Data is foundational to AI applications. While all-purpose LLMs may be trained on massive volumes of varied data from all over the internet, purpose-built applications rely on specific data sets to provide targeted and relevant results to users and other applications. The quality and freshness of the data supporting any AI application directly correlates to the value of its responses. Poor data quality leads to hallucinations or outright incorrect results. When talking about agentic AI use cases, where the AI application may take another application’s outputs as inputs for processing and then make decisions about the next step to take, data quality is even more crucial. These systems not only influence users but can make complex decisions autonomously, evaluating the context of many inputs and the current state of their own and other systems. Using accurate, accessible, and up-to-date data is crucial for the success of both the application and those who rely on it.
The most natural data set to inform such AI applications is a business’s transactional data set. Examples of this are:
- Sales and inventory data reflect business performance and inform logistics needs.
- Resource consumption metrics reveal utilization rates per customer, per geography, and overall, and inform resource planning efforts.
- Customer support ticket trends indicate customer satisfaction and identify potential product defects or incorrect marketing pages.
- Website visits and click-through rates reflect the success of marketing campaigns, confirming current messaging or suggesting a pivot.
Historically, using the same system for both transaction processing and heavy analytic, ML, and AI queries has produced poor results. Systems designed and optimized for transaction processing are just that, including normalized data formats that support processing many small transactions quickly. Analytics and AI systems require the ability to query vast amounts of data and efficiently search and filter relevant information from large data sets. This split in use cases and supporting architectures often forces system architects to denormalize data and use columnar data stores for high-volume applications. This typically requires duplication of the source transactional data in different formats and even different data service engines or platforms when the transactional system cannot serve both needs. Even capable systems often struggle to handle both transactional and analytical or AI workloads without performance degradation.
The historical solution to this problem has been to duplicate the source data out of place. Extract, Transform, and Load or “ETL” processing has been used for decades to achieve this, modifying or joining data sets along the way to better serve downstream systems. ELT processing changes this slightly, preferring to more quickly transfer the data as it exists in the source system, and then transform it on the target system. ETL and ELT are both forms of data replication: shipping data, perhaps only a subset of source operational data, to another system designed to effectively service other use cases. The process of replicating source data impacts the source system, although to a lesser degree than running additional workloads on unfiltered, unoptimized data on the same system.
However, data replication introduces its own challenges. Even if data is replicated in real time, that is each transaction on the source system is immediately sent to the target system, there is a delay and inconsistency between the source and target data. More common, historically, are batch processes that run every day, hour, or specified number of minutes, identifying changes since the last run to send downstream. Users have often accepted the resulting delay and staleness of data as a cost of doing business, for example when looking at sales data or revenue numbers, acknowledging that the data may contain inaccuracies or be incomplete for very recent time periods, such as the last 24 hours. As agentic AI applications start to make impactful decisions based on data, however, such gaps become more problematic and inhibit real-time decision making.
Another challenge with replicated environments is that they are just that: additional environments that administrators must support and that businesses must pay to run. These environments often grow very large over time because they store historical data that users rarely purge or manage with lifecycle operations. While they hold a copy of the source system data, they often grow much larger than the source system in terms of data volume and system specifications to support parallel advanced querying of that large data volume.
A third challenge with replicated environments pops up when data requirements in such systems change as the downstream system needs evolve. Data pipelines must be actively managed to ensure correct and complete data is consistently delivered to the replicated system, with replication sets changing and potentially requiring full historical reloads of specific schemas or tables. Any interruption of the normal replication process may also require running data integrity checks or purging and reloading a portion of source data such that users can be sure all changes made their way through the pipeline to the target system.
How can these challenges be addressed or even eliminated?
Oracle AI Database supports a broad range of workloads, including transactional, analytical, and, most recently, AI vector processing, in a single database engine. This allows AI agents to use up-to-date business data at the source. Still, enabling mixed workloads with a single engine isn’t enough to achieve the extreme performance required for advanced AI use cases. To truly eliminate performance and architectural challenges, you need a holistic approach.
Processing mixed workloads in one database is complex, but Oracle AI Database handles it exceptionally well. Competing platforms often make customers choose between transactional, analytical, or vector processing, which forces duplicated or stale data, brittle ETL/ELT pipelines, extra data stores, and inconsistent operational and security models.
Oracle AI Database centralizes data for any workload, using a single copy with unified operations and security. This immediately eliminates two of the three challenges outlined above. First, it removes the need to create and maintain additional environments as all of the required data is in a single database. Second, enabling the single database for its original use cases and workloads, and adding agentic AI workloads eliminates the need to create data pipelines which must be maintained as the source application changes.
Other databases and platforms often rely on a fragile combination of extensions, plugins, and various open-source libraries to deliver features like columnar storage and in-memory analytics. This approach introduces risks and data inconsistencies, complicates updates as data changes, and typically achieves results that are less performant than Oracle AI Database’s unified, converged architecture.
For example, some non-Oracle solutions combine an open-source relational database for transactional workloads with a separate SQL engine that queries a different data store for in-memory analytics, while trying to keep them in sub-second synchronization. These elements are often stitched together by extensions and numerous underlying components and libraries, further increasing complexity and potential points of failure. And this is only part of the picture!
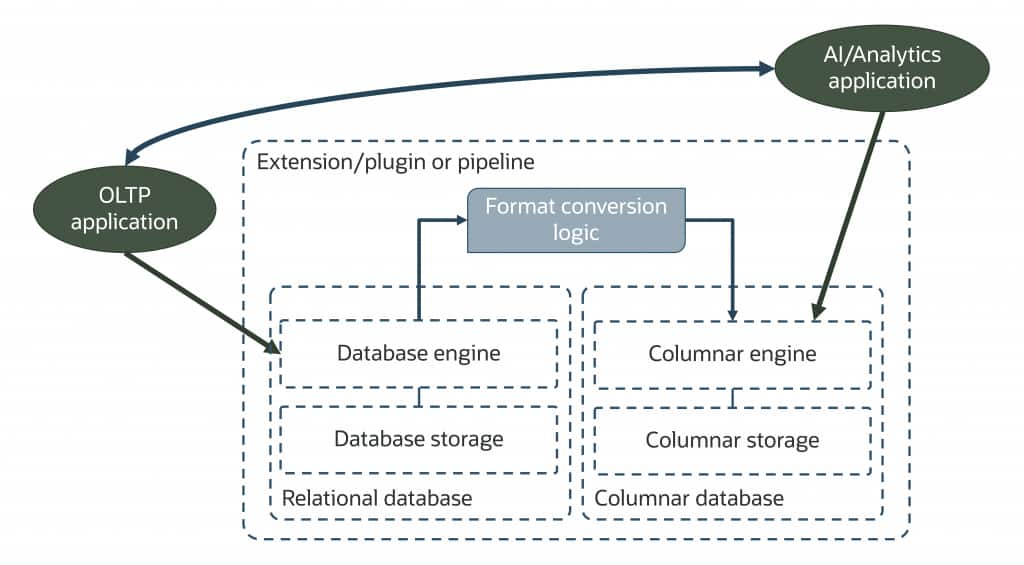
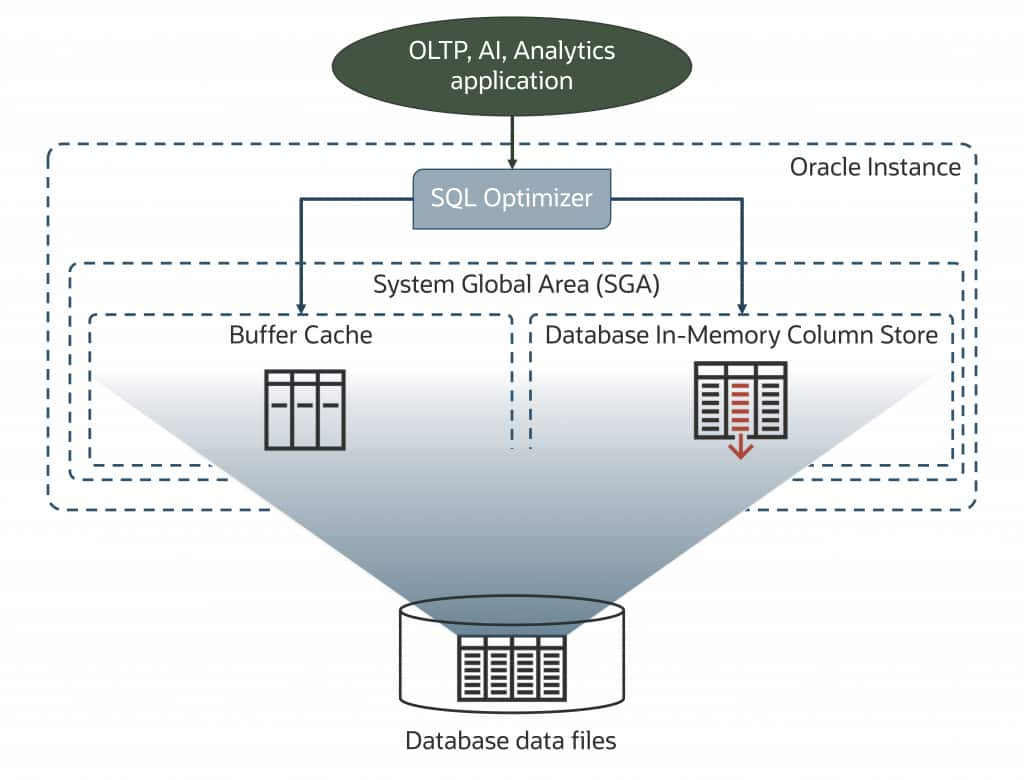
Oracle takes a fundamentally different approach, offering robust, integrated features for high performance, scalability, security, and enterprise-class data management. To provide pipeline-free data access for Agentic AI workloads, Oracle AI Database can present data in multiple formats simultaneously to accelerate queries. The row-major, memory-resident buffer cache addresses many transactional workloads, while a memory-optimized columnar format accelerates analytic queries.
Because these dual data representations are built directly into Oracle AI Database, there is no need for extensions or plugins to handle data copy, transformation, or synchronization between separate data stores. This eliminates added latency and ensures up-to-date, fresh data for both transactional and analytic workloads.
Let’s focus on the memory-optimized columnar representation, also known as Database In-Memory (DBIM). DBIM automatically and transparently presents data in a pure in-memory columnar format, implementing advanced algorithms for efficient in-memory scans, joins, and aggregation. It leverages single-instruction, multiple data (SIMD) capabilities on modern CPUs to further accelerate queries.
Oracle AI Database can transparently use both row-based and columnar formats simultaneously within a single query. Because DBIM is a native feature, not an extension or plugin, updates to both the row-major and columnar representations happen at the same time and are committed or rolled back together. This ensures there is never stale data, regardless of the access method.
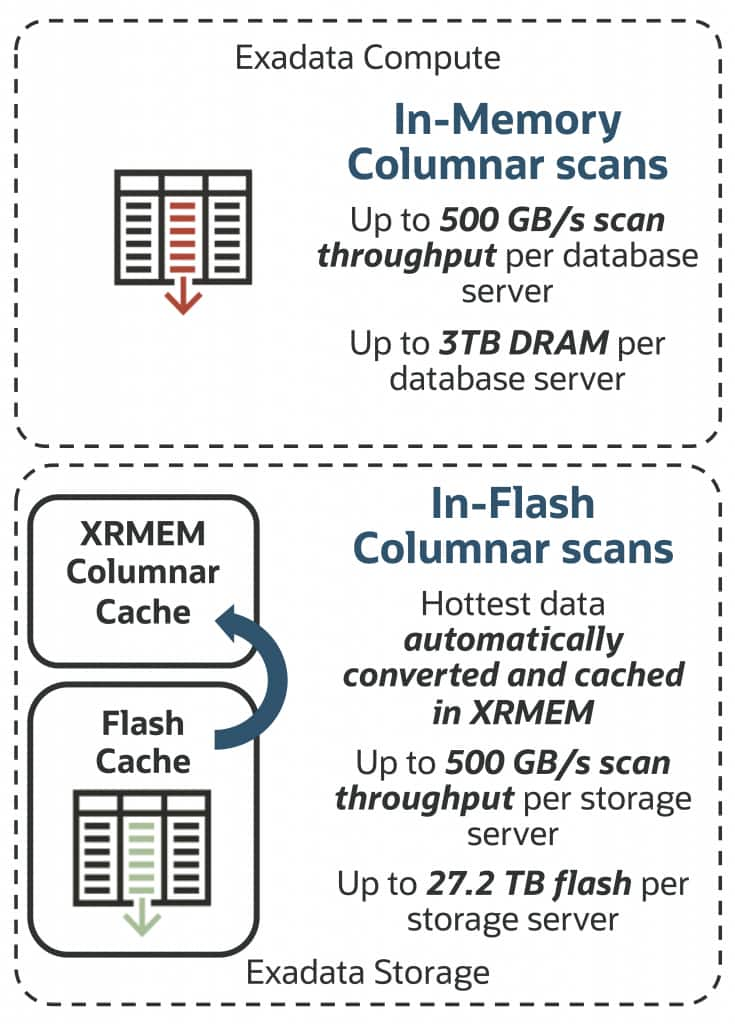
When running on Oracle Exadata, in any deployment option (on-premises, Cloud@Customer, in Oracle Cloud Infrastructure, or multicloud with Database@{AWS|GCP|Azure}), data processing is offloaded from database servers to intelligent storage servers to further optimize and accelerate queries. By processing data directly at the storage layer, Exadata accelerates analytics and transactions by orders of magnitude. Additionally, Exadata offloads vector processing to Exadata storage, further enhancing AI and analytics performance on transactional data.
Oracle AI Database on Exadata includes Hybrid Columnar Compression (HCC) for storing and compressing data and is complementary to Database In-Memory. HCC charts a middle path between the row-major format of transactional tables and a pure in-memory columnar format. It delivers the benefits of columnar storage and deep compression—up to 10x compression and often higher depending on the data, easy data updates with row-level locking, and fast analytics with Exadata Smart Scan. You can learn more about Oracle Hybrid Columnar Compression by reading this technology brief.
Because memory is relatively expensive, Exadata uses both memory and flash to store the in-memory columnar data managed by the DBIM capabilities. Flash in Exadata storage expands the total capacity for in-memory data up to 27.2 TB with a scan throughput of up to 100 GB/s* per storage server and increases parallelism through its scale-out storage architecture. Additionally, the data-intelligent Exadata software converts the hottest data into columnar cache format and places it in Exadata RDMA Memory (XRMEM), delivering Exadata Smart Scan speeds up to 500 GB/s* per X11M storage server.
Oracle AI Database 26ai on Exadata also transparently enables a single query to utilize the combined power of DBIM in-memory columnar scans on the database servers along with Exadata Smart Scan and columnar cache on the storage servers, enabling analytic and AI workloads to leverage the whole processing potential of the infrastructure on extremely large data sets.
Use Database In-Memory to eliminate ETL/ELT pipelines
For on-premises Exadata deployments, enabling in-memory processing with flash and XRMEM storage is straightforward. You can allocate memory on Exadata database servers and specify tables or partitions to be replicated in the DBIM format or let Automatic In-Memory make these decisions for you. The data-intelligent Exadata software will automatically cache columnar data in flash and XRMEM on the storage servers.
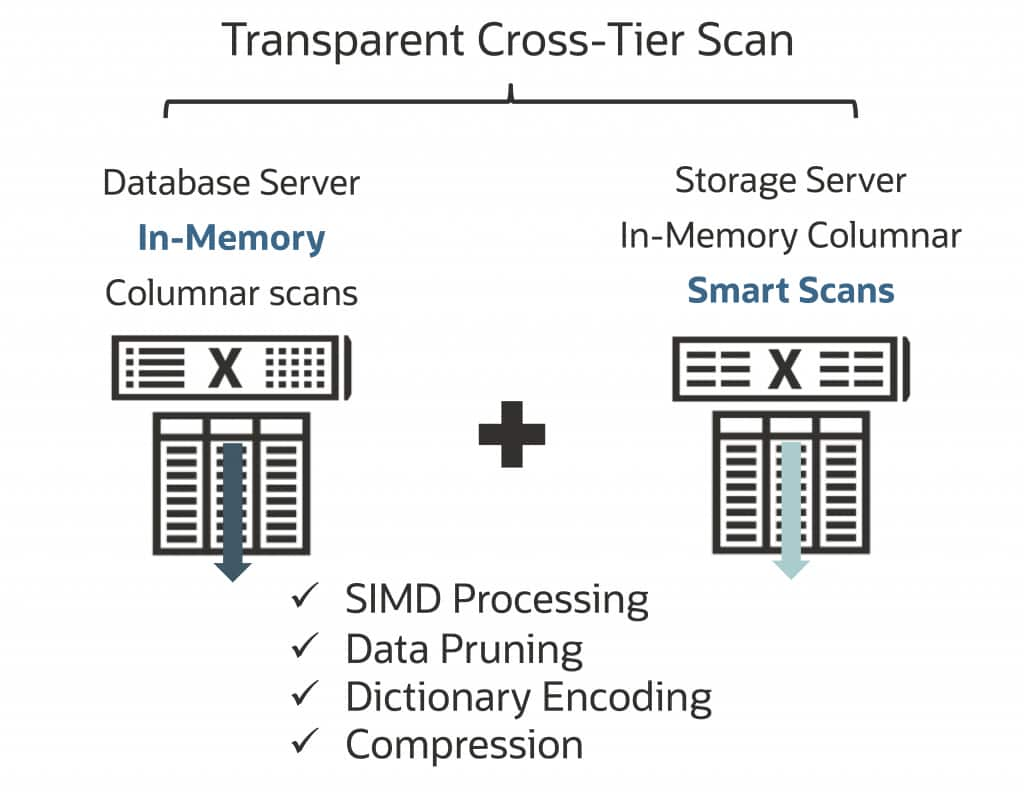
Alternatively, you can take advantage of flash and XRMEM on Exadata storage without consuming memory on the database servers by setting INMEMORY_FORCE = CELLMEMORY_LEVEL and INMEMORY_SIZE = 0. Both options outlined above require a Database In-Memory Option license.
For Exadata cloud deployments (Exadata Cloud@Customer, OCI, and multicloud), ultra-fast in-memory processing on storage is enabled by default. The same data-intelligent Exadata software automatically caches hot data to the optimal tier, whether flash or XRMEM. On Exadata database servers, you have flexibility: dedicate memory to DBIM and specify tables or partitions yourself or allow Automatic In-Memory to do the work for you for optimal allocation.
Importantly, in all Oracle cloud offerings, caching DBIM-formatted data on storage servers is included at no extra cost. Licensing requirements for Database In-Memory on database servers vary: with “License Included,” all the DBIM capabilities are available; with BYOL (“Bring Your Own License”), you will need an appropriate license.
Closing remarks
As AI becomes increasingly integral to business operations, the importance of data quality, freshness, and architecture cannot be overstated. Traditional approaches to data replication and ETL introduce latency, complexity, and risk, but Oracle AI Database, especially when deployed on Exadata, enables organizations to unify transactional, analytical, and AI workloads in a single platform. This reduces architectural overhead, ensures data consistency, accelerates decision-making, and provides a scalable, secure foundation for advanced AI applications. By consolidating operational and analytical processes, organizations can realize the full value of their business data and drive AI-driven innovation with confidence.

