※ 本記事は、Tim Chien, Dan Holevaによる”Very Large Database Backup and Recovery Best Practices“を翻訳したものです。
2023年4月6日
概要
データベースの世界で言葉の争いが起こっています。大規模なデータベースとは? 長年にわたり、その定義は変わり、ますます一般的になり、サイズが大幅に増加しています。サイズは数百ギガバイトからテラバイト、ペタバイトに及びます。この増加は、データを処理し、24時間365日のパラダイムで環境の可用性を維持するために、データベース管理者に固有の課題をもたらします。24時間365日体制が求められる中、インフラストラクチャに対する需要が高まり、グローバル・エンタープライズ全体の非常に大規模なデータベースが多数存在するという課題が生じました。データベースは数千にまで数えられるため、これらの課題はメンテナンスの観点からだけでなく、リカバリ期間にも存在します。満足のいく目標復旧時点(RPO)および目標復旧時間(RTO)は常に、規定されたビジネス・リカバリ要件に基づいている必要があります。現在または必要な任意の時点に、障害が発生せずにリカバリできる必要があります。たとえば、すべてのデータ損失状況でデータベース全体をリストアする必要はありませんが、破損した表のリカバリによって、データベースが機能状態に戻される場合があります。
この2部構成のブログ・シリーズでは、大規模データベースの一般的なベスト・プラクティスについて説明します。第1部では、ガイド原則と具体的な実践について説明します。
何をすべきか
エンタープライズ・データベース環境を保護し、維持するために考慮する必要がある基本的なガイド原則があります。これらの質問は、企業に安心して保護を提供するための具体的かつ実用的なステップを可能にする方法で回答する必要があります。
- 規定された目標を満たすバックアップ計画を作成します。ほとんどの組織はバックアップ計画を立てていますが、迅速かつアプリケーションの一貫したリカバリの要件を満たしていますか?
- プライマリ・ワークロードとバックアップ・パフォーマンスのためにアプリケーションを最適化します。
- 圧縮を使用します。これにより、高度なアルゴリズムを使用して領域を最適化し、バックアップ・サイズも削減できるため、データベースのサイズを大幅に削減できます。
- パフォーマンス、スケーラビリティ、耐障害性を向上させるエンジニアド・システム・アーキテクチャに統合します。このアプローチは、環境のコンポーネントを分離し、リカバリを高速化することで、ダウンタイムの影響を軽減するのに役立ちます。
- 包括的なバックアップおよび障害時リカバリ計画を構築、使用およびテストします。これは、エンタープライズ・リカバリ計画において見落とされることが多い重要な項目です。堅牢な計画はデータの損失や破損から保護するだけでなく、これらのバックアップを定期的に実行して、リカバリの継続性をテストする必要があります。リストアが必要な場合、組織がガードから脱出する回数が多すぎるため、データベースがなんらかの方法で破損していることがわかります。パニックが発生し、環境を作業順序に復元するために極端な手段を実装する必要があります。計画は、必要に応じて迅速かつ効率的に実行できることを確認するために定期的にテストする必要があります。
次に、特定の演習について説明します。
増分バックアップ
これは、バックアップ時間を短縮するための標準的な手法です。変更されたブロックのみがRMANの高速増分バックアップで読み取られ、書き込まれます。これは、変更頻度が中程度の低いVLDBに適しています。一般的な方針は、次に示すように、週次の完全バックアップ(レベル0)および日次の差分増分バックアップ(レベル1)で構成されます。アーカイブ・ログは必要に応じてバックアップされ、ディスク上に保持されます。
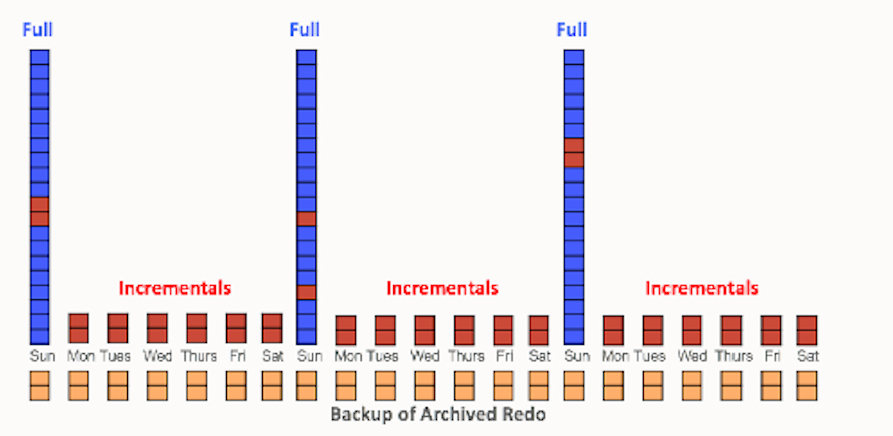
差分および累積増分バックアップ計画の使用を評価することもできます。差分増分バックアップでは、最後のレベル1の増分以降のブロック変更が取得されますが(図1を参照)、累積増分では、最後のレベル0以降のブロック変更が取得されます。このため、レベル0のバックアップと累積バックアップで個別にリストアおよびリカバリする差異が遅くなる可能性があり、レベル0に直接リカバリできます。たとえば、バックアップとリカバリの時間のバランスを改善するために、差分を土曜日、月曜日、火曜日に取り、累積を水曜日と金曜日に取り、レベル0を日曜日に取ることもできます。
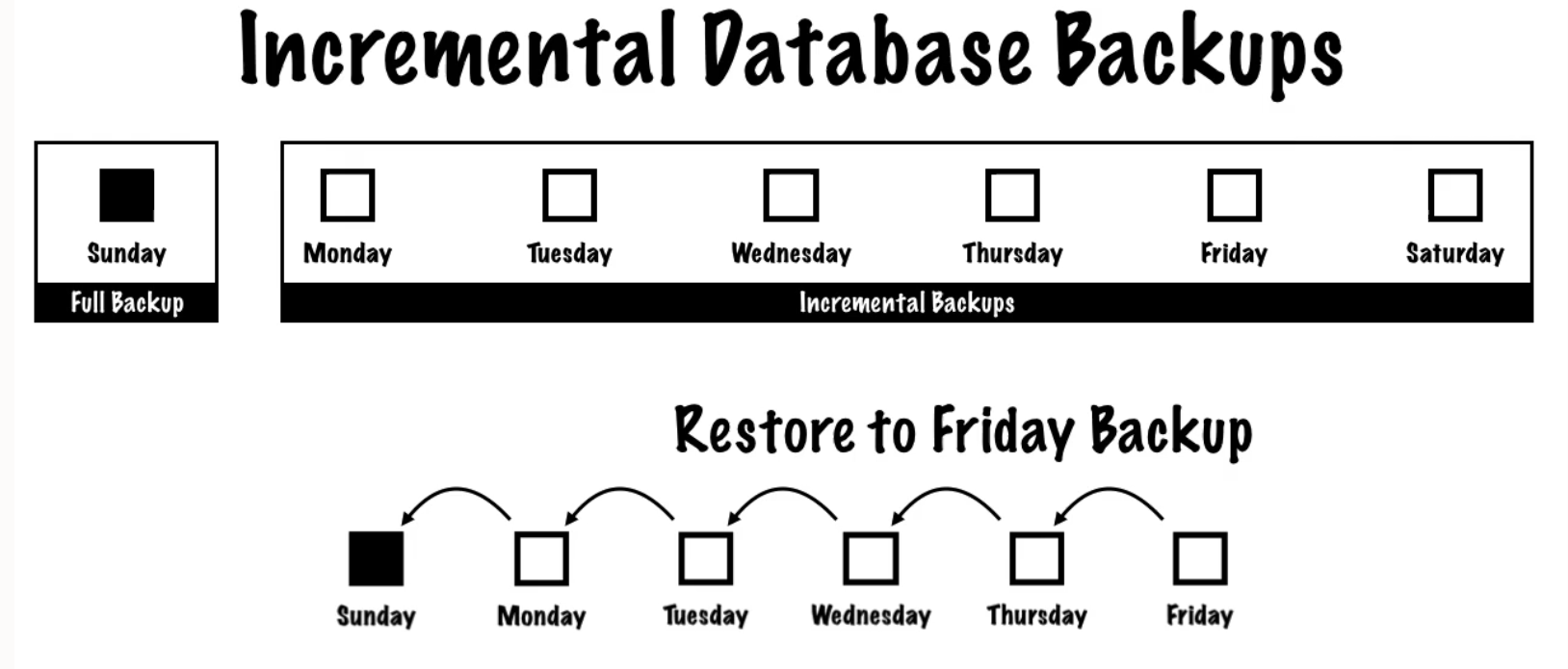
差分増分バックアップを使用したリカバリ・プロセスの例を次に示します。ここでは、日曜日に作成された全体バックアップがリストアされ、増分がリストアされて、金曜日にデータベースが特定の時点にリカバリされます。
増分ベースの戦略の詳細は、この「データベース・バックアップ戦略」のビデオを参照してください。
表領域レベルのバックアップ
アプリケーション設計で重要な(読取り/書込み)データと非クリティカル(読取り専用など)データを表領域ごとに分離できる場合、特定の表領域を他の表領域より少ない頻度でバックアップすることで、バックアップ時間を短縮できます。たとえば、索引表領域はデータ表領域よりもバックアップの頻度が低くなる場合があります。この方法では、重要な表領域を個別のバックアップにグループ化するなどして、リストア時間を短縮することもできます。長期間バックアップされていない表領域では、リカバリ中に最新のバックアップよりも多くのアーカイブ・ログを適用する必要があることに注意してください。
表領域バックアップの例については、『Oracle Backup and Recoveryユーザーズ・ガイド』を参照してください。
マルチセクション・バックアップ
データベースの急速な増加に伴い、1つの課題は、大規模なデータファイルおよび表領域を管理することです。これは、数テラバイトに及ぶこともあります。RMANでは、ファイル内パラレル・バックアップをサポートするためのマルチセクション・バックアップが提供され、1つのデータファイルをユーザー指定のセクションに分割できるため、各セクションを別々のチャネルでパラレルにバックアップできます。この方法は、多数の小さいデータファイルで構成されるデータベースではなく、残りのデータファイルよりも大幅に大きい少数のデータファイルで構成されるデータベースに最適です。これは、使用可能なテープ・ドライブの数よりも大きいデータファイルの数が少ないデータベースでも最適です。セクション・サイズ = (平均データ・ファイル・サイズ/チャネル数)の初期推奨事項。ハードウェアおよびバックアップ・デバイスの制限に応じて、チャネルを増分してバックアップ・パフォーマンスをスケール・アップできます。
バックアップ圧縮
バックアップをできるだけ小さく効率的に維持することは、大規模なデータベースにとって特に重要です。RMANでは、バックアップ・セットの作成時にブロック圧縮を使用できます。RMANブロック圧縮は従来のバイナリ圧縮ではありません。かわりに、RMANでは、このバックアップでは必要ない特定のブロックのバックアップを完全に回避するために使用する方法のセットです。未使用のブロック圧縮を使用する場合、RMANは、現在一部のデータベース・オブジェクトに割り当てられていないデータベース・ブロックの読取りおよびバックアップをスキップします。これは、それらのブロックが以前に割り当てられていたかどうかには関係ありません。
Nullブロック圧縮を使用する場合、RMANはデータを含まないブロックを出力から除外します。Nullブロック圧縮は、バックアップ・セット形式で作成されたレベル0または完全バックアップで常に使用されます。
RMANの圧縮レベルにはトレードオフがあります。つまり、BASICはLOWよりも高い圧縮を実現しますが、実行に時間がかかり、バックアップ中のCPUリソースへの影響が長くなる可能性があります。ベスト・プラクティスはLOWまたはMEDIUMです。BASIC以外の圧縮設定を使用するには、DBにAdvanced Compression Optionのライセンスが必要です。
プログレッシブ表領域のリカバリ
表領域レベルのリカバリ方法で説明したように、リカバリ計画を最適化して、ユーザー/読取り/書込み表領域を最初に選択的にリストアしてアクセス可能にし、クリティカル/読取り専用表領域を後でリストアすることで、時間を短縮することもできます。リカバリ中にこれを実現するために、データベースは制御ファイルとともにマウントされ、クリティカル/読取り/書込み表領域をリカバリしてからアクセス用にオンラインにする前に、重要度の低い表領域がオフライン・モードに設定されます。
プラガブル・データベース・レベルのリストア
マルチテナント・データベースでは、単一のコンテナ・データベース(CDB)に1つ以上のプラガブル・データベース(PDB)を含めることができます。これは、コンテナ・データベースを1つのコマンドを使用してバックアップできるため、PDBバックアップ・スクリプトが不要になるため、バックアップ手順を簡略化できます。ただし、個々のPDBは、他のPDBに影響を与えずに必要に応じてリストアできます。CDBおよびPDBのバックアップの詳細は、このドキュメントを参照してください。PDBリカバリ計画については、このドキュメントを参照してください。
リカバリ計画の開発
最後に、次に示すように、バックアップの整合性を定期的に検証し、同一のテスト・システムでリカバリ・シナリオを実践します。
メディア障害
-
データベース・ファイルを新しい記憶域の場所にリストアします。
-
データベース、表領域およびデータ・ファイルのリストアを検証します。
-
RESTORE DATABASE VALIDATE;
-
ブロック破損
- テスト環境で、ブロック・メディア・リカバリを使用して、ブロック破損の修復を確認します。
-
RECOVER CORRUPTION LIST;
-
-
データファイルをリストアした後、破損したログおよび欠落したログを検出できる、トライアル・リカバリを使用してアーカイブ・ログ適用を検証します。
-
RECOVER DATABASE TEST;
-
ユーザー・エラー
テスト環境で、フラッシュバック問合せ、フラッシュバック表、フラッシュバック・ドロップおよびフラッシュバック・トランザクションで、詳細なリカバリを確認します。
-
データベース全体の論理エラーを修復するための実行可能な方法としてフラッシュバック・データベースを検証します。
- 表の切捨てやその他のDDL操作によるリカバリなど、表領域のPoint-in-Timeリカバリ(TSPITR)を実行します。
ディザスタ・リカバリ
-
すべてのファイルを別のホストおよび記憶域の場所にリストアすることを検証します。
- Data Guard構成のスタンバイ・データベースへのスイッチオーバー/フェイルオーバー手順をテストします。
サマリー
データベースはすべての組織に不可欠であり、データベース保護は、ハードウェアまたはソフトウェアの障害、自然災害または悪意のあるアクティビティによるデータ損失に対する必要な保護を提供するために、標準運用で不可欠な部分である必要があります。今日のエンタープライズ環境の非常に大規模なデータベースは、データベース管理者に固有の課題をもたらし、ご使用の環境に合わせてカスタマイズされたベスト・プラクティス・プレイブックに従うことで、これらの大規模なデータベースを効果的に管理し、最大限のパフォーマンスと信頼性を実現するように最適化できます。エンジニアド・システム・アーキテクチャ、バックアップ圧縮、およびパフォーマンス監視を利用することは、すべて全体像の一部です。
パート2では、OracleのZero Data Loss Recovery Applianceがエンタープライズ・データ保護計画にどのように役立つかを中心に、エンジニアド・システムがこれらの目標の一部にどのように対応できるかを説明します。
バックアップとリカバリを最適化する方法の詳細は、『VLDB バックアップおよびリカバリ・ガイド』を参照してください。
