※ 本記事は、Amar Gowda, Sowmya Srinivasa Raghavan, Sid Padgaonkarによる”Serving Llama 3.1 405B model with AMD Instinct MI300X Accelerators“を翻訳したものです。
2024年11月12日
以前のブログ記事で、当時最も人気があり最大のLlamaモデルであるLlama 2 70B生成AI(Gen AI)大規模言語モデル(LLM)を提供するAMD Instinct MI300X Acceleratorのパフォーマンスについて説明しました。LLMサービング・アーキテクチャとユース・ケースは同じままですが、Metaの3番目のバージョンのLlamaは、使いやすさと正確性を大幅に向上させます。この新しいモデルであるLlama 3.1は、4050億個のパラメータを持つはるかに大規模なモデルを備えており、推論のニーズにより多くのGPUメモリーと処理が必要です。このブログ投稿では、MI300Xシェイプ(BM.GPU.MI300X.8)を使用したOracle Cloud Infrastructure (OCI) Computeを使用したLlama 3.1のベンチマークについて説明します。
各BM.GPU.MI300X.8シェイプには、8つのMI300X GPUアクセラレータが付属しており、それぞれに192 GBのHBM3メモリーと5.2 TB/秒のメモリー帯域幅があり、合計で1.53 TBのメモリーがあり、仕様の詳細はこちらを参照してください。この機能を使用すると、大規模なLLMモデルを実行し、推論リクエスト中により多くの同時ユーザーに対応できます。Llama 3.1 405B FP8モデルの単一インスタンスのパフォーマンスを単一のOCIベア・メタル・インスタンスでテストしました。8つすべてのGPUが、次に示す番号に対応するために割り当てられました。
LLMサービス・パフォーマンス
レイテンシ測定
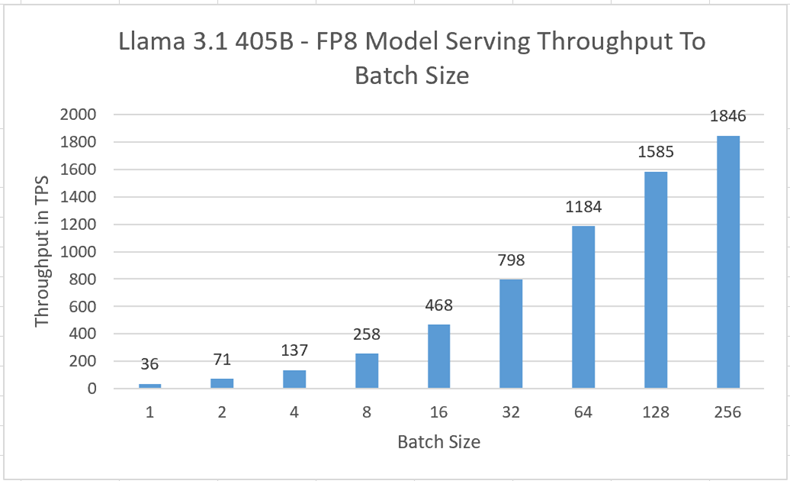
オフライン・ベンチマークは、vLLMのscripts/benchmark_latency.pyを使用して測定されました。各テストには、入力サイズが128、出力サイズが128のトークンがありました。
| Batch Size | トークン単位の出力スループット(TPS) | 平均レイテンシ(秒) |
| 1 | 36 | 3.530 |
| 2 | 71 | 3.583 |
| 4 | 137 | 3.734 |
| 8 | 258 | 3.974 |
| 16 | 468 | 4.375 |
| 32 | 798 | 5.130 |
| 64 | 1184 | 6.919 |
| 128 | 1585 | 10.340 |
| 256 | 1846 | 17.750 |
スループット測定
次の表に、vLLMでbenchmark_throughput.pyを使用して測定されたオフライン・ベンチマークを示します。
| シナリオ | トークンの入力サイズ | トークンの出力サイズ | TPSの出力スループット |
| 一般的なチャットボットのオンライン・シナリオ | 128 | 128 | 1993 |
| 世代重視のユース・ケース | 128 | 2048 | 2794 |
| 入力トークン・サイズが大きい要約ユース・ケース | 2048 | 128 | 316 |
| 要約と出力生成の重さ | 2048 | 2048 | 1807 |
どちらのテストでも、次の構成を使用:
- BM.GPU.MI300X.8シェイプの米国東部(アッシュバーン)リージョンにある8 GPUのAMD MI300X。
- ホスト6.2のAMD ROCmバージョン
- Llama 3.1 405B – FP8 AMDの定量化モデル
- 最新のコンテナとパラメータの推奨事項 from – powderluv/vllm-docs: vLLM Dev Channelリリースのドキュメント(github.com)
- vLLM version 0.6.1
- ベンチマーク・スクリプト from vLLM for レイテンシとスループット
まとめ
LLMモデルの推論は、企業内で最も一般的に採用されているユース・ケースです。その結果、8つのAMD MI300X GPUを搭載した単一のOCI Computeベアメタル・インスタンスで、大型のLLMモデルにサービスを提供する効率性が明らかになりました。405Bモデルの単一インスタンスでは、1ユーザー当たり最大256の同時使用をサポートでき、一般的な人間の読取り速度5 TPSを上回ります。70Bや8Bなどの小規模なLLMモデルなど、1つのコンピュート・ノードで複数の小規模なモデル・インスタンスを実行して、単一ノードの合計スループットを向上させ、Gen AIワークロードに対応するコンピュート・コストをより適切に管理することもできます。
この実験を繰り返したい、あるいは新しいシナリオを試してみたいという方は、ローンチの投稿を確認するか、オラクルにご連絡ください。次の投稿では、シングルノードとマルチノードの両方の設定について、機械学習(ML)のファインチューニングとMLのトレーニング・パフォーマンスの数値をMI300Xと共有する予定です。お客様がカスタム・データセットと一般的なオープンソースの基盤モデルを使用してモデルをファインチューニングする一般的なユース・ケース。お待ちください!
詳細は、次のリファレンスを参照してください
- AMD MI300X 新規OCIシェイプGAの発表
- AMD Instinct MI300X GPU (oracle.com)による初期のLLMサービス・エクスペリエンスとパフォーマンス結果
- AMD Instinct™ MI300X Accelerators
