Oracle Cloud Infrastructure (OCI) Data Flow is a fully managed Apache Spark service that performs processing tasks on extremely large datasets without infrastructure to deploy or manage. This configuration enables rapid application delivery because developers can focus on app development, not infrastructure management.
We’re pleased to announce the general availability of OCI Data Flow notebooks, a fully managed Jupyter-based notebook. With the help of Data Flow notebooks, a data scientist and data engineer can build rapidly and iteratively and share insights through quick environment creation, interactive output, and code snippets that can run in any order. Data Flow notebooks provide a web-based interface to interactively run workloads at scale, on TB- to PB-size datasets, against a remote OCI Data Flow-powered Spark cluster without leaving their notebook session environment. In essence, the notebook session environment becomes an integrated development environment (IDE) for (Py)Spark workloads.
Benefits of Data Flow notebooks
-
Unified development environment: Get a single unified environment to interactively explore, process, and visualize data using OCI Data Flow notebooks, build, and debug applications without having to log into the remote cluster.
-
Web console-based fully managed Jupyter notebooks: With Data Flow notebooks, you can develop big data analytics and data science applications in Python, Scala, and PySpark with fully managed OCI Data Science powered Jupyter notebook sessions. You can take advantage of distributed processing using OCI Data Flow-powered Apache Spark with Jupyter kernels and applications running on OCI Data Flow clusters.
-
Custom Python libraries and packages: From the Data Science notebook session, you can install custom Python libraries and packages, such as Spark NLP, and run them directly into remote OCI Data Flow cluster through published conda environments.
-
Easy collaboration using code repositories: From the Data Science notebook session environment, you can connect to code repositories, such as GitHub and Bitbucket, to collaborate and share code and best practices with peers.
-
Automatic cluster scaling: Resource planning for data processing is a complex task. Using OCI Data Flow notebooks, you can dynamically scale the cluster to optimize for performance and cost.
How to set up OCI Data Flow notebooks
Data Flow notebooks are currently available in all commercial OCI regions. The setup process is straightforward but can vary depending on your data lake architecture and where the data is stored. The process requires the following prerequisites:
-
Define a dynamic group of Data Flow runs and grant that dynamic group access to buckets where your data are stored. In this setup, resource principals handle the authorization. Your Data Flow runs read and write data to the bucket.
-
Define a dynamic group of notebook sessions and grant those notebook sessions the permission to create Data Flow runs. In this case, Data Flow runs are the long-lived Data Flow clusters. For more details, refer to the documentation.
-
If your setup requires more advanced setup, such as access to Hive Metastore or using customized conda environment, refer to this advanced policy setup of the Data Flow notebooks service documentation.
When the policies are set up, the next step is to install the conda environment with the custom SparkMagic commands.
-
Create or open a notebook session in the Data Science service. The notebook session environment includes the odsc conda CLI tool and the conda environment explorer.
-
Install the conda environment within your notebook session with the following command:
odsc conda install -s pyspark32_p38_cpu_v1 -
Activate the conda environment:
source activate /home/datascience/conda/pyspark32_p38_cpu_v1
Now, you’re set to use the Data Flow Notebooks.
Controlling the Spark cluster with Data Flow magic commands
The Data Flow notebooks ship with customized SparkMagic with a modified set of commands to interact with the remote OCI Data Flow Spark cluster. When you run a Spark command in a Jupyter notebook, in turn SparkMagic calls the remote OCI Data Flow cluster using the %%spark magic directive within a JupyterLab code cell.
Begin by setting the authenticating type in the Oracle Accelerated Data Science (ADS) software developer kit (SDK). Data Flow notebooks support both API key-based and resource principal-based authentication.
import ads
ads.set_auth("resource_principal")A resource principal is a feature of Identity and Access Management (IAM) that enables resources to be authorized principal actors that can perform actions on service resources. Each resource has its own identity, and it authenticates using the certificates that are added to it. These certificates are automatically created, assigned to resources, and rotated, avoiding the need for you to store credentials in your Notebook session. Resource principals provides a more secure way to authenticate to resources compared to the OCI configuration and API key approach.
The next step is to load the SparkMagic extension:
%load_ext dataflow.magicsTo verify that the SparkMagic extension was loaded correctly, type the %help command. The command lists all the supported SparkMagic command for Data Flow notebooks:

Session: A new type of Data Flow application
With Data Flow notebooks, we’re introducing a new Data Flow application type, “SESSION,” which is created to set up clusters for an interactive session. The application of SESSION type is a long-lived interactive Data Flow cluster that you can interact with through REST APIs in Data Flow notebooks.
We can start by creating a Data Flow session with a driver and one executor shape. For illustration purposes, we use a virtual machine (VM) Standard.E3.Flex shape for both driver and executor. Using the create_session command, we launch the interactive session as shown in the following image:
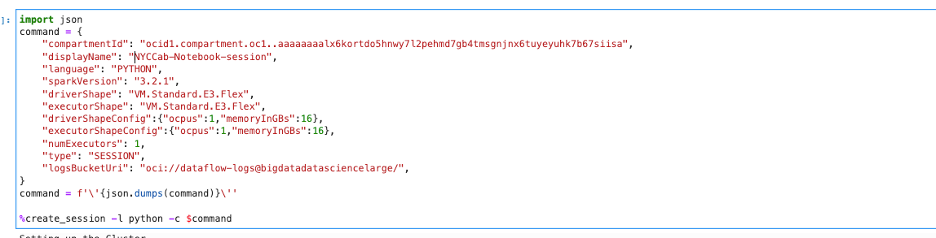
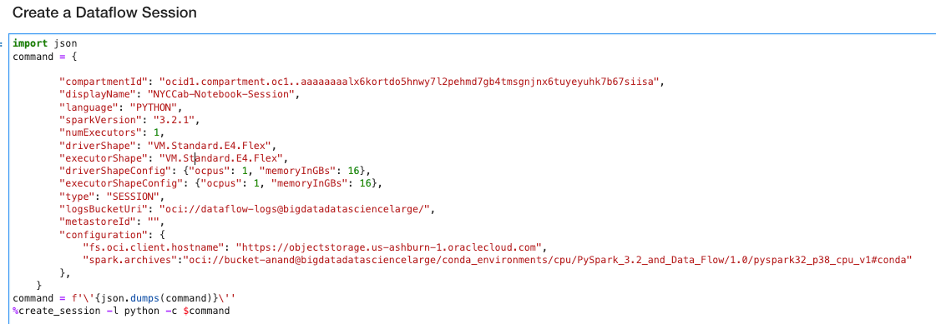
The command creates an interactive session on the remote Spark cluster. The command returns the session ID and a link to the Data Flow Run page. Also returned are the SparkSession (spark) and SparkContext (sc), which are the entry points to build the Spark application:

Simple example: Data analysis on NYC taxi trip duration dataset
We use the popular NYC TLC trip record dataset, also known as the NYC Taxi Dataset. The taxi trip records include fields capturing pick-up and drop-off dates, times, and locations, trip distances, itemized fares, rate types, payment types, and driver-reported passenger counts. We load the dataset into OCI Data Flow and perform some basic data analysis. The notebook is available on GitHub.
We start by reconfiguring the session using the %configure_session command and add executors. The dataset is over one billion records.
%configure_session -f -i '{"driverShape": "VM.Standard2.8", "executorShape": "VM.Standard2.8", "numExecutors":4}'
The command modifies the session to increase the number of executors to 4 and reconfigures the session.
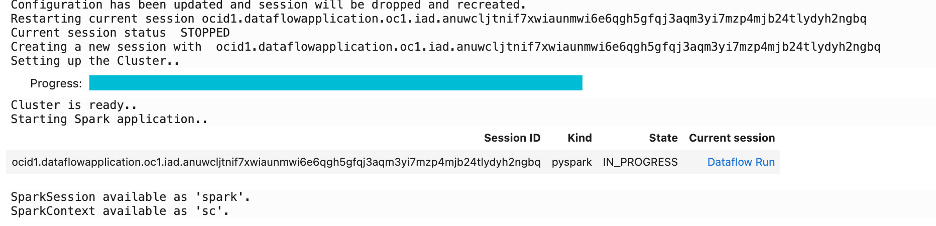
Next, we load the dataset to the Spark cluster. We have uploaded the entire parquet bundle to an Object Storage bundle and load that the cluster:
%%spark
nyc_tlc201 = spark.read.parquet("oci://hosted-ds-datasets@bigdatasciencelarge/nycP_tlc/201[1,2,3,4,5,6,7,8]/**/data.parquet", header=False,inferSchema=True)
nyc_tlc201.show()
nyc_tlc201.create0rReplaceTempView("nyc_tlc201")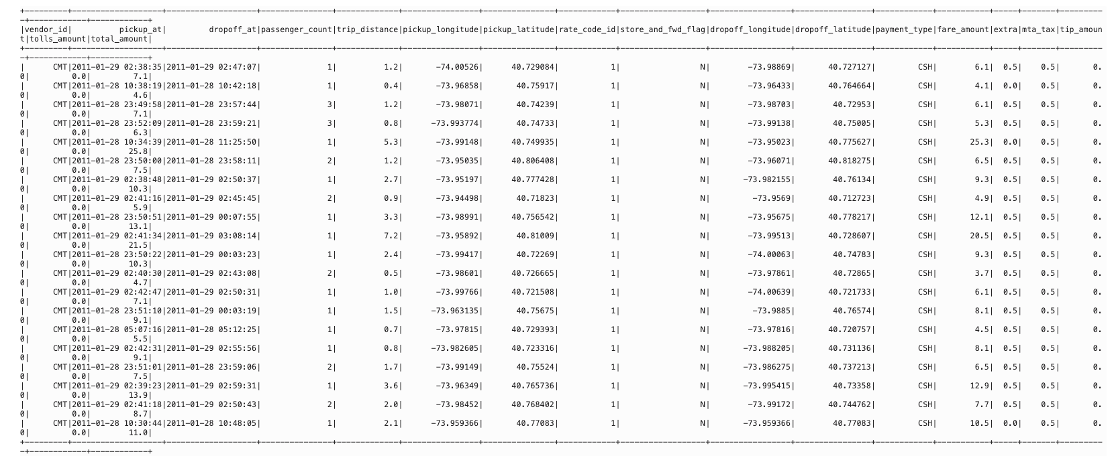
We print the count of records to verify:

Next, run a simple Spark SQL that does statistics on fare, tip, and so on:
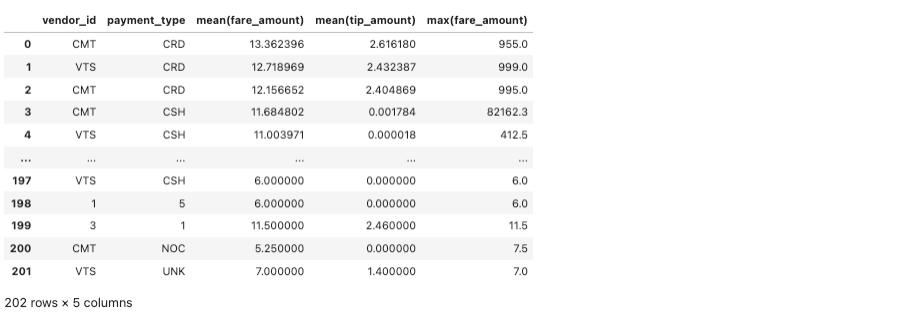
%%spark -c sql -o fare_summary
SELECT vendor_id, payment_type, MEAN(fare_amount), MEAN(tip_amount),MAX(fare_amount) \
FROM nyc-tlc201 \
GROUP BY vendor_id, payment+type, passenger_count;We export the results of the query to a local pandas dataframe object called fare_summary. This query allows the data frame to be manipulated in the local notebook session VM. The query gives the following result:
SparkMagic comes with autovizwidget and enables the visualization of Pandas data frames. The display_dataframe() function takes a Pandas data frame as a parameter and generates an interactive graphic user interface (GUI) in the notebook. It has tabs that allow the visualization of the data in various forms, such as tabular, pie charts, scatter plots, and area and bar graphs.
The following cell calls display_dataframe() with the df_people dataframe that was created:
from autovizwidget.widget.utils import display_dataframe
display_dataframe(fare_summary)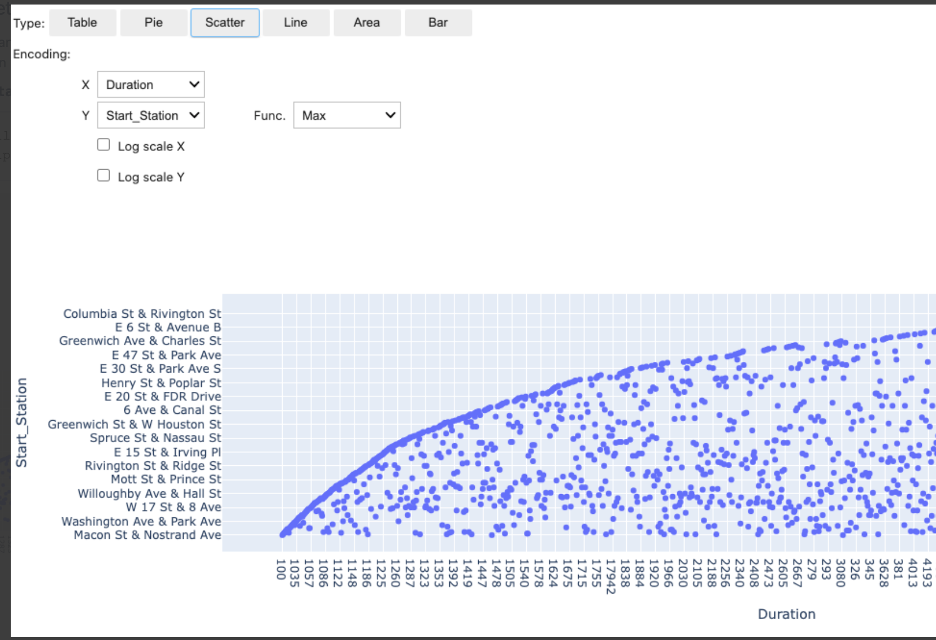
Conclusion
OCI Data Flow is fully managed and highly scalable service for running Apache Spark. In this post, we highlighted some of the capabilities of Data Flow notebook based on Jupyter. We saw how easy it is to create cluster, reconfigure the cluster, run Apache Spark commands interactively, and visualize the data without the burden of setting. All those capabilities are available within an OCI Data Science notebook session environment.
Try an Oracle Cloud Free Trial! A 30-day trial with US$300 in free credits gives you access to OCI Data Science service.
Ready to learn more about the Oracle Cloud Infrastructure Data Science service?
-
Configure your OCI tenancy with these setup instructions and start using OCI Data Science.
-
Star and clone our new GitHub repo! We included notebook tutorials and code samples.
-
Visit our service documentation.
-
Subscribe to our Twitter feed.
-
Visit the Oracle Accelerated Data Science Python SDK documentation.
-
Try one of our LiveLabs. Search for “data science.”
