※ 本記事は、Karan Singh, Sujoy Chowdhuryによる”Introducing OCI Data Flow SQL endpoints“を翻訳したものです。
2023年9月21日
Oracle Cloud Infrastructure (OCI) Data Flowは、膨大なデータセットを処理するために調整された包括的な管理Apache Sparkサービスであり、インフラストラクチャのデプロイメントと管理の煩わしさを解消します。このサービスを利用して、Data Flow SQLエンドポイントの最新の追加をご紹介します。
OCI Data Flow SQLエンドポイント
アナリスト、開発者およびデータ・サイエンティスト向けのData Flow SQLエンドポイントを設計し、データを変換または移動するのではなく、データレイク内のデータをネイティブ形式で直接対話形式で問い合せるようにしました。この機能は、データ・レイク内のリレーショナル・データ、半構造化データおよび非構造化データの量と複雑さが指数関数的に増加するため、非常に重要です。Data Flow SQLエンドポイントは、セキュアでコスト効率が高く、パフォーマンスに優れた方法でこの目標を達成します。これらはSpark上に構築されており、非構造化データのスケーラブルで簡単な読取りおよび書込みと、既存のOCI Data Flowサービスとの相互運用性を実現します。JSON、Parquet、CSV、Avroなど、Sparkでサポートされているすべてのファイル形式をサポートしています。
Oracle Cloudコンソール、CLIまたはAPIを使用して、データ・フローSQLエンドポイントを作成できます。エンドポイントを設定するには、まずOCI Data Catalogにメタストアを作成し、関連付けられたメタデータを格納します。Identity and Access Management (IAM)ポリシーも設定する必要があります。コンソールのナビゲーション・メニューの「Analytics and AI」で、「Data Lake」を選択し、「Data Flow」を選択します。「Data Flow」ページで、メニューの「SQL Endpoints」をクリックします。
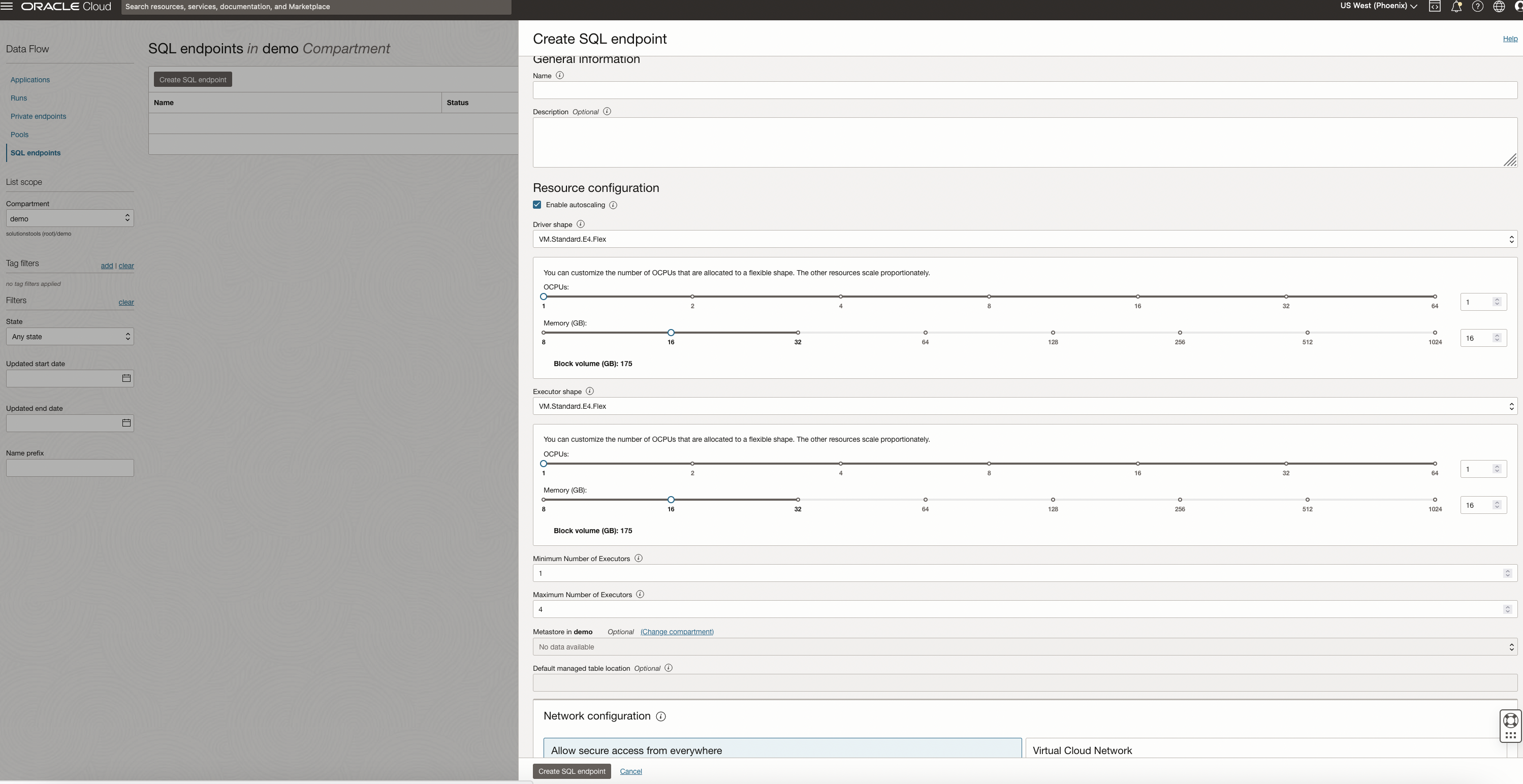
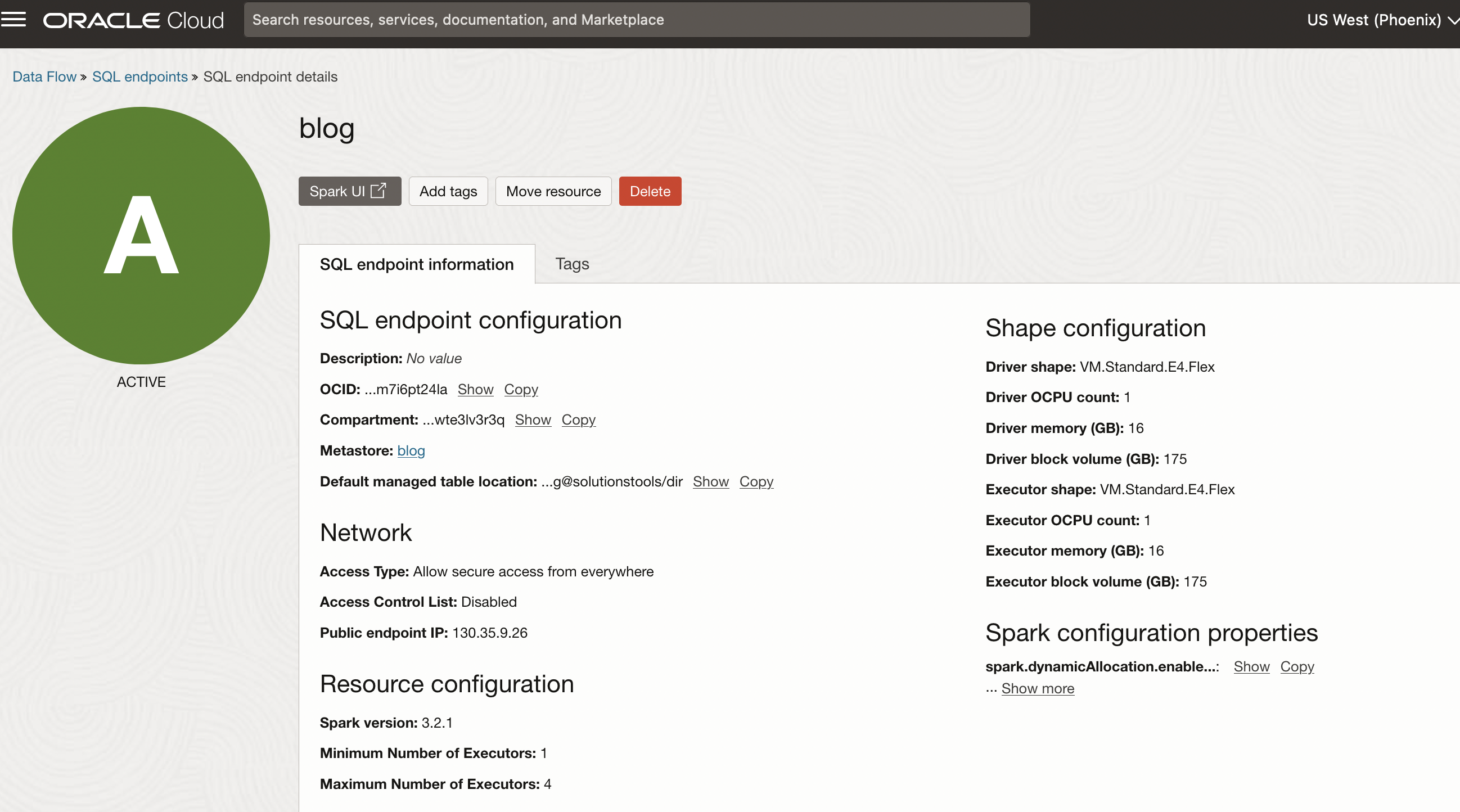
使用する名前、オプションの説明、ドライバとエグゼキュータのシェイプおよびメタストアを指定します。自動スケーリングを選択し、エンドポイントのエグゼキュータの最小数と最大数を指定することもできます。高度なオプションの下で、仮想クラウド・ネットワーク(VCN)およびアクセス制御ルールの指定などのネットワーキングを構成できます。オプションで、Spark構成プロパティを設定することもできます。
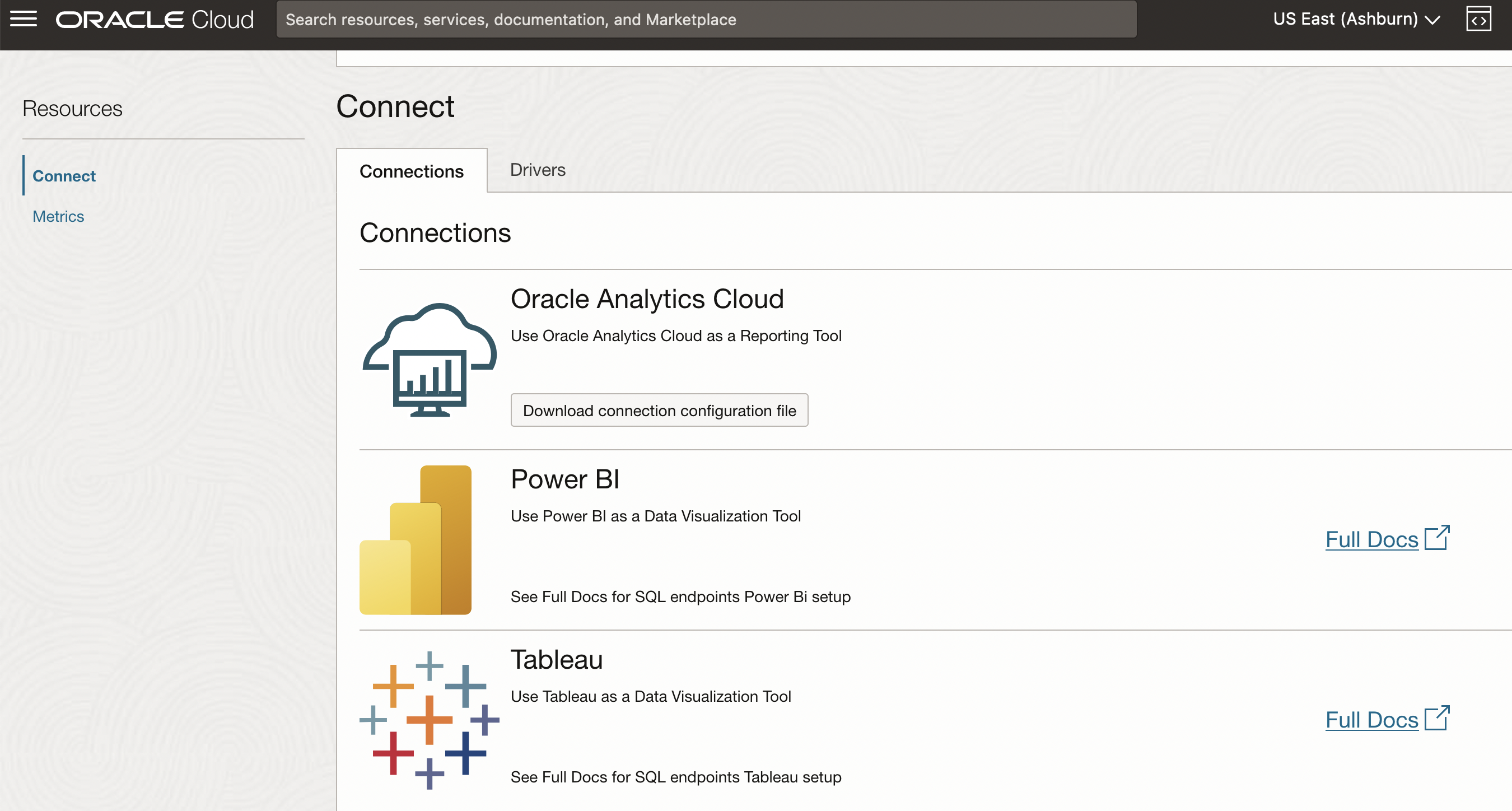
Data Flow SQLエンドポイントは、SQLを使用して、Oracle Analytics Cloud (OAC)、Microsoft Power BI、Tableauなどの主要なBusiness Intelligence (BI)ツール(Microsoft Open Database Connectivity (ODBC)やJava Database Connectivity (JDBC)接続とIAM資格証明を簡単かつ高速に問い合せ、サポートします。Data Flow SQLエンドポイントに接続するには、JDBCまたはODBCドライバとトークンまたはAPIキー認証が必要です。接続方法については、ドキュメント・ページを参照してください。
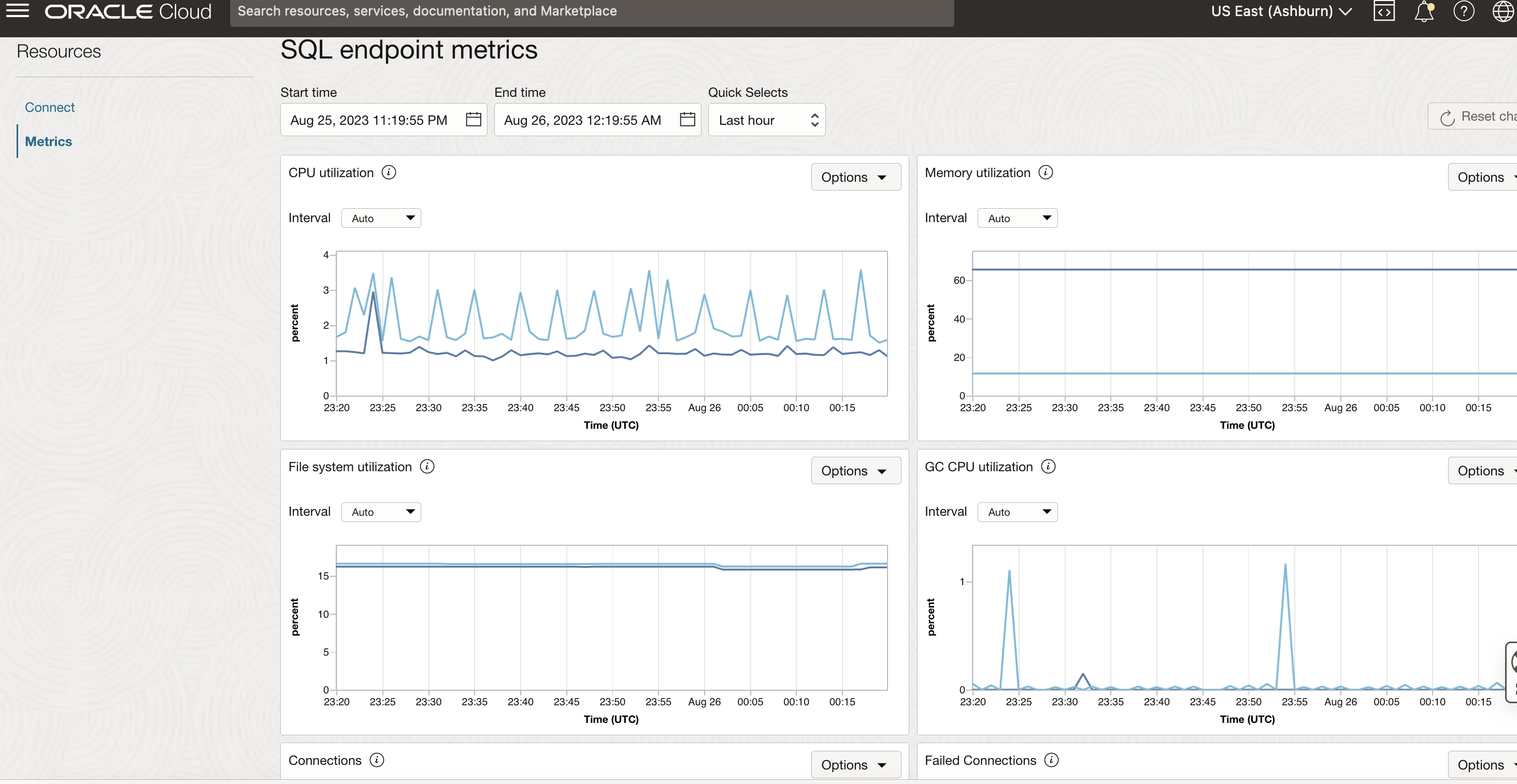
Data Flow SQLエンドポイントの問合せも、スケジュールされた本番パイプラインのData Flowバッチとシームレスに相互運用されます。コンソールには、CPU、メモリー、ファイル・システム使用率などのインフラ・レベルのメトリックや、接続、実行中、完了または失敗した問合せ、問合せ期間、ヘルス・ステータスなどのSQLエンドポイント関連のメトリックなど、重要なメトリックが表示されます。
まとめ
Data Flow SQLエンドポイントについてさらに学習するには、Oracle CloudWorldセッション 『Build an Intelligent Data Lake for Your Enterprise Data Platform』に参加してください。そして、ドキュメントを参照してください。
