INTRODUCTION
We have a war of words going on in the database world. What is a very large database? Over the years, that definition has changed, become increasingly common, and radically increased in size. They can range in size from hundreds of gigabytes, through terabytes, and into petabytes. This increase presents unique challenges to database administrators to process the data and maintain availability of the environment in a 24-hour, 7 days a week, 365 days a year paradigm – this places increasing demands on infrastructure and has created challenges due to the sheer number of very large databases across the global enterprise. Databases can number into the thousands and the challenges not only exist from a maintenance perspective but with recovery windows as well. A satisfactory data recovery point objective (RPO) and recovery time objective (RTO) must always stem from stated business recovery requirements. We need to be able to recover to the current or any required point in time specified without fail. For example, it may not be required to restore the database in its entirety for all data loss situations, but a recovery of a corrupt table may put the database back into a functional state.
In part 1 of this two-part blog series, we will first discuss guiding principles and specific practices.
WHAT TO DO?
The below guiding principles should be considered in order to protect and maintain an enterprise database environment. These should be carefully considered and result in concrete and practical steps for implementation.
- Create a backup strategy to meet stated recovery objectives. Most organizations have a backup strategy in place, but will it meet the requirements for a quick and application consistent recovery?
- Make use of database or backup compression. Reducing database size means that backup sizes are also reduced. Altenatively, backup compression may be considered as a simpler, standardized method to reduce backup storage consumption.
- Optimize application design for primary workload and backup performance.
- Build, use, and test a comprehensive backup and disaster recovery plan. This is a key item that so often gets overlooked in an enterprise recovery plan. Not only will a robust plan protect against data loss and corruption, but these backups should also be performed and tested regularly for continuity of recovery. Too many times organizations are caught off guard when a restoration is necessary, only to discover that the database is corrupt in some way. Panic ensues and extreme measures must now be implemented to restore the environment to working order. The plans must be tested regularly to verify that they can be executed quickly and efficiently should it be necessary.
- Consolidate to a database engineered system architecture that allows for better performance, scalability, and fault tolerance.
Now, let’s examine specific practices.
INCREMENTAL BACKUPS
This is a standard technique to reduce backup time. Only changed blocks are read and written with RMAN fast incremental backup, which are well-suited for VLDBs with low-medium frequency of changes. A typical strategy consists of weekly full (level 0) and daily differential incremental (level 1) backups as shown below. Archived logs are backed up and retained on-disk, as needed.
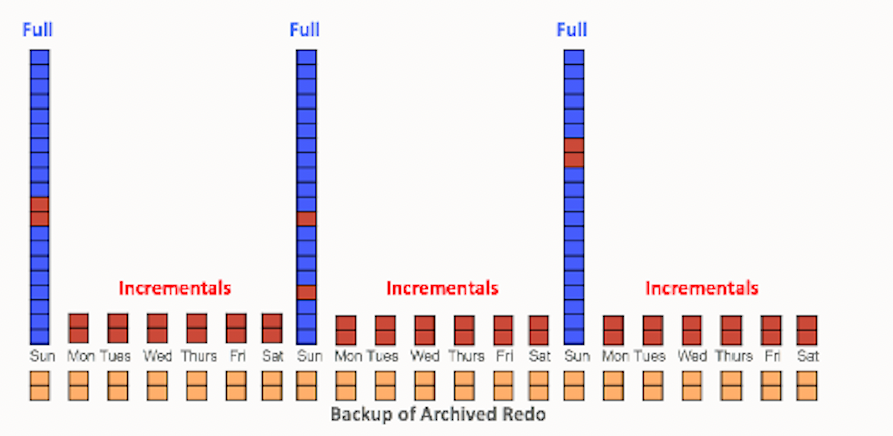
You may also evaluate use of differential and cumulative incremental backup strategies. Differential incremental backups capture block changes since last level 1 incremental (as in Figure 1), whereas cumulative incrementals capture block changes since last level 0. Thus, differentials could potentially be slower to individually restore and recover on a level 0 backup versus cumulative, which can be directly recovered onto a level 0. For example, to better balance backup and recovery time, differentials may be taken on Saturday, Monday, and Tuesday, cumulatives taken on Wednesday and Friday, and level 0 taken on Sundays.
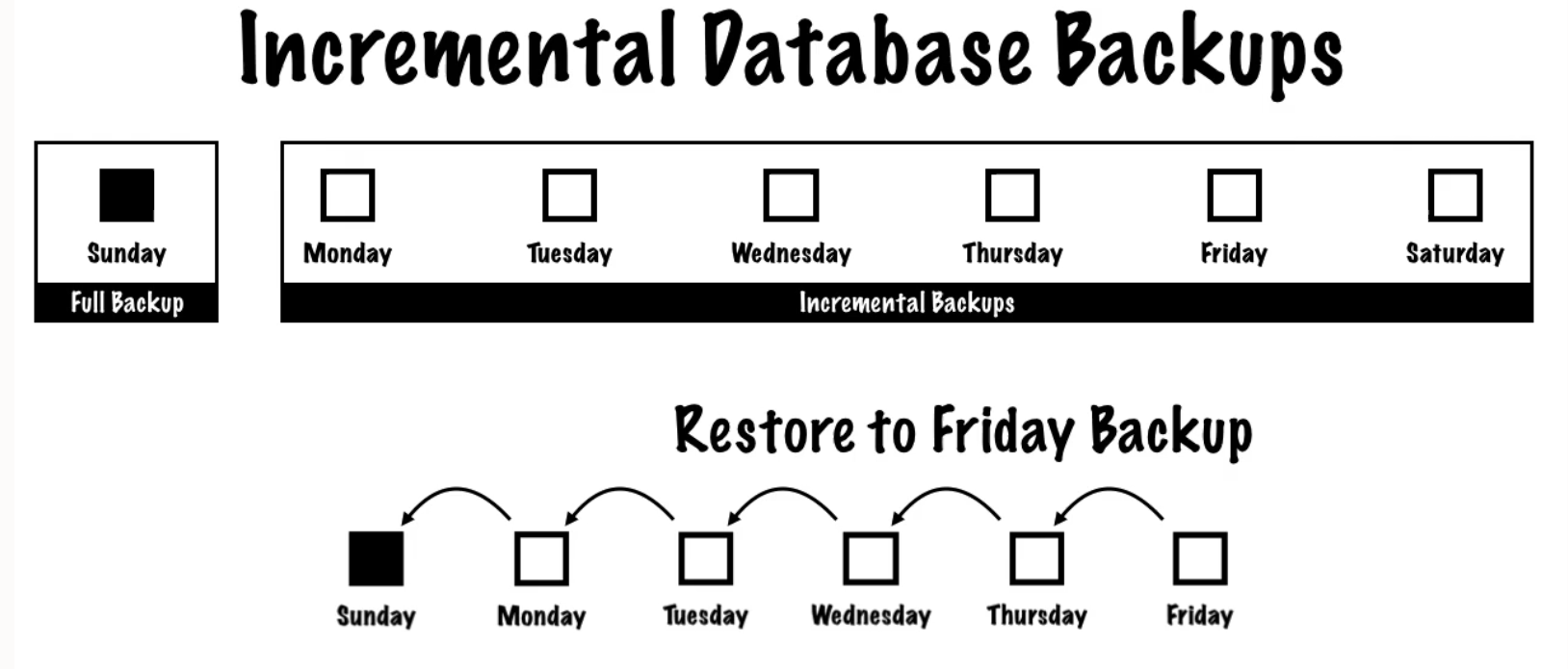
To illustrate the recovery process using incremental backups, the below figure shows a full backup taken on Sunday is first restored, then incrementals are restored and applied to recover the database to a point-in-time on Friday. The time needed to restore and apply incrementals in succession must be factored into the overall recovery time objectives.
See this Database Backup Strategies video for more details on incremental-based strategies.
BACKUP COMPRESSION
Keeping backups as small and efficient as possible is especially important for large databases. RMAN can use block compression when creating backup sets. This block compression is not traditional binary compression. Rather, it is a set of techniques that RMAN uses to altogether avoid backing up certain blocks that are not needed in this backup. When employing unused block compression, RMAN skips reading and backing up any database blocks that are not currently allocated to database objects. This is regardless of whether those blocks had previously been allocated.
When employing null block compression, RMAN omits fron the backup any block that has never contained data. Null block compression is always used with level 0 or full backups that are created in backup sets.
Note that there are trade-offs among RMAN compression levels, i.e. BASIC achieves higher compression than LOW, but can take longer to run and longer impact to CPU resources during backup. Based on our customer’s experiences, LOW or MEDIUM is recommended to achieve an acceptable trade-off between CPU usage/time and compression savings achieved. Note that Advanced Compression Option must be licensed for use of any RMAN compression setting other than BASIC.
MULTISECTION BACKUP
With the rapid growth of databases, one challenge is to manage larger datafiles and tablespaces, which can range into multiple terabytes. RMAN offers multisection backup to support intrafile parallel backup and allows one data file to be divided into user-specified ‘sections’, so that each section can be backed up in parallel on separate channels. This method is best for databases composed of a few data files that are significantly larger than the rest, versus a database composed of large number of small data files. This is also optimal for databases where there are fewer number of large data files than the number of available tape drives. An initial recommendation for section size = (average data file size / # of channels). Channels can be incrementally added to scale up backup performance, depending on hardware and backup device limits.
TABLESPACE LEVEL BACKUP
If the application design can allow segregation of critical (read-write) vs non-critical (e.g. read-only) data by tablespaces, backup time can be reduced by backing up certain tablespaces less frequently than others. For example, index tablespaces may be backed up less frequently than data tablespaces, while read-only tablespaces can be automatically skipped by RMAN. This strategy can also improve restore time, e.g. by grouping critical tablespaces in a separate backup. Note that a tablespace that has not been backed up in a long time will require application of more archived logs during recovery, than a more recent backup.
Refer to the Oracle Backup and Recovery User’s Guide for examples of tablespace backups.
PROGRESSIVE TABLESPACE RECOVERY
Just as tablespace level backups can help reduce overall backup windows, recovery strategies can also be optimized to reduce time by selectively restoring user/read-write tablespaces first, and making them available for access, while restoring less critical/read-only tablespaces later. To accomplish this during recovery, databases are mounted with control file, and less critical tablespaces are set to offline mode, prior to recovering the critical/read-write tablespaces and then placing them online for access.
PLUGGABLE DATABASE LEVEL RESTORE
With multitenant databases, a single container database (CDB) may have one or more pluggable databases (PDB). This does not require changes to application design, while allowing backup procedures to be simplified as a container database can be backed up using one command, eliminating the need to run individual PDB backup scripts. However, individual PDBs can be selectively restored as needed per application needs, without affecting other PDBs. For more information on CDB and PDB backup, see this documentation and for PDB recovery strategies, see this documentation.
DEVELOP RECOVERY STRATEGIES
Finally, regularly validate backup integrity and practice recovery scenarios on identical test systems, as suggested below.
Media Failure
-
Restore database files to a new storage location.
-
Validate restoring database, tablespace, and data file.
-
RESTORE DATABASE VALIDATE;
-
Block Corruption
- In test environment, verify block corruption repair with Block Media Recovery.
-
RECOVER CORRUPTION LIST;
-
-
Validate archived log apply with Trial Recovery, which can detect corrupt and missing logs, after restoring data files.
-
RECOVER DATABASE TEST;
-
User Error
In test environment, verify Flashback Query, Flashback Table, Flashback Drop, and Flashback Transaction for fine-grained recovery.
-
Verify Flashback Database as a viable method to repair database-wide logical errors.
- Perform tablespace point-in-time recovery (TSPITR), including recovery through table truncates or other DDL operations.
Disaster Recovery
-
Validate restoring all files to another host and storage location.
- Test switchover/failover procedures to a standby database in a Data Guard configuration.
SUMMARY
Databases are an essential part of all organizations and database protection must be an essential part of standard operations to provide the necessary safeguards against data loss due to hardware or software failure, natural disasters, or malicious activities. Very large databases in today’s enterprise environments present unique challenges to database administrators and by following a best practices playbook tailored for your environment, these large-scale databases can be managed effectively and optimized for maximum performance and reliability. Leveraging an engineered system architecture, backup compression, and performance monitoring are all part of the big picture.
In part 2, we will examine how an engineered system can help meet some of these objectives, focusing on how Oracle’s Zero Data Loss Recovery Appliance can be part of an enterprise data protection plan.
For more information on methods to optimize backup & recovery, refer to the VLDB Backup & Recovery Guide.

