※本ページは、”Modern Oracle Database Workloads Need More Than General-Purpose Infrastructure“の翻訳です。
AI、分析処理、そしてエンタープライズデータが求める要件に、汎用インフラストラクチャは対応できるのでしょうか?
簡単に答えるなら、「場合によるが、多くの場合はかなりの追加対策が必要」です。サーバーを増やし、チューニングを重ね、キャッシュを追加し、ネットワーク設計を最適化し、運用調整を行い、そして時には非常に忍耐強いエンジニアの力も必要になります。
エンタープライズデータベースを取り巻く環境は、数年前と比べて大きく変化しています。もはや、注文処理やレコード更新といった単独のトランザクションシステムを支えるだけの存在ではありません。
現在では、同じデータベース環境が、OLTP、分析処理、AIパイプライン、ベクトル検索、レポーティング、さらには継続的なアプリケーションアクセスを同時に支える必要があります。そして、それらすべてを実現しながら、予測可能な性能を維持し、スムーズにスケールし、ビジネスのために高可用性を確保しなければなりません。
私自身は、これを次のように考えています。汎用インフラストラクチャは、多目的なオフィスビルのようなものです。さまざまな業務を収容できます。しかし、ある日突然、大規模なトレーディングフロア、研究所、放送スタジオ、そしてデータセンターを同時に運営しなければならなくなったらどうでしょうか。その建物には、用途に特化した設計が必要になってきます。
エンタープライズデータベースは、まさにその段階に到達しています。ワークロードがもはや汎用的ではない以上、インフラストラクチャも汎用的なものとして扱うことはできません。
この変化によって、インフラストラクチャの役割そのものが変わりつつあります。一般的なクラウド環境やオンプレミス環境では、需要の増加に対してCPUコア、メモリ、帯域幅、キャッシュレイヤー、分散サービスなど、あらゆるリソースを追加することで対応します。
こうした追加は確かに処理能力を向上させますが、根本的な非効率を解消するわけではありません。データは依然として、コンピュート、ストレージ、ネットワーク、キャッシュといった分離されたレイヤー間を何度も移動しなければなりません。小規模な環境では問題にならなくても、エンタープライズ規模になると、それはバトンの受け渡しごとに時間が失われるリレー競技のような状態になりかねません。
ここからが本題です。重要なのは、「汎用インフラストラクチャではOracle Databaseを実行できない」という話ではありません。実際、多くの企業がその方法で運用しています。
本当に問うべきなのは、ユーザーの同時接続数、分析処理、AI主導のアクセスパターンが拡大していく中で、ワークロードの応答性、一貫性、可用性を維持するために何が必要なのかということです。多くの環境では、サービスレベルを維持するために、さらなるチューニング、ワークロードの分離、インフラの拡張、そしてデータベース、サーバー、ストレージ、ネットワーク各チーム間の綿密な調整が求められます。
そこでExadataの出番となります。Exadataは、たまたまOracle Databaseを実行できる汎用インフラとして設計されたわけではありません。エンタープライズ規模のOracle Database運用を前提に構築された、データベース認識型(Database-Aware)のプラットフォームです。
Exadataは、データベース基盤がデータベースの動作を理解すべきであるという考え方から設計されています。
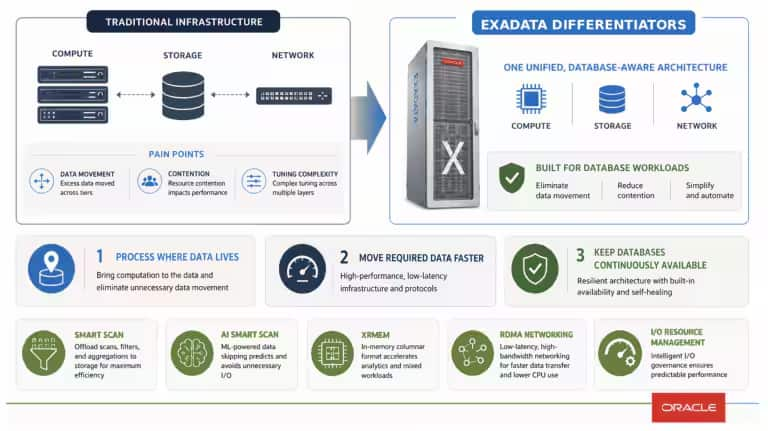
コンピュート、ストレージ、ネットワーク、メモリを、それぞれ独立したコンポーネントとして後から連携させるのではなく、Exadataはそれらを単一のデータベース認識型プラットフォームとして統合しています。その目的は明確です。Oracle Databaseが不要なデータ処理を減らし、システム内で移動するデータ量を削減し、負荷が高い状況でも重要なワークロードを安定して実行できるようにすることです。
汎用インフラストラクチャは限界に直面し始める理由
簡単に言えば、汎用インフラストラクチャは柔軟性を重視して、コンピュート、ストレージ、ネットワークを分離しています。このモデルは多くのアプリケーションに適しており、幅広い用途に対応できます。
しかしながら、データベースは単にインフラの上で静かに動作する一つのアプリケーションではありません。データベースは常に、読込み、書込み、ロック、メモリ管理、キャッシュ、ログ、クエリ処理、バックアップ、リカバリ、そしてユーザーの同時アクセスを調整し続けています。言い換えれば、データベースは建物全体を常に稼働させ続ける存在なのです。
汎用インフラストラクチャや一般的なクラウドアーキテクチャでは、コンピュート、ストレージ、ネットワークが独立したレイヤーとして分離されています。この設計は柔軟性が高く、多様なアプリケーションへの適用が可能ですが、大規模なOracle Database環境にとって必ずしも最適とは限りません。
データベース性能は、個々のコンポーネントの性能だけで決まるものではありません。CPUコア数の増加、ストレージスループットの向上、ネットワーク帯域の拡張は確かに効果がありますが、それらはシステム全体が実際のワークロード負荷の下で効率的に連携できる場合に限られます。
各レイヤーが独立して動作する環境では、性能向上の手段として効率化よりもリソース増強が選ばれることが少なくありません。その結果、より多くのインフラ、より多くのチューニング、より多くの運用調整が必要となり、場合によってはコストだけが増加して根本的なボトルネックが解消されないこともあります。
Exadataは、このモデルを変革し、データベースを理解するインテリジェンスをプラットフォームそのものに組み込んでいます。
Smart Scanは、データ集約型のSQL処理の一部をインテリジェントなExadataストレージへオフロードします。RoCE(RDMA over Converged Ethernet)は、データベースサーバーとストレージサーバー間の通信に低レイテンシのネットワークファブリックを提供します。Exadata RDMA Memory(XRMEM)は、このファブリックを利用して、ストレージサーバー上のDRAMに保持された最もアクセス頻度の高いデータへのアクセスを高速化します。また、I/O Resource Management(IORM)は、ビジネス上の重要度に応じてデータベースワークロードの優先順位を制御します。
より簡単に言えば、Exadataは単にOracle Databaseに高速なハードウェアコンポーネントを提供しているのではありません。Oracle Databaseが何を実行しようとしているのかを理解するインフラストラクチャ層を提供しているのです。
これらは、Exadataが備える数多くの技術革新のほんの一例に過ぎません。重要なのは、これらの機能がデータベースの周囲に後付けされた個別のオプションではないということです。これらはプラットフォームに組み込まれており、Exadataはスタック全体を通じてデータベース処理を最適化できるよう設計されています。
Exadataをアーキテクチャ面で差別化している点
大まかに言えば、Exadataのアーキテクチャは、次の3つの繰り返し登場する考え方を軸に捉えると理解しやすくなります。
- データが存在する場所の近くで処理を実行
- 最も頻繁に利用されるデータへのアクセスを高速化
- 多様なワークロードが混在する大規模環境においても、予測可能な性能と可用性を維持
Exadataの主要な機能の多くは、これらの考え方のいずれか、あるいは複数に結び付いています。そして、これらの原則が組み合わさることで、Exadata System Softwareおよび運用インテリジェンスが基盤ハードウェアを補完し、その能力を最大限に引き出す仕組みが形作られています。
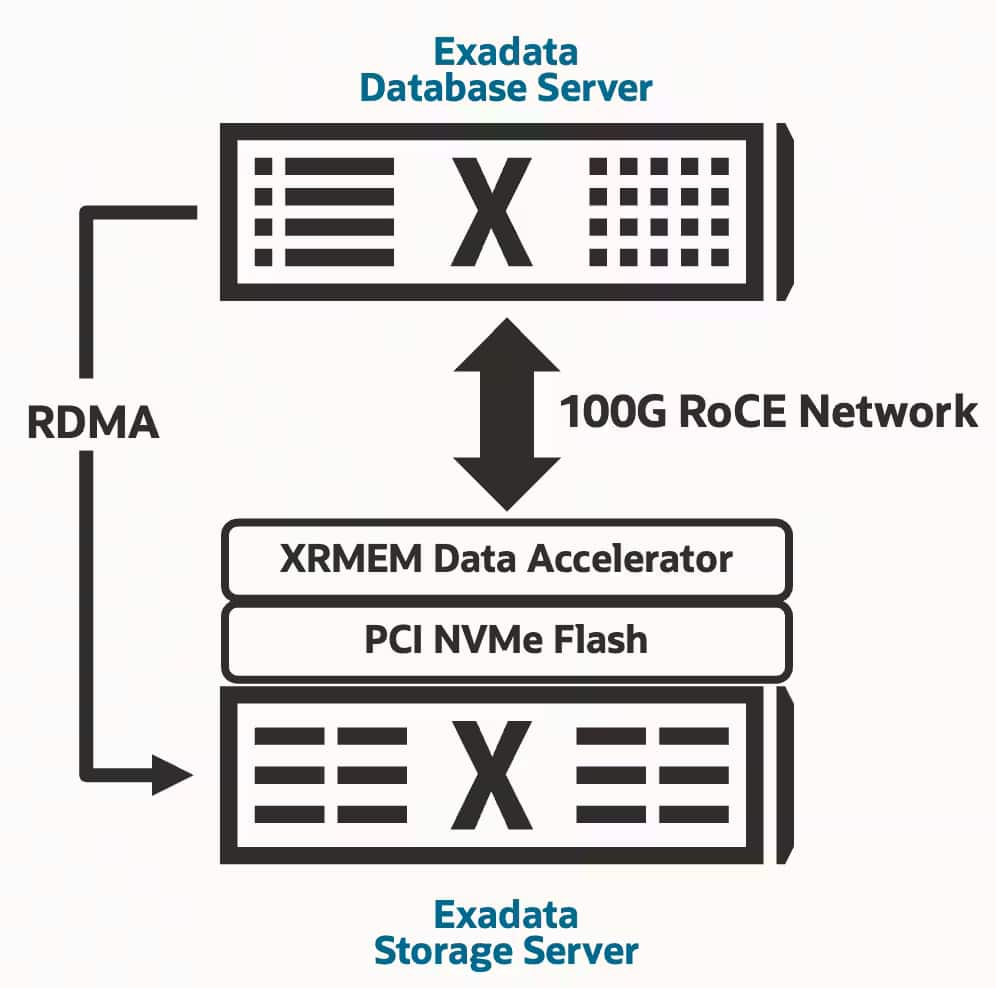
Exadataは、データベースコンピュートとインテリジェントストレージの両方を、高速かつ低レイテンシなデータベース専用ネットワーク上でスケールアウトできるアーキテクチャを採用しています。
この違いは非常に重要です。従来のストレージアーキテクチャでは、ストレージを追加すると通常は容量、IOPS、またはスループットが増加します。しかしExadataでは、ストレージを追加することで、インテリジェントなSQLオフロード処理能力、キャッシュ機能、そしてストレージ層そのものにおけるワークロード高速化能力も同時に増強されます。
つまり、プラットフォームは単に大きくなるだけではありません。スケールするほど、より高機能になるのです。
また、ExadataはRoCEネットワークファブリックを活用し、共有メモリおよびフラッシュベースの高速化モデルを実現しています。XRMEM(Exadata RDMA Memory)は、Exadataストレージサーバー上のDRAMをRDMA経由でアクセス可能な高速化レイヤーとして利用し、最も頻繁にアクセスされるデータを保持します。これはExadata Smart Flash Cacheを補完する役割を果たします。
より平易に言えば、Exadataは頻繁に利用されるデータに対して、データベースクラスタ全体で共有できる非常に高速なアクセラレーションレイヤーを提供します。そのため、性能を個々のサーバーに閉じたローカルキャッシュだけに依存する必要がありません。
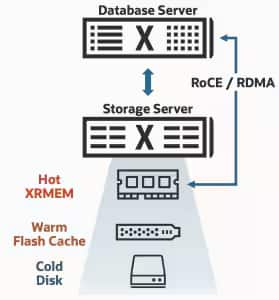
Smart Flash Cacheは、頻繁にアクセスされるデータをフラッシュストレージ上に保持します。一方、Exadata System Softwareは、メモリ、フラッシュ、および大容量ストレージ間でのデータ配置を管理します。その結果、プラットフォーム全体で統合されたキャッシュおよび階層化(ティアリング)モデルが実現され、データベースクラスタはシステム全体を通じてホットデータへ効率的にアクセスできるようになります。
「データ移動を減らす」というExadataの考え方が最も効果を発揮するのが分析処理(Analytics)です。
分析クエリは大量のデータを対象とすることが多いため、パフォーマンスはシステム内を移動しなければならないデータ量をどれだけ削減できるかに大きく依存します。Exadataはストレージを単なる汎用ブロックI/O装置として扱うのではなく、Smart Scanによってデータベースを理解したインテリジェントな処理をストレージサーバー上で実行します。
Smart Scanは、対象となるデータに対してフィルタリングや処理をストレージサーバー上で実施し、その結果だけをデータベースノードへ返すことができます。クエリ実行に必要な行と列のみを返すことで、ネットワークトラフィックを削減し、データベースサーバーのCPU使用率を低減するとともに、クエリ処理効率を向上させます。
この考え方は、AI Smart ScanによってAIワークロードにも拡張されています。
AIベクトル検索では、企業内の大規模データに対して膨大な比較処理が必要になることがあります。もし候補となるすべてのベクトルデータをデータベースサーバーへ転送してからフィルタリングや評価を行うと、システムは大量の不要なデータ移動を強いられることになります。
AI Smart Scanは、データ量と計算量の多いAIベクトル検索処理をインテリジェントなExadataストレージへオフロードすることで、この問題を回避します。大量の候補データをデータベースサーバーへ転送して処理する代わりに、Exadataはインテリジェントストレージおよびキャッシュアーキテクチャを活用し、データが存在する場所の近くでより多くのベクトル検索処理を実行できます。
つまりExadataは、長年SQL分析処理に適用してきた原則をAI検索にも適用しているのです。すなわち、「データの近くでより多くの処理を実行し、システム内を移動するデータ量を減らす」という考え方です。
ミッションクリティカルなOLTPワークロードに対しては、ExadataのRDMA対応メモリアーキテクチャがホットデータへの読込みレイテンシを低減します。XRMEMはExadataストレージサーバー全体に配置されたDRAMを利用するため、システム内のデータベースインスタンスは共有された大規模なメモリ高速化レイヤーの恩恵を受けることができます。
重要なのは、価値の源泉が単なるRDMA技術そのものではないという点です。RDMAは、ExadataのSQLオフロード機能、インテリジェントキャッシング、そしてデータベース認識型リソース管理と組み合わされることで真価を発揮します。これらの機能は相互に連携するよう設計されており、その統合された動作こそがExadataの大きな価値となっています。
この統合された階層化(ティアリング)戦略は、インフラストラクチャの効率性向上とコスト管理にも貢献します。
DRAMやフラッシュは高価なリソースであるため、すべてのデータを最高性能のストレージ階層で扱いたいと考える組織はほとんどありません。データにはさまざまな特性があります。頻繁にアクセスされるホットデータもあれば、時々利用されるウォームデータもあります。また、必要になるまで静かに待機しているコールドデータもあります。
Exadataは、XRMEM、フラッシュ、および大容量ストレージ間でデータ配置のバランスを最適化します。その結果、頻繁にアクセスされるデータやレイテンシに敏感なデータはメモリやフラッシュの高速アクセスの恩恵を受ける一方で、アクセス頻度の低いデータはより低コストなストレージに保持されます。分析処理やAI主導のワークロードによってデータ量が急速に増加する一方で、すべてのデータが同じレベルの性能を必要とするわけではありません。このような環境において、こうしたバランスの取れたデータ配置戦略の重要性はますます高まっています。
混在ワークロードをどのようにExadataが制御するのか
1つの重要なワークロードを安定して実行するだけでも十分に難しい課題です。複数の重要なワークロードを同時に実行するとなると、その難しさはさらに増します。
エンタープライズ環境では、トランザクションシステム、レポーティング、分析処理、バッチジョブ、さらにはAI関連処理が、互いに干渉することなく同じインフラストラクチャを共有する必要があります。そのため、リソース管理は単なる付加機能ではなく、不可欠な要素となります。
Exadataは、統合されたデータベースリソース管理、ワークロード制御、およびリソース優先順位付けによって、混在ワークロード環境を管理するよう設計されています。Database Resource ManagerおよびIORM(I/O Resource Management)は、重要なワークロードを優先し、「ノイジーネイバー(他ワークロードによる性能干渉)」の影響を軽減し、統合環境全体で予測可能なサービスレベルを維持するのに役立ちます。
こうした一貫した性能管理は、組織がより多くのデータベースやワークロードを少ないシステムへ統合できる理由の一つです。その結果、運用負荷を削減しながら、リソース利用効率を向上させることができます。
もちろん、汎用アーキテクチャでも高可用性を実現することは可能です。ただし、そのためには複数のレプリケーション技術、フェイルオーバープロセス、データ同期、ワークロード配置、インフラチューニングなどを個別に調整する必要がある場合が少なくありません。
環境がハイブリッドクラウドやマルチクラウドへ広がるにつれて、その調整作業自体が専任業務になってしまうこともあります。
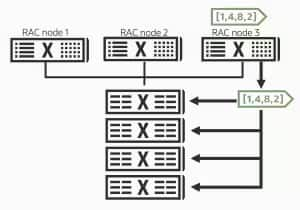
Exadata Database Machine、Exadata Cloud@Customer、およびExadata Database Serviceでは、Oracle Real Application Clusters(RAC)をExadataのエンジニアドシステム上で実行できます。複数のデータベースインスタンスが相互接続されたデータベースサーバー上で稼働しながら、共有のExadataストレージへアクセスできます。
RACは、複数サーバーにまたがるデータベース処理のスケールアウトと、データベースサーバー障害時の可用性向上を実現します。さらに、Exadataのストレージミラーリング機能と単一障害点(Single Point of Failure)を排除した設計により、高可用性がさらに強化されています。
ここには実務的なビジネス上の利点もあります。
Exadataの重要な経済的メリットの一つは、統合(Consolidation)です。より多くのワークロードを少数のExadataシステムへ集約することで、導入、電力供給、冷却、パッチ適用、監視、保守が必要なハードウェアの台数を削減できます。
また、ライセンスモデルや導入設計によっては、統合とストレージオフロードによってソフトウェアライセンス効率を向上させることも可能です。より少ないライセンス対象データベースサーバーコアで、より多くの処理を実行できる場合があるためです。
さらに、Exadataの高可用性機能は、わずかな停止であっても大きなビジネス影響が発生する環境において、ダウンタイムに伴う運用上および経済上の損失を軽減することにも貢献します。
Oracle Databaseがどこで稼働していても、同じExadataアーキテクチャを利用可能
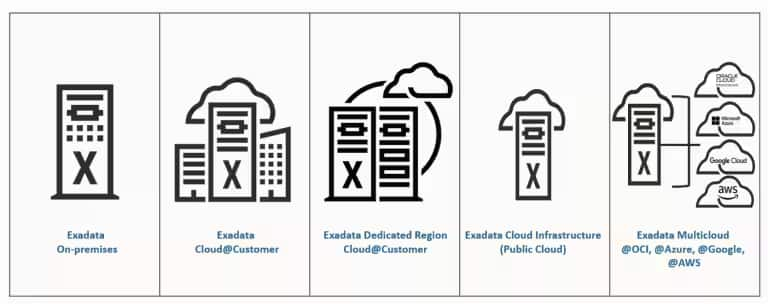
関連してよくある質問の一つに、「Exadataはオンプレミス専用のアーキテクチャなのか」というものがあります。
答えは「いいえ」です。Exadataは、オンプレミス環境、OCI(Oracle Cloud Infrastructure)、Exadata Cloud@Customer、さらにはMicrosoft Azure、Google Cloud、AWSとのマルチクラウド・データベースサービスに至るまで、一貫したOracle Databaseアーキテクチャを提供しています。
これにより、顧客は共通のExadata基盤を利用しながら、Oracle Databaseワークロードをアプリケーション、ユーザー、クラウドサービスの近くに配置することができます。導入形態は変わっても、その根本的なアーキテクチャの考え方は変わりません。すなわち、Oracle DatabaseがExadataのデータベース認識型コンピュート、インテリジェントストレージ、RDMA対応メモリアクセス、およびワークロード制御機能を最大限活用できるよう最適化されているということです。
まとめ:Exadataはエンタープライズ・データベース・ワークロードのために設計
要点は非常にシンプルです。現代のデータベースワークロードには、データベースの動作を理解するインフラストラクチャが必要だということです。
企業がOLTP、分析処理、AI、そして統合されたエンタープライズ環境を拡大していく中で、効率性を実現するためには、不要なデータ移動を削減し、ホットデータへのアクセスを高速化し、リソースをインテリジェントに優先制御し、負荷が高い状況でも可用性を維持することが重要になります。
Exadataは、まさにこれらの原則を中心に設計されています。データベース認識型コンピュート、インテリジェントストレージ、RDMA対応メモリアクセス、Smart ScanによるSQLオフロード、AI Smart Scan、そして統合リソース管理機能により、オンプレミス、クラウド、マルチクラウドのいずれの導入形態においても、Oracle Databaseに一貫したエンジニアド基盤を提供します。
汎用インフラストラクチャは、多種多様なワークロードを適切に実行できます。しかし、要求の厳しいOracle Databaseワークロードに対して、Exadataにはより明確な使命があります。それは、データベースが不要な処理を減らし、不要なデータ移動を減らし、ビジネスクリティカルなアプリケーションを大規模環境でも予測可能な性能で稼働させ続けることです。
だからこそ、性能、可用性、統合性、そして運用の一貫性が重視されるOracle Database環境において、Exadataは今なお魅力的なアーキテクチャ選択肢であり続けているのです。
