Can general-purpose infrastructure keep up with what AI, analytics, and enterprise data now demand?
The simple answer is: sometimes, but usually with a lot of extra help. More servers, more tuning, more caching, more network planning, more operational coordination, and occasionally a few very patient engineers.
Enterprise databases are operating in a very different environment than they were just a few years ago. They are no longer just supporting isolated transactional systems that process orders, update records, and call it a day.
Today, the same database environment may need to support OLTP, analytics, AI pipelines, vector search, reporting, and continuous application access at the same time. It has to do all of that while keeping performance predictable, scaling cleanly, and staying available for the business.
My simple mental model is this: general-purpose infrastructure is like a very capable office building. You can host many kinds of work in it. But if you suddenly need a high-volume trading floor, a research lab, a broadcast studio, and a data center operating together, the building starts needing purpose-built design.
Enterprise databases have reached that point. The workload is no longer generic, so the infrastructure cannot be treated as generic either.
This shift changes the role of infrastructure. General-purpose cloud and on-premises architectures typically respond to growing demand by adding more of everything: more CPU cores, more memory, more bandwidth, more caching layers, and more distributed services.
Those additions can increase capacity, but they do not necessarily remove the underlying inefficiency. Data still has to move repeatedly across separate compute, storage, networking, and caching tiers. At small scale, that may be manageable. At enterprise scale, it can start to look like a relay race where every handoff costs time.
This is where the discussion gets interesting. The point is not that general-purpose infrastructure cannot run Oracle Database. It can, and many organizations do exactly that.
The real question is what it takes to keep those workloads responsive, consistent, and available as user concurrency, analytics, and AI-driven access patterns expand. In many environments, maintaining service levels requires more tuning, more workload isolation, more infrastructure expansion, and more coordination across database, server, storage, and network teams.
That is where Exadata enters the picture. It was not built as generic infrastructure that simply happens to run Oracle Database. It was built as a database-aware platform designed specifically for Oracle Database at enterprise scale.
Exadata starts from a different assumption: database infrastructure should understand database behavior.
Instead of treating compute, storage, networking, and memory as separate pieces that need to be coordinated after the fact, Exadata brings them together as one database-aware platform. The goal is simple: help Oracle Database process less unnecessary data, move less data across the system, and keep critical workloads steady under pressure.
Why General-Purpose Infrastructure Starts to Strain
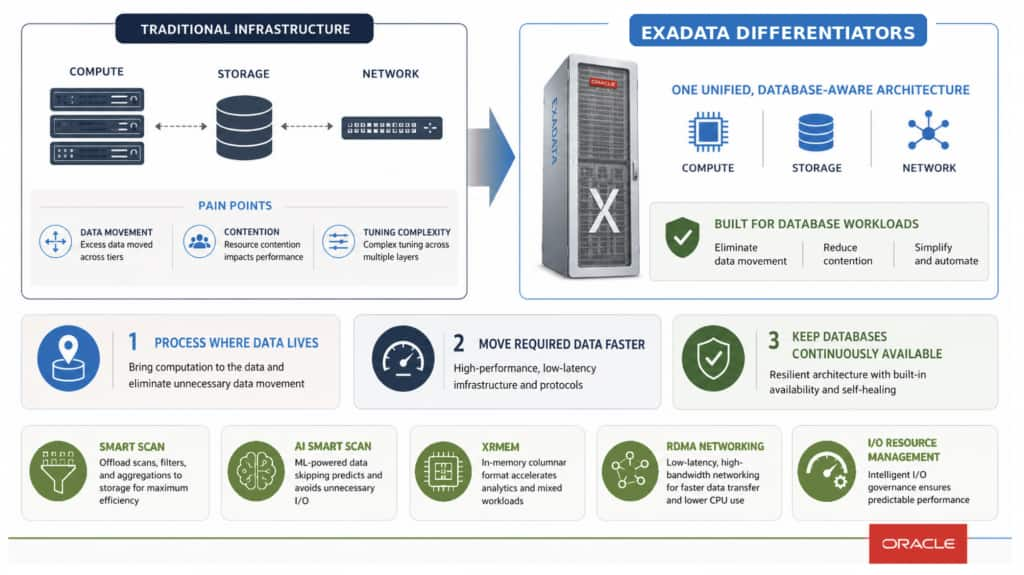
Here is the simplified view: general-purpose infrastructure separates compute, storage, and networking because that model is flexible. It works well for many applications.
Databases, however, are not just another application sitting politely on top of infrastructure. They are constantly coordinating reads, writes, locks, memory, cache, logs, queries, backups, recovery, and user concurrency. In other words, they keep the whole building busy.
General-purpose infrastructure and conventional cloud architectures usually separate compute, storage, and networking into independent layers. That design provides flexibility and broad application compatibility, but it is not always ideal for large-scale Oracle Database environments.
Database performance is not determined by component capacity alone. More CPU, more storage throughput, or more network bandwidth can help, but only if the overall system coordinates efficiently under real workload pressure.
When each layer operates independently, performance improvements often come from expansion rather than efficiency. That can mean more infrastructure, more tuning, more operational coordination, and sometimes more cost without fully removing the bottleneck.
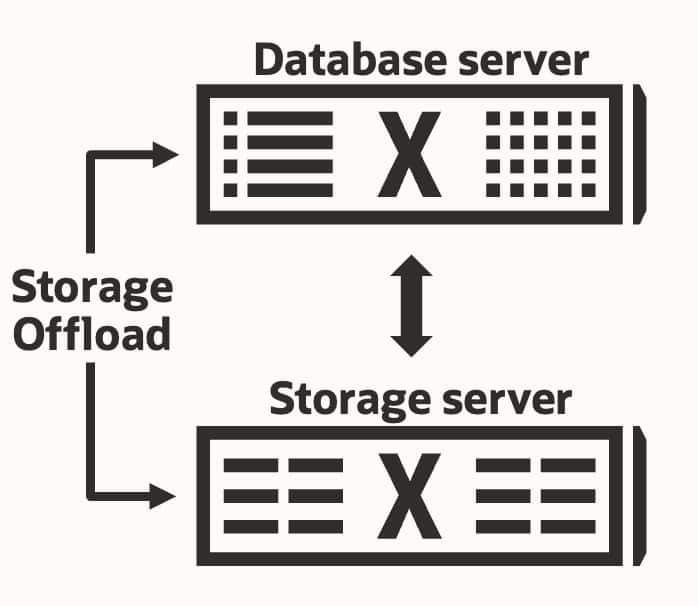
Exadata changes that model by putting database-aware intelligence directly into the platform.
Smart Scan moves selected data-intensive SQL processing into intelligent Exadata storage. RoCE provides a low-latency network fabric for database and storage communication. Exadata RDMA Memory, or XRMEM, uses that fabric to accelerate access to the hottest data in DRAM on storage servers. I/O Resource Management, or IORM, prioritizes database workloads according to business importance.
Put more simply: Exadata is not just giving Oracle Database faster components. It is giving Oracle Database an infrastructure layer that understands what the database is trying to do.
These are only a few examples from a much larger set of Exadata innovations. The important point is that these capabilities are not separate add-ons bolted around the database. They are built into the platform so Exadata can optimize database operations across the full stack.
What Makes Exadata Architecturally Different
At a high level, Exadata’s architecture is easier to understand if you think about three recurring ideas.
- Process data closer to where it lives.
- Accelerate access to the most frequently used data.
- Maintain predictable performance and availability under mixed-workload scale.
Most of Exadata’s major capabilities connect back to one or more of those ideas. Together, these principles shape how Exadata System Software and operational intelligence augment the underlying hardware.
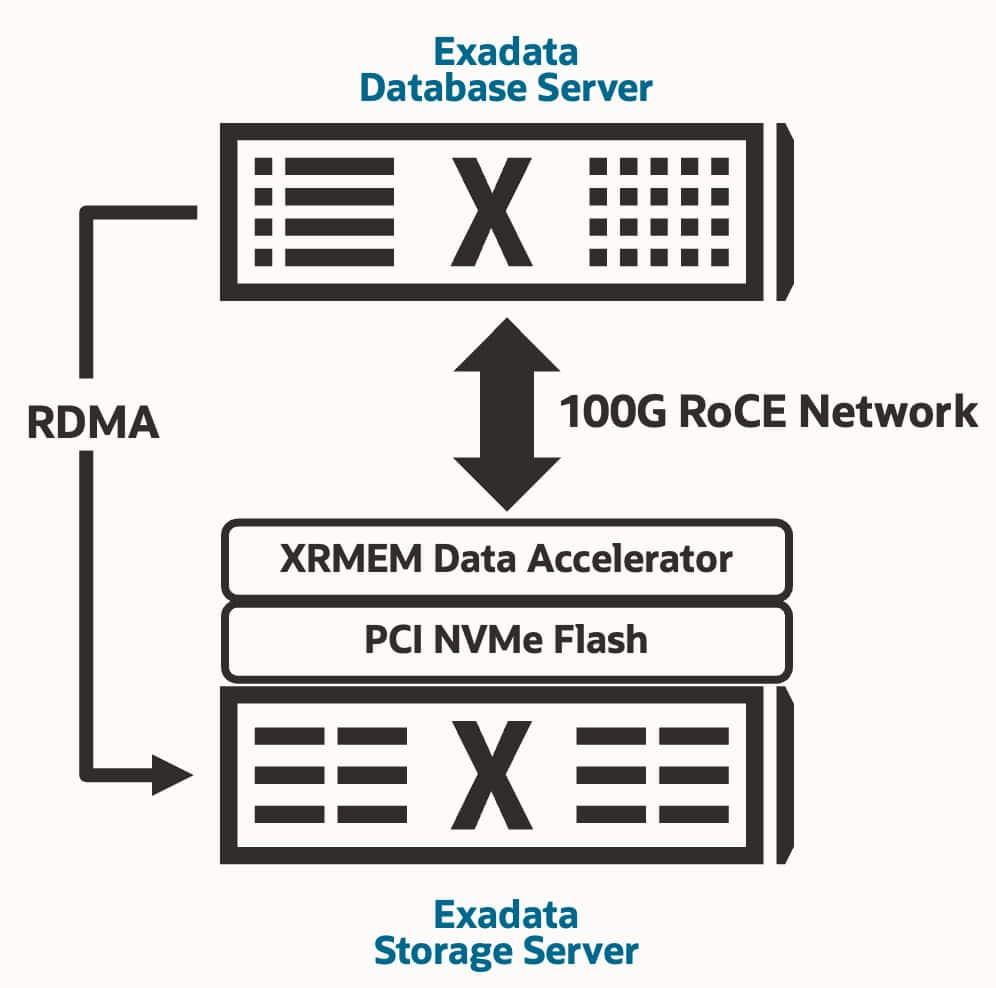
Exadata uses a scale-out architecture that expands both database compute and intelligent storage over a high-speed, low-latency network designed for database operations.
This distinction matters. In conventional storage architectures, adding storage usually gives you more capacity, IOPS, or throughput. In Exadata, adding storage also adds more intelligent SQL offload processing, more caching intelligence, and more workload acceleration inside the storage layer itself.
So the platform does not just get bigger. It gets more capable as it scales.
Exadata also uses its RoCE network fabric to support a shared memory-and-flash acceleration model. XRMEM uses DRAM in Exadata storage servers as an RDMA-accessible acceleration tier for the hottest data, complementing Exadata Smart Flash Cache.
In plain terms, Exadata gives the database cluster a very fast shared acceleration layer for frequently used data, instead of making performance depend only on isolated server-local caches.
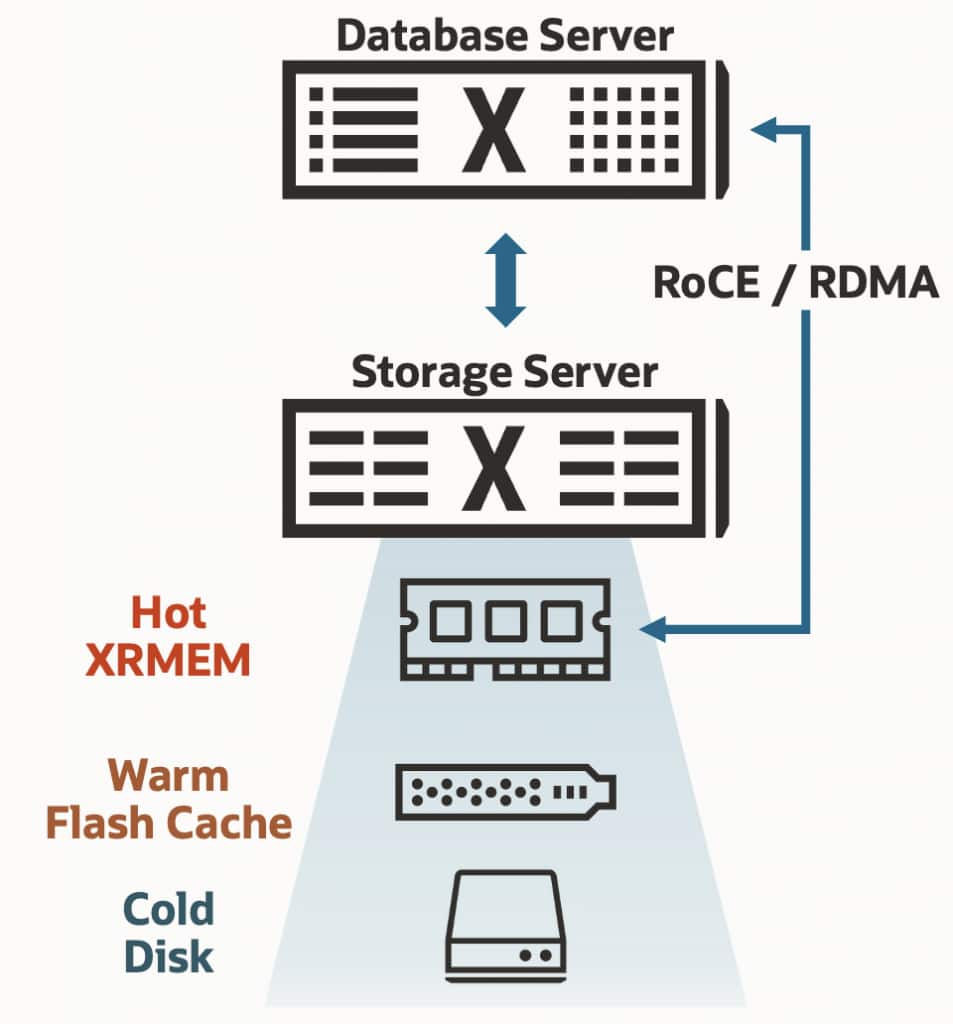
Smart Flash Cache keeps frequently accessed data on flash, while Exadata System Software manages data placement across memory, flash, and capacity storage. The result is a coordinated platform-level caching and tiering model that helps the database cluster access hot data efficiently across the system.
Analytics is where the “move less data” idea really shows up.
Analytical queries often operate across large volumes of data, so performance depends heavily on minimizing how much data must move through the system. Instead of treating storage as generic block I/O, Exadata uses Smart Scan to apply database-aware intelligence directly on storage servers.
Smart Scan can filter and process eligible data before returning results to database nodes. By returning only the rows and columns required for query execution, Smart Scan reduces network traffic, lowers database-server CPU utilization, and improves query efficiency.
The same idea now extends into AI workloads through AI Smart Scan.
AI vector search can require large-scale comparisons across enterprise data. If every candidate vector has to travel back to the database servers before useful filtering happens, the system does a lot of unnecessary hauling.
AI Smart Scan helps avoid that by offloading data- and compute-intensive AI Vector Search operations to intelligent Exadata storage. Instead of moving large volumes of candidate data back to database servers for processing, Exadata can perform more of the vector search work close to where the data resides, using the platform’s intelligent storage and caching architecture.
Exadata is applying the same principle to AI search that it has long applied to SQL analytics: process more near the data and move less across the system.
For mission-critical OLTP workloads, Exadata’s RDMA-enabled memory architecture helps reduce read latency for hot data. Because XRMEM uses DRAM across Exadata storage servers, database instances across the system can benefit from an aggregate memory acceleration tier.
The important point is that the advantage is not RDMA by itself. It is RDMA combined with Exadata’s SQL offload, intelligent caching, and database-aware resource management. The pieces are designed to work together, which is where much of the value comes from.
This coordinated tiering strategy also improves infrastructure efficiency and cost management.
DRAM and flash are premium resources, so most organizations do not want to treat every byte of data as if it needs the most expensive performance tier. Some data is hot. Some data is warm. Some data is politely waiting in the background until someone needs it.
Exadata balances data placement across XRMEM, flash, and capacity storage so frequently accessed and latency-sensitive data can benefit from memory-speed and flash-speed access, while colder data remains on lower-cost storage. That balance becomes increasingly important as analytics and AI-driven workloads expand data volumes without making every byte equally performance sensitive.
How Exadata Keeps Mixed Workloads Under Control
Running one important workload well is hard enough. Running many of them together is where things get interesting.
Enterprise environments often need transactional systems, reporting, analytics, batch jobs, and AI-related processing to share infrastructure without stepping on each other. That is where resource management becomes more than a nice-to-have.
Exadata is designed to manage mixed workloads through integrated database resource management, workload coordination, and resource prioritization. Database Resource Manager and IORM help prioritize critical workloads, reduce noisy-neighbor impact, and maintain predictable service levels across consolidated environments.
That consistency is one reason organizations can consolidate more databases and workloads onto fewer systems while reducing operational overhead and improving resource utilization.
General-purpose architectures can absolutely support high availability. The catch is that they often require more coordination across separate replication technologies, failover processes, synchronization, workload placement, and infrastructure tuning.
As environments spread across hybrid and multicloud deployments, that coordination can become its own full-time workload.
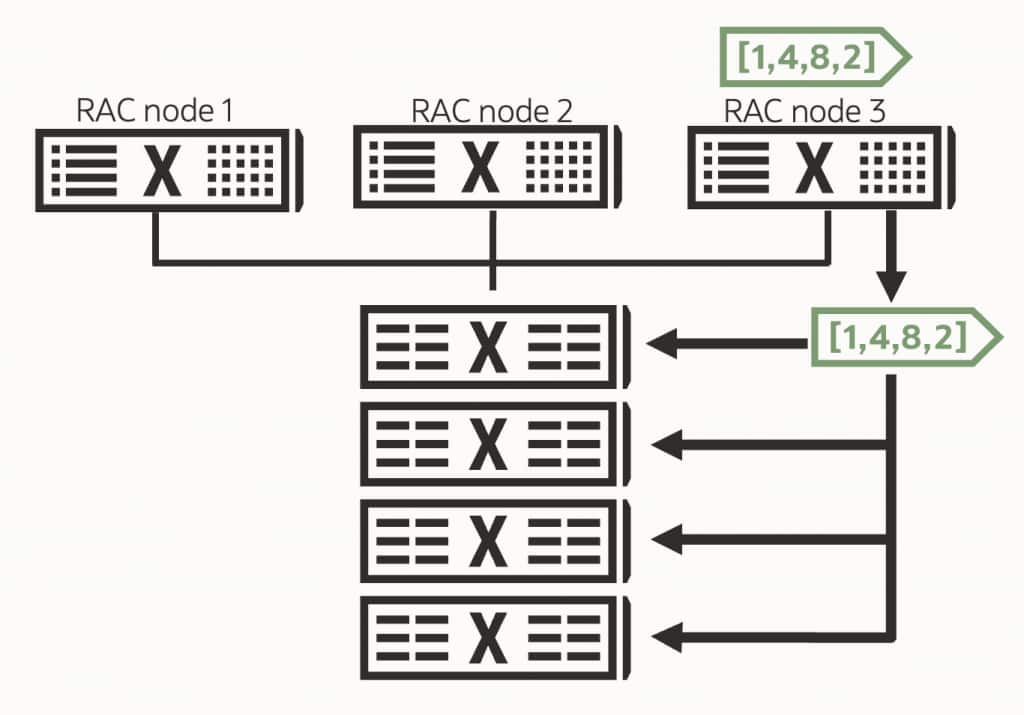
In Exadata Database Machine, Exadata Cloud@Customer, and Exadata Database Service deployments, Oracle Real Application Clusters, or RAC, can run on Exadata’s engineered platform. Multiple database instances can operate across interconnected database servers while accessing shared Exadata storage.
RAC helps scale database processing across servers and protect against database server failures, while Exadata’s storage mirroring and no-single-point-of-failure design further support high availability.
There is also a practical business angle here.
A key economic benefit of Exadata comes from consolidation. By running more workloads on fewer Exadata systems, organizations can reduce the hardware they need to deploy, power, cool, patch, monitor, and maintain.
Depending on the licensing model and deployment design, consolidation and storage offload can also improve software licensing efficiency by allowing more work to be performed on fewer licensed database server cores. The platform’s high availability capabilities can also reduce the operational and financial impact of downtime in environments where even brief interruptions can have significant business consequences.
The Same Exadata Architecture, Wherever Oracle Database Runs
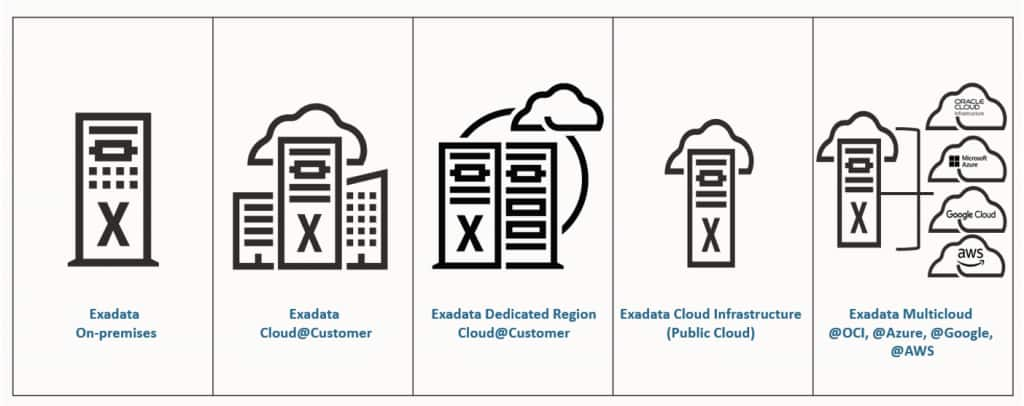
A related question is whether Exadata is only an on-premises architecture.
The answer is no. Exadata provides a consistent Oracle Database architecture across on-premises deployments, OCI, Exadata Cloud@Customer, and Oracle’s multicloud database services with Microsoft Azure, Google Cloud, and AWS.
That gives customers a common Exadata foundation while allowing them to place Oracle Database workloads closer to applications, users, and cloud services. The deployment model may change, but the architectural idea stays the same: Oracle Database is optimized to take advantage of Exadata’s database-aware compute, intelligent storage, RDMA-enabled memory access, and workload coordination.
The Takeaway: Exadata Is Built for Enterprise Database Workloads
The main point is simple: modern database workloads need infrastructure that understands database behavior.
As organizations scale OLTP, analytics, AI, and consolidated enterprise environments, efficiency depends on reducing unnecessary data movement, accelerating access to hot data, prioritizing resources intelligently, and maintaining availability under pressure.
Exadata was built around those principles. Its database-aware compute, intelligent storage, RDMA-enabled memory access, Smart Scan offload, AI Smart Scan, and integrated resource management give Oracle Database a consistent engineered foundation across on-premises, cloud, and multicloud deployment models.
General-purpose infrastructure can run many things well. But for demanding Oracle Database workloads, Exadata has a more focused job: help the database do less unnecessary work, move less unnecessary data, and keep business-critical applications running predictably at scale.
That is why Exadata remains a compelling architectural choice for Oracle Database environments where performance, availability, consolidation, and operational consistency matter.
