Oracle launched a new generation of high-performance computing (HPC) instances with Intel’s 3rd Generation Xeon “Ice Lake” scalable processors last year. With 36 cores, 512-GB memory, 3.2-TB NVMe, and 100-Gbps RDMA, these bare metal machines are substantially faster than Oracle’s previous HPC offering based on Skylake. They’re interconnected through RDMA over converged ethernet (RoCE) v2 network, with latency as low as to 1.6 µs. For detailed information on Oracle HPC and computational fluid dynamics (CFD) applications, visit our CFD page.
In this blog, we compare multi-node performance of the new HPC instances, BM.Optimized3.36 to the previous generation, and BM.HPC2.36 for CFD applications, such as Ansys Fluent and LS-DYNA. As the price per core-hour of compute is the same between the two generations, any performance improvement translates directly into cost savings and faster completion time per HPC job, making the new BM.Optimized3.36 instances the best option to run your HPC workloads on Intel processors in the cloud.
Setup for benchmarks
We create a cluster of bare metal HPC instances (BM.Optimized3.36) using a stack in the Oracle Cloud Infrastructure (OCI) Resource Manager. This stack is a Terraform template containing all the parts that turn a collection of instances into a functional HPC cluster. The stack can add network file share (NFS) share volumes, extra block volumes, another file system, such as OCI File Storage service, and SLURM scheduler.
For our tests, we used 3.2-TB local NVMe as a shared NFS volume among all the nodes. The tests in this blog don’t require a parallel file system, such as Lustre or SpectrumScale.
Ansys Fluent
We ran Ansys Fluent Fluids 2022R1 using Intel MPI 2019u12 for the benchmark models.
The f1_racecar_140m model is an external flow over a Formula-1 Race car and has around 140 million Hex-core cells. This model uses the realizable k-epsilon turbulence model, the pressure-based coupled solver, least-squares cell base, and pseudo-transient solver.
The following graph shows the comparison of BM.Optimized3.36 and BM.HPC2.36 in the Fluent test, where a higher rating is better. The f1_racecar_140m model is approximately 30% faster on BM.Optimized3.36 compared to BM.HPC2.36 with near-perfect scaling on 72–576 cores (2–16 nodes). So, as an HPC user you get 30% cheaper and faster results.
Figure 1: f1_racecar_140m is 30% faster on BM.Optimized3.36
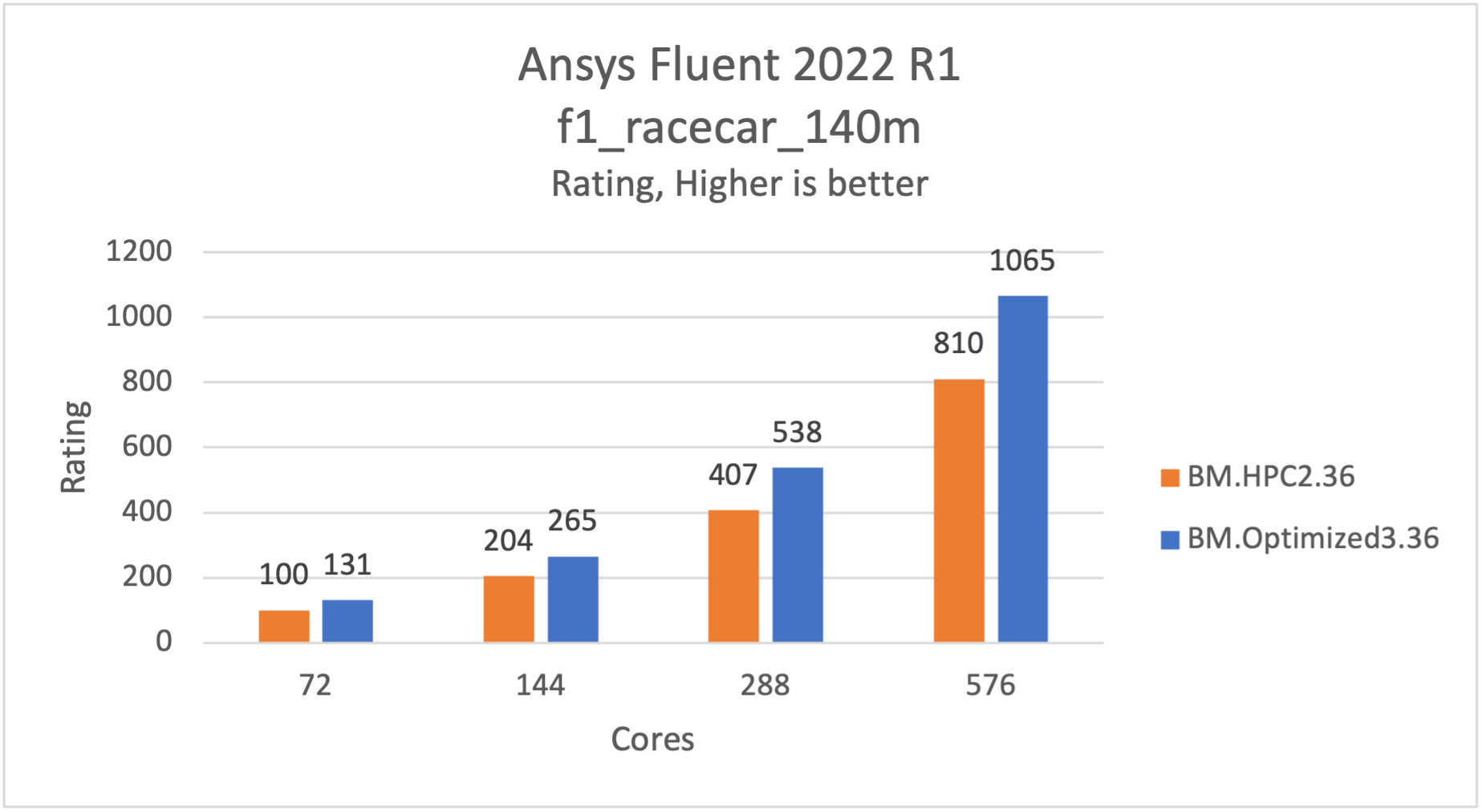
Figure 1: f1_racecar_140m is ~30% faster on BM.Optimized3.36
The combustor_12m model is a flow through a combustor. The case has around 12 million polyhedral cells and uses the realizable k-epsilon turbulence, Species Transport model, and the pressure-based coupled solver, least-squares cell base, and pseudo transient solver.
It runs approximately 26% faster on BM.Optimized3.36 than BM.HPC2.36.
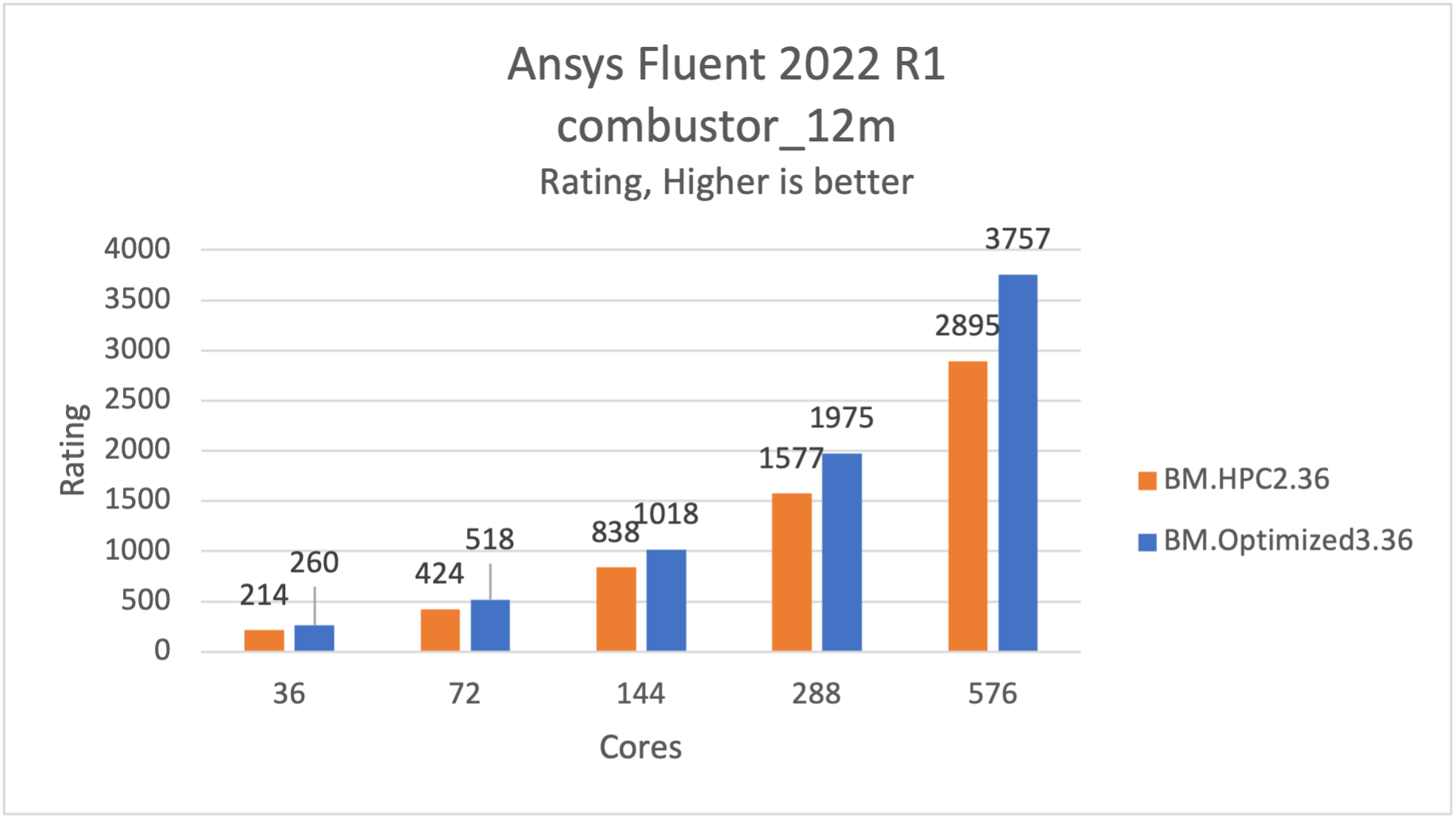
Figure 2: combustor_12m is 26% faster on BM.Optimized3.36
The combustor_71m model is a flow through a combustor. The case has around 71 million Hex-core cells and uses the Large Eddy Simulation (LES), Species Non-Premixed Combustion, PDF, DPM model, and the pressure-based coupled solver, least-squares cell base, and unsteady solver.
It runs approximately 30% faster on BM.Optimized3.36 compared to BM.HPC2.36.
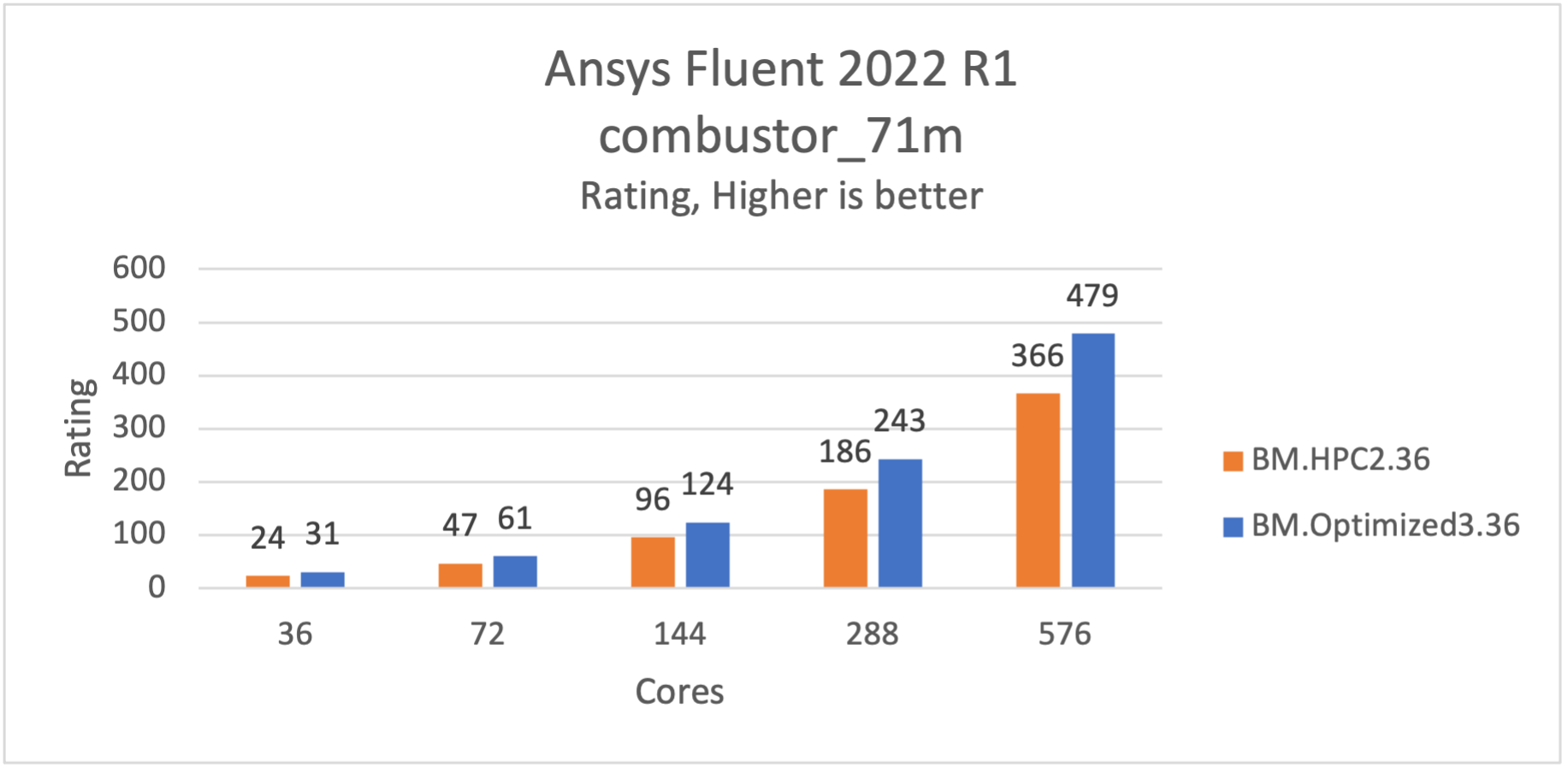
Figure 3: combustor_71m is 30% faster on BM.Optimized3.36
The lm6000_16m model is a flow through combustor. The case has around 16 million hexahedral cells and uses the Large Eddy Simulation (LES), partially premixed combustion, PDF model, the pressure-based segregated solver, Green Gauss cell base, and unsteady solver.
It runs approximately 31% faster on BM.Optimized3.36 when compared to BM.HPC2.36.
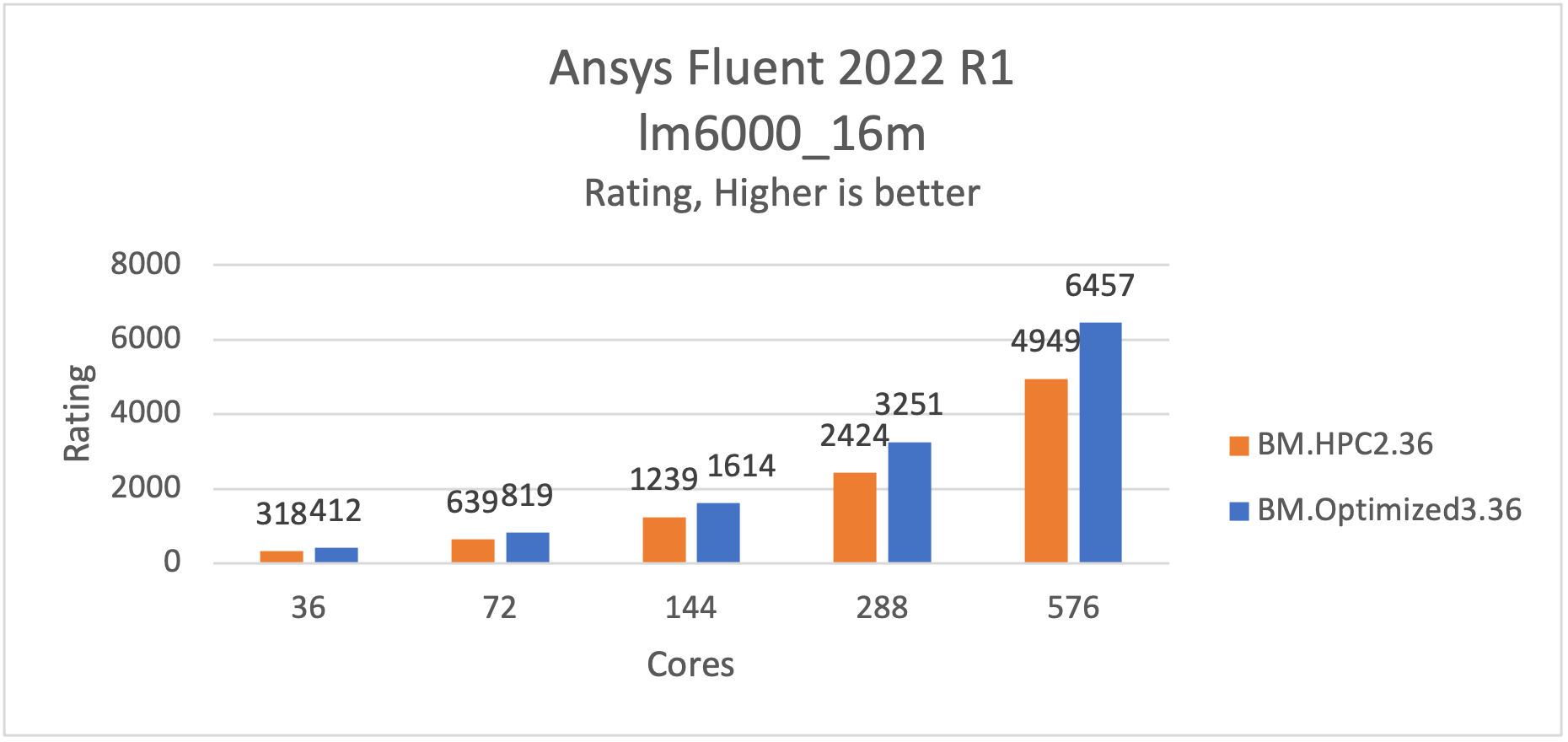
Figure 4: lm6000_16m is 31% faster on BM.Optimized3.36
In general, you get a 30% average performance increase on OCI when running Ansys Fluent. The exact number depends on the model that you run.
LS-DYNA
For LS-DYNA, we ran car2car-20m model. In the car2car-20m simulation, a head-on collision occurs between two vehicles. For our benchmark, we modified this test to shorten the end time to 0.02 seconds. We see performance gains of approximately 28% compared to Oracle’s previous generation HPC bare metal servers across wide range of core counts. So, you get 28% cheaper and faster results compared to the previous generation HPC shape based on Skylake. However, the exact number depends on the model you run.
The following graph shows the comparison of BM.Optimized3.36 and BM.HPC2.36 in the LS-DYNA R12.0.0 CentOS-65_AVX2 using Intel MPI 2019u12 car2car-20m-20ms test, where a lower time is better.
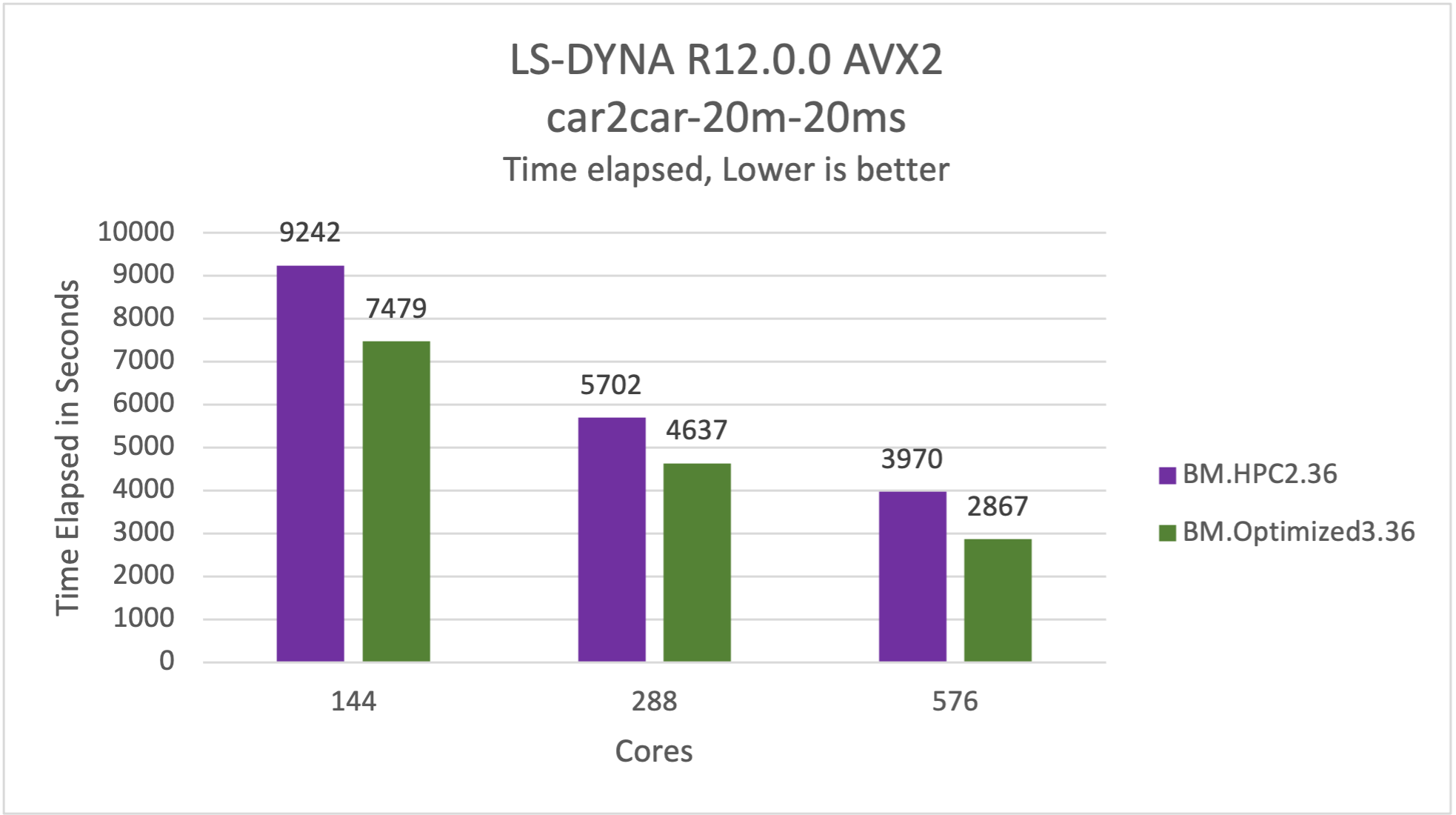
Figure 5: car2car-20-20ms is 28% faster on BM.Optimized3.36
Conclusion
We saw an increase of approximately 30% in performance on BM.Optimized3.36, compared to BM.HPC2.36, for the Ansys Fluent models. The performance translates to about 30% better price-performance. For LS-DYNA, we saw an improvement of 28%. With this performance increase and price of USD$2.70 per hour, it leaves no doubt that switching to BM.Optimized3.36 gives you the best price-performance available on Oracle Cloud Infrastructure today. To learn more about how to get started, check out how to start your free 30-day trial today.
For more details, see the following resources:
