※ 本記事は、JR Gauthier, Anand Chandakによる”Access Jupyter notebooks within OCI Data Flow service“を翻訳したものです。
2023年1月5日
Oracle Cloud Infrastructure(OCI)Data Flowは、完全に管理されたApache Sparkサービスであり、インフラストラクチャをデプロイまたは管理することなく、非常に大規模なデータセットに対して処理タスクを実行します。この構成により、開発者はインフラストラクチャ管理ではなくアプリケーション開発に集中できるため、迅速なアプリケーション配信が可能になります。
完全管理型のJupyterベースのnotebookであるOCI Data Flowノートブックの一般提供を発表します。Data Flowノートブックの助けを借りて、データ・サイエンティストとデータ・エンジニアは、迅速な環境作成、対話型の出力、任意の順序で実行できるコード・スニペットを通じて、迅速かつ反復的にインサイトを共有できます。Data Flowノートブックは、ノートブック・セッション環境を離れることなく、TBからPBサイズのデータセットに対してワークロードを大規模に、TBからPBサイズのデータセットに対して対話的に実行するためのWebベースのインタフェースを提供します。本質的に、ノートブック・セッション環境は(Py)Sparkワークロードの統合開発環境(IDE)になります。
Data Flowノートブックの利点
-
統合開発環境: 単一の統合環境を取得し、リモート・クラスタにログインせずに、OCI Data Flowノートブックを使用してデータを対話的に探索、処理およびビジュアル化します。
-
Webコンソールベースの完全管理型のJupyter notebooks: Data Flowノートブックを使用すると、完全管理型のOCI Data Science搭載のJupyter notebookセッションを使用して、Python、ScalaおよびPySparkでビッグ・データ分析およびデータ・サイエンス・アプリケーションを開発できます。OCI Data Flow搭載のApache Sparkと、OCI Data Flowクラスタで実行されているJupyterカーネルおよびアプリケーションを使用して、分散処理を利用できます。
-
カスタムPythonライブラリおよびパッケージ: Data Scienceノートブック・セッションから、Spark NLPなどのカスタムPythonライブラリおよびパッケージをインストールし、公開されているconda環境を介してリモートOCIデータ・フロー・クラスタに直接実行できます。
-
コード・リポジトリを使用した簡単なコラボレーション: Data Scienceノートブック・セッション環境から、GitHubやBitbucketなどのコード・リポジトリに接続して、ピアとコードおよびベスト・プラクティスをコラボレーションおよび共有できます。
-
自動クラスタ・スケーリング: データ処理のリソース・プランニングは複雑なタスクです。OCI Data Flowノートブックを使用すると、クラスタを動的にスケーリングしてパフォーマンスとコストを最適化できます。
OCI Data Flowノートブックの設定方法
現在、すべての商用OCIリージョンでData Flowノートブックを利用できます。設定プロセスは簡単ですが、データ・レイク・アーキテクチャとデータの格納場所によって異なります。このプロセスには、次の前提条件が必要です。:
-
Data Flow実行の動的グループを定義し、データが格納されているバケットへのアクセス権をその動的グループに付与します。この設定では、リソース・プリンシパルが認可を処理します。データ・フローでは、バケットに対するデータの読取りおよび書込みが実行されます。
-
ノートブック・セッションの動的グループを定義し、それらのノートブック・セッションにData Flow実行を作成する権限を付与します。この場合、Data Flow実行は存続期間の長いデータ・フロー・クラスタです。詳細は、ドキュメントを参照してください。
-
Hiveメタストアへのアクセスやカスタマイズされたconda環境の使用など、より高度な設定が必要な場合は、Data Flowノートブック・サービス・ドキュメントのこの高度なポリシー設定を参照してください。
ポリシーが設定されると、次のステップはカスタムのSparkMagicコマンドを使用してconda環境をインストールすることです。
-
Create or open a notebook session in theData Scienceサービスでノートブック・セッションを作成またはオープンします。ノートブック・セッション環境には、odsc conda CLIツールおよびconda環境エクスプローラが含まれます。
-
次のコマンドを使用して、ノートブック・セッション内にconda環境をインストールします:
odsc conda install -s pyspark32_p38_cpu_v1 -
conda環境をアクティブ化します。
source activate /home/datascience/conda/pyspark32_p38_cpu_v1
これで、Data Flowノートブックを使用するように設定されました。
Data Flowマジック・コマンドを使用したSparkクラスタのコントロール
Data Flowノートブックは、リモートOCI Data Flow Sparkクラスタと対話するための変更済のコマンド・セットとともにカスタマイズされたSparkMagicが付属しています。Jupyter notebookでSparkコマンドを実行すると、SparkMagicはJupyterLabコード・セル内の%%sparkマジック・ディレクティブを使用してリモートOCI Data Flowクラスタをコールします。
まず、Oracle Accelerated Data Science(ADS)ソフトウェア開発者キット(SDK)で認証タイプを設定します。Data Flowノートブックは、APIキーベースとリソース・プリンシパルベースの両方の認証をサポートしています。
import ads
ads.set_auth("resource_principal")リソース・プリンシパルは、Identity and Access Management(IAM)の機能であり、リソースは、サービス・リソースに対してアクションを実行できる認可されたプリンシパル・アクターになることができます。各リソースには独自のアイデンティティがあり、追加された証明書を使用して認証されます。これらの証明書は自動的に作成され、リソースに割り当てられてローテーションされるため、ノートブック・セッションに資格証明を格納する必要がなくなります。リソース・プリンシパルは、OCI構成およびAPIキー・アプローチと比較して、リソースに対してよりセキュアな認証方法を提供します。
次のステップでは、SparkMagicエクステンションをロードします。:
%load_ext dataflow.magicsSparkMagicエクステンションが正しくロードされたことを確認するには、%helpコマンドを入力します。このコマンドは、Data FlowノートブックでサポートされているすべてのSparkMagicコマンドをリストします:

セッション: 新しいタイプのData Flowアプリケーション
Data Flowノートブックでは、対話型セッションのクラスタを設定するために作成された新しいData Flowアプリケーション・タイプSESSIONを導入しています。SESSIONタイプのアプリケーションは、Data FlowノートブックでREST APIを介して操作できる長期間の対話型Data Flowクラスタです。
まず、ドライバと1つのエグゼキュータ・シェイプを使用してData Flowセッションを作成できます。説明のために、ドライバとエグゼキュータの両方に仮想マシン(VM)のStandard.E3.Flexシェイプを使用します。create_sessionコマンドを使用して、次のイメージに示すように対話型セッションを起動します。:
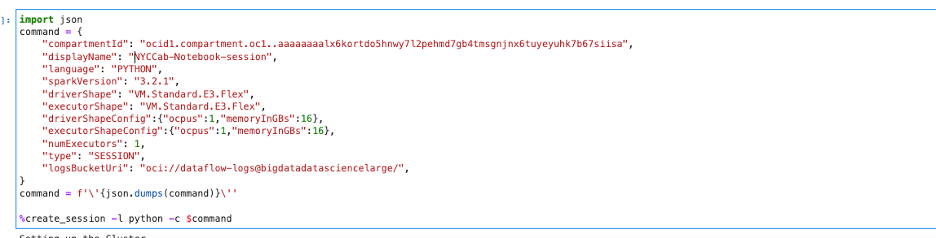
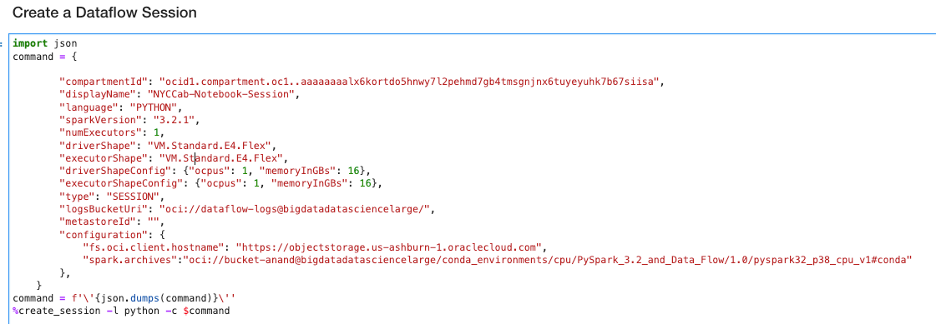
このコマンドは、リモートSparkクラスタに対話型セッションを作成します。このコマンドは、セッションIDとData Flow実行ページへのリンクを返します。また、Sparkアプリケーションを構築するためのエントリ・ポイントであるSparkSession(spark)およびSparkContext(sc)も返されます:

簡単な例: NYCタクシー旅行期間データセットのデータ分析
人気のNYC TLCトリップ・レコード・データセット(NYCタクシー・データセットとも呼ばれる)を使用しています。タクシー・トリップ・レコードには、ピックアップおよびドロップオフの日付、時刻、場所、トリップ距離、項目別運賃、レート・タイプ、支払タイプおよび運転手が報告する乗客数を取得するフィールドが含まれます。データセットをOCI Data Flowにロードし、いくつかの基本的なデータ分析を実行します。ノートブックはGitHubにあります。
まず、%configure_sessionコマンドを使用してセッションを再構成し、エグゼキュータを追加します。データセットが10億レコードを超えています。
%configure_session -f -i '{"driverShape": "VM.Standard2.8", "executorShape": "VM.Standard2.8", "numExecutors":4}'
このコマンドはセッションを変更して、エグゼキュータの数を4に増やし、セッションを再構成します。
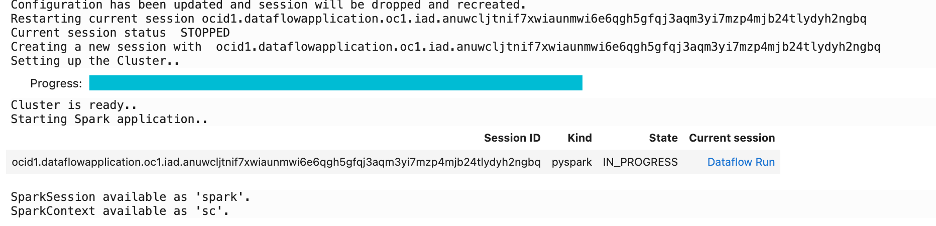
次に、データセットをSparkクラスタにロードします。Parquetバンドル全体をオブジェクト・ストレージ・バンドルにアップロードし、クラスタをロードしました:
%%spark
nyc_tlc201 = spark.read.parquet("oci://hosted-ds-datasets@bigdatasciencelarge/nycP_tlc/201[1,2,3,4,5,6,7,8]/**/data.parquet", header=False,inferSchema=True)
nyc_tlc201.show()
nyc_tlc201.create0rReplaceTempView("nyc_tlc201")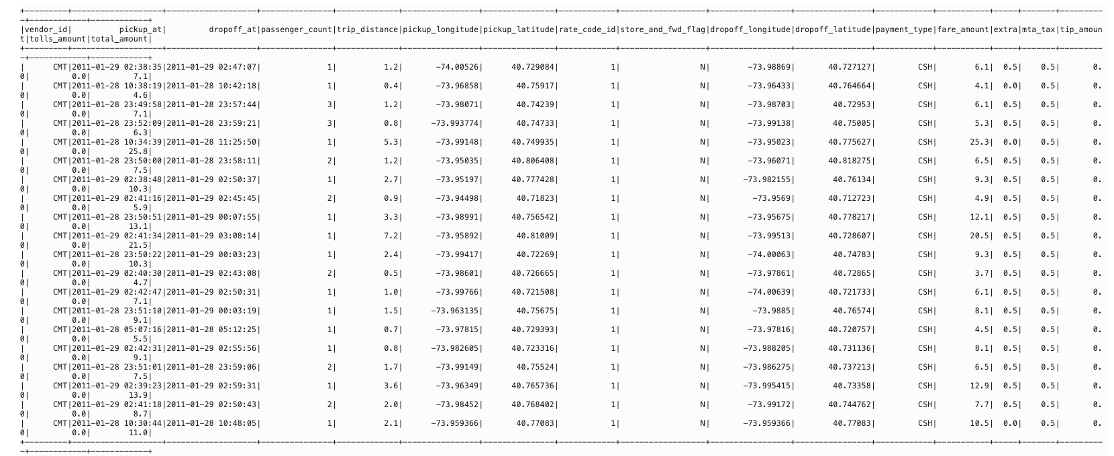
確認するレコードの数を出力します。:

次に、料金、ヒントなどの統計を実行する単純なSpark SQLを実行します:
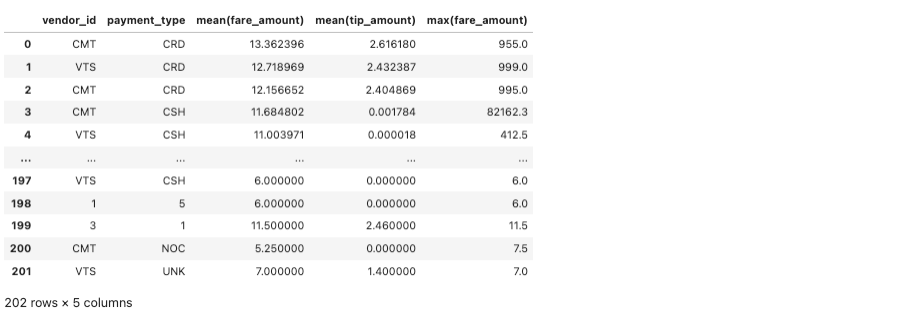
%%spark -c sql -o fare_summary
SELECT vendor_id, payment_type, MEAN(fare_amount), MEAN(tip_amount),MAX(fare_amount) \
FROM nyc-tlc201 \
GROUP BY vendor_id, payment+type, passenger_count;問合せの結果をfare_summaryというローカル・パンダ・データフレーム・オブジェクトにエクスポートします。この問合せを使用すると、ローカル・ノートブック・セッションVMでデータ・フレームを操作できます。問合せによって次の結果が得られます。:
SparkMagicにはautovizwidgetが付属しており、Pandasのデータ・フレームを可視化できます。display_dataframe()関数はパラメータとしてPandasデータフレームを取り、ノートブックに対話型グラフィック・ユーザー・インタフェース(GUI)を生成します。表、円グラフ、散布図、面グラフ、棒グラフなど、様々な形式のデータを視覚化できるタブがあります。
次のセルは、作成されたdf_peopleデータフレームを使用してdisplay_dataframe()をコールします:
from autovizwidget.widget.utils import display_dataframe
display_dataframe(fare_summary)
まとめ
OCI Data Flowは、Apache Sparkを実行するための完全に管理された非常にスケーラブルなサービスです。この投稿では、Jupyterに基づいたData Flowノートブックの機能のいくつかを強調しました。クラスタの作成、クラスタの再構成、対話形式でのApache Sparkコマンドの実行、設定の負担なしにデータのビジュアル化をいかに簡単に行うかを確認しました。これらの機能はすべて、OCI Data Scienceノートブック・セッション環境で使用できます。
Oracle Cloud無料トライアルをお試しください。US$300分の無料クレジットで30日間トライアルすると、OCI Data Scienceサービスにアクセスできます。
Oracle Cloud Infrastructure Data Scienceサービスについて詳しく知る準備はできていますか?
-
これらの設定手順でOCIテナンシを構成し、OCI Data Scienceの使用を開始します。
-
新しいGitHubリポジトリに星をつけてクローンを作成します。ノートブックのチュートリアルとコード・サンプルが含まれています。
-
サービス・ドキュメントを参照してください。
-
YouTubeプレイリストのチュートリアルをご覧ください。
-
Twitterフィードをサブスクライブしてください。
-
LiveLabsのいずれかを試してください。「data science」を検索してください。
