combustion、PDF、DPMモデル、圧力ベースの結合ソルバー、最低二乗セルベース、および非定常なソルバーを使用します。
BM.Optimized3.36では、BM.HPC2.36と比較して約30%高速で実行されます。
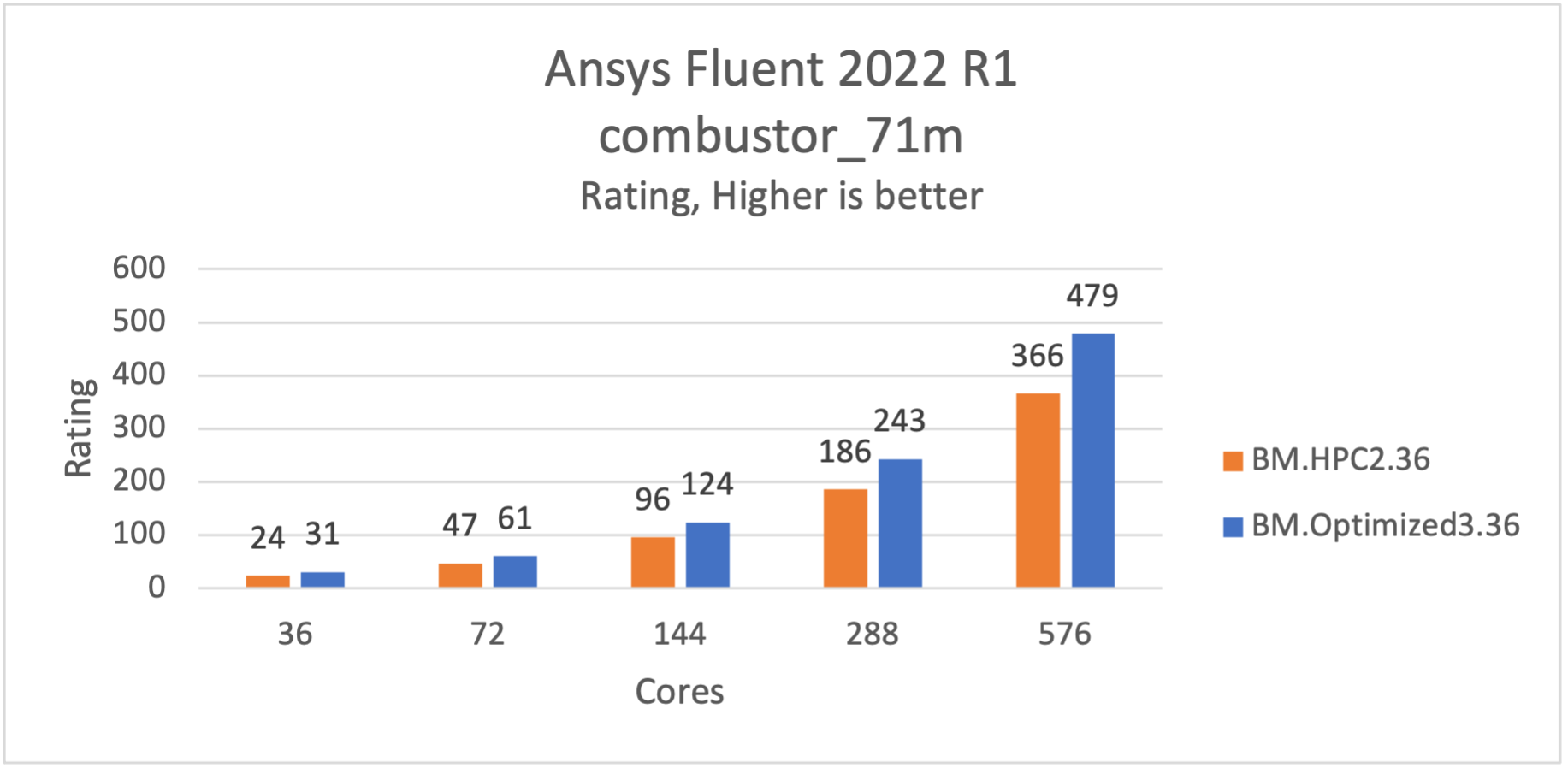
図 3: combustor_71mはBM.Optimized3.36で30%高速
lm6000_16mモデルは、コンボストを介したフローです。このケースは約1600万個の六面体を持ち、大渦シミュレーション(LES)、一部固定式燃焼、PDFモデル、圧力ベースの分離ソルバー、緑ガウスセルベース、非定常なソルバーを使用します。
BM.HPC2.36と比較すると、BM.Optimized3.36で約31%高速で実行されます。
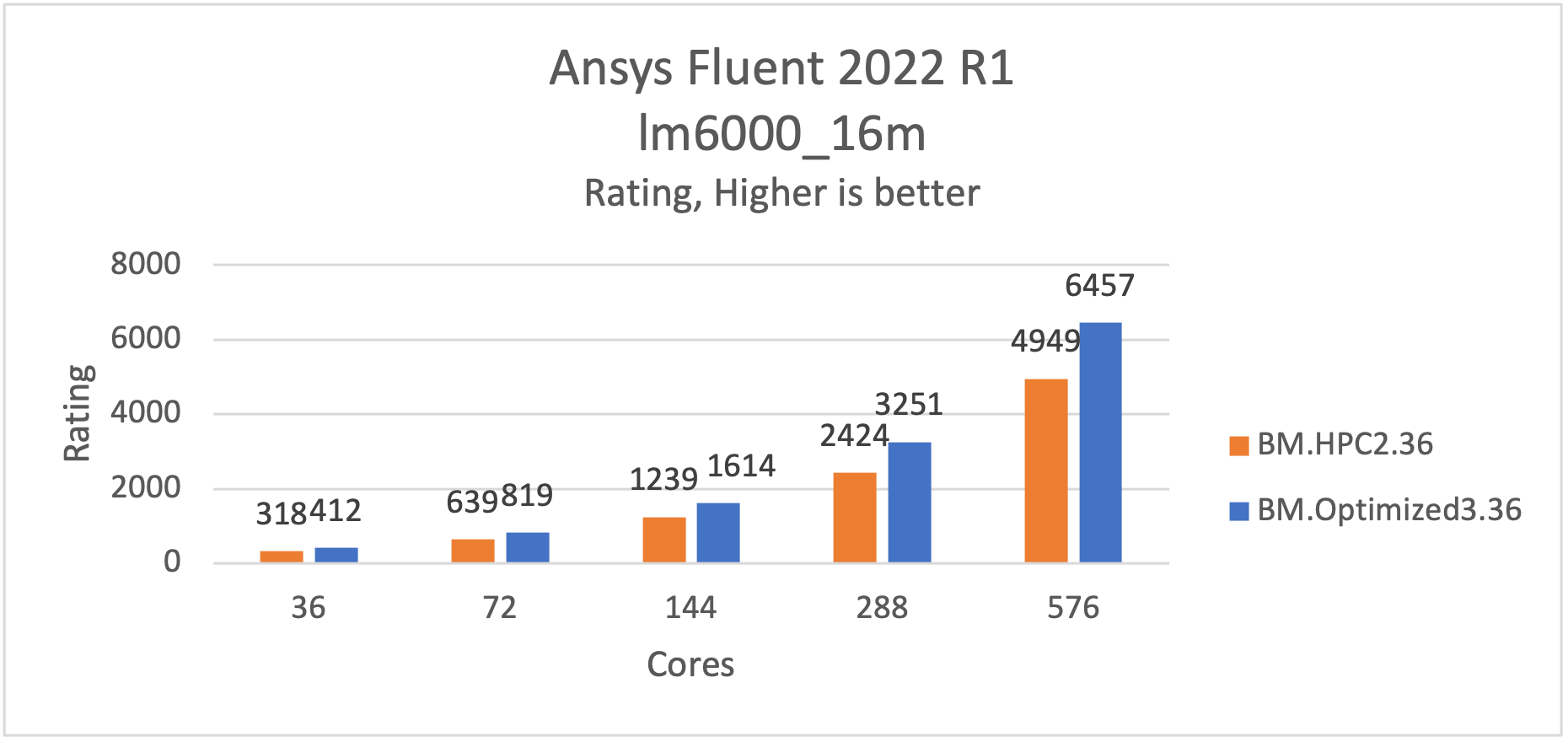
図 4: lm6000_16mがBM.Optimized3.36で31%高速
通常、Ansys Fluentの実行時にOCIのパフォーマンスが30%向上します。正確な数は、実行するモデルによって異なります。
LS-DYNA
LS- DYNAの場合、car2car-20mモデルを実行しました。car2car-20mシミュレーションでは、2台の車両間でヘッドオン衝突が発生します。ベンチマークでは、このテストを変更して終了時間を0.02秒に短縮しました。Oracleの以前の世代のHPCベア・メタル・サーバーと比較して、様々なコア数でパフォーマンスは約28%向上しました。そのため、Skylakeに基づく前世代のHPCシェイプに比べて、28%安価で迅速に結果を得ることができます。ただし、正確な数は、実行するモデルによって異なります。
次のグラフは、Intel MPI 2019u12 car2car-20m-20msテストを使用したLS-DYNA R12.0.0 CentOS- 65_AVX2のBM.Optimized3.36とBM.HPC2.36の比較を示しています。この場合、時間が短くなります。
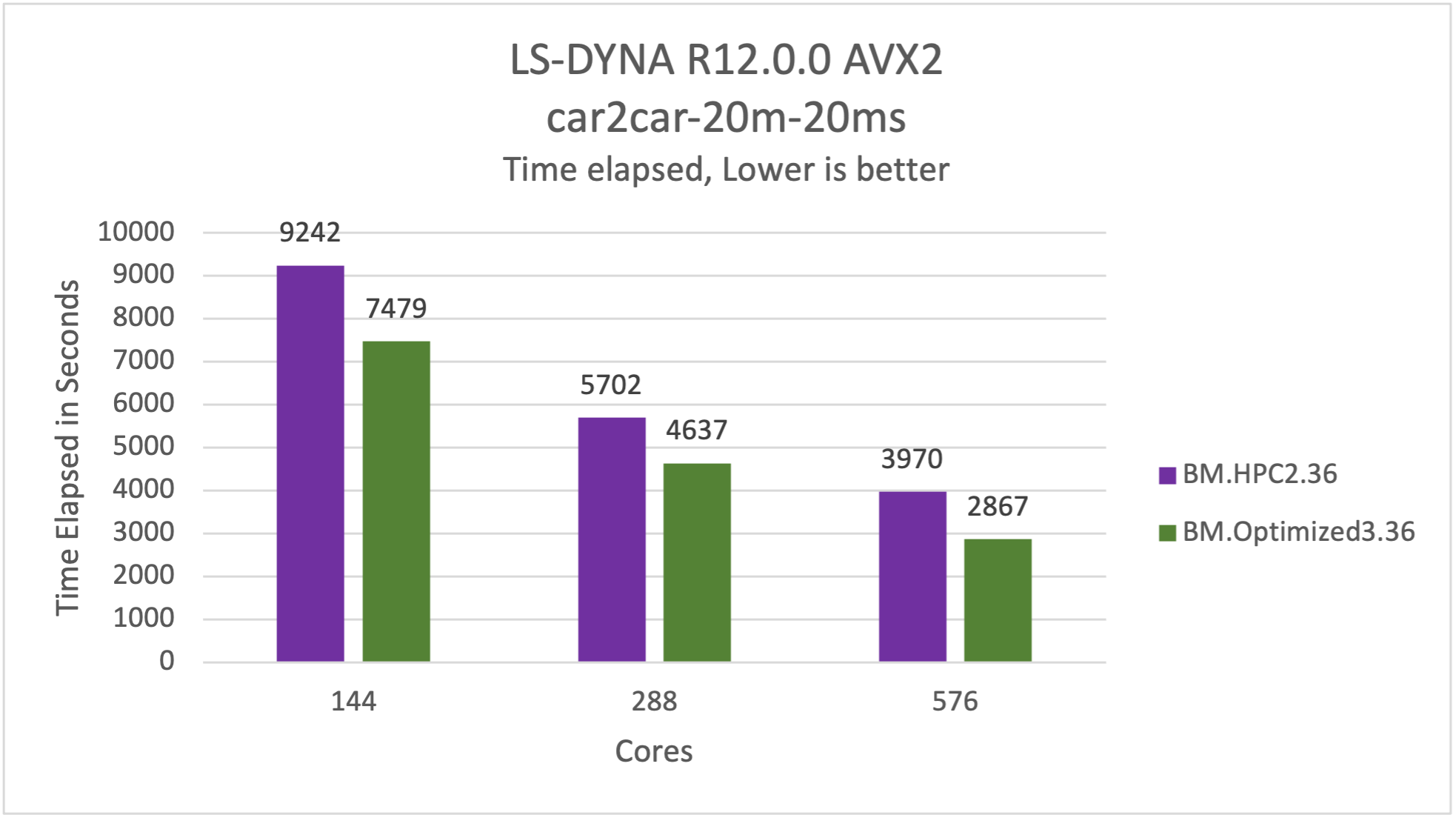
図 5: car2car-20-20msはBM.Optimized3.36で28%高速
まとめ
Ansys FluentモデルのBM.HPC2.36と比較して、BM.Optimized3.36のパフォーマンスが約30%向上しました。パフォーマンスは、価格性能が約30%向上しています。LS-DYNAの改善は28%でした。このパフォーマンスの向上と1時間当たり2.70米ドルという価格で、BM.Optimized3.36に切り替えると、Oracle Cloud Infrastructureで現在使用可能な価格性能が最高になります。開始方法についてさらに学習するには、今すぐ無料の30日間トライアルを開始する方法を確認してください。
詳細は、次のリソースを参照してください。
