※本ページは、”Oracle Database In-Memory and Exadata are meant for Agentic AI Workloads” の翻訳です。
データはAIアプリケーションの基盤です。汎用LLMはインターネット上の多種多様な膨大なデータで学習されることがありますが、目的特化型アプリケーションは特定のデータセットに基づき、ユーザーや他のアプリケーションにとって的確かつ関連性の高い結果を提供します。AIアプリケーションを支えるデータの質や新しさは、その応答の価値と直接相関します。データ品質が低いと、ハルシネーションや完全に誤った結果につながります。エージェント型AIのユースケース――AIアプリケーションが他のアプリケーションの出力を入力として処理し、そのうえで次に取るべきステップを決定する場合――ではデータ品質はさらに重要になります。こうしたシステムはユーザーへ影響を与えるだけでなく、多数の入力や自身および他システムの現状を評価しながら、複雑な意思決定を自律的に行う場合があります。正確でアクセス可能かつ最新のデータを用いることは、アプリケーションとその利用者双方の成功に極めて重要です。
こうしたAIアプリケーションにとって最も自然なデータセットは、企業のトランザクションデータセットです。具体例は以下の通りです:
- リソース消費メトリクス:顧客や地域、全体ごとの利用率を把握し、リソース計画策定に寄与
- 売上や在庫データ:事業の業績を反映し、物流のニーズを知らせる
- カスタマーサポートチケットの傾向:顧客満足度を示し、製品不具合や誤ったマーケティングページ等の特定に有用
- ウェブサイト来訪数やクリック率:マーケティングキャンペーンの成果を示し、現状のメッセージングの有効性を確認または方向転換を示唆
従来、トランザクション処理と大規模な分析・ML・AIクエリを同一システムで行うとパフォーマンスが低下するという課題がありました。トランザクション処理向けに設計・最適化されたシステムは、主に多くの小さなトランザクションを高速に処理できる正規化データ形式を使用します。一方、分析やAIシステムには大量データの高速検索・抽出が求められます。この用途・アーキテクチャの違いは、システム設計者にデータの非正規化やカラムナ型データストア採用を強いることが多くあります。その結果、元のトランザクションデータを異なる形式や、複数のデータサービスエンジン・プラットフォームに重複して保持する必要が生じます。たとえ対応できるシステムであっても、トランザクションと分析やAIのワークロードを両立させるのは性能面で困難な場合が多いです。
この問題への伝統的な解決策は「データの複製」です。ETL(Extract, Transform, Load)処理は、長年使われてきた手法であり、データをより下流のシステム向けに加工・結合しつつ転送します。ELT処理では、まずソースのデータを迅速に転送し、ターゲット側で変換を行います。ETLもELTも広義にはデータレプリケーションであり、ソースの業務データのサブセットを他用途向けシステムに転送します。ソースデータの複製は、同一システム内で未加工データに追加ワークロードを実行するよりは低負荷ですが、それでもソースシステムに影響します。
しかし、データレプリケーションには固有の課題もあります。たとえリアルタイム複製(ソースシステムの各トランザクションを即座にターゲットへ送る)であっても、ソースとターゲット間に遅延や不整合が生じます。従来多かったのは、日次・毎時・数分ごとにバッチで変化分を転送する方式です。多くの利用者は、ビジネス上のコストとしてデータの遅延や鮮度低下(例:売上データや収益が直近24時間などごく最近分は正確でない、未反映である)が生じることを受け入れてきました。しかし、エージェント型AIがデータをもとに重要な意思決定を行いはじめると、この「ギャップ」は致命的となり、リアルタイムな意思決定を妨げる要因となります。
もう一つの課題は、複製環境(追加システム)の存在自体です。これら環境は管理者が維持し、企業が運用コストを負担せねばなりません。たいてい歴史的データが蓄積し年々巨大化します。運用者はソースデータを保持するだけでなく、大量データの並列分析クエリ対応のため、ソース環境自体より遥かに大規模な環境の構築・管理を強いられることもあります。
三つ目の課題は、下流システムのニーズ変化に応じて複製システムのデータ要件が変化した時です。正確・完全なデータを届けるため、パイプラインの継続的な運用・管理が必要になり、複製セットの変更、特定スキーマやテーブルの全履歴リロード、さらには複製プロセスの中断時の整合性チェックや一部ソースデータの削除・再ロードなどが必要となる場合があります。ユーザーが全データ変更がターゲットシステムに正しく届いたと確信できるようにするためです。
これらの課題はどのように対処、あるいは排除できるのか?
Oracle AI Databaseは、トランザクション、分析、そして最新のAIベクタ処理など幅広いワークロードを、単一のデータベースエンジンでサポートします。これにより、AIエージェントはソース上で最新のビジネスデータを利用できるようになります。それでも、高度なAIユースケースに必要な極限のパフォーマンスを達成するには、単一エンジンで混合ワークロードを実現するだけでは十分と言えません。パフォーマンスおよびアーキテクチャ上の課題を本当に解消するには、全体的なアプローチが必要です。
1つのデータベースで混合ワークロードを処理するのは複雑ですが、Oracle AI Databaseはこれを卓越して実現しています。他社プラットフォームでは、しばしばトランザクション、分析、またはベクタ処理のいずれかを選ばせるため、データの重複、古いデータ、壊れやすいETL/ELTパイプライン、追加ストア、そして一貫性のない運用・セキュリティモデルを強いられます。
Oracle AI Databaseは、すべてのワークロードに対して単一のコピーでデータを一元管理し、統合された運用とセキュリティを実現しています。これにより、前述の課題のうち2つを即座に排除できます。第一に、すべてのデータが単一データベース内に存在するため、追加の環境を作成・維持する必要がなくなります。第二に、データパイプラインの構築が不要となり、ソースアプリケーションの変更に応じたパイプライン維持管理の手間も解消します。
サードパーティ拡張/プラグインやパイプラインはデータ同期を複雑化させ、アプリケーションにとってエージェント型AIワークロードには最適でないソリューションを強制します。他社データベースやプラットフォームは、カラムナストレージやインメモリアナリティクスなどの機能提供のために、拡張機能/プラグインやさまざまなOSSライブラリを組み合わせて依存することが多いです。こうしたアプローチは、リスクやデータ不整合をもたらし、更新のたびに複雑さが増し、Oracle AI Databaseの統合アーキテクチャほどのパフォーマンスは達成できません。
例えば、一部の非Oracleソリューションは、トランザクションワークロードのためのオープンソースRDBと、インメモリアナリティクス用の異なるSQLエンジン(やデータストア)を組み合わせ、両者をサブセカンドで同期しようとします。これらは多くの拡張やミドルウェアなどで連結されており、複雑さや障害点を増大させる要因となります。そしてこれは一例に過ぎません。
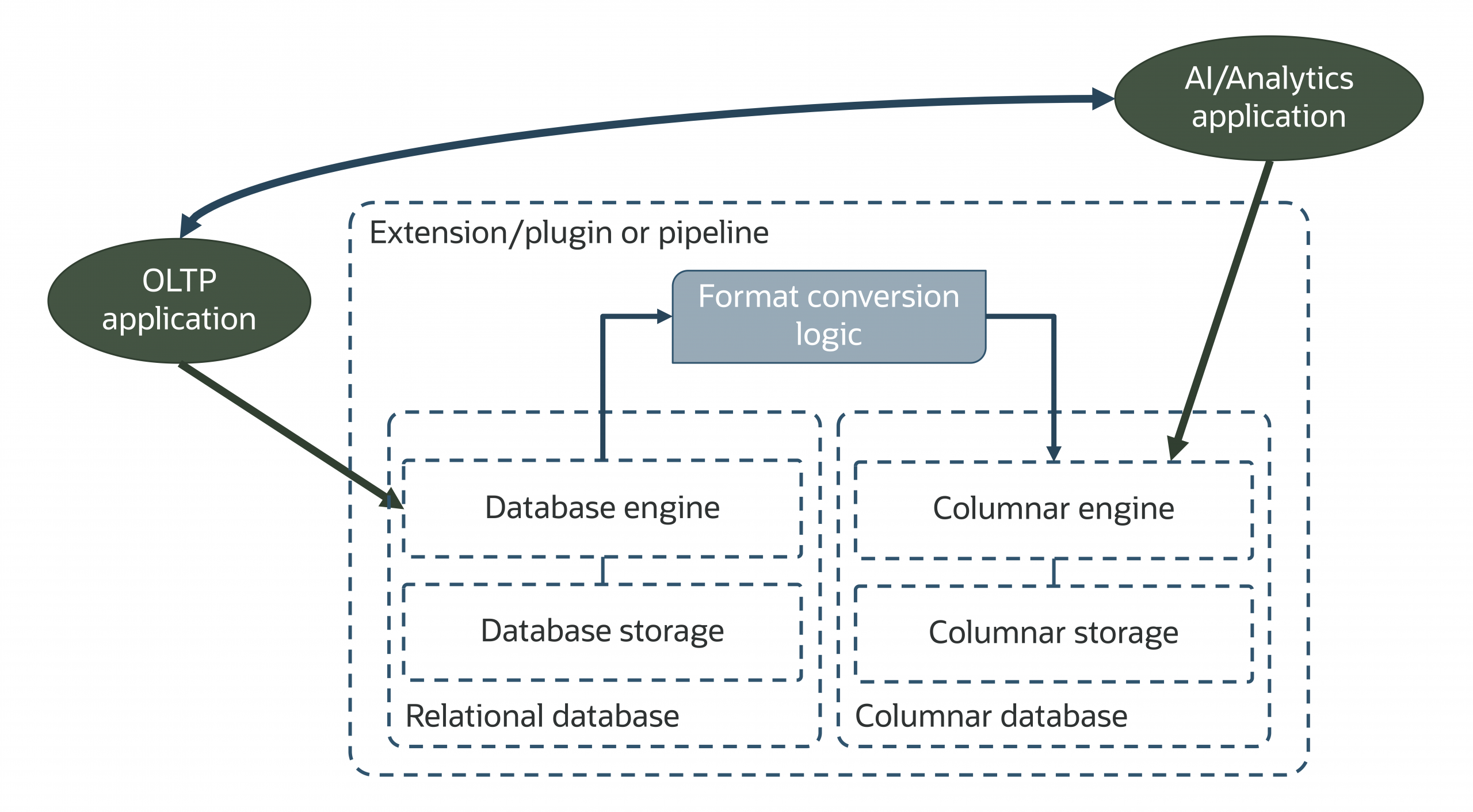
Oracleは根本的に異なるアプローチを採用しており、高パフォーマンス、拡張性、セキュリティ、エンタープライズクラスのデータ管理のための堅牢かつ統合された機能を提供しています。エージェント型AIワークロード向けにパイプライン不要のデータアクセスを実現するため、Oracle AI Databaseはデータを複数のフォーマットで同時に提示し、クエリを加速できます。行指向のメモリ常駐バッファキャッシュは多くのトランザクションワークロードに対応し、メモリ最適化されたカラムナ形式は分析クエリを高速化します。
これらのデュアルデータ表現はOracle AI Database本体に組み込まれており、データコピーや変換、異なるストア間同期のためのプラグインや拡張は不要です。これにより追加レイテンシがなくなり、トランザクション・分析両ワークロードで最新データを保証できます。
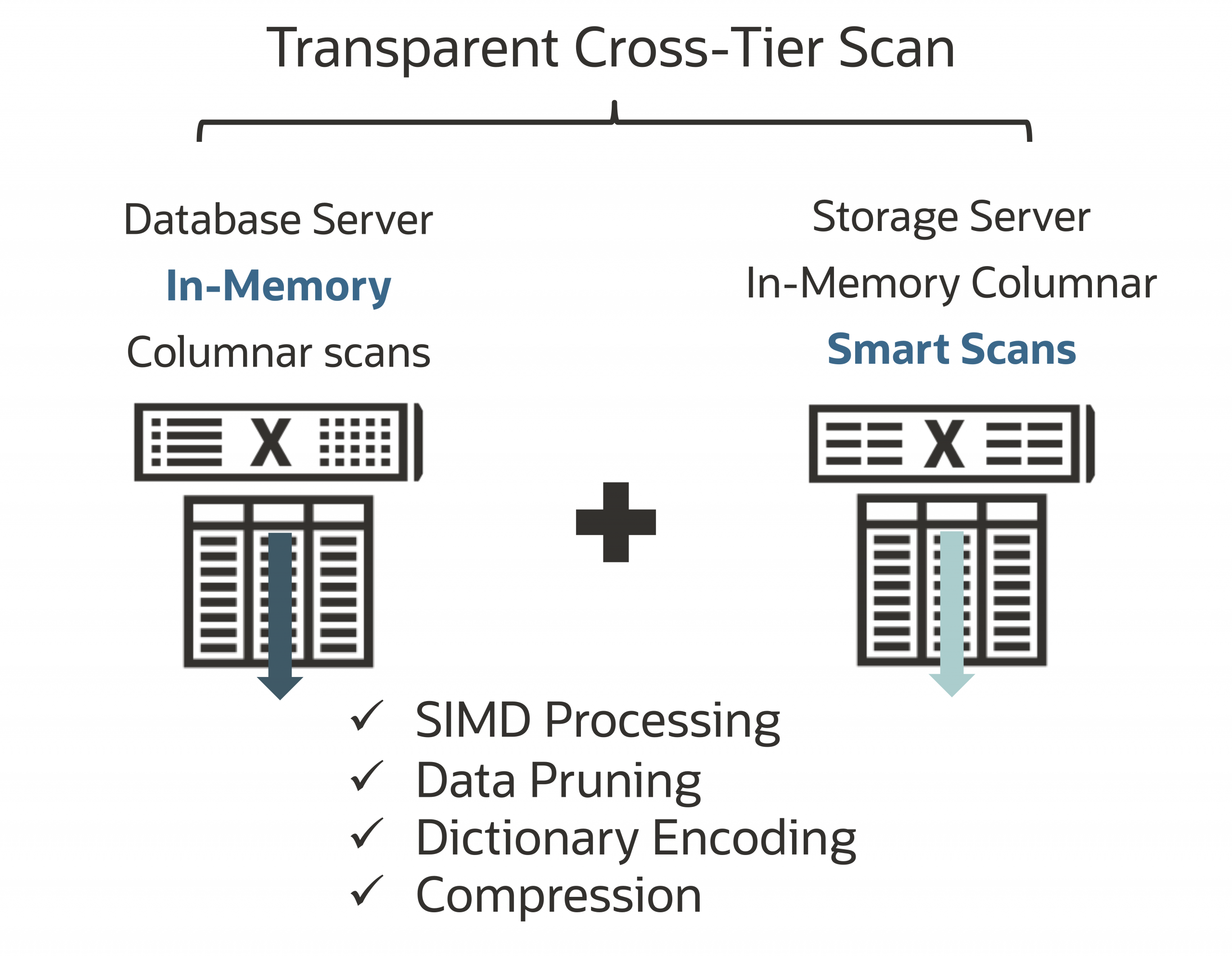
とくにインメモリ最適化のカラムナ表現(Database In-Memory, DBIM)に注目しましょう。DBIMはデータを純粋インメモリカラムナ形式で自動・透過的に提示し、高効率なインメモリスキャン・結合・集約のアルゴリズムを実装しています。モダンなCPUに実装されているSIMD処理(Single-Instruction, Multiple Data)も活用し、さらなるクエリ高速化を実現します。
Oracle AI Databaseは1つのクエリ内で行形式・カラムナ形式を同時に使い分けることができます。DBIMは拡張・プラグインではなく標準機能であり、両方の表現での更新も同時にコミットまたはロールバックされ、どのアクセス方式を選んでも古いデータとなることがありません。
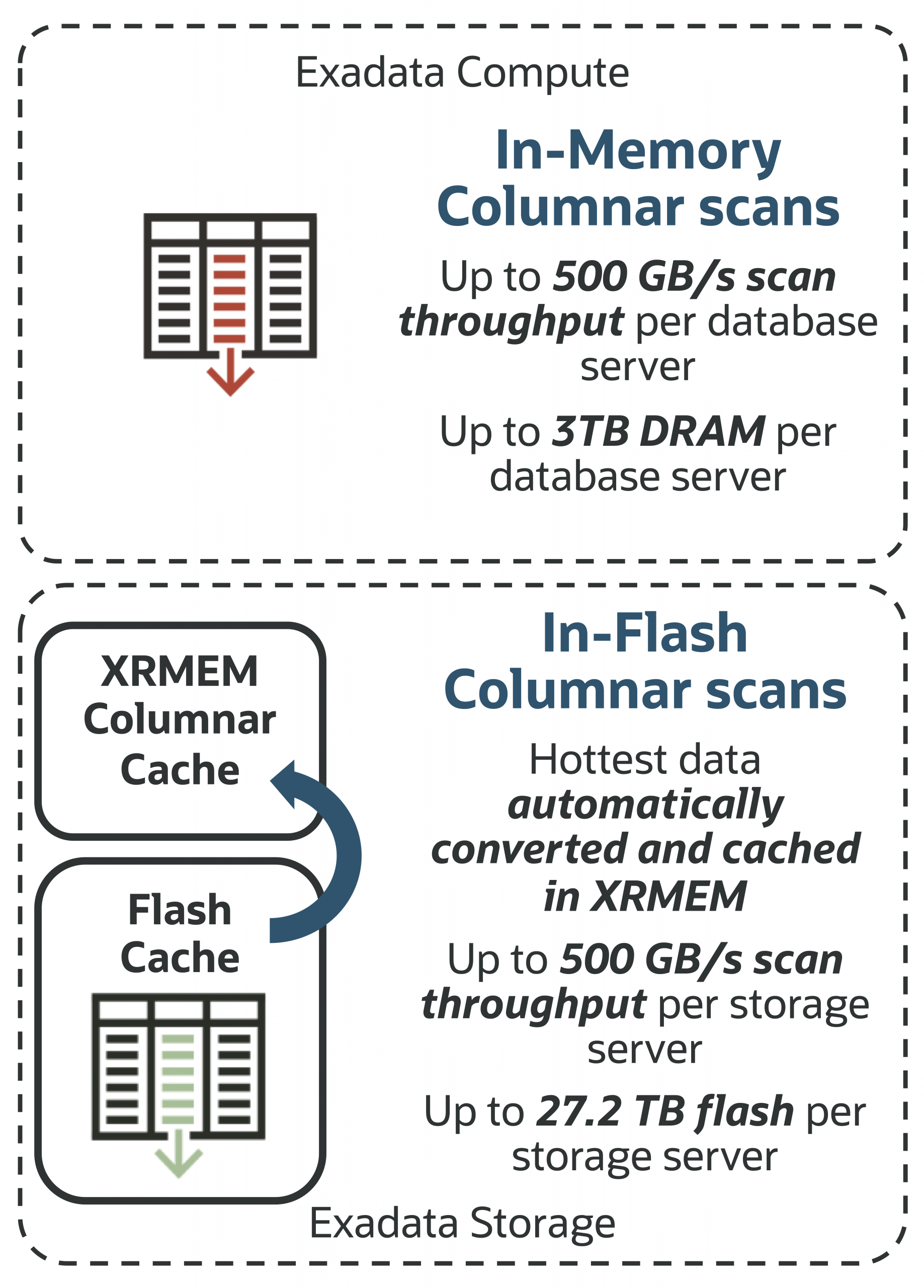
Exadata上のOracle AI Databaseは、データベースサーバとストレージサーバ(フラッシュとXRMEMを活用)におけるインメモリカラムナ処理で卓越した性能を発揮します。オンプレミス、Cloud@Customer、Oracle Cloud Infrastructure、もしくはDatabase@(AWS|GCP|Azure)などいずれのデプロイメント形態でも、データ処理はストレージ層にオフロードされ、高速化されます。Exadataはトランザクションや解析処理を桁違いに加速し、ベクタ処理もストレージ側でオフロード可能なため、AIおよび分析性能をさらに向上させます。
また、Exadata上のOracle AI Databaseでは、Database In-Memoryと相補的なHybrid Columnar Compression(HCC)も利用できます。HCCはトランザクションテーブルの行形式とインメモリカラムナ形式の中間を取るもので、最大10倍(データによってはさらに高い)圧縮、行レベルロックでの容易なデータ更新、Exadata Smart Scanによる高速分析などのメリットを提供します。Oracle Hybrid Columnar Compressionの詳細は技術概要を参照してください。
メモリは比較的高価なため、ExadataはDBIMのカラムナデータをメモリとフラッシュの双方に保持します。ストレージあたり最大27.2TBのインメモリデータ容量・最大100GB/sのスキャンスループットを実現し、スケールアウトストレージによる並列度も高まります。さらにExadataソフトウェアは最もアクセスされるデータをカラムナキャッシュ形式に変換し、Exadata RDMAメモリ(XRMEM)上に配置、X11Mストレージサーバ当たり最大500GB/sのSmart Scan速度を実現します。
Exadata上のOracle AI Database(26ai)は、DBIMインメモリカラムナスキャンとExadata Smart Scan/カラムナ・キャッシュをストレージ側で組み合わせ、1件のクエリでインフラ全体の処理能力をレバレッジでき、非常に大量のデータセットに対して分析・AIワークロードでも最大処理性能を引き出します。
Database In-Memoryを活用することでETL/ELTパイプラインを排除
オンプレミスのExadata環境では、フラッシュやXRMEMストレージによるインメモリ処理を有効化するのは非常に簡単です。ExadataのデータベースサーバのメモリをDBIMに割り当て、DBIM形式で複製するテーブルやパーティションを指定することも可能ですし、自動インメモリ(Automatic In-Memory)に任せて自動的に決定させることも可能です。データインテリジェントなExadataソフトウェアが、カラムナデータをストレージサーバ上のフラッシュやXRMEMに自動でキャッシュします。
また、INMEMORY_FORCE = CELLMEMORY_LEVEL および INMEMORY_SIZE = 0 を設定することで、データベースサーバのメモリを消費せずにExadataストレージのフラッシュ/ XRMEMを活用することもできます。上記のいずれの方法もDatabase In-Memoryオプションライセンスが必要です。
Exadataクラウド環境(Exadata Cloud@Customer、OCI、マルチクラウド)では、ストレージ上での超高速インメモリ処理がデフォルトで有効です。同じくデータインテリジェントExadataソフトウェアがホットデータをフラッシュまたはXRMEMの最適なレイヤーに自動キャッシュします。Exadataデータベースサーバ側では、DBIM用にメモリを割り当てて自らテーブルやパーティションを指定するか、自動インメモリに割り当てを任せる柔軟性があります。
重要な点として、すべてのOracleクラウドサービスでは、ストレージサーバにおけるDBIM形式データのキャッシュは追加費用不要で含まれています。データベースサーバでのDatabase In-Memoryライセンス要件は導入形態によって異なりますが、“License Included”の場合はすべてのDBIM機能が利用可能、“BYOL(持ち込みライセンス)”の場合は適切なライセンスが必要です。
まとめ
AIがビジネス運用に不可欠になる中で、データの品質・鮮度・アーキテクチャの重要性はますます高まっています。従来型のデータレプリケーションやETL手法は、遅延・複雑性・リスクを招きますが、特にExadata上にデプロイしたOracle AI Databaseなら、トランザクション・分析・AIワークロードを単一プラットフォームで統合可能です。これによりアーキテクチャのオーバーヘッドは削減され、データ整合性が確保され、意思決定も加速され、高度なAIアプリケーションのための拡張性とセキュリティを備えた基盤が提供されます。運用・分析過程を統合することで、企業はビジネスデータの価値を最大限引き出し、自信をもってAIイノベーションを推進可能になります。
※すべてのパフォーマンス数値はExadata X11Mハードウェア世代に基づきます。
