Oracle Database 23ai (リリース更新23.5)がオンプレミスのExadata Database Machineで利用可能になり、お客様が最新かつ最高のデータ管理テクノロジのメリットを享受できるようになったことをお知らせします。
Exascaleインフラストラクチャ上で提供される Exadata Database Service(Exadata Database Service on Exascale Infrastructureのご紹介)、革新的なExadata Exascaleテクノロジ、Googleとの素晴らしい新しいパートナーシップなど、Oracleにとってエキサイティングな時期であり、Exadata、Oracle Database、その他のデータ管理クラウド・サービスをGoogleデータ・センターに導入するなど、多くの画期的な発表があります。
今日は、オンプレミスExadata向けのOracle Database 23aiの一般提供により、新たなマイルストーンを迎えました。Oracle Database 23aiは、Oracle Databaseの最新の長期サポート・リリースです。AI Vector Search、JSON Relational Duality、True Cache、Lock-Free Reservations、Priority Transactions、Java Script Stored Procedures、組み込みのSQL Firewall、これ以外にも300以上の新機能のリストが含まれており、生産性、効率性、パフォーマンス、可用性、セキュリティを向上させるために細心の注意を払って作られています。Oracle Database 23aiのリリースでは、Exadata Exascaleは、オンプレミスの Exadata X8M以降の新しいExadata Database Machine でも使用できるようになりました。
Oracleのミッション・クリティカル・データベース・テクノロジ担当エグゼクティブ・バイスプレジデントであるJuan Loaizaが、フラッグシップ・データベースの最新リリースの概要をご覧いただけます。
Oracle Database 23aiを発表するDom Gilesの素晴らしいブログ記事もお読みいただくことをお勧めします。このブログは、多くの重要な改善点について説明しています。
この投稿では、Exadataプラットフォーム(Exadata Database Machine、Exadata Cloud@Customer、Exadata Database Service)でOracle Database 23aiを高速化および強化する方法に焦点を当てます。
AIの時代
Oracle Database 23aiでは、新規および既存のアプリケーションがデータを意味的に検索し、データの意味をデータベース内にすでに格納されているビジネス・データと組み合せることができるようにする、印象的な新機能が導入されています。我々はこの機能をAI Vector Searchと呼びます。Doug HoodとRanjan Priyadarshiは、AI Vector Searchの解説のブログ記事を書いています。
ベクトル(ベクトル・エンベディング)は、AIアプリケーションで使用される一般的なデータ構造です。ベクトルは、様々なデータ型(イメージ、ドキュメント、ビデオなど)からディープ・ラーニング・モデルによって生成される数値のリストで、データのセマンティクスをエンコードします。
Oracle AI Vector Searchでは、SQLのパワーをすべて使用して、他のビジネスデータとともにベクトルのエンベディングを生成、保存、インデックス作成、検索が可能です。たとえば、ドキュメントを検索する場合、ベクトル検索はキーワードベースの検索よりも効果的であると考えられます。ベクトル検索は、実際の単語自体ではなく、単語の背後にある意味とコンテキストに基づいているためです。
Oracle AI Vector Searchでは、セマンティック・ドキュメント検索と構造化されたドキュメント・プロパティの検索を組み合せることができます。たとえば、テクノロジ記事のデータベースでは、最後に公開されたエンタープライズ・ユース・ケースの「特定の著者と特定の国の特定の発行社によって過去5年間に公開されたエンタープライズ・ユース・ケース用の大規模言語モデル(LLM)のファイン・チューニングに関する記事を検索」は、1つ以上の表に存在する可能性のある記事テキストと記事属性の両方を検索する必要があります。
言い換えると、Oracle Databaseは、この新しいタイプのデータを既存のビジネス・データに格納、処理、結合して、アプリケーションとユーザー・インタラクションを強化し、よりコンテキスト的で有意義な結果をもたらします。
この機能を有効にするために、Oracle Database 23aiでは、VECTORデータ型、新しいSQL演算子を使用して、VECTORデータ型に格納されているベクトル・エンベディング、新しいVECTOR最適化索引、新しいSQL演算子を作成し、ビジネス問合せで類似性検索を簡単に表現し、セマンティック情報をビジネス・データと結合します。Exadataと最近リリースされた Exadata System Software 24aiは、この新世代のユース・ケースを加速する補完的な新機能を提供します。
低レイテンシのAIクエリ
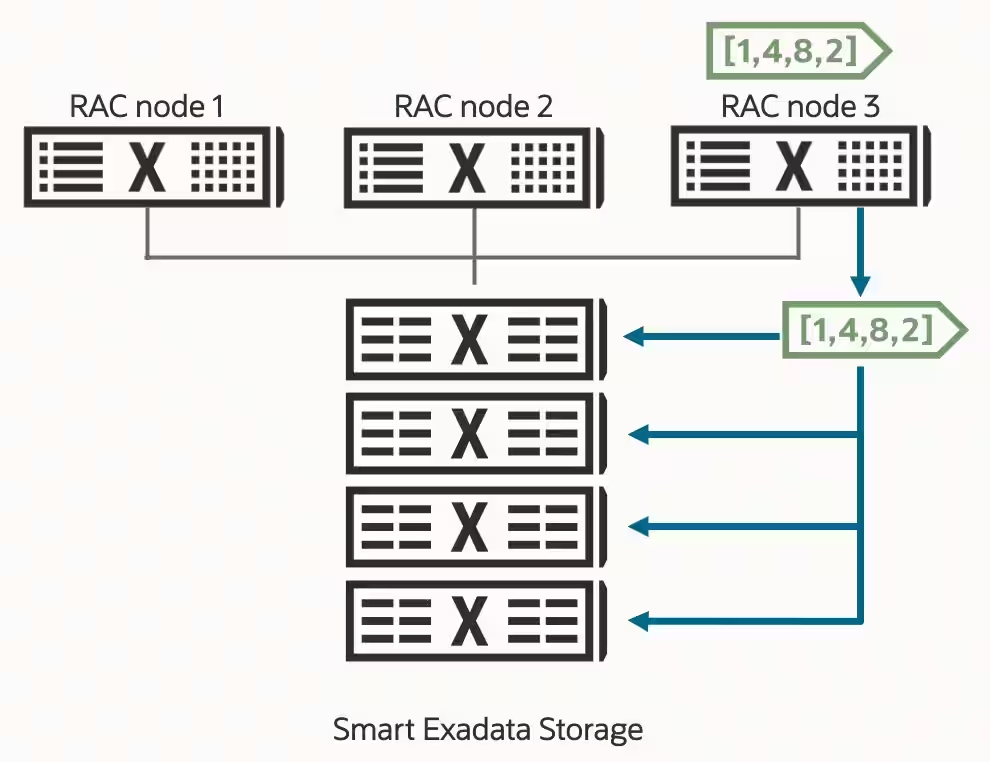
Exadataの基本的な属性の1つは、ワークロードをスケーリングする機能です。これは、超高速RDMAネットワークと独自のデータ転送最適化機能を利用してパフォーマンスを向上させるデータベース・サーバー上のReal Application Clusters (RAC)の水平方向のスケーラビリティを使用し、データベースからExadataストレージ・サーバーに作業をオフロードして、ストレージからデータベース・サーバーにデータを送信するよりはむしろ、そのほとんどが破棄される場合に、データ処理が実行されます。このデータ処理のオフロード(スマート・スキャンまたはSQLオフロード)は、Exadataがリリースされた以降に使用可能になった機能です。これは通常、データ分析に使用されます。データ分析では、結果セットが最終処理のためにデータベースに戻される前に、大量のデータをスキャンして結合します。
AI Vector Searchでは、膨大な量のベクトルデータをスキャンする必要性がありますが、結果レポートが生成されるのに、複雑な分析のため生成するのに数秒、数分、または数時間かかる場合もあります。AI Vector Searchは、トランザクションワークフローで使用されます。たとえば、「過去5年間に公開されたエンタープライズ・ユース・ケースの大規模言語モデル(LLM)のファイン・チューニングに関する記事を探す」と尋ねられた場合、結果はすぐに戻ってくる必要があります。結果を確認した後で質問を絞り込み、再度尋ねる必要がある場合、問合せのパフォーマンスは高速ないしはさらに高速である必要があります。ここでスキャンする必要がある可能性のある記事の数(またはそれらを表すベクター)は、数百万または数十億に及ぶ可能性があります。
スマート・スキャンは、数十億のベクターをスキャンする際の超高速な応答時間を実現するために、AIワークロード用に最適化されています。ストレージ・サーバー上で何十億ものレコードをスキャンし、従来の分析ワークロードと同様に不要なデータをプルーニングおよびフィルタリングします。検索の実行に必要なデータのみが返されます。ただし、AIベクトル検索に対して実行すると、スマート・スキャンは高速に開始するように最適化され、すでに作成されているスマート・スキャンのセッション(メモリーおよび接続)の再利用が可能になり、ラウンドトリップ・データ転送が削減されます。
ベクトル距離計算
ベクトルは、人間がベクトル空間の位置(ベクトルの多次元マッピング)に認識するように、データ・オブジェクトのセマンティック・コンテキストを変換できるようにします。あるデータ・オブジェクトと別のデータ・オブジェクトのセマンティック類似性を判断するために、これらのデータ・オブジェクトを表すベクトルの近接性が計算されます。ベクトルが互いに近ければ近いほど、ベクトルはより類似しています。逆に、距離が大きいほど、近似性は少なくなります。Exadataでは、ベクトル距離を計算するタスクがAIスマート・スキャンに与えられます。2つのベクトル間の距離を比較することはほとんどなく、数百万または数十億のベクトルを比較する可能性が高いことに注意してください。ベクトルのスキャンを並列化するだけでなく、ベクトル距離計算をストレージ・サーバーにプッシュ・ダウンすることで、不必要にデータをデータベース・サーバーに移動することを回避し、かわりにストレージ・サーバー上の高パフォーマンスなデータベース・カーネルの最適化を利用して、AIベクトル検索問合せを最大30倍高速化します。
ストレージ・サーバーのTop-K
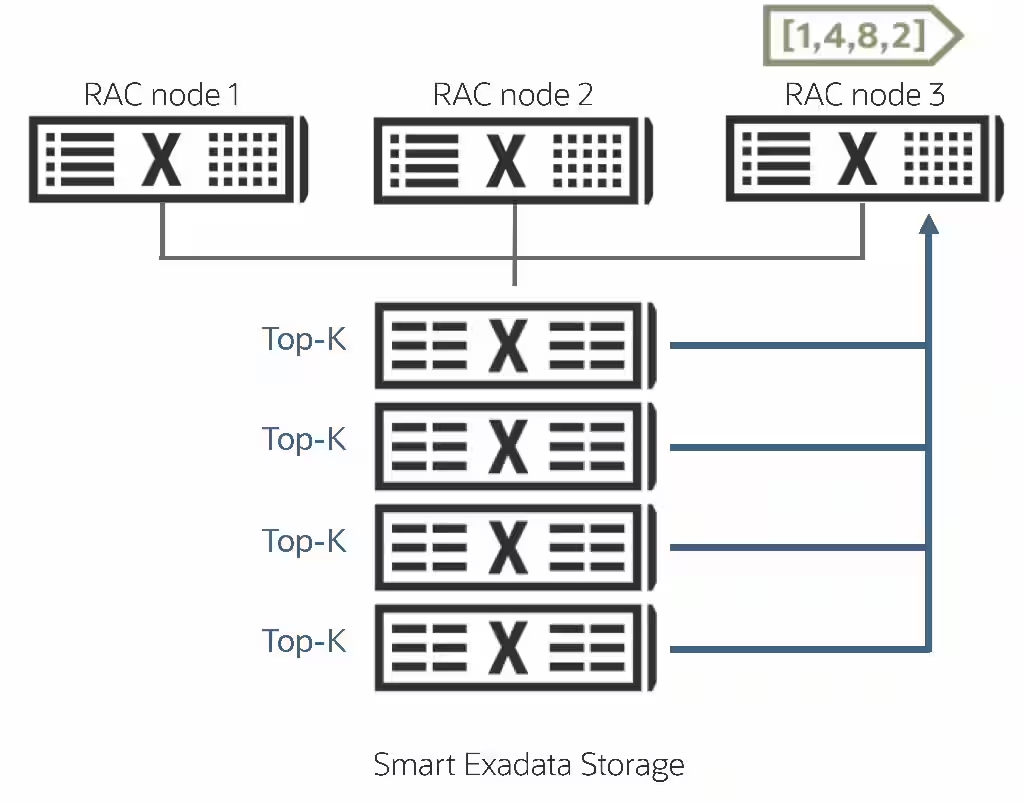
AI Vector Searchは、本質的に、正確な値の一致ではなく、類似性検索(概算検索)です。前述の簡単な例を考えてみます。「過去5年間に公開されているエンタープライズ・ユース・ケースで、大規模言語モデル(LLM)のファイン・チューニングに関する記事を見つけてください。」この問合せでは、LLMに関する要件を意味的に概算する記事を検索し、過去5年間のエンタープライズ・ユース・ケースを記述します。この問合せでは完全一致を期待していません。最も近い記事を期待しています。これは、Top-K(Kは、戻したい類似記事の数を表します)と呼ばれます。
Oracle Database 23aiでは、ベクトルを効率的に格納するために、AIベクトル検索の Inverted File Flat(IVF)専用に最適化された新しい索引が導入されました。この索引は、検索領域を大幅に削減し、データベース・サーバーからストレージ・サーバーにTop-K計算をオフロードするためにAIスマート・スキャンによって使用され、データベース・サーバーへの大規模なデータ移動が再び回避されます。各ストレージ・サーバーからのTop-Kがデータベースに返されるため、データベースによる全体的なTop-Kの最終決定が非常に効率的です。AIスマート・スキャンでは、インメモリー・カラム形式、SIMD処理、スマート・フラッシュ・キャッシュとExadata RDMAメモリー(XRMEM)データ・アクセラレータ、ベクトル距離計算(上記を参照)の実行時における高パフォーマンス・データベース・カーネルとストレージ・サーバーへのTop-K計算など、多くのExadataの優れたパフォーマンス最適化を利用して、ベクトル処理を大幅に高速化します。
ストレージ・サーバーでのメモリー速度でのベクトル検索
IVF索引(前述を参照)は、Oracle Database内にパーティション表として作成されます。各パーティションは、ベクトルの集合を表します。Exadata上の任意の表構造と同様に(この場合は索引として使用しますが)、最もホットなデータは自動的に透過的にデータベース・インメモリー列形式に変換され、Exadataフラッシュ・キャッシュに配置されることで、AIスマート・スキャンの問合せが高速化されます。このブログで後述するように、この列データの最もホットなデータは自動的にXRMEMに昇格され、AIスマート・スキャンがさらに加速され、膨大なデータ量にわたってメモリー速度でAIベクトル検索を実行できるようになります。
Exadata Exascale
Exascale Exascale (Exascale)は、ストレージ管理の分離と簡素化によってコンピュート・リソースとストレージ・リソースがExadataプラットフォームでどのように管理されているかを再考し、革新的な新機能への道を開きます。これにより、組織がExadataに期待する、業界をリードするデータベース・パフォーマンス、可用性およびセキュリティ標準が保証されます。
Exascaleの画期的な機能の1つは、Exadata上のデータベース・スナップショットおよびクローンに対する再考されたアプローチです。これにより、任意の読取り/書込みデータベースまたはプラガブル・データベースの領域効率の高いシン・クローンが可能になり、開発者の生産性が大幅に向上します。Exascaleは開発、テストおよびデプロイメント・パイプラインの要件とシームレスに統合され、ネイティブのExadataパフォーマンスを提供します。
Exascale上のデータベースは、Exascaleストレージ・クラウドで使用可能なすべてのストレージに自動的に分散されるため、I/O用の超低レイテンシのRDMAと、すべてのワークロードで使用可能な最大数千のコアを備えたデータベース対応のインテリジェント・スマート・スキャンが提供されます。複数のストレージ・サーバー間での自動データ・レプリケーションにより、フォルト・トレランスと信頼性が確保されます。
ACFSやXFSなどの仮想マシンおよびLinuxファイルシステムでもExascaleを利用できます。新しいExascaleブロック・ボリュームは、ブロック・デバイスI/Oへの超低レイテンシRDMAを提供し、仮想マシン・イメージ・ファイルやその他のファイルシステムを共有ストレージでホストします。ExascaleボリュームでExadata仮想マシン・イメージ・ファイルをホストすると、Exadataの一意のRDMA対応データベース・ワークロードに対して、物理データベース・サーバー間のシンプルで高速なオンライン移行が可能になります。これにより、短期的に計画された物理サーバー・メンテナンス中に仮想マシンのダウンタイムとパフォーマンスのブラウンアウトが大幅に削減され、オンライン仮想マシンの移行が終わり、長期的に物理サーバー・メンテナンスを行うための仮想マシンのダウンタイムがなくなります(注1)。
Exascaleは、既存のExadataデプロイメントと共存するように設計されているため、お客様は自社の機能をいつ利用するかを選択できます。
Exadata Exascaleの詳細は、Exadata Exascaleのアナウンスブログで入手できます。
JSON問合せのインメモリー列速度での実行
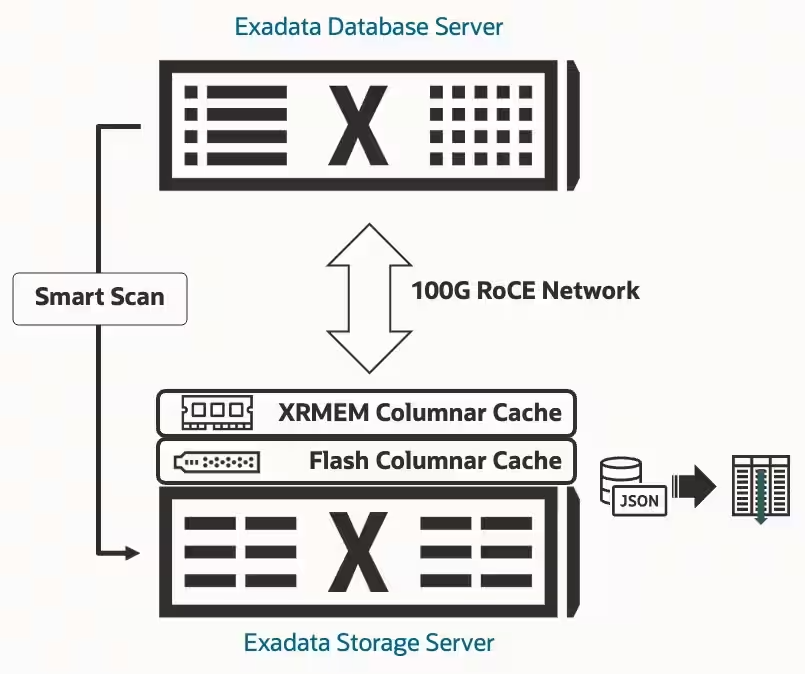
JSONデータ形式は、データ交換の事実上の標準です。軽量構造なことと、機械や人間両方からの可読性により、アプリケーション開発に広く用いられています。Oracle Database 19cに初めてサポートが追加されたことで、Oracle Databaseに格納されているJSONデータに対して分析を実行する必要があるため、OracleでのJSONとストレージの使用が大幅に増加しました。
JSONドキュメントに格納されたデータに対する分析を高速化するために、ExadataはJSONドキュメント(DB 19c の OSONフォーマットと、DB 23aiのネイティブJSONデータ型)をDatabase In-Memory列形式に自動的かつ透過的に変換し、フラッシュ・キャッシュにロードします。インメモリー列形式は、Exadata System Software 12.2.1.1.0 (2017年にリリース)からExadataで使用でき、Database In-Memory機能(Oracle Database 12.2で導入)をストレージ・サーバーのフラッシュ領域に拡張して、列データ処理の容量を大幅に増やします(ストレージ・サーバー当たり最大27.2TBのフラッシュが搭載されています)。Exadata Storage Serversでは、これをインメモリー・カラムナー・キャッシュと呼びます。JSONドキュメントに格納されているデータをストレージ・サーバー上のインメモリー列形式に変換することで、分析問合せのスループットは最大4.4倍、レイテンシーは最大4.4倍の低レイテンシを実現できます。つまり、JSONデータに対する分析クエリがますます高速化されます。
メモリー速度でのカラムナー・スマート・スキャン
Exadata RDMAメモリー(XRMEM)は、Exadata X8M 以降の新しいExadataストレージ・サーバーのメモリーを使用して、最もホットなOLTPデータをメモリーにキャッシュするデータ・キャッシュ層です。Oracle Database 19c以降では、リモート・ダイレクト・メモリー・アクセス(RDMA)を使用して、データベース・サーバーと同じようにストレージ・サーバー内のデータを読み取り、Exadata X10Mストレージ・サーバー上の単一ブロック読取りレイテンシを17マイクロ秒まで短縮します。
ちょっと待ってください、インメモリー列キャッシュは分析に有益であると述べました。OLTPの高速化に使用されるXRMEMについて説明するのはなぜでしょうか?
質問を頂けて嬉しく思います。Exadata System Software 24ai以降、Exadata X10Mは、OLTPデータと同様に、最もホットな列形式データをFlashからXRMEMに自動的かつ透過的にポピュレートします。スマート・スキャンでは、メモリー内の列データに直接アクセスし、分析問合せを最大6.5倍高速化し、新しいAIスマート・スキャン機能を使用して、OLTPライクなAIベクトル検索問合せを1秒未満で実行できるようになりました。
透過層間スキャン
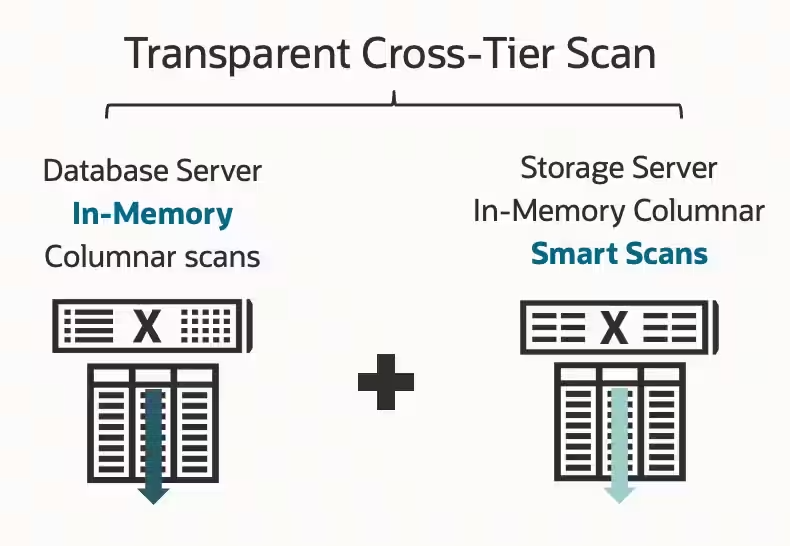
Exadataは、2017年以降、Database In-Memory (IM)列形式をストレージ・サーバーに拡張しました。ExadataでDatabase In-Memoryオプションを使用すると、データをデータベースに格納し、ストレージ・サーバーにインメモリー列形式で格納できます。インメモリー列データを使用する場合、データベース・オプティマイザは、データベースまたはストレージ・サーバー上のIM列ストアを読み取るかどうかを決定する必要がありますが、両方からは読み取ることはできません。処理されるデータの量によっては、データベース・ストアまたはストレージ・コラム・ストアのみを使用することが適切である場合がありますが、問合せで必要なデータ量がデータベースとストレージ・サーバーの両方にまたがる場合、この選択によって実行計画が最適でない可能性があります。
Exadata System Software 24ai と Oracle Database 23aiでは、透過層間スキャンを使用することが出来るようになりました。透過層間スキャンによって、データベース・オプティマイザは、データベース上のインメモリー列ストアとストレージ・サーバーのいずれかを選択する必要がなくなりました。単一の問合せ(シリアル問合せまたはパラレル問合せとして実行)で、データベース・サーバー上のインメモリー・ストアのスキャンと、スマート・スキャンを使用したストレージ・サーバー上のFlashおよびXRMEM内のインメモリー列形式のデータをスキャンの両方が実行できます。
SIMD処理、データ・プルーニング、ディクショナリ・エンコーディング、データ圧縮などのCPU最適化により、透過的層間スキャンは、データベースおよびストレージ・サーバーのインメモリー機能を使用した分析問合せを最大3倍高速化します。
大きいテーブルでのハッシュ結合の高速化
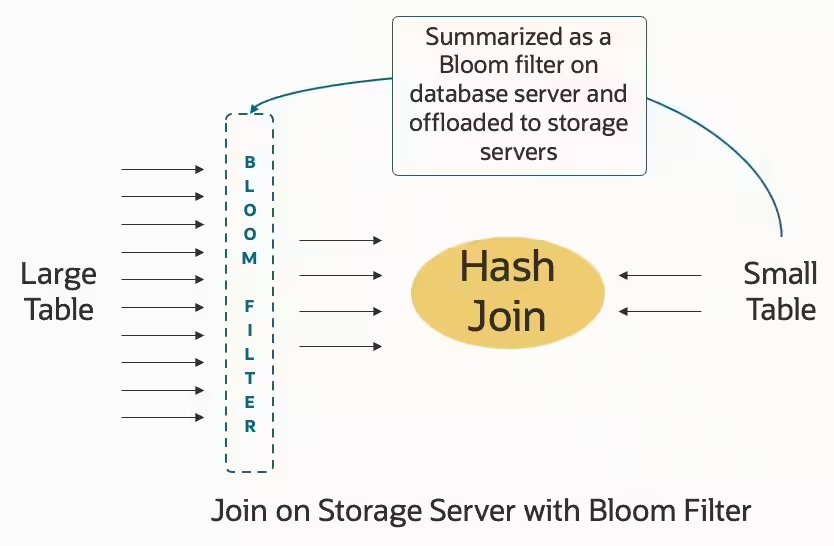
アナリティクスやレポート・ワークロードは、膨大な量のデータを操作し、複数の大きな表のデータを結合して、複数年にわたるデータのインサイトとトレンドを提供します。このようなワークロードで表を結合する主な方法は、ハッシュ結合です。
Exadataは2008年のリリース以来、Oracle Databaseでは、ブルーム・フィルタを使用してハッシュ結合を最適化しています。ブルーム・フィルタは、結合内の小さい方の表のサマリーとみなすことができます。これにより、データベース・オプティマイザは、小さい方の表に要素(大きい方の表の行)が存在するかどうかの確率を迅速にテストできます。この確率テストにより、データベースでは一致しない行を非常に迅速に破棄でき、ハッシュ結合の有効性が向上します。Exadataでは、ストレージからデータベース・サーバーへの破棄される不要なデータのプル(データベースサーバーに転送すること)と、複数のストレージサーバーが並列にハッシュ結合が分散されることを回避するために、これらのブルーム・フィルタを常にストレージ・サーバーにオフロード(プッシュダウン)しています。
ブルーム・フィルタは、データベースに格納されるオブジェクトではありませんが、比較的小さいにもかかわらず、ストレージ・サーバー上のメモリーが必要です。表が大きくなると、ブルーム・フィルタの潜在的なサイズも増加します。Exadataは世代が新しくなる毎に、ストレージ・サーバーのメモリー容量が増加しました。Oracle Database 23aiでは、ストレージ・サーバーにオフロードされたブルーム・フィルタのサイズが大幅に増加し、より大きな表に対応できるようになり、ストレージ・サーバーはデータが存在する場所でより多くの作業を行うことができます。
ストレージ・サーバーにオフロードされたブルーム・フィルタのサイズを増やすことで、分析問合せのパフォーマンスが最大2倍向上します。これは、アプリケーションのSQLを変更せずに高速化できます。
データの暗号化
データ・セキュリティ、特にデータ暗号化は、日々の会話において永続的なトピックとなり、オンプレミスおよびクラウドにおけるOracleデータベースの一般的な要件となっています。Oracleでは、Oracle Cloud Database Service (Exadata Database Service on Cloud@Customer、Exadata Database Service on Dedicated Infrastructure (Database@AzureおよびDatabase@Googleを含む)、Base Database Service、および多くのAutonomous製品)でのTransparent Data Encryption (TDE)の使用が義務付けられています。
OracleデータベースをOracle Cloud Infrastructureに移行する場合、またはオンプレミス・データベースでTDEを使用する場合でも、暗号化プロセスを実行するためにデータベース・ファイルが必要です。クラウドでは、暗号化はデータベースの移行中に行われます。オンプレミス暗号化では、暗号化の実行時期をより詳細に制御できます。ただし、どちらの場合も、多くのお客様がこれらのデータベースを移行後および暗号化中にすぐに使用できるようにする必要があります。Oracle Database 12cR2 (12.2)以降、オンライン暗号化が利用可能です。従来は、Exadataに存在するデータベースでは、表領域(およびデータファイル)内のデータが暗号化を実行している最中にスマート・スキャンは無効になり、パフォーマンスが低下する可能性がありました。
Oracle Database 23aiでは、スマート・スキャンは暗号化処理中も常に使用可能になり、最大4倍の高速な分析問合せパフォーマンスを提供します。また、スマート・スキャンでは、Oracle Database 23aiで追加されたTDE表領域暗号化のAES-XTS暗号化モードがサポートされています。さらに、スマート・スキャンは、オンライン再入力および関連する操作中に使用でき、暗号化および暗号化されていないデータを自動的かつ透過的に処理します。
索引構成表(Index-Organized Table)
索引構成表(IOT)は、オンライン取引、支払、小売プラットフォームなどの高スループットを求められるOLTPアプリケーションに適しています。データ取得キーとともにデータをBツリー索引構造に格納し、高速アクセスと分析で使用されるデータの事前ソートを実現します。Oracle Database 23aiおよびExadata System Software 24ai以降、IOT(圧縮IOTを含む)はスマート・スキャンを使用できるようになりました。スマート・スキャンを使用したIOTの分析問合せは最大13倍高速になります。
ワイドテーブル
Oracle Database 23aiでは、表に含まれる列数が1000から4096に増加しました。一部のワークロードおよびアプリケーションは、表の1000列が不足している時点までデータを非正規化するように設計されています。このような状況では、複数のテーブルを結合することは、理想的ではありませんが、よく使用される回避方法でした。列制限を大きくすると、非正規化データの複雑さが軽減されます。Exadataでは、表の幅の増加は透過的かつ自動的にスマート・スキャン(SQLオフロード)によって処理されます。
タイムゾーンのアップグレード中のスマート・スキャン
国によっては、タイム・ゾーンを変更したり、夏時間(DST)の処理方法を調整したりして、更新済タイム・ゾーンおよびDSTデータをデータベースにロードすることが継続的に必要になる場合があります。通常、この新しいタイム・ゾーン・データはOracle Databaseの更新およびパッチとともに出荷されますが、お客様は必要に応じてデータベースにインストールすることを選択できます。Database 21cでは、新しいタイムゾーン・データをインストールしても、データベースの停止は不要になりました。データベースに適用されるほとんどの更新およびパッチとは異なり、タイム・ゾーンの更新によってメタデータおよび表データが変更される可能性があることに注意してください。
Oracle Database 23aiより前は、タイム・ゾーン・データの更新中にタイム・ゾーン列を含む表に対する問合せにスマート・スキャンを使用できませんでした。Oracle Database 23aiでは、表がTIMESTAMP WITH TIME ZONEデータ型を含まないかぎり、タイム・ゾーン列を含む表に対する問合せに対してスマート・スキャンが使用可能なままであるため、タイム・ゾーン・データの更新時の問合せスループットが向上します。
新しい関数と演算子のスマート・スキャン・オフロード対応
Oracle Database 23aiでは、BOOLEANデータ型が追加され、TRUEおよびFALSEの真理値の格納および処理が簡略化されます。BOOLEANデータ型とともに、TO_BOOLEAN()関数および’IS FALSE’、’IS NOT FALSE’、’IS TRUE’および’IS NOT TRUE’述語演算子が追加されました。Oracle Database 23aiでは、新しいDate CEILおよびFLOOR関数とInterval CEIL、FLOOR、ROUNDおよびTRUNC関数も追加されています。これらすべての演算子および関数は、Exadata System Software 24aiのスマート・スキャンに含まれており、分析問合せのパフォーマンスが向上しています。
パイプライン・ログ書込み

REDOログ書込みレイテンシは、オンライン・トランザクション処理(OLTP)アプリケーションの全体的なパフォーマンスにとって常に重要です。REDOログが永続メディアに書き込まれると、トランザクションはより早くファイナライズされます。Exadataでは、Smart Flash Log Write-Back 機能によって、REDOログがライトバック・モードでフラッシュ・キャッシュに自動的かつ透過的にキャッシュされるため、フラッシュに書き込むことで、潜在的なパフォーマンス・ボトルネックとしてのハード・ディスク待機時間がなくなります。Smart Flash Log Write-Back は、Exadata Smart Flash Log と透過的に結合され、同時にログ書込みを2つのフラッシュ・ドライブに送信して書込みI/Oレイテンシを排除します。
Oracle Databaseでは、通常、各REDO書込みがシリアル操作およびアトミック操作として処理されます。つまり、次のREDO書込みがストレージに発行される前に、前の書込みが受信済として確認され、ストレージに書き込まれる必要があります。Exadata X10Mでは、データベースは、データベースとストレージ・サーバー間の超高速ネットワーク、超高速フラッシュおよび前述の最適化にアクセスできます。Oracle Database 23ai (およびDatabase 19c RU22 2024年1月)のログ・ライター・プロセス(LGWR)は、後続のREDO書込みリクエストを送信する前に、以前のログ書込みの確認応答を待機しなくなりました。LGWRは、最後のリクエストが動作している間、次のREDO書込みの送信を開始します。この書込みリクエストの重複により、データベース・サーバーからストレージ・サーバーへのREDOログ書込みのパイプラインが作成され、最大1.45倍のトランザクション処理が改善されます。
Exadataフラッシュ・キャッシュへの自動KEEPオブジェクト・ロード
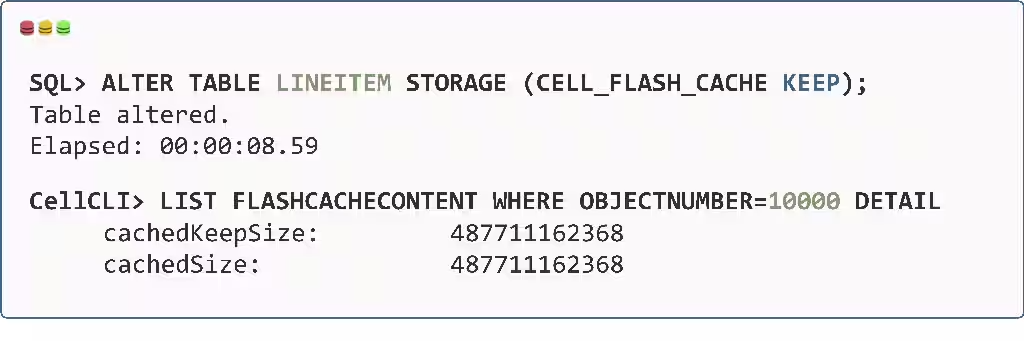
一部のOLTPワークロードでは、スマート・フラッシュ・キャッシュに表を永続的に固定することでメリットが得られます。従来、管理者は、データベース内の表定義を変更してCELL_FLASH_CACHE KEEP属性を追加し、全表スキャンを開始してフラッシュ・キャッシュへの表のロードを開始することで、このような表を事前にフラッシュにKEEPできました。
Oracle Database 23aiおよびExadata System Software 24ai以降では、データベースから全表スキャンを手動で実行する必要がなくなりました。次のように表を変更すると、ストレージ・サーバーがフラッシュ・キャッシュへの表のロードを自動的に開始します。
通常、フラッシュ・キャッシュ内の表のKEEPは必須でも推奨でもありませんが、絶対に100%のフラッシュ・キャッシュ・ヒット率を達成する必要がある表がある場合は、この方法を使用します。
該当する表のロード・プロセスは、CellCLIを使用し ‘list flashcache content where objectnumber=<table_object_number> detail’を実行することで監視できます。
まとめ

Oracle Database 23aiのリリースは刺激的です。オラクルのフラグシップ・データベースの最新の長期サポート・リリースを表し、AI Vector Search、JSON Relational Duality、Priority Transactions、SQL Firewall、Readable Per-PDB Standby、300以上の新機能が豊富に含まれています。Exadata、オンプレミスまたはクラウド、およびExadata System Software 24aiでは、データ管理要件を満たすのに役立つ、パフォーマンス、セキュリティ、使いやすさの大幅な機能を使用できます。
詳細は、次の貴重なリソースを参照してください。
- Exadata System Software 24aiの新機能に関するドキュメント
- My Oracle Supportノート- Exadata Database MachineおよびExadata Storage Serverのサポートされるバージョン(ドキュメントID 888828.1)
- My Oracle Support Note – Release Schedule of Current Database Releases (Doc ID 742060.1)
- Oracle Database 23ai新機能ガイドのドキュメント
- Oracle Database一般提供のお知らせ
(注1)将来のリリースで対応予定
