※ 本記事は、Omar Awileによる”Effectively benchmarking OCI Compute Shapes for LLM inference serving“を翻訳したものです。
2025年7月10日
概要
生成AIモデルの急速な進化には目を見張るものがあり、毎週のように新しく強力なモデルが登場しています。2019年にOpenAIのGPT-2がリリースされて以来、その数は爆発的に増え、現在までに50以上のモデルが発表されています(図1)。パラメータ数の多さで限界に挑み続けるモデルもあれば、効率性と汎用性を優先するモデルもあります。モデル・ファミリが多様化し、特定のユース・ケースおよびハードウェア・プラットフォームに合せた複数のバリアントが提供されるようになっています。MetaのLlamaモデル・ファミリを例にとります。3.2 リリースでは、コンパクトな10億パラメータLLMや30億パラメータ・バリアントなどのオプションが提供されています。さらに、Llama 3.2には、110億と900億のパラメータを持つ2つのビジョン言語モデル(VLM)もあります。
図1: ベンダーによって分割された時間の経過に伴うLLMモデルの相対サイズ
モデル・アーキテクチャの爆発と並行して、より広範なAIソフトウェア・エコシステムは大幅に成熟しています。少し前までは、推論のためにAIモデルを導入するには、必要なソフトウェア・スタックを組み立てるための簡単な作業が必要でした。しかし、今日では、ツールとライブラリの豊富なコレクションが出現し、プロセスが合理化されています。これらのツールは多くの複雑さを解消し、モデルをアプリケーションにシームレスに統合し、開発者がインフラストラクチャの混乱ではなくビジネス上の問題の解決に集中できるようにします。
この新しい効率性はイノベーションの恩恵ですが、AIを活用したサービスでユーザーにサービスを提供するには、どのようなコンピュート・リソースが必要かという重要な疑問も生じます。
適切なハードウェア、特にOracle Cloud Infrastructure (OCI) GPUインスタンスで使用されるGPUプラットフォームなど、GPUプラットフォームの選択には、GPUメモリー要件などの表面レベルの見積り以上のものが含まれます。このような一次近似は出発点となりますが、情報に基づいた意思決定を行う最善の方法は、ターゲット・モデルを直接ベンチマークすることです。現在利用可能なツールとフレームワークにより、ベンチマークの実行は簡単なプロセスとなり、チームは実用的なパフォーマンス・データを収集し、特定のワークロードやユース・ケースに沿った意思決定を行うことができます。
OCIでの単純なLLM推論ベンチマーク・システムの設定
独自の推論ベンチマーク・ユーティリティを開発できますが、既存のいくつかのツールがこの目的に適しています。たとえば、fw-AI/benchmarkは、AIモデルのベンチマークを実行および分析するための簡単なソリューションです。もう一つの選択肢は、生成AIモデルの強力なパフォーマンス評価機能を提供するNVIDIA Dynamo Perf Analyzerです。
この項では、Ray LLMPerfに焦点を当てます。このツールは、OpenAI、Anthropic、Hugging Face、VertexAIなど、様々なバックエンドおよびAPIにわたるモデル・パフォーマンスのベンチマークを容易にします。Ray LLMPerfは、特定のバックエンドの異なるモデルを比較するのに十分な柔軟性があります。また、推論サーバーを介して提供している特定のモデルのパフォーマンスを評価できます。
ここに示す例では、Llama 3.2 3Bモデルのパフォーマンス特性の分析と、必要なパフォーマンスを提供できるOCI Computeシェイプの評価に関心があります。OCI Computeサービスは、様々な仮想マシン(VM)およびベア・メタル(BM)のハードウェア構成(シェイプと呼ばれます)を提供します。NVIDIA A10 GPUでは30億パラメータの大規模言語モデルが快適に収まる必要があるため、実験にはVM.GPU.A10.1シェイプを使用します。モデルのフロントエンドを提供するために、私たちは、数千の同時要求を効率的に処理し、幅広い大規模言語モデルをサポートする能力で知られている一般的なオープンソースの推論サーバーであるvLLMを使用します。ベンチマーク・システムの設定方法およびベンチマークの実行方法の詳細は、このチュートリアルを参照してください。
LLM推論のベンチマーク
ベンチマーク・システムを設定した後、ベンチマーク・シナリオを定義し、ベンチマークを実行する必要があります。大規模言語モデルを選択した特定のアプリケーション・シナリオについて、同時推論リクエストの実行のパフォーマンス特性について、ターゲット・システムで理解します。
表1に、実験パラメータの概要を示します。ここでは、最大32の同時リクエストをサポートする必要がある単純なクエリ回答チャットボットのパフォーマンスを測定することに興味があります。考慮すべき2つの重要なパラメータは、入力トークンと出力トークンの数で、問合せサイズと回答サイズを表します。これが問合せ応答チャットボットである場合、通常平均200個のトークンで配布される入力トークンの数を定義しますが、出力トークンの数は通常平均100個のトークンで配布されるように定義されます。
| パラメータ | 値 |
|---|---|
| 出力トークン | N(100, 10) |
| 入力トークン | N(200, 40) |
| ユース・ケース | chat |
| モデル | Meta Llama 3.2 3B Instruct |
| コンカレント要求 | 1 – 32 |
このシナリオでは、推論問合せを繰り返し実行し、関心のある様々なパフォーマンスの数値を測定できるようになりました:
- 1秒当たりのトークン当たりの問合せごとのトークン・スループット(TPS): モデルおよびシステム全体が問合せに応答する1秒当たりのトークンの割合。値が大きいほど、パフォーマンスが向上し、合理的なユーザー・エクスペリエンスを提供するレスポンシブ・システムは、少なくとも10から15のトークン/秒を提供する必要があります
- トークン当たりのシステム・トークン・スループット/秒: システムはリクエストを並行して処理できるため、システム・トークン・スループットによって示される、システムが維持できる最大同時実行性に関心があります。トークン・スループットの合計は、システムが同じレベルのパフォーマンスを維持できるかぎり、同時実行性の増加とともに拡張し続けます。
- 最初のトークンまでの時間(秒) (TTFT): 問合せと返される最初のトークンの間の待機時間。値が小さいほど、システムの応答性が向上します。リアルタイム推論では、通常、最初のトークンまでの時間には数秒のレイテンシしか許容できませんが、バッチ・シナリオでは、リアルタイムのユーザー・インタラクションがないため、最初のトークン・レイテンシまでの時間はそれほど重要ではありません。
結果の分析
前述のベンチマークの実行には、同時実行性レベルの増加を繰り返すため、時間がかかります。結果は、トークン・スループットとTTFTの両方がプロットされている図2で確認できます。
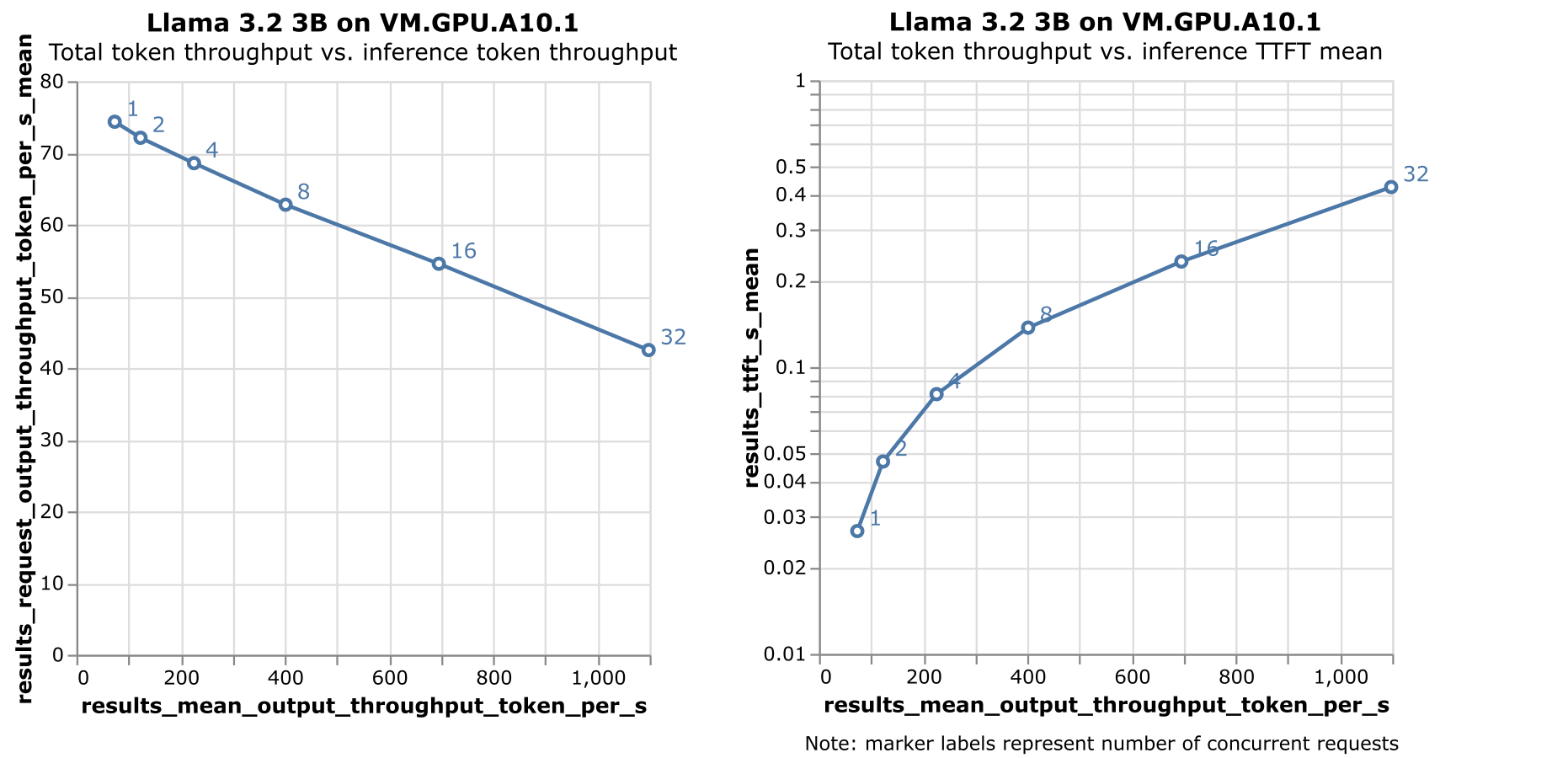
図2の2つのプロットは、前述の主要なパフォーマンス・メトリックを示しています:
- 左プロット: システム・スループット(トークン/秒)と問合せごとのスループット(トークン/秒)の比較。
- 右プロット: システム・スループット(トークン/秒)と最初のトークンまでの時間(TTFT)のレイテンシ。
これらの結果から、いくつかの観測結果を得ることができます:
- VM.GPU.A10.1シェイプのインフラストラクチャ適合性: 選択したOCIシェイプは、定義されたユース・ケースで3.2 3Bを提供するための強力なパフォーマンスを示しています。トークン/スループットとTTFTの両方が、テストされたすべての同時実行レベルにわたって許容範囲内に残ります。
- システムのスケーラビリティ: 左のプロットは、システム・スループットの上昇に伴う問合せごとのスループットの線形増加を示し、システムがまだ飽和状態に達していないことを示しています。これは、選択したGPUシェイプが追加の同時実行性を効果的に処理できることを意味します。
- 最大同時実行性: テストされた同時実行性レベル(32)で、システムは40トークン/秒を超えるスループットを維持し、最初のトークンまでの時間(TTFT)のレイテンシは500ミリ秒未満です。実際のパフォーマンスは、入力トークン・サイズと出力トークン・サイズによって異なりますが、これらの結果は、実際のシナリオでの予測に対する信頼できるベースラインを提供します。
これらの結果は、VM.GPU.A10.1シェイプがこのワークロードに適しているだけでなく、必要に応じてより高いレベルの同時実行性にスケーリングする余地があることを示しています。これにより、低レイテンシを維持しながら、推論ワークロードを効率的に処理できるという自信が得られます。
まとめ
Oracle Cloud InfrastructureのVM.GPU.A10.1シェイプで、Llama 3.2 3Bなどの大規模言語モデルを効果的にベンチマークすることは、高パフォーマンスのAI推論サービスをクラウドにデプロイすることの実現可能性だけでなく、適切に構造化されたベンチマーク・プロセスの重要性も示しています。Ray LLMPerfなどのツールを使用すると、MLおよびクラウド・エンジニアはシステム・スループット、スケーラビリティおよびレイテンシに関する重要なインサイトを得て、インフラストラクチャの最適化について情報に基づいた意思決定を行うことができます。高い同時実行性レベルでも、堅牢なスループットと最小レイテンシによって強調された有望な結果は、スケーラブルなAIアプリケーションをサポートするためのOCI GPUシェイプの可能性を示しています。生成AIが進化し続ける中で、このようなベンチマーク・プラクティスを活用することは、多様なユーザー・ニーズを満たす効率的で応答性の高いAI主導のソリューションを設計するために不可欠です。
リソース
- Meta Llama 3.2 model card
- オープン・ソースLLM推論サーバー: vLLM
- オープン・ソース・ベンチマーク / Rayが管理するロードテスト・スイート: LLMPerf
- OCI Compute サービス
- 推論ベンチマーキング・システムの設定に関するOCIチュートリアル
