This blog was written in collaboration with Rama Nishtala, senior principal application engineer at Ampere.
Apache Spark is an open-source, distributed processing system used for big data workloads. It utilizes in-memory caching and optimized query processing for fast analytic queries against data of any size. It provides APIs in Java, Scala, and Python. Spark supports multiple operations in real-time analytics, batch processing, interactive queries, and machine learning. Spark addresses the limitations of Hadoop by doing in-memory processing using Resilient Distributed Dataset (RDD) and reusing data across multiple parallel operations. Spark works with many storage systems like HDFS, Couchbase, Cassandra, and others. Spark can run in a standalone cluster mode or on cluster management systems like Yarn, Kubernetes, and Docker.
Spark architecture consists of the Spark driver, executor, and cluster manager. The driver is the controller of the Spark execution engine and maintains the state of the cluster. It interacts with the cluster manager to get physical resources like vCPU and memory. The driver also launches the executors. Actual tasks are processed by the Spark executors assigned by the driver. The executors run the tasks and report back their results and state to the driver. The cluster manager is responsible for maintaining the cluster of nodes that run the Spark applications.
Spark on OCI Ampere A1 Flex VM
Oracle Cloud Infrastructure (OCI)’s A1 compute, powered by Arm-based Ampere Altra processors, provides superior price-performance for big data applications when compared to its x86 peers. A1 shapes with Ampere processors are a recommended choice for Spark applications for the predictable and highly scalable nature of the architecture.
OCI uses Ampere Altra processors with industry-leading 80 cores per CPU for the OCIAmpere A1 shapes. All cores can run at the maximum frequency of 3.0 GHz consistently. Utilizing Ampere Altra’s low-power design and OCI’s high-performance infrastructure, Ampere A1 shapes deliver the best price-performance in the cloud.
In this blog post, the performance of OCI Ampere VM.Standard.A1.Flex virtual machines (VMs), represented as A1 in the charts, is compared with OCI’s VM.Standard3.Flex, represented as X9 in the charts (Intel IceLake), VM.Standard.E3.Flex, represented as E3 in the charts (AMD Rome), and VM.Standard.E4.Flex, represented as E4 in the charts (AMD Milan) flex VMs. The following benchmarks and tests were run on Spark with yarn:
-
Spark TeraSort
-
Join operations
-
Word count
-
TPC-DS
Spark on OCI Architecture
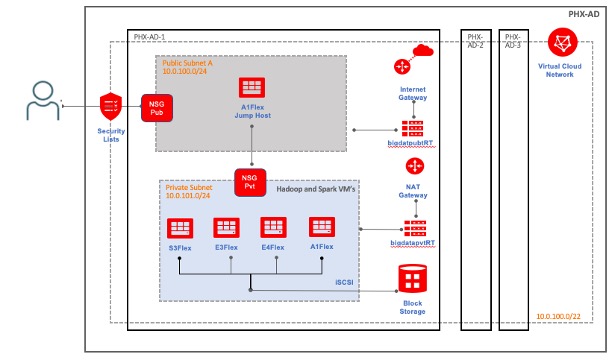
Benchmarking configuration
VMs were provisioned in a private network space. Hadoop 3.3.1 (aarch64 binaries) and Spark 3.1.2 were installed on the test bed. A single VM was deployed across each architecture with the configuration outlined in the table. All VMs had identical CPU core and thread configurations, memory, and storage.
The storage bandwidth was limited to l000 MB/s across all the VMs. The maximum bandwidth for an x86 VM with 8 OCPUs is 8 Gb/s in OCI. An Ampere A1 instance with 16 OCPUs receives a max bandwidth of l6 Gb/s. The A1 Instance was throttled to 8 Gb/s in our benchmark, to keep it average with x86 VMs. Few changes were made to the guest operating system, including disabling transparent huge pages and reducing VM swappiness.
A few configuration parameters in Spark were tuned to maximize the utilization of CPU, memory, and storage. Oracle JDK8 EPP was used on the test bed. You can download the patch 34375301 from the Oracle support site. JDK 17 improvements are added to Oracle JDK 8 enterprise performance pack (EPP).
VM and Spark on yarn configuration
| dfs.block.size |
256M |
| yarn.scheduler.minimum-allocation-mb |
1,024 |
| yarn.scheduler.maximum-allocation-mb |
65,536 |
| yarn.scheduler.minimum-allocation-vcores |
1 |
| yarn.scheduler.maximum-allocation-vcores |
15 |
| yarn.nodemanager.resource.cpu-vcores |
16 |
| yarn.nodemanager.resource.memory-mb |
94,208 |
| mapreduce.map.memory.mb |
1,024 |
| mapreduce.reduce.memory.mb |
3,072M |
| mapred.reduce.parallel.copies |
16 |
| mapreduce.reduce.shuffle.parallelcopies |
16 |
| mapreduce.map.java.opts |
2,048M |
| spark master |
yarn |
| spark.executor.memory |
12G |
| spark.default.parallelism |
30 |
Benchmark
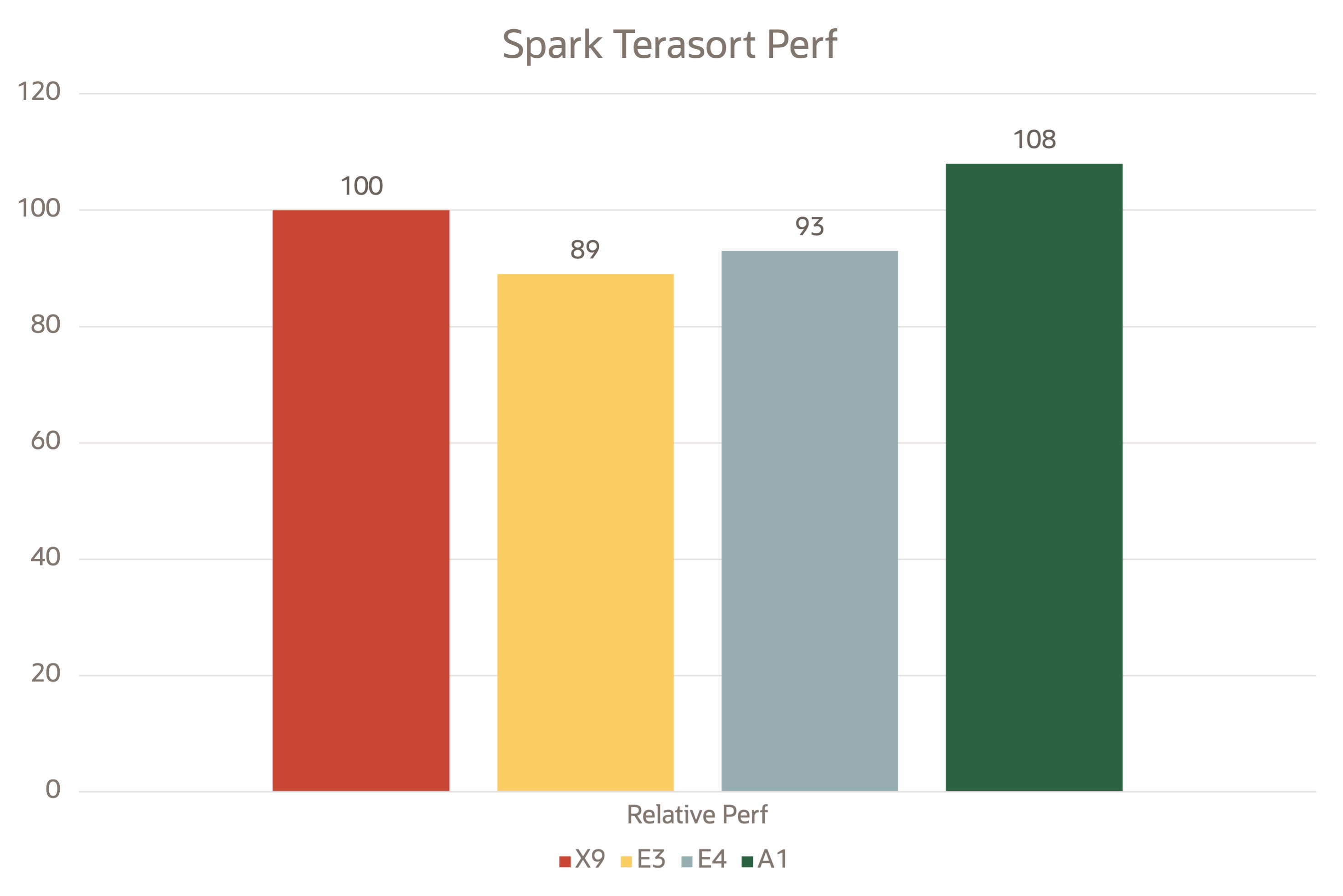
Spark TeraSort
The TeraSort workload sorts 100-byte records generated by the TeraGen program contained in the Hadoop distribution. The Intel HiBench benchmark tool was used on each of the VMs to generate a 250 GB dataset. We ran the Spark TeraSort benchmark on these VMs and captured the TeraSort output in MB/s.
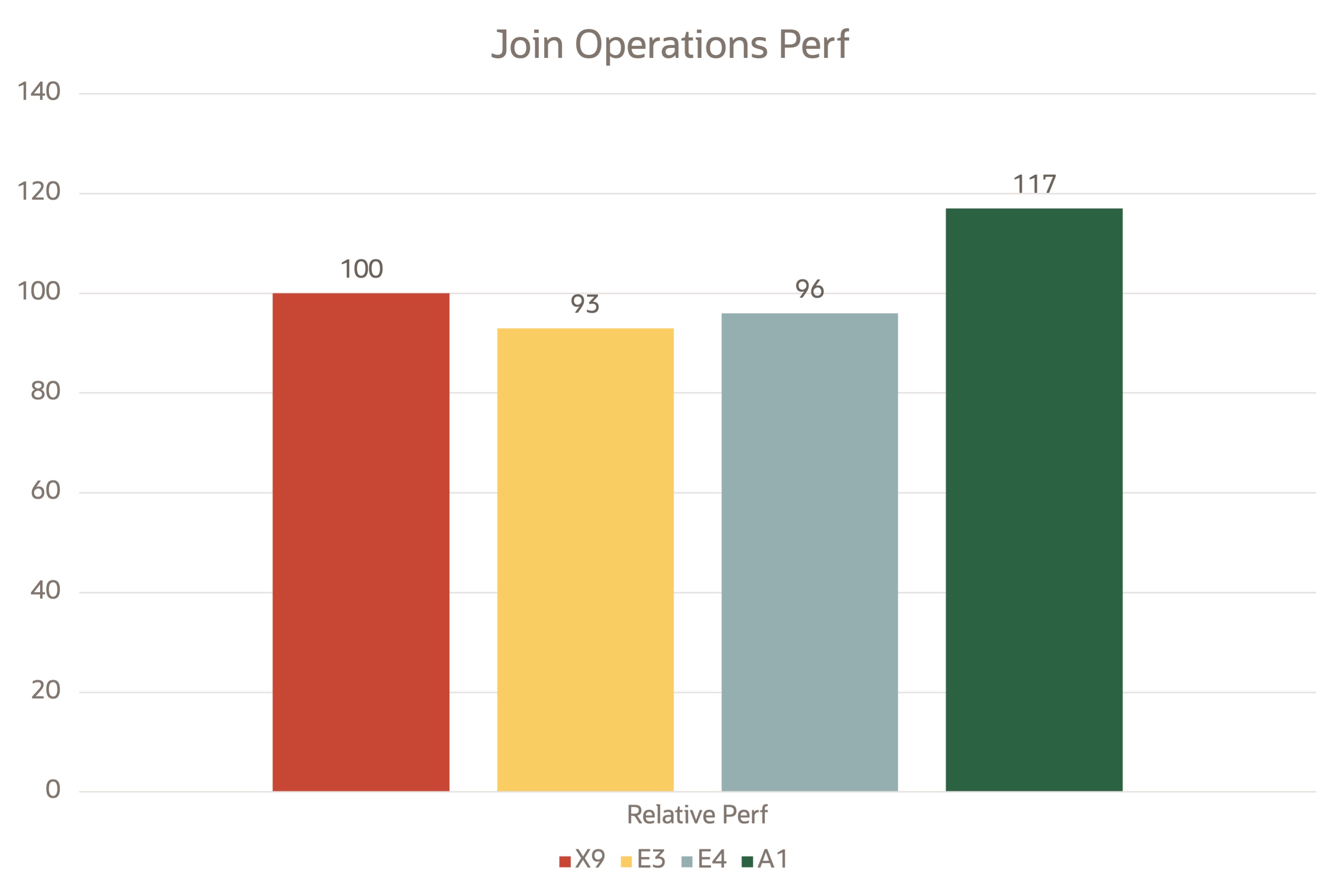
Joint operations
We ran the following Scala query multiple times in a Spark shell to capture the time taken to complete the joint query.
val df = sc.makeRDD(1 to 10000000, 7).toDF
val df2 = sc.makeRDD(1 to 10000000, 7).toDF
df.select( $"value" as "a").join(df2.select($"value" as "b"), $"a" === $"b").countWord count
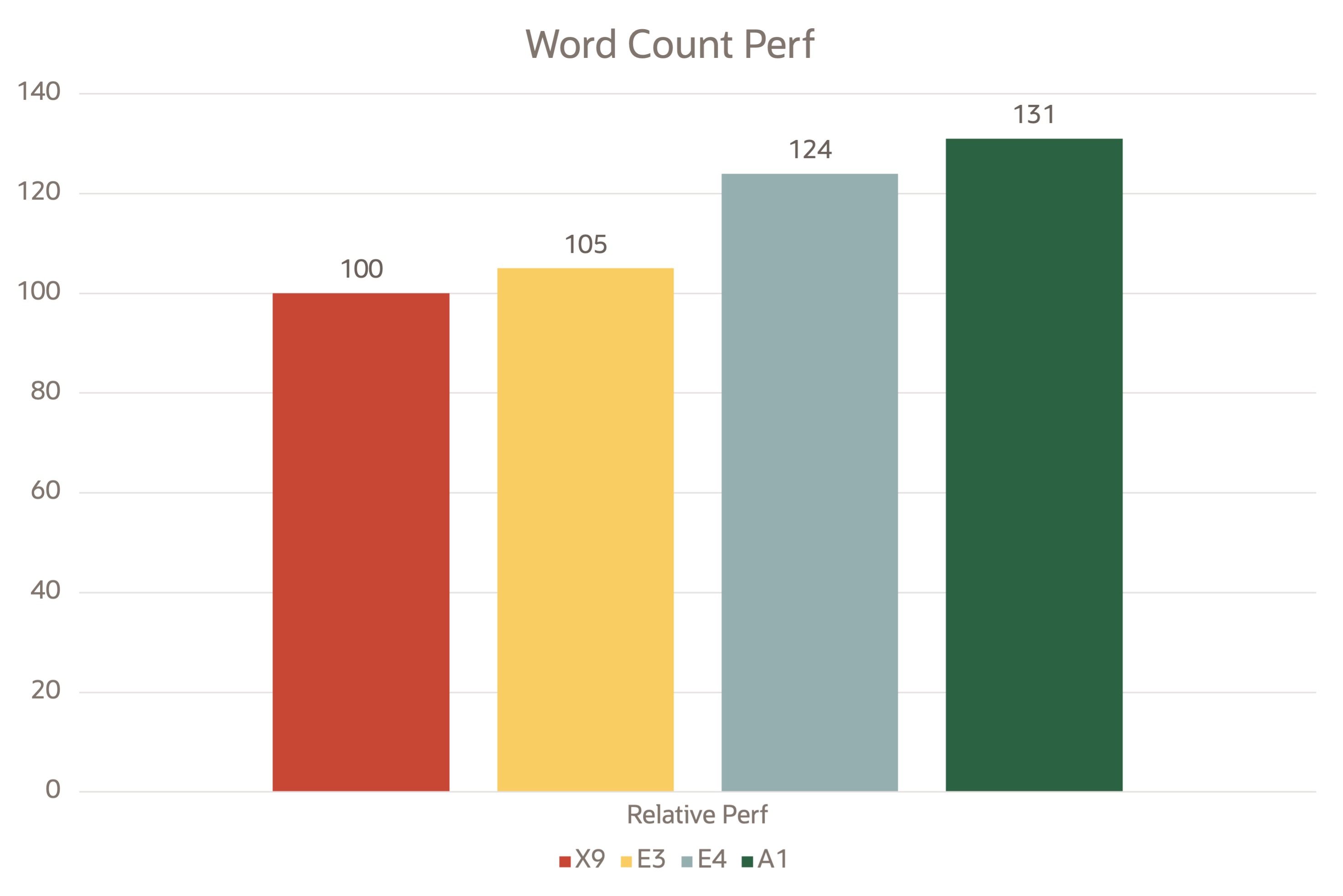
Word count programs are representative of a large subset of real-world MapReduce jobs, one transforming data from one representation to another and another extracting a small amount of interesting data from a large data set. We uploaded 10 GB of text files to HDFS and then attempted to count the words in the file.
TPC-DS
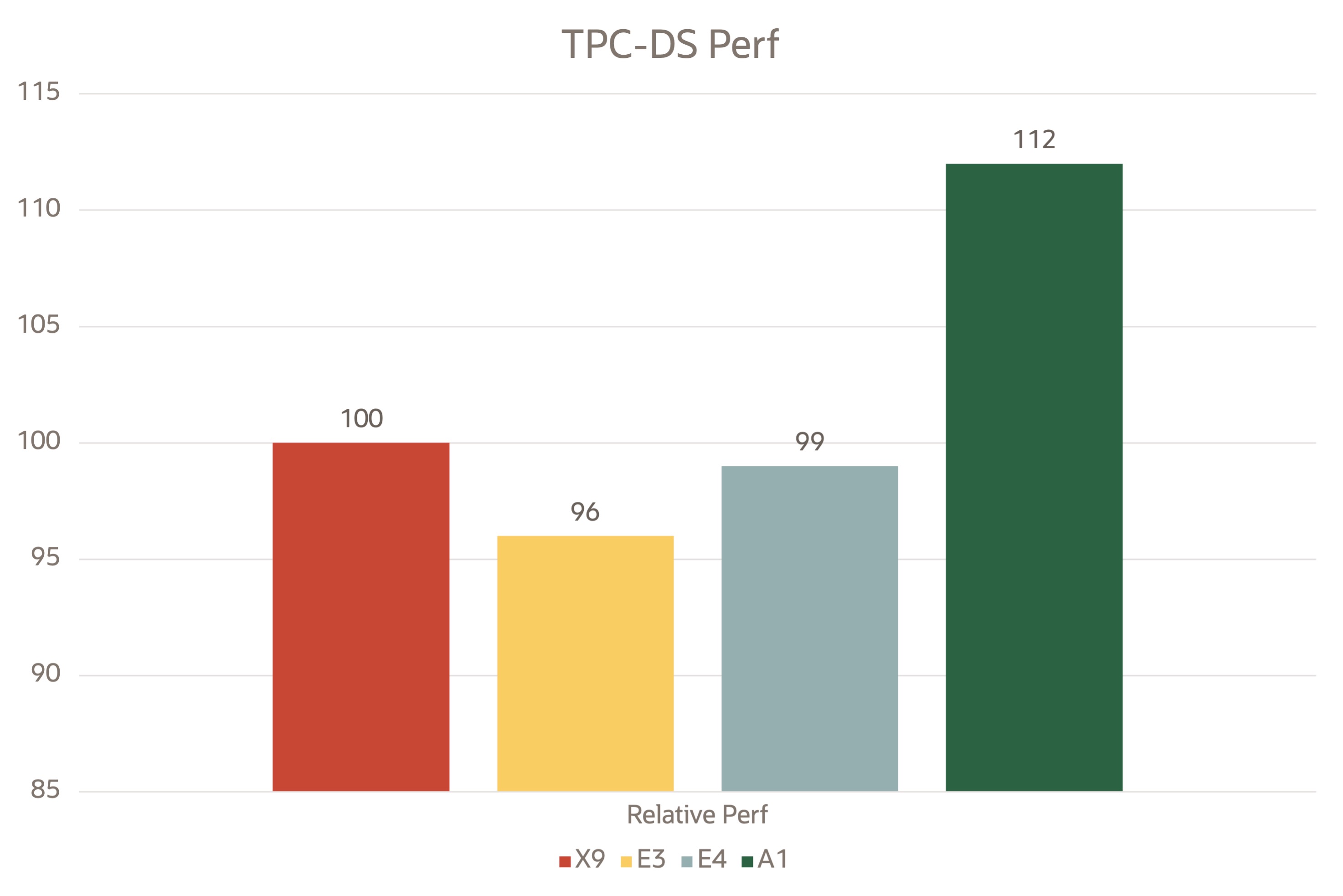
TPC-DS is a decision support benchmark that models several aspects of a decision support system. We cloned the tpcds-kit from the DataBricks GitHub site. We ran Spark 3.2 in yarn mode with a scale factor of 250 in parquet format. Then we captured the time taken to run all the 99 SQL statements.
Performance data
The following images show the relative performance data captured on the OCI test bed with Spark on yarn.
Word count
Join operations
Spark Terasort
TPC-DS
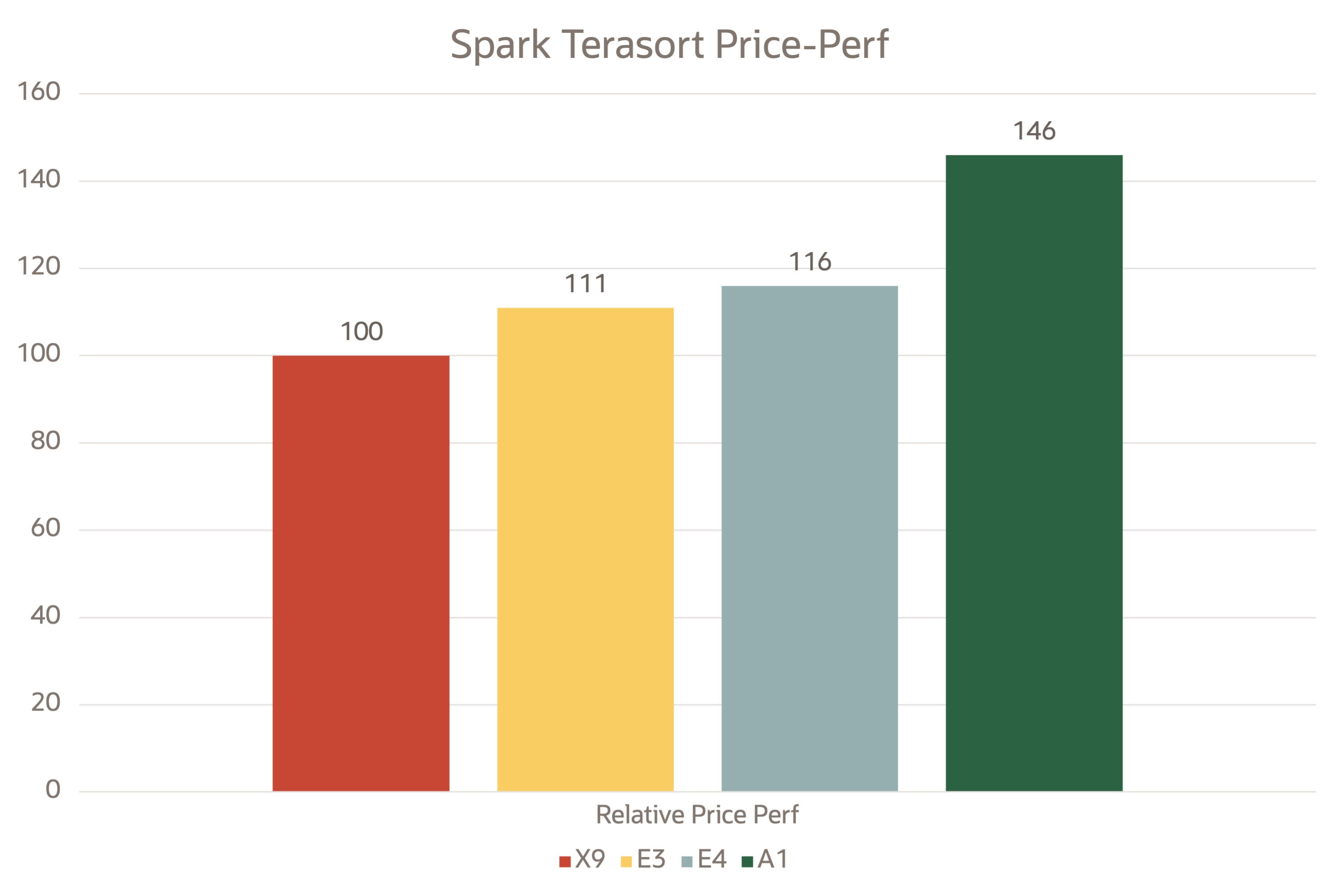
The following image shows the relative price-performance data captured with Spark TeraSort. You can plot similar graphs for other benchmarks and tests like word count and join operations by taking the prices from compute and storage pricing.
Relative price-performance analysis for Spark on OCI VMs
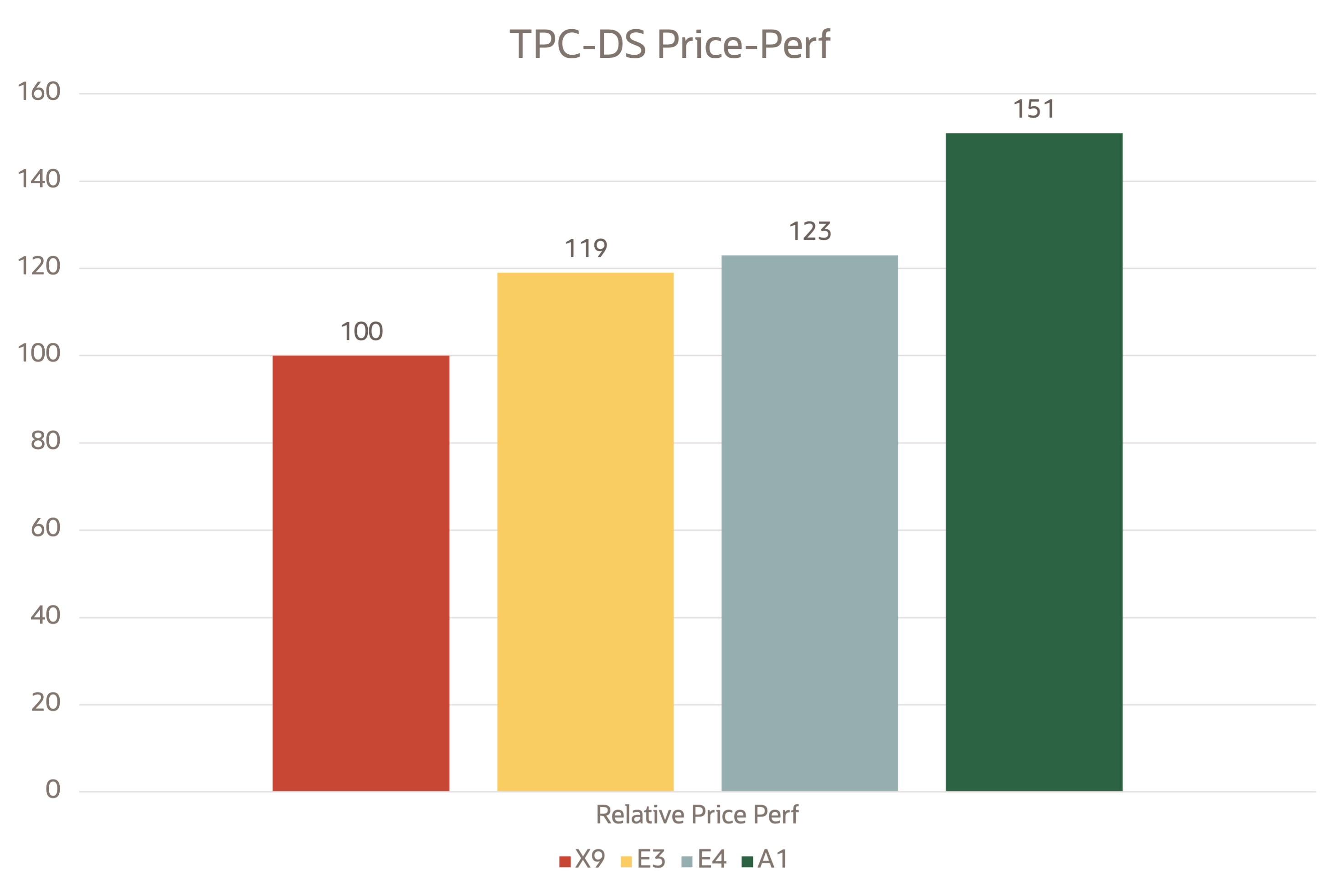
Relative price-performance analysis for TPC-DS on OCI VMs
Observations
-
After tuning the parameters, the CPU was fully utilized and hovered around 85–90%, making this a fair comparison under high load conditions.
-
Ampere A1 VMs performed well compared to their x86 peers. The performance graphs were plotted by taking Intel X9 as the baseline reference point.
-
OCI Ampere A1 shapes price-performance was observed to be 50% better than Intel and 30% better over AMD shapes.
Price-performance was calculated from the OCI Compute pricing list for 16 core VMs and 96G memory (Oct 2022). Storage costs were calculated from the OCI Storage pricing sheet for two 500-GB iSCSI Luns at 50 VPU (480 MB/s).
Conclusion
Oracle OCI Ampere A1 instances powered by Ampere Altra processors provide high performance for big data solutions like Apache Spark. The performance advantage on the Ampere instances, combined with the price advantage, provides up to 50% higher price-performance when using Oracle Cloud Infrastructure Ampere A1 instances for Spark TeraSort and TPCDS workloads.
For more information, see the following resources:
