こんにちは。日本オラクルのクラウド・エンジニアの小西です。
暑い日が続きますが、6月はじまりのオラクルでは新年度が始まりました。気持ちも新たにこの一年も引き続き新機能ハイライトを継続していきたいと思いますのでよろしくお願いいたします!
「Oracle Cloud Infrastructure 新機能ハイライト」では隔週でOracle Cloud Infrastructure(OCI)の主な新機能をご紹介していきます。
それでは、前回に引き続き、ここ2週間の新機能を見ていきましょう!
[Data Science] データ・サイエンスで VM.Standard.E3.Flex シェイプをサポート
-
VM.Standard.E3.Flex コンピュート・シェイプがデータ・サイエンス・サービスでサポートされました。
[Database] Autonomous Database on Dedicated infrastructure: ネットワークアクセス制御リストを利用したアクセス制限
-
ネットワーク・アクセス制御リスト(ACL)を設定して、Dedicated Exadata InfrastructureのAutonomous Databaseへのアクセスを特定のIPアドレスのみ許可することができるようになりました。
-
ACLによって、Autonomous Databaseのネットワークアクセスを特定のアプリケーションやクライアントに制限するようなきめこまやかなアクセス制御ポリシーを設定することができます。
-
詳細
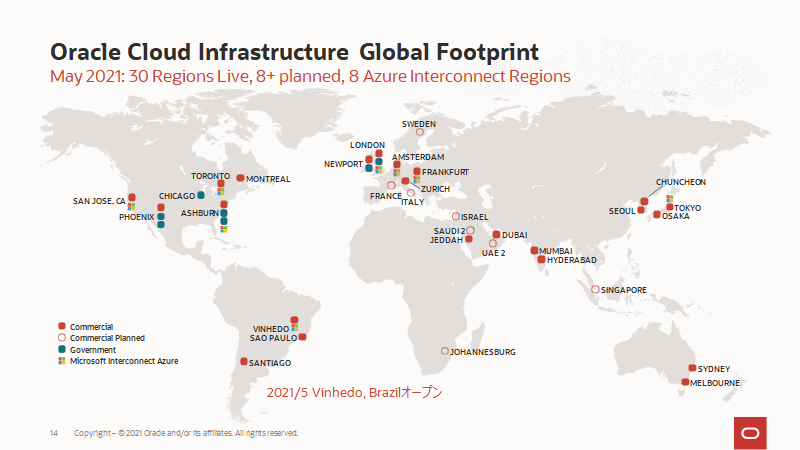
[OCI] 新規リージョン Vinhedo, Brazil
-
ブラジルのSoutheast (Vinhedo) リージョンがオープンしました。リージョン名は sa-vinhedo-1、リージョン・キーは VCP です。これによって、OCIのリージョンは全部で30リージョンとなりました!
-
詳細 Managing Regions.
[Logging Analytics] 監査ログ、フロー・ログ、APIゲートウェイ用のプリビルド・カスタマイズ可能ダッシュボード
-
Oracle-defined dashboards では、ビルトインのウィジェットが含まれ、エンタープライズ・ネットワーク(VCN)概要、OCI APIゲートウェイ概要、OCI監査分析、およびVCNフロー・ログのような重要なログのいくつかの外観を把握できます。
-
また、 Oracle-defined saved searches も、いくつかのユースケースで利用可能になりました。ログ・エクスプローラーで事前定義された保存済み検索のデータを表示したり、それをダッシュボードに追加したり、ベースとなるクエリーのスケジュール・タスクを作成したりできます。
[Logging Analytics] ATP/ADW ログ分析のサポート
-
分析用途にOracle Autonomous Databaseの表やビューからログを収集することが可能になりました。Logging Analyticsではデータベースに接続して、ユーザーが定義したSQLクエリーを実行してデータを収集します。
-
チュートリアル Collect Logs from Tables or Views in Oracle Autonomous Database.
[Logging Analytics] New streamlined onboarding
-
これまではLogging Analyticsを利用するには、有効化後に手動で関連リソースなどを作成する必要がありましたが、ワンクリックで自動的に構成することができるようになり、簡単に利用開始できるようになりました。
[Logging Analytics] OCIメトリック用のインタラクティブ・メトリック・チャートの作成
-
保存済検索から生成されたメトリックデータやそのほかのOCIモニタリング・サービスで蓄積されたメトリックデータを表示できるメトリック・ウィジェットが作成できるようになりました。
[Data Science] PySpark V3.0 conda環境の登場
-
Data Flowジョブの作成やPySparkをローカル実行するために PySpark V3.0 conda が利用可能です。
-
このconda環境で、Data Flowアップグレードと互換性を持つため PySpark バージョンはV2.4.4 から V3.0.2 にアップデートされました。condaはPython 3.7をベースにし、 Oracle Accelerated Data Science (ADS) SDK v2.2.1 library を含みます。これにより、Oracle Autonomous Databaseとparquetファイルのsnappy圧縮をサポートします。また、このconda環境はCPU向けです。 slug名は pyspark30_p37_cpu_v1。
-
詳細 Data Science 、 Data Science API.
[MySQL Database] MySQLデータベース・サービスのバックアップからのリストア中にストレージ拡張が可能
-
バックアップからのリストアを行う際に、MySQL DBシステムのデータ・ストレージを拡張することができるようになりました。この改善によって、既存の自動もしくは手動バックアップからストレージ容量を拡張し、簡単に新たなDBとして作成することができます。
[File Storage] ファイル・システムのクローン
-
ファイル・ストレージ・サービスで、任意のスナップショットからファイル・システムのクローンを作成して即座に利用することが可能になりました。テスト環境やパッチ適用の用途や、より高速なアプリケーションのプロビジョニングなどに活用することができます。
-
スナップショットは、ある時点でのクローンをする際の初期データになります。クローンはデータ自体を親ファイルシステムから移動するのではなく、親ファイルシステムのデータを共有して参照します。
-
クローン作成後の親ファイルシステムのデータ更新はクローンには反映されず、同様にクローンへのデータ更新は親ファイルシステムには反映されず、それぞれ独立します。
-
-
もしテスト時に失敗してデータがリカバリ不能な状態になった場合は、オリジナルのファイル・システム・スナップショットから再度新規のクローンを作成して、作業をやり直すことが可能です。
-
クローンからさらにブランチを作成することも可能(クローン・ツリー)
-
ブログ:https://blogs.oracle.com/cloud-infrastructure/announcing-cloning-for-file-storage-service
[Compute] ArmベースのAmpere A1コンピュート・シェイプのベアメタル・インスタンスが利用可能
-
Armベースの Ampere A1 コンピュート・シェイプのベアメタル・インスタンスも利用可能になりました!
-
A1シェイプのご紹介は前回の新機能ハイライトもご参照ください。
[Operations Insight] アプリケーションをまたいだデータベースとホストのフィルタリング
-
Operations Insightsで、データベース名やデータベースホストをもとにフィルタリングができるようになりました。
###
以上が本日の新機能ハイライトです。
今後も引き続き新機能情報をお伝えしていきたいと思います!
関連情報
