※ 本記事は、Kailas Jawadekarによる”Achieve up to 50% better price-performance for big data workloads on OCI Ampere A1 Compute“を翻訳したものです。
2023年4月21日
このブログは、Ampereのシニア・プリンシパル・アプリケーション・エンジニアであるRama Nishtala氏と共同で書かれています。
Apache Sparkは、ビッグ・データ・ワークロードに使用されるオープンソースの分散処理システムです。インメモリー・キャッシュと最適化された問合せ処理を利用して、あらゆるサイズのデータに対する高速な分析問合せを実現します。Java、ScalaおよびPythonでAPIを提供します。Sparkは、リアルタイム分析、バッチ処理、対話型問合せおよび機械学習で複数の操作をサポートしています。Sparkは、自己回復性分散データセット(RDD)を使用してインメモリー処理を実行し、複数のパラレル操作にわたってデータを再利用することで、Hadoopの制限に対処します。Sparkは、HDFS、Couchbase、Cassandraなどの多くのストレージ・システムで機能します。Sparkは、スタンドアロン・クラスタ・モード、またはYarn、Kubernetes、Dockerなどのクラスタ管理システムで実行できます。
Sparkアーキテクチャは、Sparkドライバ、エグゼキュータおよびクラスタ・マネージャで構成されます。ドライバはSpark実行エンジンのコントローラであり、クラスタの状態を維持します。これはクラスタ・マネージャと対話して、vCPUやメモリーなどの物理リソースを取得します。ドライバもエグゼキュータを起動します。実際のタスクは、ドライバによって割り当てられたSparkエグゼキュータによって処理されます。エグゼキュータがタスクを実行し、結果および状態をドライバにレポートします。クラスタ・マネージャは、Sparkアプリケーションを実行するノードのクラスタを維持します。
OCI Ampere A1 Flex VM上のSpark
ArmベースのAmpere Altraプロセッサを搭載したOracle Cloud Infrastructure (OCI)のA1コンピュートは、x86ピアと比較して、ビッグ・データ・アプリケーションの優れた価格パフォーマンスを提供します。Ampereプロセッサを使用するA1シェイプは、アーキテクチャの予測可能でスケーラブルな性質のために、Sparkアプリケーションに推奨されます。
OCIは、OCI Ampere A1シェイプに対して、業界をリードする80コア/CPUのAmpere Altraプロセッサを使用します。すべてのコアは、最大3.0 GHzの頻度で一貫して実行できます。Ampere Altraの低電力設計とOCIの高性能インフラストラクチャを活用して、Ampere A1シェイプはクラウドで最高の価格性能を提供します。
このブログ投稿では、チャートでA1として表されるOCI Ampere VM.Standard.A1.Flex仮想マシン(VM)のパフォーマンスが、チャート(Intel IceLake)でX9として表されるOCIのVM.Standard3.Flex、チャート(AMD Rome)でE3として表されるVM.Standard.E3.Flexおよびチャート(AMD Milan) flex VMでE4として表されるVM.Standard.E4.Flexと比較されます。次のベンチマークおよびテストがyarnを使用してSparkで実行されました:
-
Spark TeraSort
-
Join operations
-
Word count
-
TPC-DS
OCIアーキテクチャ上のSpark
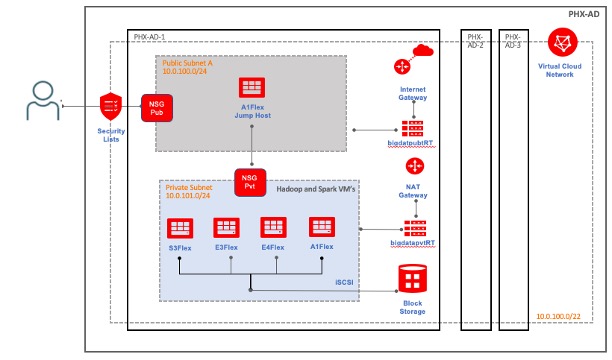
ベンチマーク構成
VMはプライベート・ネットワーク領域にプロビジョニングされました。Hadoop 3.3.1 (aarch64バイナリ)およびSpark 3.1.2がテスト・ベッドにインストールされました。表で説明する構成を使用して、各アーキテクチャに単一のVMがデプロイされました。すべてのVMに、同じCPUコアおよびスレッド構成、メモリーおよびストレージがありました。
ストレージ帯域幅は、すべてのVMでl000 MB/sに制限されていました。8 OCPUのx86 VMの最大帯域幅は、OCIでは8 Gb/sです。16 OCPUのAmpere A1インスタンスは、最大帯域幅のl6 Gb/sを受け取ります。A1インスタンスは、x86 VMで平均を維持するために、ベンチマークで8 Gb/sにスロットルされました。ゲスト・オペレーティング・システムは、透過的なHuge Pageの無効化やVMのスワップ性の削減など、ほとんど変更されませんでした。
Sparkのいくつかの構成パラメータは、CPU、メモリーおよびストレージの使用率を最大化するようにチューニングされました。Oracle JDK8 EPPはテスト・ベッドで使用されました。パッチ34375301は、Oracleサポート・サイトからダウンロードできます。Oracle JDK 8エンタープライズ・パフォーマンス・パック(EPP)にJDK 17の改善が追加されました。
VMおよびSpark on yarn構成
| dfs.block.size |
256M |
| yarn.scheduler.minimum-allocation-mb |
1,024 |
| yarn.scheduler.maximum-allocation-mb |
65,536 |
| yarn.scheduler.minimum-allocation-vcores |
1 |
| yarn.scheduler.maximum-allocation-vcores |
15 |
| yarn.nodemanager.resource.cpu-vcores |
16 |
| yarn.nodemanager.resource.memory-mb |
94,208 |
| mapreduce.map.memory.mb |
1,024 |
| mapreduce.reduce.memory.mb |
3,072M |
| mapred.reduce.parallel.copies |
16 |
| mapreduce.reduce.shuffle.parallelcopies |
16 |
| mapreduce.map.java.opts |
2,048M |
| spark master |
yarn |
| spark.executor.memory |
12G |
| spark.default.parallelism |
30 |
ベンチマーク
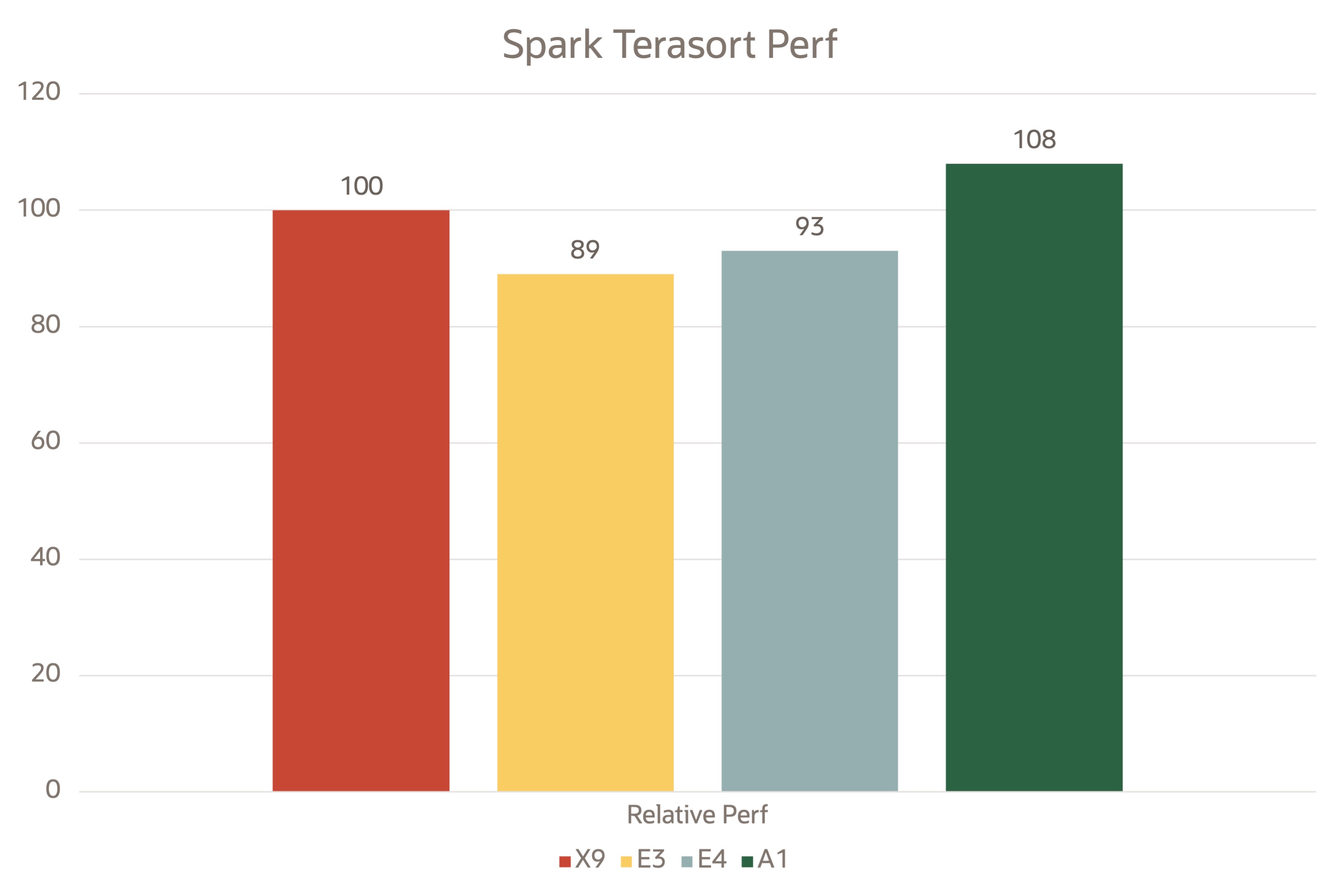
Spark TeraSort
TeraSortワークロードは、Hadoopディストリビューションに含まれるTeraGenプログラムによって生成された100バイトのレコードをソートします。Intel HiBenchベンチマーク・ツールは、各VMで250 GBデータセットを生成するために使用されました。これらのVMでSpark TeraSortベンチマークを実行し、TeraSort出力をMB/sで取得しました。
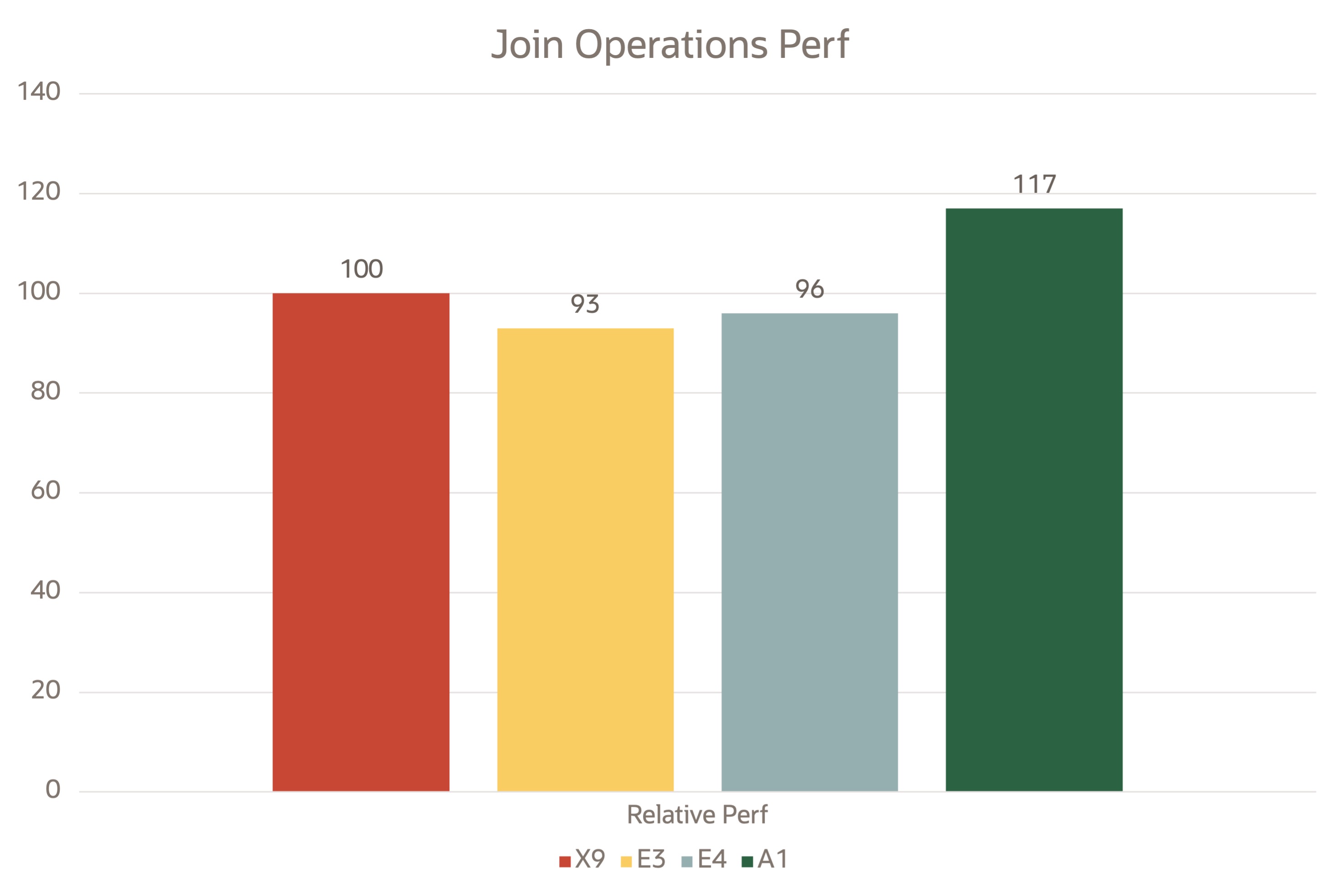
Joint operations
Sparkシェルで次のScala問合せを複数回実行し、ジョイント問合せの完了に要した時間を取得しました。
val df = sc.makeRDD(1 to 10000000, 7).toDF
val df2 = sc.makeRDD(1 to 10000000, 7).toDF
df.select( $"value" as "a").join(df2.select($"value" as "b"), $"a" === $"b").countWord count
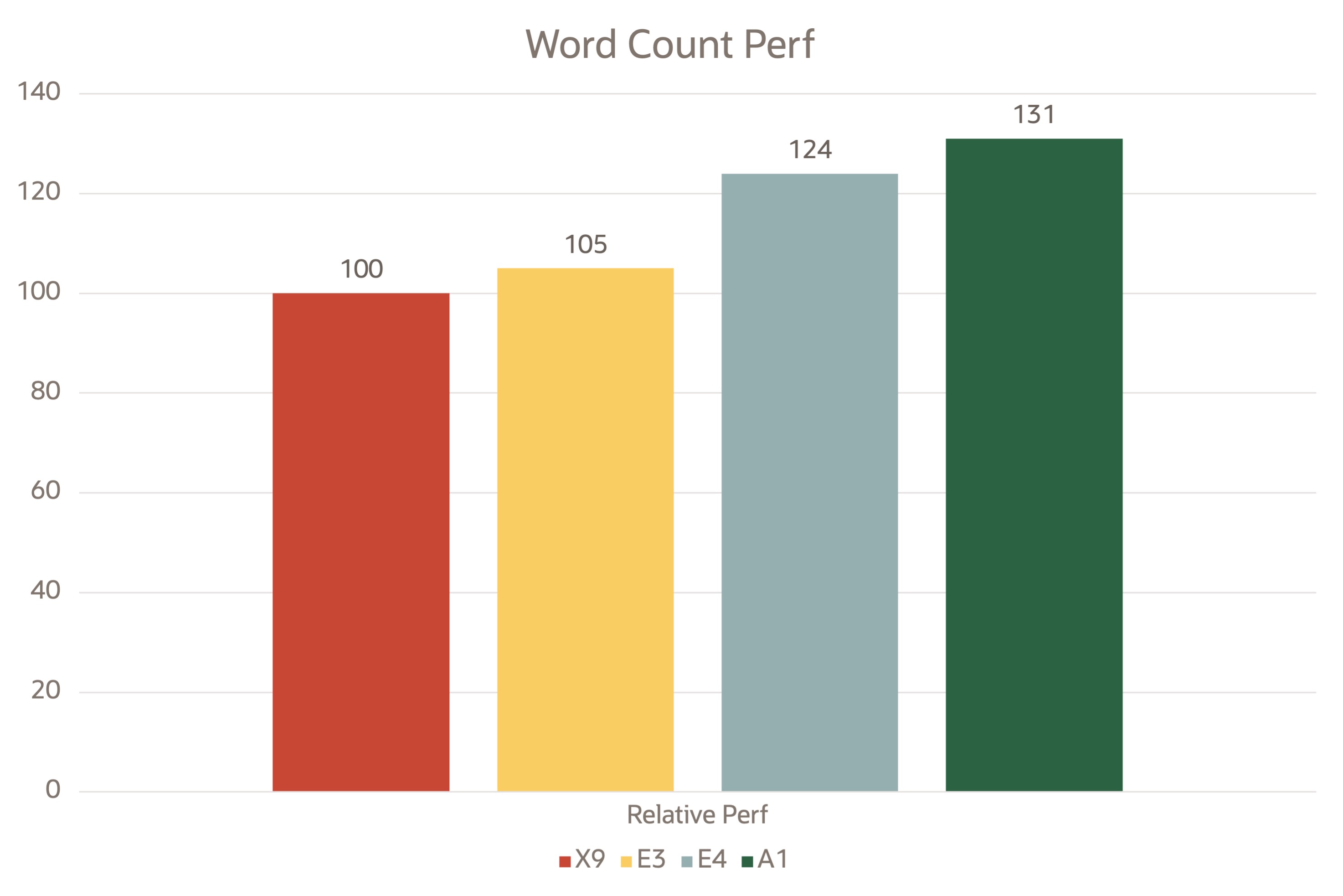
ワード・カウント・プログラムは、実世界のMapReduceジョブの大規模なサブセットを表します。1つはデータをある表現から別の表現に変換し、もう1つは大量のデータ・セットから少量の興味深いデータを抽出します。10 GBのテキスト・ファイルをHDFSにアップロードし、ファイル内の単語をカウントしようとしました。
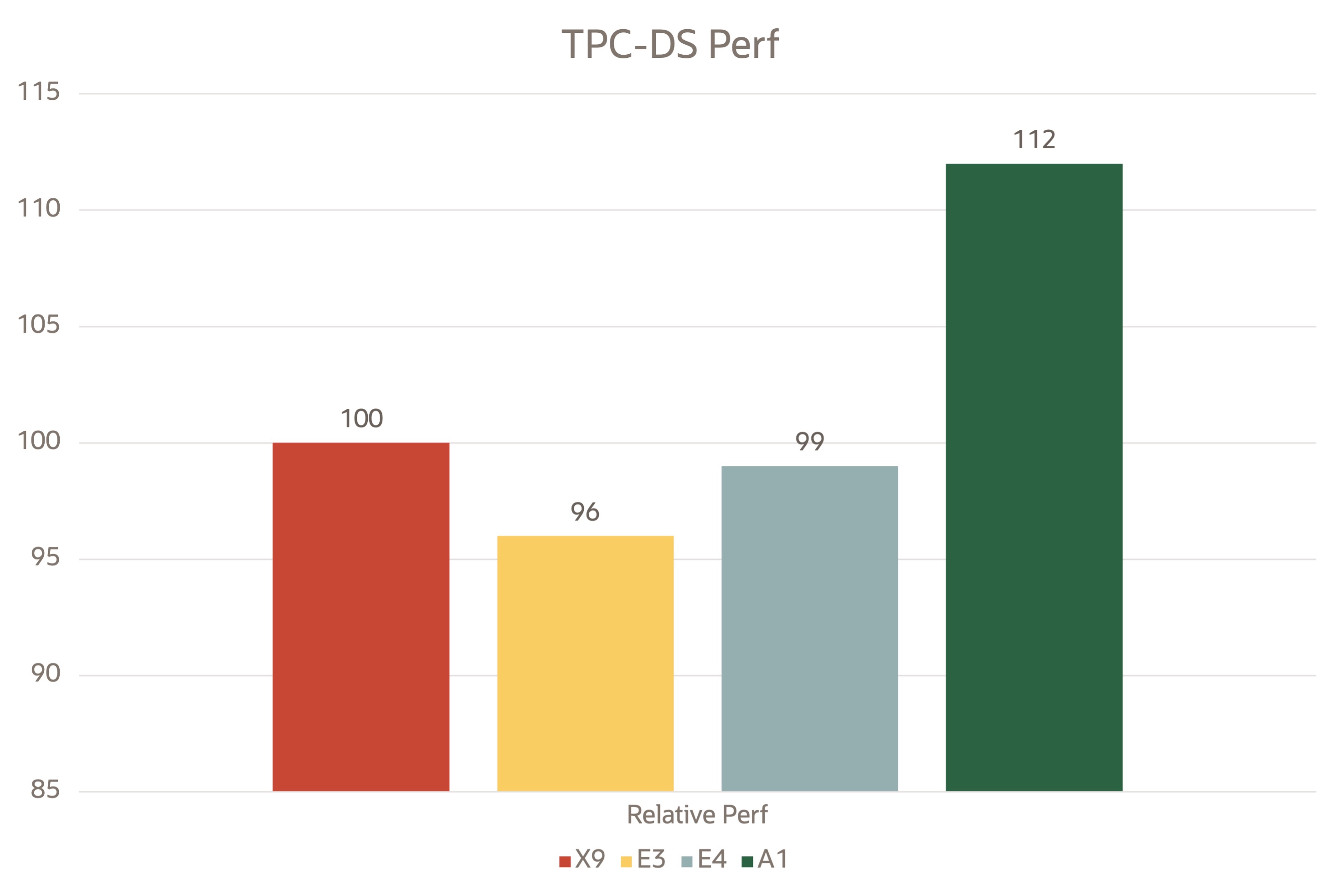
TPC-DS
TPC-DSは、意思決定支援システムのいくつかの側面をモデル化する意思決定支援ベンチマークです。tpcds-kitは、DataBricks GitHubサイトからクローニングしました。Spark 3.2をyarnモードで、スケーリング・ファクタ250をparquet形式で実行しました。その後、すべての99 SQL文の実行にかかった時間を取得しました。
パフォーマンス・データ
次の図は、Spark on yarnを使用してOCIテスト・ベッドで取得された相対パフォーマンス・データを示しています。
Word count
Join operations
Spark Terasort
TPC-DS
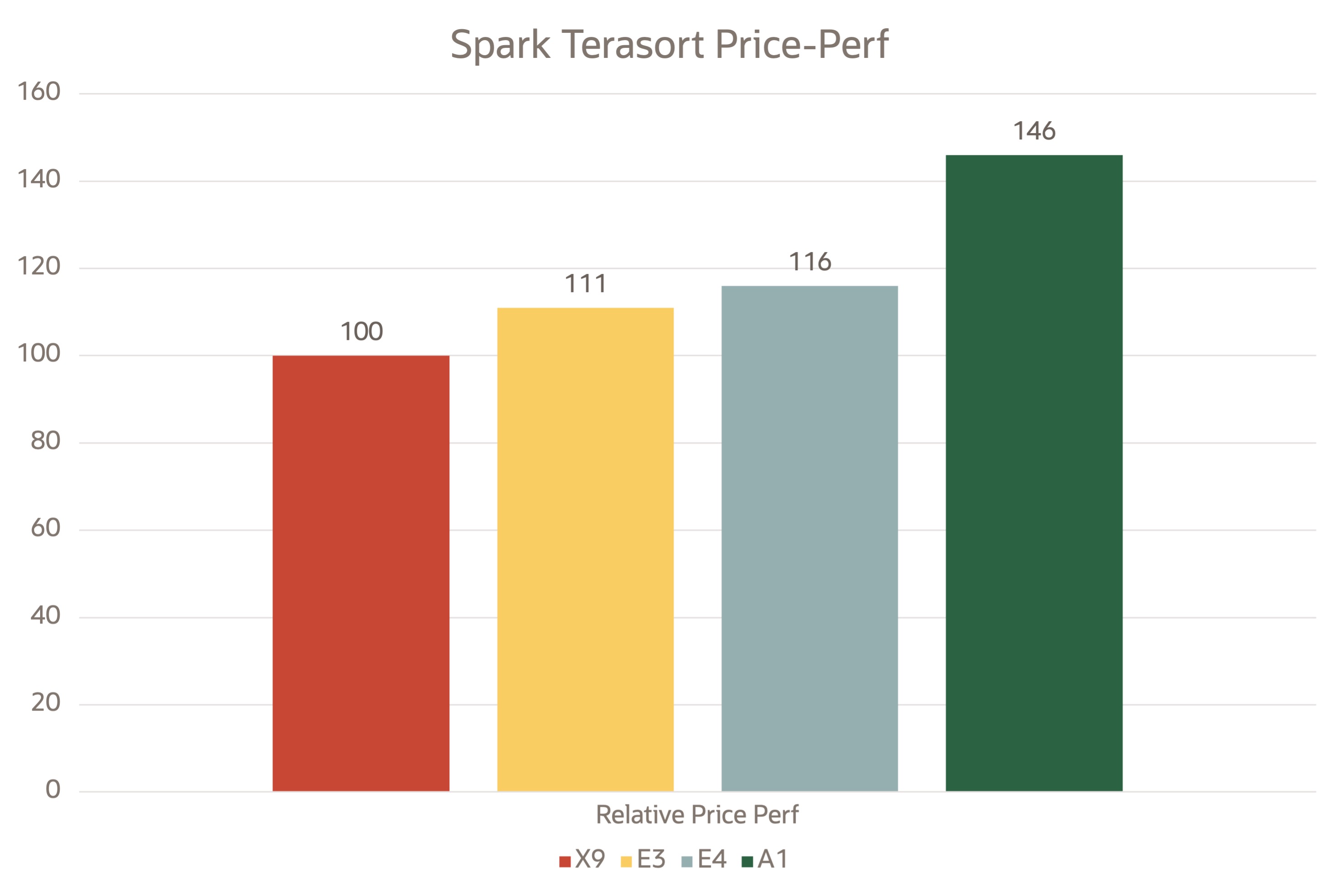
次の図は、Spark TeraSortで取得された相対的な価格パフォーマンス・データを示しています。コンピュートおよびストレージの価格設定から価格を取得することで、ワード・カウントや結合操作など、他のベンチマークやテストに類似したグラフをプロットできます。
OCI VM上のSparkの相対価格パフォーマンス分析
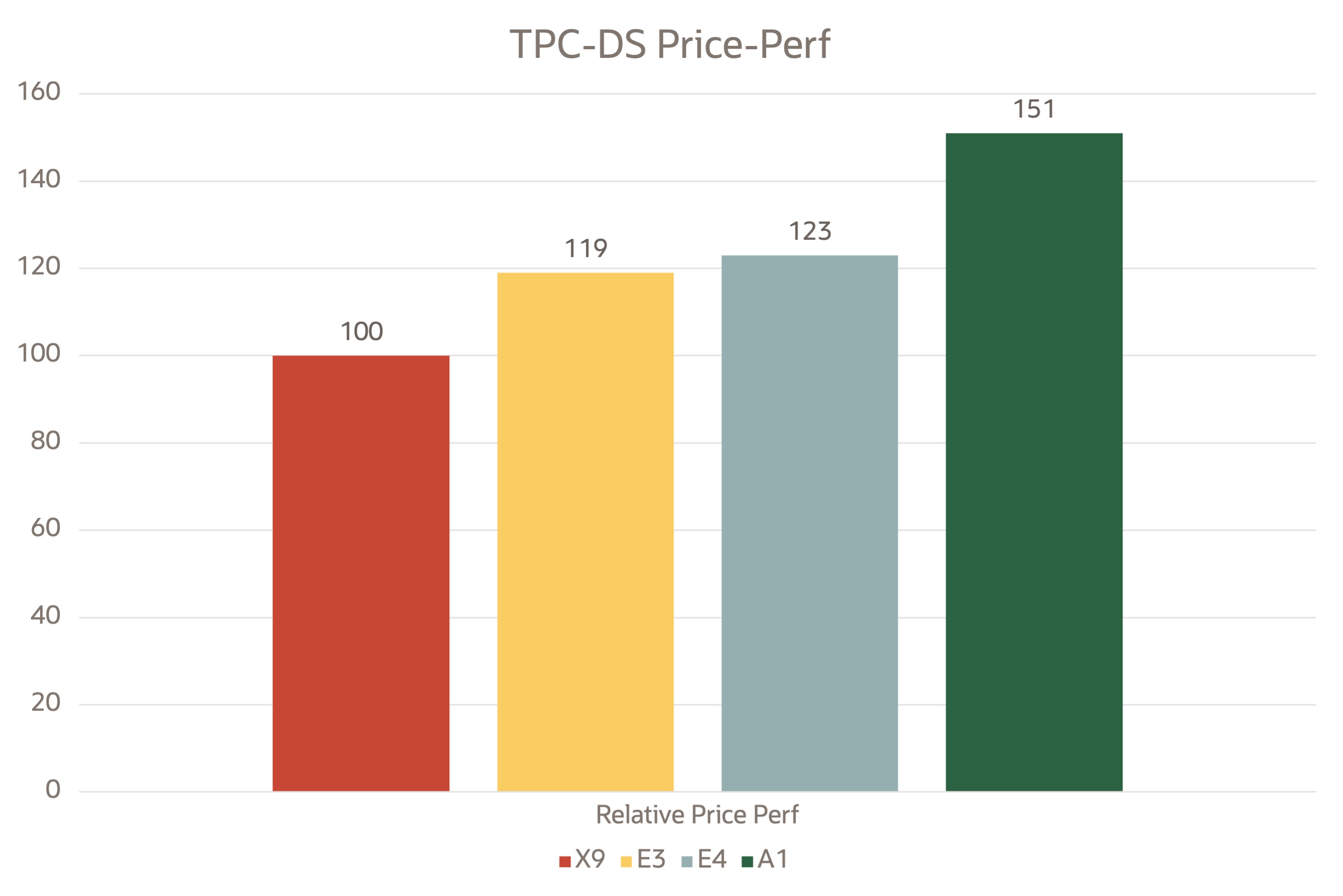
OCI VM上のTPC-DSの相対的な価格パフォーマンス分析
観察
-
パラメータのチューニング後、CPUはフルに利用され、約85-90%程度で推移しており、負荷の高い状況での公正な比較となりました。
-
Ampere A1 VMは、x86ピアと比較して適切に実行されました。パフォーマンス・グラフは、Intel X9をベースライン参照ポイントとして描画したものです。
-
OCI Ampere A1シェイプの価格性能は、Intelより50%、AMDシェイプより30%優れています。
価格パフォーマンスは、16コアVMおよび96Gメモリー(2022年10月)のOCI Compute価格リストから計算されました。ストレージ・コストは、50 VPU (480 MB/s)の2つの500 GB iSCSI LunsのOCI Storage価格シートから計算されました。
まとめ
Ampere Altraプロセッサを搭載したOracle OCI Ampere A1インスタンスは、Apache Sparkなどのビッグ・データ・ソリューションに高いパフォーマンスを提供します。Ampereインスタンスでのパフォーマンス上の利点は、Spark TeraSortおよびTPCDSワークロードにOracle Cloud Infrastructure Ampere A1インスタンスを使用する場合、最大50%高い価格パフォーマンスを提供します。
詳細は、次のリソースを参照してください。:
