※本ページは、”From HA to Multi-Region: Always-On Distributed Databases with Asynchronous Raft Replication“の翻訳です。
2026年4月9日
エンタープライズ・データベースは、停止が許容されないアプリケーションを支えています。深夜に取引を処理する決済プラットフォームであれ、大陸を越えてユーザーにサービスを提供するグローバルなSaaS製品であれ、ダウンタイムは収益の損失や顧客の信頼低下に直結します。
今日のアプリケーションには、高可用性だけでなく、グローバルな分散性も求められています。毎秒数百万件のトランザクションを処理し、リージョン間でペタバイト規模のデータを扱う必要があります。こうした要件は、従来の高可用性だけでなく、分散システムの領域にも適用できます。
単一リージョンのデプロイメントでは、障害でアプリケーション全体がオフラインになってしまうという重大なリスクを伴います。これに対処するために、組織は複数のリージョンにまたがるAlways-onの分散データベース・アーキテクチの採用が進んでいます。Oracle Globally Distributed AI Databaseの今後のリリースでは、アクティブ/アクティブ構成でのローカルRaftベースのレプリケーションのサポートに加えて、アクティブ/パッシブ・トポロジおよび片方向の非同期レプリケーションによるRaftベースのレプリケーションを使用したマルチリージョン耐障害性もサポートされる予定です。これにより、リージョン間でデータを継続的にレプリケーションされます。
Always-Onの必要性
スタンバイ・レプリカ、フェイルオーバー・クラスタ、定期的なバックアップといった従来の高可用性アーキテクチャは、局所的な障害を想定して設計されました。これらはノードレベルの問題には有効ですが、リージョン全体が利用不能になった場合には不十分です。
復旧の有効性を定義するために、以下の2つの指標がよく用いられます:
- RPO(リカバリ・ポイント・オブジェクティブ):どの程度のデータ損失を許容できるか。 データ損失は絶対に避けたいものであるため、数値は低いほど良い。
- RTO(リカバリ・タイム・オブジェクティブ):どれくらいで復旧できるか。 ダウンタイムは1秒たりとも無駄にできないため、数値は低いほど良い。
マルチリージョン展開において、RPOをほぼゼロに、RTOを低く抑えるという目標を達成するには、基本的に異なるアプローチが必要です。それぞれにフォルト・トレランスが組み込まれた独立したクラスタ間で、継続的かつ非同期のレプリケーションを行うというアプローチです。
Oracle Globally Distributed AI Database: クロス・リージョンRaftレプリケーション
Oracle Globally Distributed AI Databaseは、RaftベースのレプリケーションをコアとするAlways-Onのアーキテクチャを提供します。
Globally Distributed AI Databaseでは、他のレプリケーションメカニズムを用いたマルチリージョン展開がすでに利用可能であり、地域をまたぐデータ分散と耐障害性を実現しています。この基盤をさらに発展させ、片方向非同期Raftレプリケーションを用いたアクティブ・パッシブ型のマルチリージョン構成を採用することで、リージョン内での強力な一貫性を維持しつつ、運用設計を簡素化します。
各クラスタは独立したRaftグループとして動作し、以下を提供します:
- リージョン内の同期的かつ強一貫性のあるレプリケーション
- リージョン間の非同期レプリケーション
この設計により、単一の論理データベースを維持しつつ、運用面でのリージョンの独立性が確保されます。
アーキテクチャ: アクティブ・パッシブのマルチ・リージョン デプロイメント
アクティブ・パッシブ・モデルは、強力な一貫性、予測可能な書き込み動作、およびリージョン間の競合解決を必要としない簡素化された運用が求められるワークロードに特に適しています。これは、より高度な分散デプロイメント・パターンに向けた基礎となるステップとなります。
以下の図は、2つのリージョンにまたがるOracle Globally Distributed AI Databaseのアクティブ・パッシブ・トポロジーを示しています。
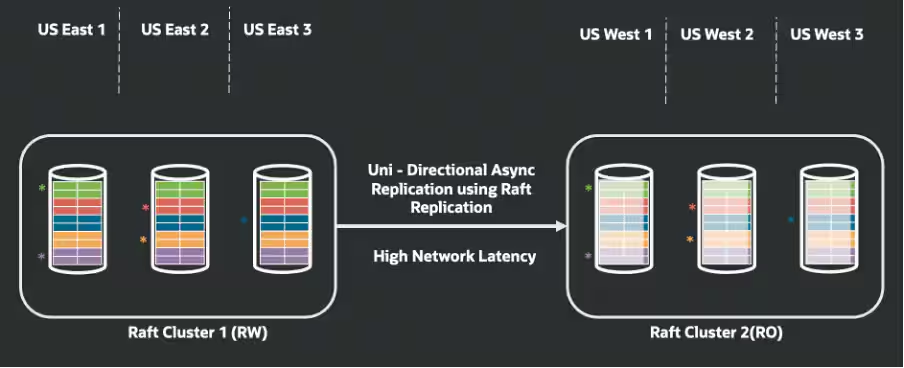
アーキテクチャは、2つのリージョンにわたるアクティブ/パッシブ・モデルを採用しています。
- プライマリ(アクティブ)リージョン: すべての読取り/書込みトラフィックを処理します。
- セカンダリ(パッシブ)リージョン: 片方向非同期レプリケーション(プライマリからスタンバイ)を介して、継続的にレプリケートされるコピーを保持します。
レプリケーション・モデル
このパターンの主な特徴は次のとおりです。
- 強力なリージョン内一貫性: Raftは、クォーラム・ベースのコミットを使用して、プライマリ・リージョン内で強力な一貫性を実現します。
- 低レイテンシの書込み: プライマリ・コミットはリモート・リージョンの応答を待たないため、定常状態での書き込み遅延を低く抑えます。
- トランザクション一貫性のあるスタンバイ: 変更はトランザクション境界で順番に適用されるため、スタンバイはプライマリの一貫したスナップショットを反映します。
- 明確な運用モデル: 書込みは一方向(プライマリからスタンバイ)に流れ、リージョン間の書込み競合を回避します。
- リージョン間の横断的なリカバリ・ポイント: RPOは非同期レプリケーションの遅延によって制限されます。この遅延は、ネットワーク状況やワークロードに依存します。
フェイル・オーバー: リージョン障害が発生した際の動作
このアーキテクチャは、2つのレベルの復旧機能をサポートしています。
リージョン内
Raftは、クォーラムが維持されている限り、リージョン内の障害(たとえば、US East 1でのノード障害)に対して、データ損失をほぼゼロに抑えた自動フェイルオーバーを提供します。これにより、リージョン内での強力な一貫性と中断のない運用が可能になります。
リージョン間
プライマリリージョンで障害が発生した場合:
- スタンバイリージョンには、継続的にレプリケートされ、トランザクション一貫性を保ったデータのコピーが(レプリケーションの遅延の範囲内で)すでに保持されています。
- スイッチオーバーまたは昇格手順により、スタンバイリージョンが読み書きモードに移行し、アプリケーションのトラフィックがセカンダリリージョンにリダイレクトされます。
- 発生しうるデータ損失は、障害発生時点での非同期レプリケーションの遅延の範囲内に収まります。
これにより、サービスの迅速な復旧とデータ損失の抑制が可能な、予測可能なリカバリモデルが提供されます。
例: リアルタイム決済プラットフォーム
大手金融機関では、低遅延のトランザクション処理、プライマリ地域内での強力な一貫性、および継続的な可用性を提供するために、リアルタイム決済プラットフォームのマルチリージョン展開が必要となることがよくあります。このアーキテクチャにより、プラットフォームはプライマリ地域で高いトランザクション処理能力を維持しつつ、地域的な障害発生時に迅速なフェイルオーバーが可能な、常に同期されたスタンバイ環境を維持できます。
耐障害性を高めるため、金融機関は同一国内の地理的に離れた2つのリージョンにまたがる展開を採用することができます。プライマリリージョンがすべての読み書きトラフィックを処理する一方、スタンバイリージョンは片方向の非同期レプリケーションを通じて、継続的にレプリケートされたコピーを維持します。リージョンで障害が発生した場合、ダウンタイムを最小限に抑えながらスタンバイをプライマリに昇格させ、アプリケーショントラフィックをリダイレクトすることができます。
柔軟なデプロイメント・モデル
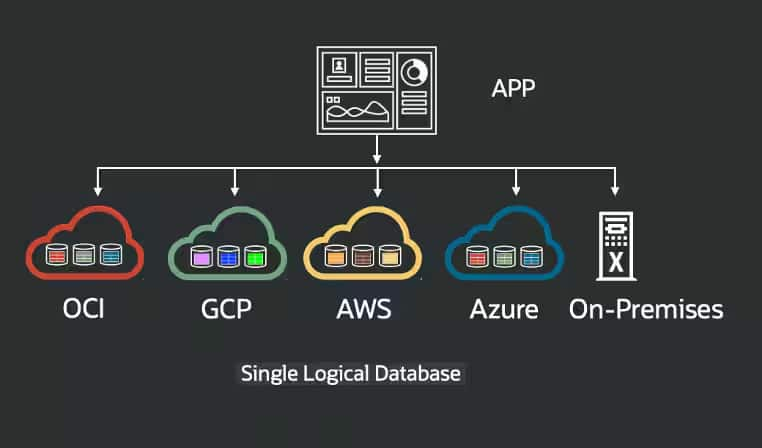
Oracle Globally Distributed AI Databaseは、インフラ環境全体におけるシャードの配置方法に柔軟性を提供します。シャードはオンプレミス、クラウド、あるいは複数のクラウドプロバイダーにまたがって配置することが可能です。これにより、お客様はシャードごと、あるいは国ごとに配置場所を個別に選択でき、データの配置をきめ細かく制御することで、パフォーマンスやコンプライアンスの要件に対応することが可能になります。
このアーキテクチャの大きな利点は、シャードが特定のクラウドプロバイダーに限定されないことです。クラスターはOracle Cloud Infrastructure(OCI)、AWS、Azure、Google Cloudにまたがって構築できるため、特定のクラウドに孤立したインスタンスではなく、マルチクラウド環境での展開が可能になります。このようなアーキテクチャにより、特定のクラウド環境への依存度を低減できます。たとえ特定のリージョンやクラウドプロバイダー全体で障害が発生した場合でも、他のリージョンやクラウドで稼働しているシャードを活用することで、アプリケーションの運用を継続することができます。
- クラウド固有の障害や地域的な障害からの保護
- アーキテクチャの再構築を必要とせずにワークロードを分散・移行できる柔軟性
さらに、下記の柔軟性も有効です
- 地域の需要とクラウドの可用性に基づいたスケーリングの最適化
- クラウドへのロックインの回避
- クラウド間でのシャードのオンライン移行
- 設備投資(CapEx)と運用コスト(OpEx)の最適化によるコスト効率の向上
複数のクラウドにまたがってアーキテクチャを展開できることは、データの保管場所や規制要件への対応を図る組織にとって特に有益です。なぜなら、これによりデータを特定の地理的範囲や管轄区域内に留めておくことができるからです。
まとめ
このアーキテクチャパターンは、単に災害復旧をサポートするだけでなく、従来の高可用性から、継続的な稼働、予測可能なパフォーマンス、そして運用上の簡素化を目的としたグローバルに分散されたシステムへの転換を意味します。
Oracle Globally Distributed AI Database は、以下の機能を組み合わせたものです:
- 強力な一貫性を確保するための、リージョン内での Raft ベースの同期レプリケーション
- リージョン間の非同期かつ一方向のレプリケーション
- マルチクラウド構成を含む柔軟な導入オプション
マルチ・リージョン・レプリケーションを中核とし、柔軟な導入オプションを備えたことで、常時稼働するAlways-On 分散データベースの構築は、実用的かつ運用が容易なものとなりました。
参考
Oracle Globally Distributed AI Database 製品ページ
Oracle Globally Distributed AI Database ドキュメント
Oracle Globally Distributed AI Database LiveLabs
