Oracle Cloud Infrastructure (OCI) Data Flow is a comprehensive managed Apache Spark service tailored for processing vast datasets, eliminating the hassle of infrastructure deployment and management. Building on this service, we’re excited to introduce our latest addition: Data Flow SQL endpoints.
OCI Data Flow SQL endpoints
We designed Data Flow SQL endpoints for analysts, developers, and data scientists to interactively query data directly in the data lake in native formats instead of transforming or moving it. This functionality is critical as the volume and complexity of relational, semistructured, and unstructured data in data lakes increases exponentially. Data Flow SQL endpoints accomplish this goal in a secure, cost-effective, and performant manner. They’re built on Spark for scalable, easy read and write of unstructured data and interoperability with the existing OCI Data Flow service. They support all the file formats supported by Spark, including JSON, Parquet, CSV, and Avro.
You can create a Data Flow SQL endpoint using the Oracle Cloud Console, CLI, or API. To set up an endpoint, first create a metastore in OCI Data Catalog to store associated metadata. You must also set up Identity and Access Management (IAM) policies. In the Console navigation menu, under Analytics and AI, select Data Lake and then select Data Flow. On Data Flow page, click SQL Endpoints in the menu.
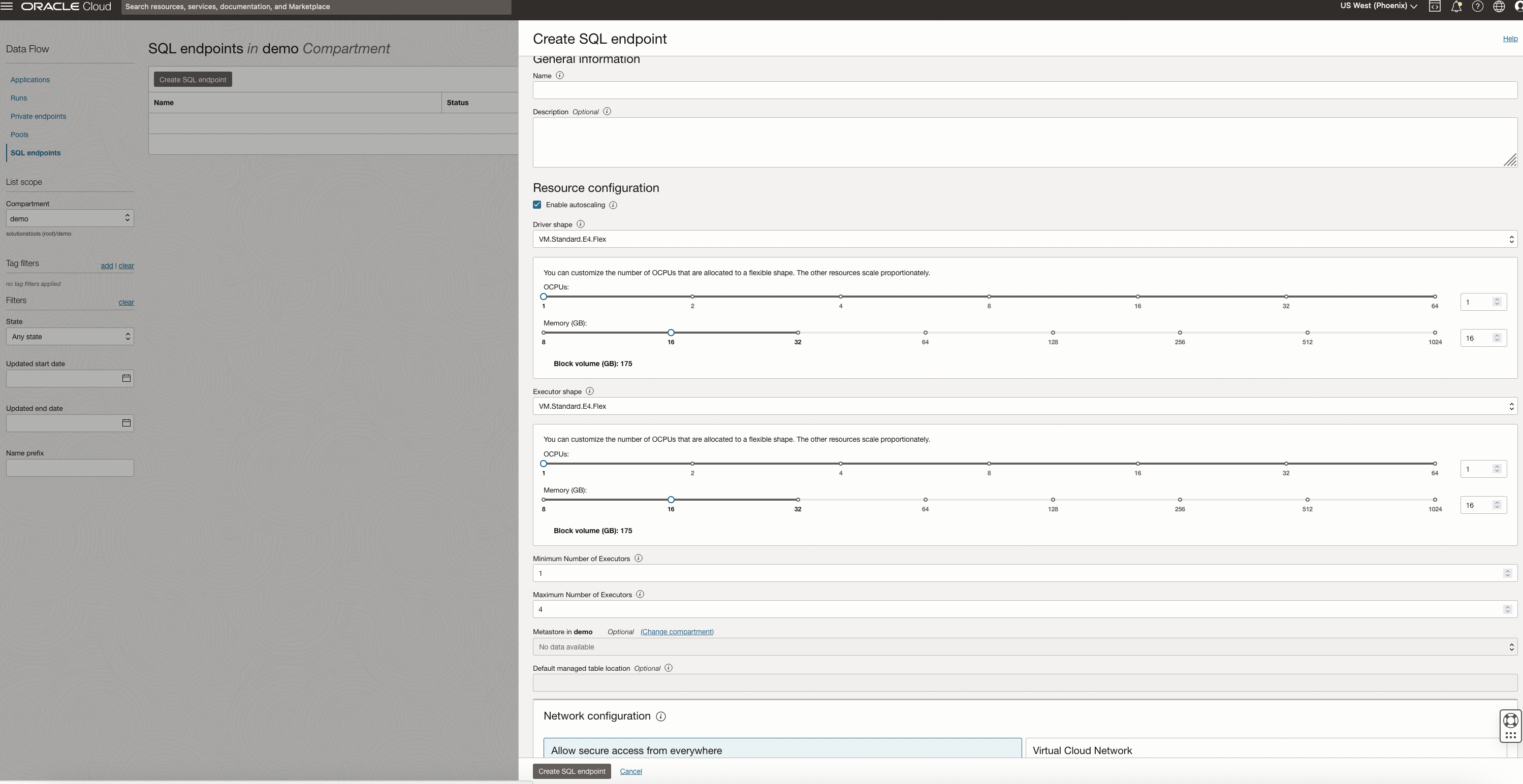
Provide a name, optional description, driver and executor shapes, and metastore to be used. You can also choose autoscaling and specify a minimum and maximum number of executors for the endpoint. Under advanced options, you can configure networking, including specifying your virtual cloud network (VCN) and access control rules. Optionally, you can also set Spark configuration properties.
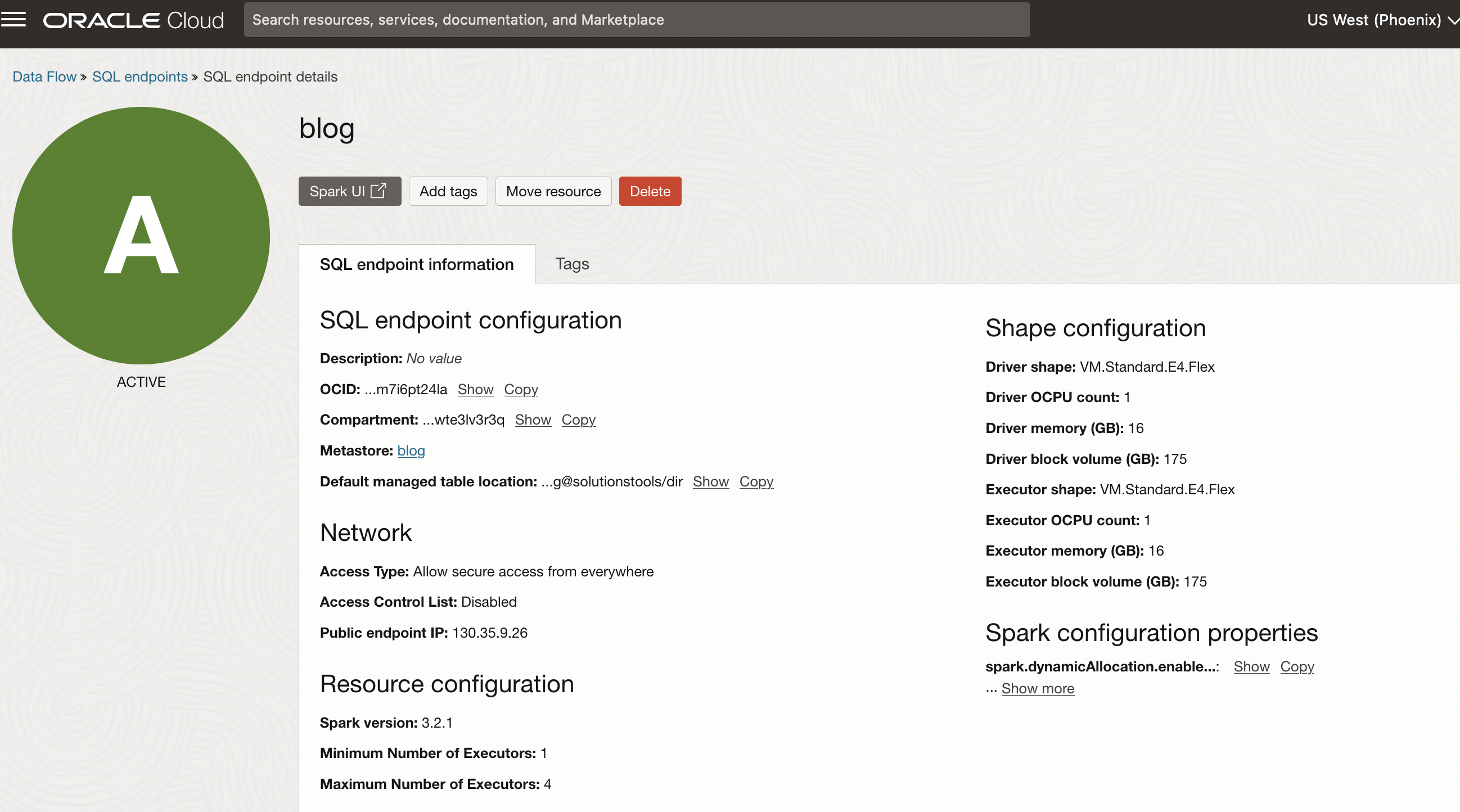
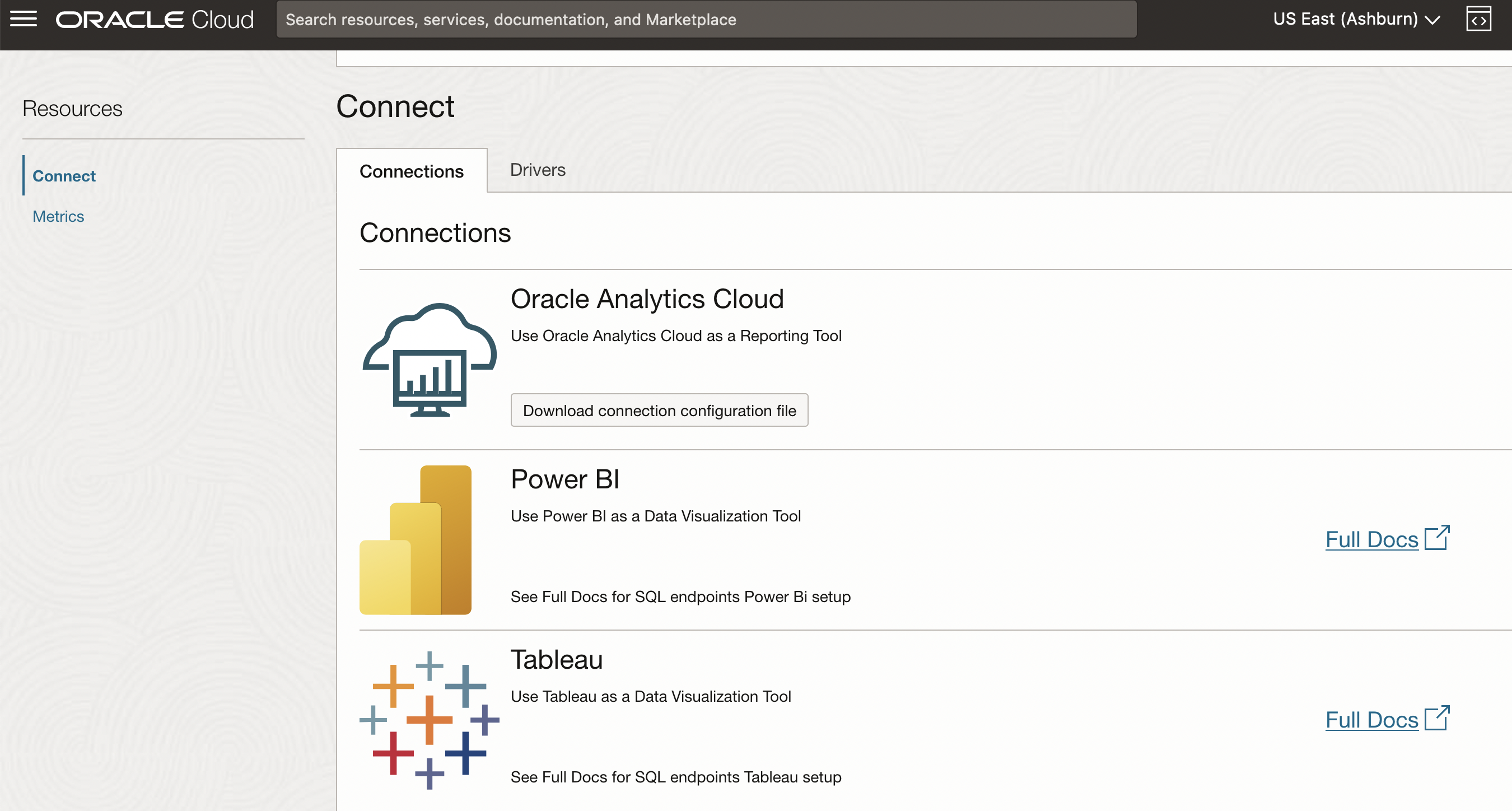
Data Flow SQL endpoints use SQL for easy, fast querying and support major Business Intelligence (BI) tools like Oracle Analytics Cloud (OAC), Microsoft Power BI and Tableau using Microsoft Open Database Connectivity (ODBC) or Java Database Connectivity (JDBC) connections with IAM credentials. You need a JDBC or ODBC driver and a token or API key authentication to connect to a Data Flow SQL endpoint. Instructions to connect are available on the documentation page.
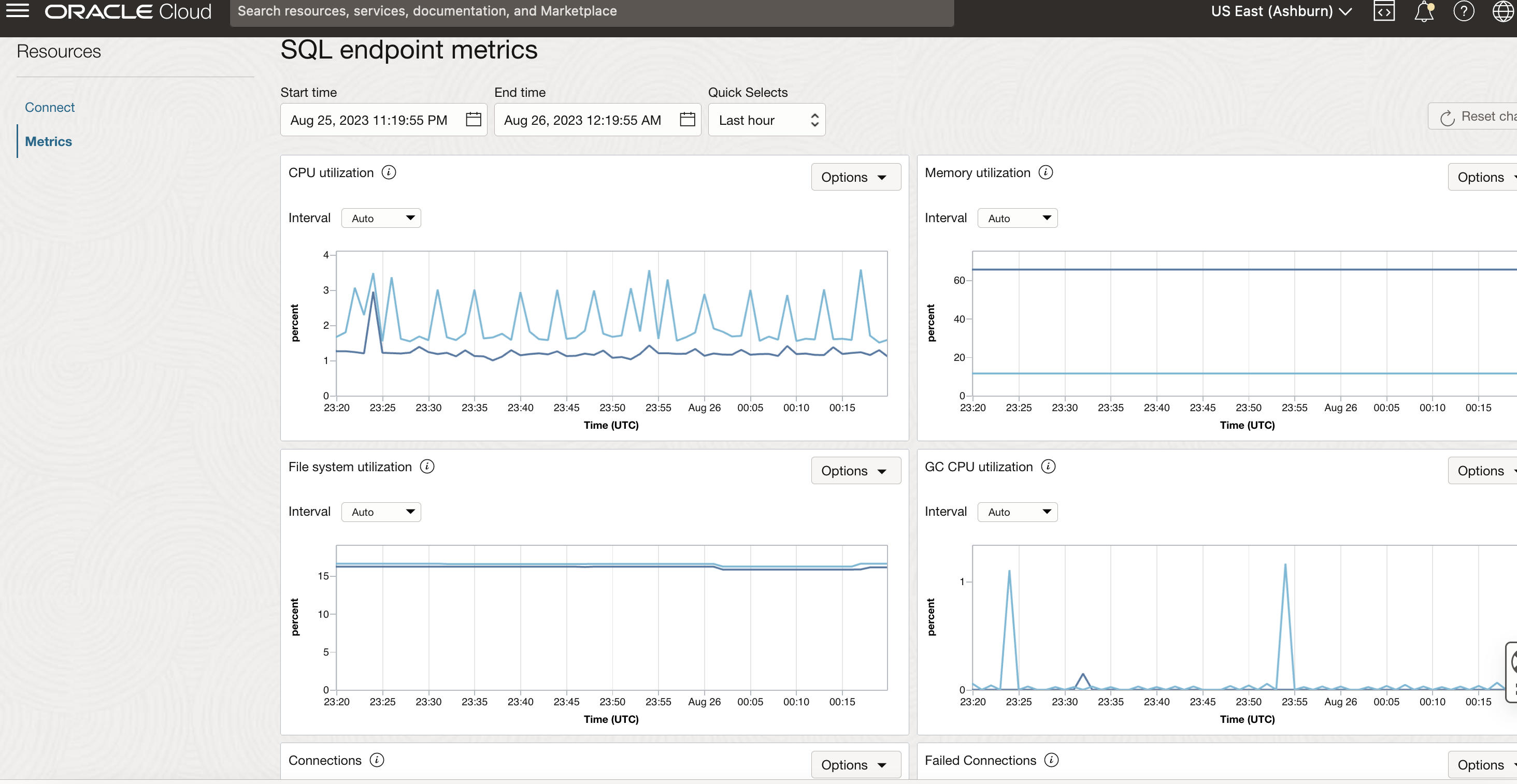
Queries in Data Flow SQL endpoints also seamlessly interoperate with Data Flow batches for scheduled production pipelines. The Console provides important metrics, including infra-level metrics like CPU, memory, and file system utilization and SQL endpoint-related metrics like connections, running, completed, or failed queries, query duration, and health status.
Conclusion
To learn more about Data Flow SQL endpoints, join us at the Oracle CloudWorld session, Build an Intelligent Data Lake for Your Enterprise Data Platform, and see the documentation.

