※本ページは、”Exadata PDB Sparse Clones“の翻訳です
はじめに
Exadata Sparse Clones(Exadata Sparse Snapshotとも呼ばれます)は、Exadataのネイティブ機能であり、開発やテストなどの非本番目的で、シン・プロビジョニングされたデータベース(プラガブルデータベース(PDB) 、およびフルデータベースの両方)の作成を可能にします。ここで重要な点は、Exadata Sparse Clones はデータベースに対応していることです。つまり、この投稿で説明するように、Exadata System Software とOracleデータベースの両方と緊密に統合されています。
データベースクローンは、組織が本番環境のようなデータベース環境に対して、テストおよび開発をできるようにするために必要になります。データの量が重要な場合もあれば、それほど重要でない場合もあります。コードをシステムテスト、統合テスト、パフォーマンステスト環境に移行する前に、各開発者が作業用に個別の環境を用意する(または必要とする)場合があります。データベースクローンの一部のユースケースは、開発やテストとは関係がない場合があります(少なくとも、これらのIT用語の意味では)。一部の組織は、what / if分析または分析モデルのトレーニング、チューニングなどのためのデータベースを、本番データベースに影響を与えることなく、アナリストに提供したい場合があります。ソース
PDB Sparse Clones の環境では、各PDBはその親データベース内のすべてのデータに効果的にアクセスでき、変更されたデータのみが Sparse PDBデータファイルに書き込まれます。その結果、本番サイズのデータ(セキュリティの観点で親データベースでデータをマスクしている場合もあります)を持つデータベースを提供し、Exadataのすべてのパフォーマンス機能にアクセスできるようになります。これはwin-winなソリューションです!
前述したように、PDBまたは「フル」データベースの Sparse Cloneを作成できます。これは、非CDB(11gR2〜19c)データベースまたはCDBとそれに関連するすべてのPDB(12cR1〜21c)のいずれかを意味します。このブログ記事では、PDBのみに焦点を当て、完全なデータベースクローンについて説明します。
始める前に、実行する必要のある小さな事前作業をカバーしましょう。まず、Exadata に SPARSE ASMディスクグループが必要です。名前が示すように、SPARSE ディスクグループには、作成した Sparse Clone(およびクローンのクローン、クローンのクローンのクローン…)が格納されます。
しかし、なぜ別のASMディスクグループが必要なのでしょうか?ご質問ありがとうございます。 Exadataの Sparse ディスクグループは、クローン用に作成するシンプロビジョニングされた(スパースな)データファイルと、クローンを作成しているPDBに属する完全にプロビジョニングされたデータファイルの親をリンクする特定のコードを実行します。これをPARENT(親)と呼びます。 PARENTは通常のPDBであり、通常はディスクグループにあります。Sparse ディスクグループは、物理サイズ(通常のグリッドディスク)と仮想サイズの両方を持つ Sparse グリッドディスクを使用します。
単一セルディスク上の Sparse グリッドディスクの最大集約物理サイズは4 TBであり、グリッドディスクあたりの対応する最大集約仮想サイズは100 TBであることに注意してください。(訳注:最大 25:1の比率まで設定できます)
たとえば、一台の Exadata X9M-2 HCモデルのストレージサーバーでは、セルディスクごとに単一の4 TB の Sparse グリッドディスクを使用して、Sparse グリッドディスクに48 TB(訳注: 4 TB x 12 disk)を物理的に割り当てることができます。これは、最大で1,200 TB(訳注:48TB の 25:1)の仮想スペースに相当します。ベストプラクティスは、 10:1(仮想対物理)の比率で、480 TBの仮想スペースが得られます。この時点ではまだASMの冗長性が考慮されていないことに注意してください。他のディスクグループと同じように、Sparse ディスクグループをミラーリングする必要があります。(Oracle)は高冗長性での利用を推奨します。 Exadata X9M-2 HCモデル Quarterラック構成の場合、ベストプラクティスの10:1の比率を使用して、Sparse ディスクグループに最大48TBの物理スペースと480TBの仮想スペースを割り当てることができます。
どのくらいの物理的および仮想的なスペースが必要でしょうか?良い質問です。 Exadata System Softwareユーザーズガイドの第10章には、これらの答えを決定するのに役立つ式が記載された優れたガイドがあります。
Sparse ディスクグループをどのように作成できるのでしょうか?この時点で、MOS Note 2176737.1を見てみましょう。このMOS NOTEでは、既存のディスクグループとそのグリッドディスクのサイズを変更して、Sparse グリッドディスクとディスクグループ用のスペースを作成する方法を説明します。新しいグリッド・ディスクおよびディスク・グループの作成については、 『Exadata System Software Users Guide』の第3章で説明されています。 OEDACLIを使用して同じ作業を実行することもできます。これにより、仮想空間のサイズ設定のベストプラクティスが自動的に適用されます。 この投稿を読んで、OEDACLIを使用して新しいグリッドディスクとASMディスクグループを簡単に作成できます。
Sparse データファイルは親データファイルに「リンク」されていると述べました。Sparse データファイルの構造を簡単に見てみましょう。
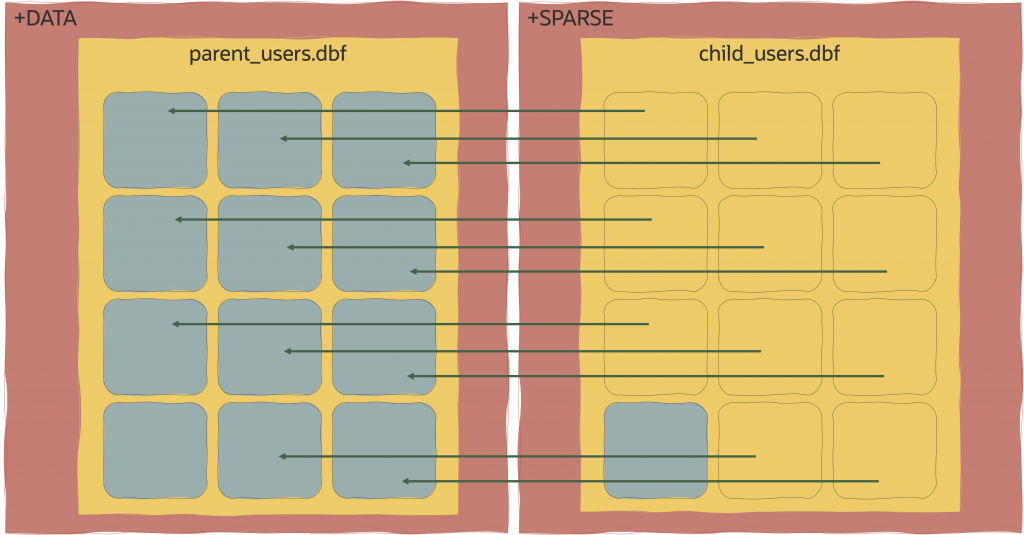
うまくいけば、右側の各Oracleデータ・ブロック(青い輪郭で表されている)には、左側の実際のOracleデータ・ブロック(青いブロックで表されている)へのポインターがあることに気付くでしょう。これは、Sparse ディスクグループ上のブロックに対して読み取りが要求されたときに、ASMがその読み取りブロックが Sparse ディスクグループに存在しない場合は実際のブロックにポイントすることを示しています。また、child_users.dbfファイルの左下に「実際の」ブロックがあることに気付くでしょう。Sparse データファイルへの書き込みが発生すると、親からの元のブロックがDBWRプロセスによって、Sparse ディスクグループにコピーされ、そのブロックの将来のヘッドが取得されます。
したがって、Sparse PDB Clones を実際に作成してみる前に、Exadata Sparse Clones のスペース効率を確認できます。
先に進む前に、1つのことを明確にする必要があります。親として機能しているデータベースまたはPDB(古い用語ではテストマスター)は読み取り専用である必要があります。上の図をもう一度見ると、親のソースブロックが変更された場合、そのブロックをSparse ディスクグループにコピーする必要があり、スペース効率が低下します。以前に「クローンのクローン」(階層クローンとも呼ばれます)に触れました。つまり、Sparse Clone はさらにSparse Clone の親になることもできます。これは、たとえば、データをマスキングしたり、そのポイントより下のすべてのクローンで取得したいスキーマ変更をデプロイしたりすることを目的としています。
それでは、投稿の残りの部分で何をするかを「マップ」してみましょう。
- +DATAC1ディスクグループおよび+SPARSC1ディスクグループでアクセス制御を設定します
- 親(テストマスター)として機能するPDBを作成します。
- 親DBにデータを挿入します
- 親DBを一度クローズして、再度読み取り専用でオープンします。
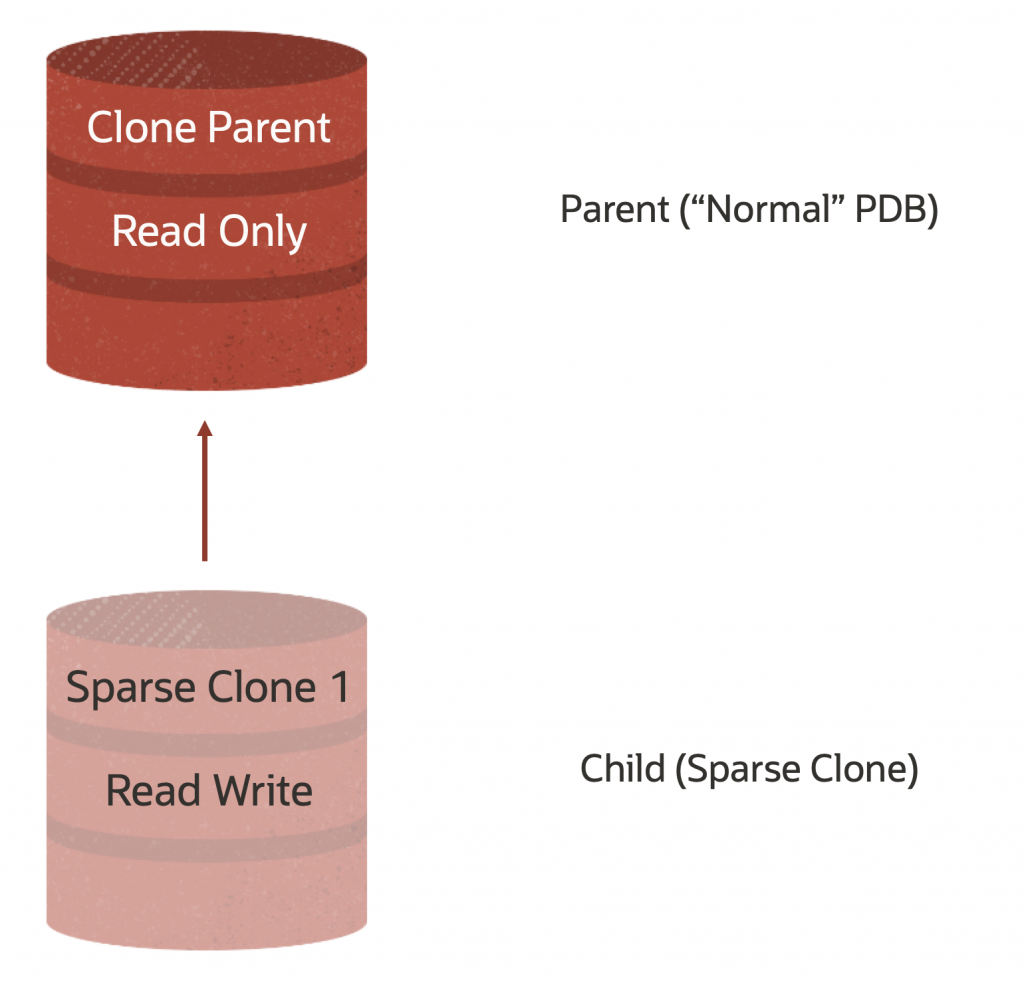
- 親DBからスパース・クローンPDBを作成します
この時点で、次の構造になっているはずです。このビューではCDBを表示していないことに注意してください。
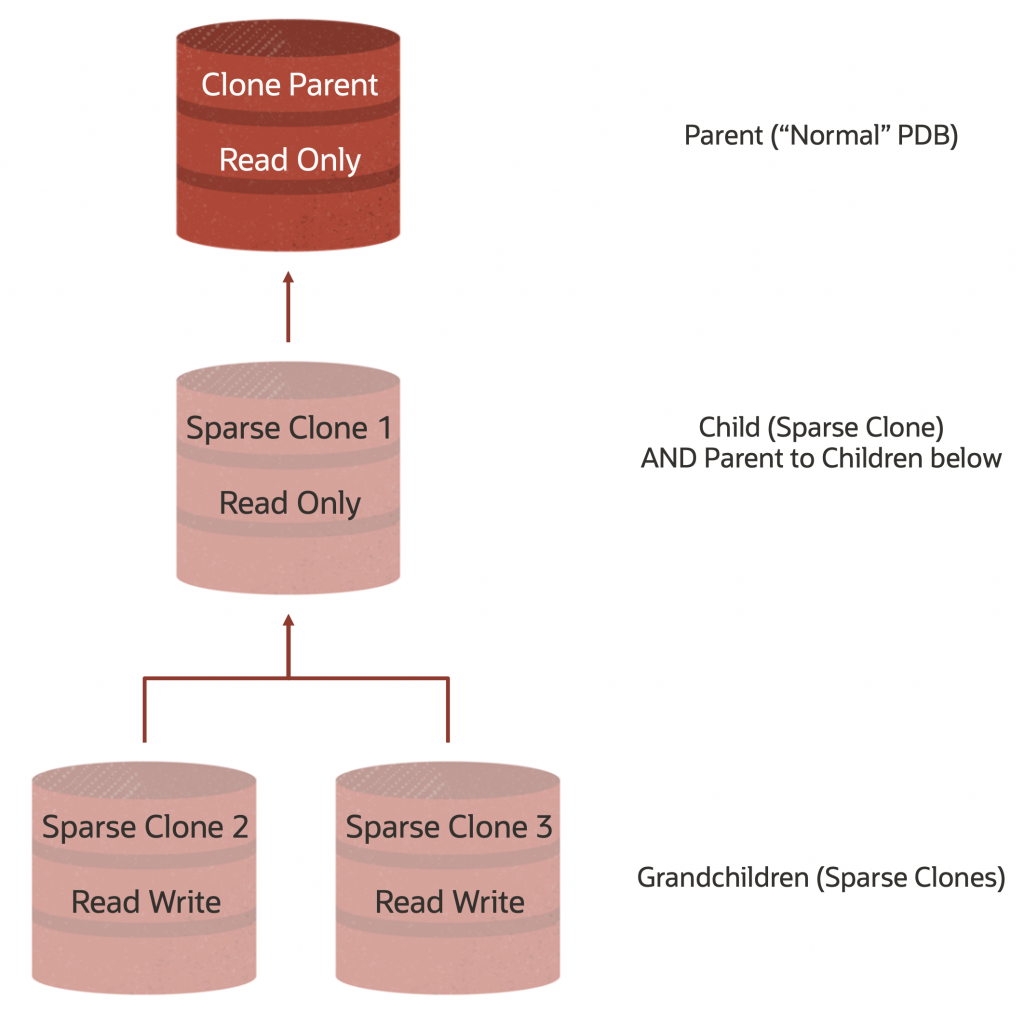
次に、このプロセスを繰り返して、さらに2つのクローンを作成します。今回は、最初の Sparse Clone を親として使用する階層クローンです。
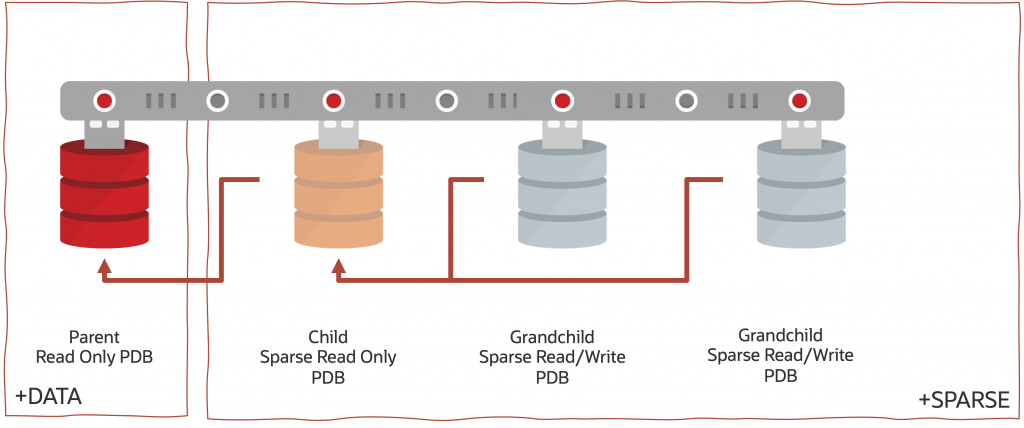
これをOracleマルチテナントアーキテクチャのコンテキストに置くと、次のようになります。赤い線は、各 Sparse PDB Clone からDATAディスクグループの親PDBまでのIOパスを示します。
(ついに)始めましょう。
ASMファイル・アクセス制御
Sparse Clone では、クローンの親DBを保持するディスクグループにASMファイル・アクセス制御を設定する必要があります。この場合、いくつかの階層クローンの作成を計画しているため、+DATAC1ディスクグループと+SPARSC1ディスクグループの両方でこれを行う必要があります。
これを行うには、gridユーザーでASMインスタンスに接続します。
sqlplus / as sysasmaccess_control.enabled属性をTRUEに設定して実行します
SQL> alter diskgroup DATAC1 set attribute 'access_control.enabled' = 'true';
SQL> alter diskgroup SPARSC1 set attribute 'access_control.enabled' = 'true';ついでに、ディスクグループに新しく作成されたファイルを所有しているASMに通知する必要もあります。所有者が割り当てられていない場合、アクセス制御を強制するのは困難です。
SQL> alter diskgroup DATAC1 add user 'oracle';
SQL> alter diskgroup SPARSC1 add user 'oracle';
次に、使用している既存のCDBおよびPDBのデータファイルを所有しているASMに通知します。 CDB$ROOTに接続して、次のSQLを使用して、必要な alter diskgroupコマンドを生成します。
SQL> select 'alter diskgroup '||substr(file_name,2,regexp_instr(file_name,'\/')-2)||' set ownership owner=''oracle'' for file '''||file_name||''';' as cmd from containers(dba_data_files);これにより、次のようなものが得られます。
alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/DATAFILE/system.262.1081269351';
alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/DATAFILE/sysaux.264.1081269355';
alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/DATAFILE/undotbs1.266.1081269357';
alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/DATAFILE/undotbs2.270.1081269377';
alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/DATAFILE/users.271.1081269377';
alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/DATAFILE/soe_ts.286.1081323253';
alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/DATAFILE/otn_ts2.289.1085263559';
alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/D05FA6C6D11BF1F7E053CE421F0A656F/DATAFILE/system.402.1088159855';
alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/D05FA6C6D11BF1F7E053CE421F0A656F/DATAFILE/sysaux.401.1088159855';
alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/D05FA6C6D11BF1F7E053CE421F0A656F/DATAFILE/undotbs1.411.1088159855';
alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/D05FA6C6D11BF1F7E053CE421F0A656F/DATAFILE/data_ts.412.1088159877';
これらのalter diskgroupコマンドを、ASMで実行します。
sqlplus / as sysasm
SQL*Plus: Release 21.0.0.0.0 - Production on Thu Nov 11 20:51:46 2021
Version 21.3.0.0.0
Copyright (c) 1982, 2021, Oracle. All rights reserved.
Connected to:
Oracle Database 21c Enterprise Edition Release 21.0.0.0.0 - Production
Version 21.3.0.0.0
SQL> alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/DATAFILE/system.262.1081269351';
Diskgroup altered.
SQL> alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/DATAFILE/sysaux.264.1081269355';
Diskgroup altered.
... - Truncated for readbility
SQL> alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/D05FA6C6D11BF1F7E053CE421F0A656F/DATAFILE/undotbs1.411.1088159855';
Diskgroup altered.
SQL> alter diskgroup DATAC1 set ownership owner='oracle' for file '+DATAC1/CDB1DB5/D05FA6C6D11BF1F7E053CE421F0A656F/DATAFILE/data_ts.412.1088159877';
Diskgroup altered.「通常の」PDBを作成し、データを追加します
Sparse PDBの最終的な親DBとして使用するPDBを作成する方法は多数あります。本番データベースからのPDBホットクローン、GoldenGate、Data Guard、Goliath Snail(実際の製品ではありませんが、おそらくそうあるべきですなどの方法を使用できます)。
この例では、Patrick Wheelerが意図した方法でPDBを作成します。
SQL> create pluggable database PARENT_PDB admin user admin identified by welcome1;
SQL> alter pluggable database PARENT_PDB open;これにより、+DATAC1ディスクグループにPARENT_PDBというプラガブルデータベースが作成されてOpenされました(読み取り/書き込み可能)。 +DATAC1ディスクグループに作成されていることをどうやって知ることができますか? db_create_file_destパラメーターから分かります。
SQL> show parameter db_create_file_dest
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_create_file_dest string +DATAC1
それでは、データを追加しましょう。これは、PDBにディクショナリ以外のデータがあり、さらに、PDBのクローンを作成することで必要な処理を実行し、SPARSEディスクグループにデータが見つからない場合はIOをそのデータにリダイレクトできることを確認するためです。
SQL> alter session set container=PARENT_PDB;
SQL> create tablespace data_ts datafile '+DATAC1' size 100M autoextend on next 100M maxsize 1G ;
SQL> create table sample_table tablespace data_ts as select * from dba_objects;
SQL> commit;
この時点で、CDBには次のPDBが存在します。
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
4 PARENT_PDB READ WRITE NO
次に、PARENT_PDB PDBを読み取り専用モードで閉じて再オープンし、後続のスパースクローンのクローンの親になる準備をします。以下の出力の最後の行に注意してください(出力の残りの部分はかなり自明だと思います)- PARENT_PDBがオープン読み取り専用になったことが分かります。
SQL> alter session set container=cdb$root;
Session altered.
SQL> alter pluggable database PARENT_PDB close IMMEDIATE instances=all;
Pluggable database altered.
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
4 PARENT_PDB MOUNTED
SQL> alter pluggable database PARENT_PDB open read only instances=all;
Pluggable database altered.
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
4 PARENT_PDB READ ONLY NO
新しいPDBを作成する前に、「alter plugingable database <db_name> open read only」コマンドを入力して、PDBが読み取り専用であることをCDBに通知するだけでなく、ASMにデータファイルのファイル権限を読み取り専用に変更するように指示することにも注意してください。これは、誰かがASMで直接データファイルを削除したり操作したりするのを防ぐために設計された安全機能です。親PDBは、SPARSE PDBからIOを向けるためにOPENである必要はないため、PDBがMOUNT状態のみであっても、ファイルがそこにあることを確認する必要があることに注意してください。
そして、私たちはついにあなたが待っていた瞬間に到着します-私たちの最初のSPARSE PDBを作成します!期待してください!!!!
SQL> create pluggable database CHILD_PDB from PARENT_PDB create_file_dest='+sparsc1' SNAPSHOT COPY;
SQL> alter pluggable database CHILD_PDB open instances=all;
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
4 PARENT_PDB READ ONLY NO
5 CHILD_PDB READ WRITE NO
ご覧のとおり、SPARSE PDBの作成は、通常のPDBの作成と非常に似ています。ちょっと待って!!!そのcreate_file_destの属性と、SNAPSHOT COPY 句のコマンドオプションは何でしょうか?新しいオプションです…
実際には、インスタンスのcreate_file_destは、init.oraパラメーターの同じパラメーターをオーバーライドするだけです。この場合、データベースに+SPARSEディスクグループを使用するように指示しています。ただし、これをSNAPSHOT COPY 句コマンドオプションと組み合わせて使用すると、データベースに SPARSE CLONE を作成するように指示します。 SNAPSHOT COPY コマンド句は、Exadata Storage Snapshot 機能を利用してPDBのシンクローンを作成するようにデータベースに指示するために使用されます。Exadataでは、SPARSE ディスクグループ、ないしはACFSのいずれかを使用することを意味します。
PARENT_PDB と CHILD_PDB PDBの両方に問い合わせると、両方に同じデータが存在することが確認できます。
SQL> alter session set container=PARENT_PDB;
Session altered.
SQL> select count(*) from sample_table;
COUNT(*)
----------
24489
SQL> alter session set container=CHILD_PDB;
Session altered.
SQL> select count(*) from sample_table;
COUNT(*)
----------
24489
信じられない場合に備えて、CHILD_PDB にさらにデータを挿入し、READ ONLY の PARENT_PDB PDB で同じことを試みることができます。何が起こるかを推測するための賞品はありませんが。。
SQL> alter session set container=CHILD_PDB;
Session altered.
SQL> insert into sample_table select * from sample_table;
24489 rows created.
SQL> commit;
Commit complete.
SQL> select count(*) from sample_table;
COUNT(*)
----------
48978
SQL> alter session set container=PARENT_PDB;
Session altered.
SQL> insert into sample_table select * from sample_table;
insert into sample_table select * from sample_table
*
ERROR at line 1:
ORA-16000: database or pluggable database open for read-only access
SQL> rollback;
Rollback complete.
了解しました。感動したと言えますが、もっと知りたいでしょう。わかりました、わかりました。
最後から2番目のフェーズである階層クローンの作成に取り掛かりましょう。または、階層クローンの意味を忘れた場合は、クローンのクローン。 CHILD_PDB PDB を次のレベルの Sparse PDBの親として使用するため、PARENT_PDB PDBの場合と同様に、CHILD_PDB PDBを準備して読み取り専用で再度開く必要があります。
SQL> alter session set container=cdb$root;
Session altered.
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
4 PARENT_PDB READ ONLY NO
5 CHILD_PDB READ WRITE NO
SQL> alter pluggable database CHILD_PDB close immediate instances=all;
Pluggable database altered.
SQL> alter pluggable database CHILD_PDB open read only instances=all;
Pluggable database altered.
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
4 PARENT_PDB READ ONLY NO
5 CHILD_PDB READ ONLY NO
次に、SPARSEディスクグループとSNAPHOT COPY コマンド句を使用して、G_CHILD_PDB1 という新しいPDBを作成します。
SQL> create pluggable database G_CHILD_PDB1 from CHILD_PDB create_file_dest='+sparsc1' SNAPSHOT COPY;
Pluggable database created.
SQL> alter pluggable database G_CHILD_PDB1 open instances=all;
Pluggable database altered.
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
4 PARENT_PDB READ ONLY NO
5 CHILD_PDB READ ONLY NO
6 G_CHILD_PDB1 READ WRITE NO
そして、ここにいる間に G_CHILD_PDB2 という2つ目の PDB 作成を行い、2人の開発者の友人がそれぞれ1つずつ持つことができるようにします。
SQL> create pluggable database G_CHILD_PDB2 from CHILD_PDB create_file_dest='+sparsc1' SNAPSHOT COPY;
Pluggable database created.
SQL> alter pluggable database G_CHILD_PDB2 open instances=all;
Pluggable database altered.
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
4 PARENT_PDB READ ONLY NO
5 CHILD_PDB READ ONLY NO
6 G_CHILD_PDB1 READ WRITE NO
7 G_CHILD_PDB2 READ WRITE NO
これで、意図したとおりに実行され、論理的に次のようにプロビジョニングされたPDBの階層ができました。
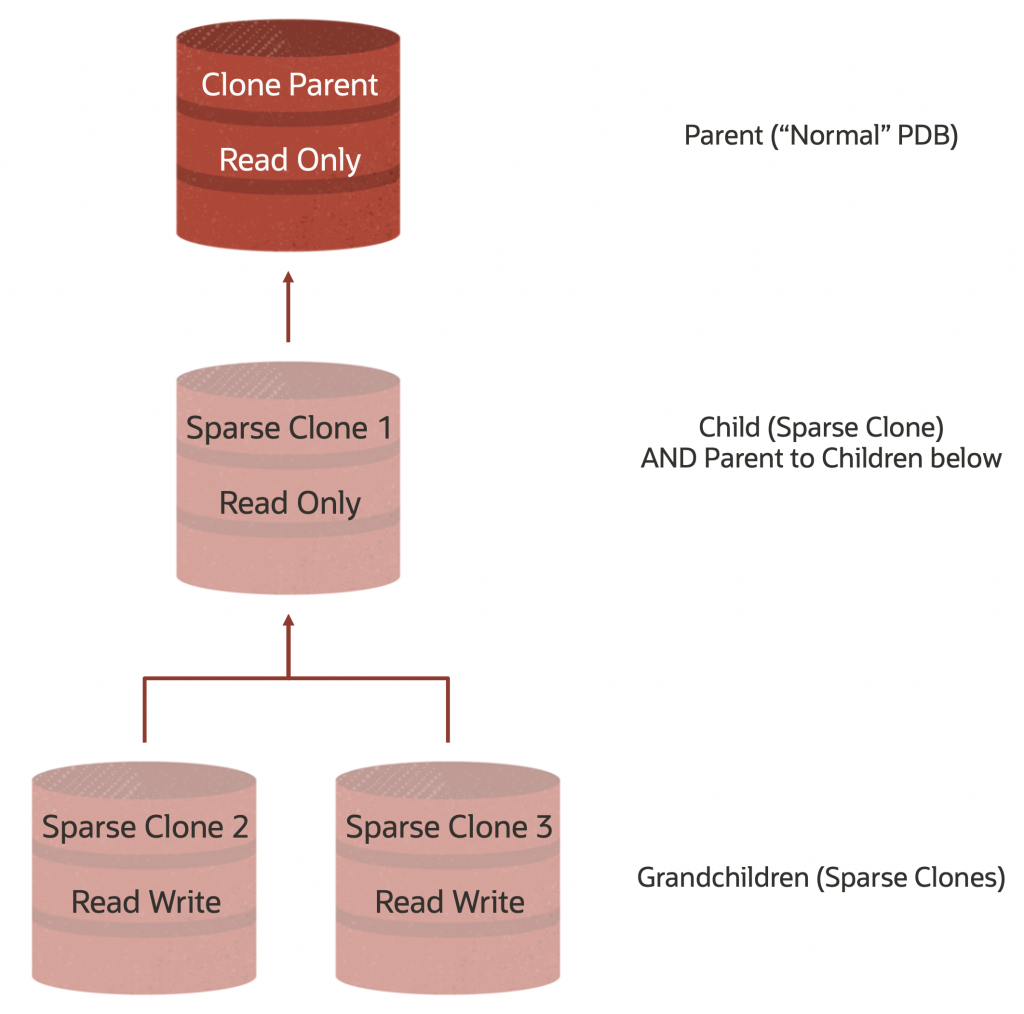
しかし、どうすればあなたが尋ねているのを聞いているかを確認できますか? SQLで!!! 正確には、2つのSQLで確認できます。ドキュメントでは、ASMで実行するSQLにより、SYSTEMテーブルスペースのASMパスが提供されます。これはすばらしいことですが、ASMはPDB名を認識していないためです(私はOracle Managed FIlesを使用しているシステムを使用しているので、そうする必要があります)。 パス内のGUIDを取得し、データベース内のCDB_PDBS に対してそれを再確認することで、どのPDBがどれであるかを判断する唯一の意味のある方法です。この2段階のアプローチを使用すると、PDB_NAME をデータファイル名の GUID と一致させることができます。
set serveroutput ON
set echo off
spool report_hierarchy.sql
DECLARE
c1_pdb_name cdb_pdbs.pdb_name%type;
c1_guid cdb_pdbs.guid%type;
cursor c1 is select guid, pdb_name from cdb_pdbs;
BEGIN
dbms_output.put_line('SELECT (case REGEXP_SUBSTR(snapshotfilename, ''[^/"]+'', 1, 3)');
open c1;
LOOP
fetch c1 into c1_guid, c1_pdb_name;
exit when c1%notfound;
dbms_output.put_line('when '''||c1_guid||''' then '''||c1_pdb_name||'''');
end loop;
dbms_output.put_line('END) PARENT,');
close c1;
dbms_output.put_line('(case REGEXP_SUBSTR(clonefilename, ''[^/"]+'', 1, 3)');
open c1;
LOOP
fetch c1 into c1_guid, c1_pdb_name;
exit when c1%notfound;
dbms_output.put_line('when '''||c1_guid||''' then '''||c1_pdb_name||'''');
end loop;
dbms_output.put_line('END) CHILD');
close c1;
dbms_output.put_line('FROM v$clonedfile');
dbms_output.put_line('WHERE LOWER(snapshotfilename) LIKE ''%system.%''');
dbms_output.put_line('START WITH snapshotfilename NOT IN (SELECT clonefilename FROM v$clonedfile)');
dbms_output.put_line('CONNECT BY LOWER(clonefilename) = PRIOR (snapshotfilename);');
END;
/
spool off
!sed -i '/^PL/d;/^SQL/d;/^ [ |1-2][0-9]/d;/^Elapsed/d' report_hierarchy.sql
この最初のSQL(および下部にある小さなsedコマンド)は、ASMで実行するSQLステートメントを作成します。これにより、CDB内のPDBの親子関係が得られ、次のような結果になり、ASMで実行されます( sqlplus / as sysasm):
SELECT (case REGEXP_SUBSTR(snapshotfilename, '[^/"]+', 1, 3)
when 'CA2F5B57BD25C5ACE053CE421F0A7AF3' then 'PDB$SEED'
when 'D0CDC89E51BA85AEE053CE421F0AE0C3' then 'PARENT_PDB'
when 'D0CDC89E51D385AEE053CE421F0AE0C3' then 'CHILD_PDB'
when 'D0CE5E3D74814A66E053CE421F0ADF05' then 'G_CHILD_PDB1'
when 'D0CE5E3D74854A66E053CE421F0ADF05' then 'G_CHILD_PDB2'
END) PARENT,
(case REGEXP_SUBSTR(clonefilename, '[^/"]+', 1, 3)
when 'CA2F5B57BD25C5ACE053CE421F0A7AF3' then 'PDB$SEED'
when 'D0CDC89E51BA85AEE053CE421F0AE0C3' then 'PARENT_PDB'
when 'D0CDC89E51D385AEE053CE421F0AE0C3' then 'CHILD_PDB'
when 'D0CE5E3D74814A66E053CE421F0ADF05' then 'G_CHILD_PDB1'
when 'D0CE5E3D74854A66E053CE421F0ADF05' then 'G_CHILD_PDB2'
END) CHILD
FROM v$clonedfile
WHERE LOWER(snapshotfilename) LIKE '%system.%'
START WITH snapshotfilename NOT IN (SELECT clonefilename FROM v$clonedfile)
CONNECT BY LOWER(clonefilename) = PRIOR (snapshotfilename);
その出力は次のようになります。
PARENT CHILD
-------------- ---------------
PARENT_PDB CHILD_PDB
CHILD_PDB G_CHILD_PDB1
G_CHILD_PDB2
また、CHILD_PDB が PARENT_PDB の子であり、G_CHILD_PDB1と G_CHILD_PDB2 が CHILD_PDB の子であることを示しています。
リソースと参考資料
上記に加えて、次のことが役立つ場合があります。
Exadata System Software ユーザーガイド-第2章-Exadata での Oracle ASM の管理
Exadata System Software ユーザーガイド-第9章-Exadataスナップショットの設定
ブログ投稿:ExadataのASMクラスターファイルシステムスナップショット
Exa-Byte:OEDACLIを使用してASMディスクグループを作成する
結論
ついに結論に到達しました!私たちは何を学びましたか?まず、Sparse PDB Clone の作成の概要を説明しました。最初は+DATAC1ディスクグループの通常のPDBから、次にその1つからさらに2つの階層的な Sparse PDB Clone を作成しました。データベースクローンは、あらゆる種類の開発とテストのユースケースに役立ちます。特に、Exadataの機能(スマートスキャン、バックアップのオフロード、ストレージインデックス、フラッシュ、永続メモリのキャッシュなど)がすべて利用可能であることが分かると思います 。
投稿の冒頭で述べたように、これはExadataでクローンを作成する1つの方法にすぎません。今後の投稿では、フルデータベース・スパース・クローン、ACFSスナップショット、およびデータベースクローンに関連するその他の興味深い機能について説明します。どんな点により興味がありますか?ギャビン@GavinAtHQと私@alex_blythにお知らせください。
