※ 本記事は、Seshadri Dehalisan, Akshai Parthasarathy, Ruzhu Chenによる”OCI delivers stellar generative AI performance in MLPerf Inference v4.0 benchmarks“を翻訳したものです。
2024年5月22日
MLPerf™ Inferenceは、様々なデプロイメント・シナリオでAI/MLモデルを実行しているシステムのパフォーマンスを測定するために、MLCommonsによって開発された業界ベンチマーク・スイートです。OCIは、8つのNVIDIA H100 Tensor Core GPUを搭載し、NVIDIA TensorRT-LLMを使用しているOCIの新しいBM.GPU.H100.8シェイプにおいて、ビジョン(分類と検出、医療画像処理)、自然言語処理(NLP)、推奨事項、音声認識、大言語モデル(LLM)、およびテキストから画像への推論において、すべてのベンチマーク・ケースで優れた結果を達成しました。ハイライトは以下の通り:
- OCIのBM.GPU.H100.8ベア・メタル・シェイプは、RESNET50、Retinanet、BERT、DLRMv2、3D-Unet、RNN-T、GPT-J、Llama2-70B、およびStable Diffusion XLベンチマークにおいて、競合他社よりも優れています。1
- 世代世代を超えて、OCIのBM.GPU.H100.8は、8つのNVIDIA A100 Tensor Core GPUを搭載したBM.GPU.A100.8(GPT-Jベンチマーク)と比較して12.6倍、4つのNVIDIA A10 Tensor Core GPUを搭載したBM.GPU.A10.4(RNN-Tベンチマーク)と比較して14.7倍、パフォーマンスが向上しました。1, 2
- NVIDIA H100 GPUベースのインスタンスの場合、OCIは、最も近いクラウド競合他社よりも、DLRMv2ベンチマークで最大22%向上しました。1
OCI BM.GPU.H100.8シェイプ・ベンチマーク・パフォーマンス
次の表に、OCIのBM.GPU.H100.8シェイプのパフォーマンス数値を示します。提出者のパフォーマンスの完全なリストは、MLPerfベンチマーク結果1を参照してください。
| 参照アプリ |
ベンチマーク |
シナリオ |
|
| Server (queries/s |
Offline (samples/s) |
||
| Vision (image Classification) |
ResNet50 99 |
584,147 |
699,409 |
| Vision (Object Detection) |
Retinanet 99 |
12,876 |
13,997 |
| Vision (Medical Imaging) |
3D-Unet 99 |
– |
52 |
| 3D-Unet 99.9 |
– |
52 |
|
| Speech to Text |
RNN-T 99 |
143,986 |
139,846 |
| Recommendation |
DLRMv2 99 |
500,098 |
557,592 |
| DLRMv2 99.9 |
315,013 |
347177 |
|
| NLP |
BERT 99 |
55,983 |
69,821 |
| BERT 99.9 |
49,587 |
61,818 |
|
| LLM |
GPT-J 99 |
230 |
237 |
| GPT-J 99.9 |
230 |
236 |
|
| LLM |
Llama2-70B 99 |
70 |
21,299 |
| Llama2-70B 99.9 |
70 |
21,032 |
|
| Text to Image Gen |
Stable Diffusion XL 99 |
13 |
13 |
出典: MLPerf®v4.0 Inference Closed2024年4月14日、エントリ4.0-0073のhttps://mlcommons.org/benchmarks/inference-datacenter/ から取得されます。
AI推論のインスタンス・タイプ間のパフォーマンス
BM.GPU.H100.8 (8 x NVIDIA H100 GPU)、BM.GPU.A100.8 (8 x NVIDIA A100 GPU)およびBM.GPU.A10.4 (4 x NVIDIA A10 GPU)のMLPerf 4.0およびMLPerf 3.1で公開された結果は、次のとおりです。1,2
|
|
BM.GPU.H100.8 * |
BM.GPU.H100.8 vs. BM.GPU.A100.8* |
BM.GPU.H100 vs. BM.GPU.A10* |
|||
| ベンチマーク |
Server (Queries/s) |
Offline (Samples/s) |
Server (Queries/s) |
Offline (Samples/s) |
Server (Queries/s) |
Offline (Samples/s) |
| RESNET |
0% |
-1% |
101% |
115% |
N/A |
N/A |
| RetinaNet |
0% |
0% |
98% |
150% 1.5x |
1406% 14.1x |
1368% 13.7x |
| 3D U-Net 99 |
N/A |
0% |
N/A |
70% |
N/A |
900% |
| 3D U-Net 99.9 |
N/A |
0% |
N/A |
70% |
N/A |
N/A |
| RNN-T |
N/A |
N/A |
38% |
30% |
1465% 14.7x |
723% 7.2x |
| BERT 99 |
0% |
-1% |
100% |
175% 1.8x |
N/A |
N/A |
| BERT 99.9 |
0% |
-1% |
287% 2.9x |
325% 3.3x |
N/A |
N/A |
| DLRM v2 99 |
67% |
64% |
525% 5.3x |
303% 3.0x |
N/A |
N/A |
| DLRM v2 99.9 |
5% |
2% |
N/A |
N/A |
N/A |
N/A |
| GPT-J 99 |
187% |
122% |
1258% 12.6x |
774% 7.7x |
N/A |
N/A |
| GPT-J 99.90 |
N/A |
N/A |
1248% 12.5x |
832% 8.3x |
N/A |
N/A |
| Llama 2-70B 99 |
N/A |
N/A |
N/A |
N/A |
N/A |
N/A |
| Llama 2-70B 99.90 |
N/A |
N/A |
N/A |
N/A |
N/A |
N/A |
| SDXL |
N/A |
N/A |
N/A |
N/A |
N/A |
N/A |
* 3つのシナリオで、MLPerf v4.0とMLPerf v3.1で得られた結果に対して比較が行われました。「vs. BM.GPU.A100.8」および「vs. BM.GPU.A10」というタイトルの比較では、BM.GPU.A100.8およびBM.GPU.A10インスタンス・ファミリにMLPerf v3.1ベンチマーク結果が使用されました。1,2
上の表から、次のことがわかります:
- すべてのテストにおけるBM.GPU.H100.8のMLPerf v4.0とMLPerf v3.1のパフォーマンスは、インラインまたはそれ以上です。特に、DLRM v2 99%で最大67%、GPT-J 99%で最大187%の改善があります。OCIのお客様は、ニューラル・ネットワーク・ベースのパーソナライズとレコメンデーション・モデル、およびLLMの推論パフォーマンスを向上させることができます。
- BM.GPU.H100.8 とBM.GPU.A100.8では、前世代のA100 GPUベースのインスタンスと比較して、現在の世代のH100 GPUベースのインスタンスのパフォーマンスが大幅に向上しています。どちらのインスタンスも8つのNVIDIA GPUを搭載しています。GPT-J(LLM)のパフォーマンスは、BM.GPU.A100.8(GPT-J 99% Serverでは12.6倍、GPT-J 99% Offlineでは7.7倍)よりもBM.GPU.H100.8で大幅に向上しました。
- BM.GPU.H100.8 とBM.GPU.A10.4では、予想どおり、BM.GPU.A10.4に対して、ボード全体でorder-of-magnitudeが大幅に向上しています。BM.GPU.A10.4ベア・メタル・インスタンスは、NVIDIA A10 Tensor Core GPUの低消費電力とコストに基づいています。また、BM.GPU.A10.4には、BM.GPU.H100.8の8つのNVIDIA H100 GPUと比較して、4つのNVIDIA A10 GPUがあります。必要な価格性能比に応じて、どちらのオプションを使用するかを選択できます。
生成AIなどの高速化ワークロードの高パフォーマンス
生成AIの重要性が高まる中、新しく期待される生成AIベンチマークであるLlama2-70BとStable Diffusion XLの2つが、ベンチマーク・スイート・バージョン4.0に追加されました。Llama2-70BおよびStable Diffusion XLは、NVIDIA H100 GPUを搭載したシステムで非常に適切に動作します。次に示すように、GPT-JベンチマークBM.GPU.H100.8は、BM.GPU.A100.8と比較して13倍以上のパフォーマンスを示しています。 1,2
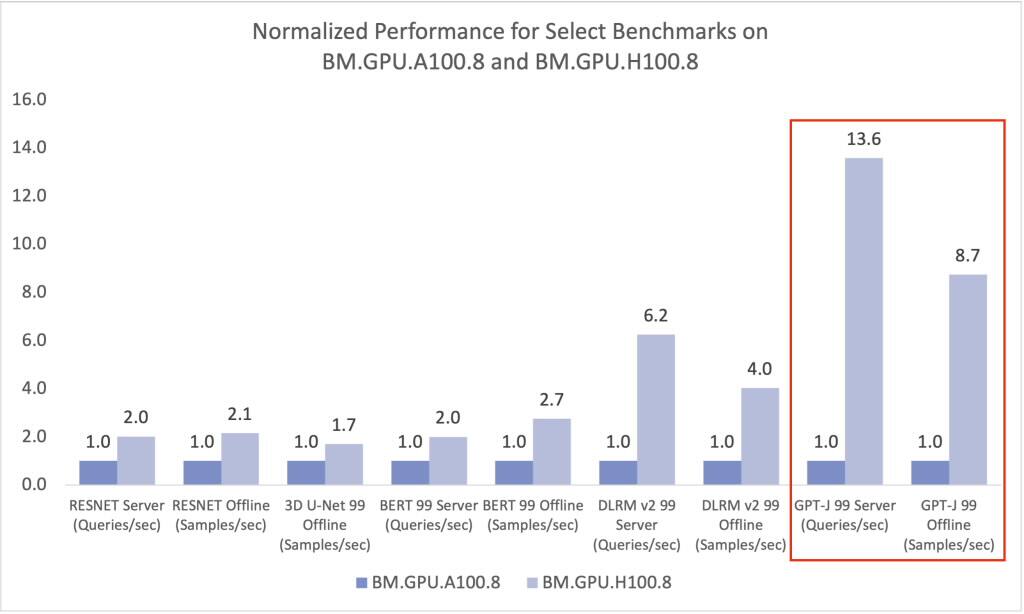
RNN-Tのベンチマーク時に、BM.GPU.H100.8はBM.GPU.A10.4のパフォーマンスを15倍、BM.GPU.A100.8インスタンスはBM.GPU.A10.4のパフォーマンスを11倍と示しています。その他の比較を次に示します。 1,2
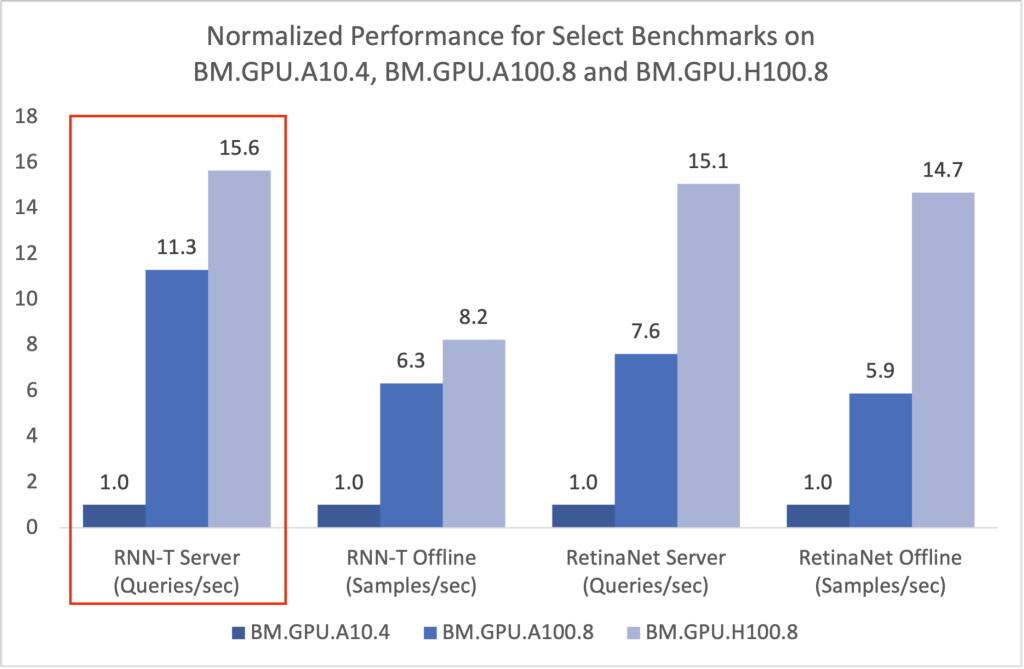
テイクアウェイ
OCIは、トレーニングや推論など、AIワークロード向けに最適化されたGPUオプションの包括的なポートフォリオを提供します。これらのGPUは、ソブリン、政府、専用リージョンに加えて、48のパブリック・クラウド・リージョンでグローバルに利用できます。オラクルのAIポートフォリオには、最先端の生成AIイノベーション、事前構築済みのAIサービス、ベクター・データベースなども含まれています。
MLPerf 4.0の推論結果は、AIインフラストラクチャにおけるOCIの競争力と、LLMやレコメンデーション・システムなど、幅広いワークロードを処理する能力を示しています。当社の製品の詳細については、当社のGPUおよびAIインフラストラクチャのページを参照してください。
確認
著者らは、OCIエンジニアリング担当シニア・ディレクターのSanjay Basu博士と、OCIエンジニアリングのプリンシパル・プログラム・マネージャーであるRamesh Subramaniam氏に、これらの成果の公開に関する支援を感謝したいと考えています。
脚注:
[1] MLPerf® v4.0 Inference Closed. 2024年3月29日、エントリ4.0-0073、https://mlcommons.org/benchmarks/inference-datacenter/ から取得。MLCommonsアソシエーションによって検証された結果。MLPerfの名前およびロゴは、米国およびその他の国におけるMLCommons協会の登録商標および未登録商標です。All rights reserved. 無断使用は固く禁じられています。詳細は、www.mlcommons.orgを参照してください。
[2] MLPerf® v3.1 Inference Closed. 2024年3月29日、エントリ3.1-0119、3.1-0120、3.1-0121、https://mlcommons.org/benchmarks/inference-datacenter/ から取得。MLCommonsアソシエーションによって検証された結果。MLPerfの名前およびロゴは、米国およびその他の国におけるMLCommons協会の登録商標および未登録商標です。All rights reserved. 無断使用は固く禁じられています。詳細は、www.mlcommons.orgを参照してください。
