In a previous blog post, we discussed AMD Instinct MI300X Accelerator performance serving the Llama 2 70B generative AI (Gen AI) large language model (LLM), the most popular and largest Llama model at the time. The LLM serving architectures and use cases remain the same, but Meta’s third version of Llama brings significant enhancements to usability and accuracy. This new model, Llama 3.1, features a much larger model with 405 billion parameters, requiring more GPU memory and processing for inference needs. This blog post covers benchmarks for Llama 3.1 with Oracle Cloud Infrastructure (OCI) Compute with MI300X shape (BM.GPU.MI300X.8).
Each BM.GPU.MI300X.8 shape comes with eight MI300X GPU accelerators, each with 192 GB of HBM3 memory and 5.2 TB/s memory bandwidth, totaling 1.53 TB of memory, more details on specification can be found here. This capability is helpful for running larger LLM models and serving more concurrent users during inference requests. We tested the performance of a single instance of the Llama 3.1 405B FP8 model on a single OCI bare metal instance. All eight GPUs were assigned for serving the numbers reported below.
LLM serving performance
Latency measurements
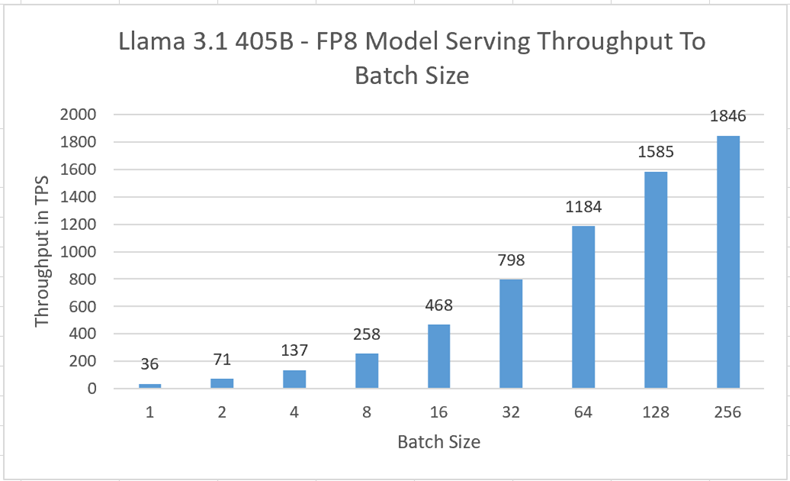
Offline benchmarks were measured using the scripts/benchmark_latency.py in the vLLM. Each test had input size 128 and an output size 128 tokens.
| Batch Size | Output throughput in token per second (TPS) | Average latency in seconds |
| 1 | 36 | 3.530 |
| 2 | 71 | 3.583 |
| 4 | 137 | 3.734 |
| 8 | 258 | 3.974 |
| 16 | 468 | 4.375 |
| 32 | 798 | 5.130 |
| 64 | 1184 | 6.919 |
| 128 | 1585 | 10.340 |
| 256 | 1846 | 17.750 |
Throughput measurements
The following table shows offline benchmarks measured using benchmark_throughput.py in the vLLM.
| Scenario | Input size in tokens | Output size in tokens | Output throughput in TPS |
| Typical chatbot online scenario | 128 | 128 | 1993 |
| Generation heavy use case | 128 | 2048 | 2794 |
| Summarization use case with larger input token size | 2048 | 128 | 316 |
| Summarization and output generation heavy | 2048 | 2048 | 1807 |
For both the tests we used the following configuration:
- 8 GPUs of AMD MI300X in US East (Ashburn) region on BM.GPU.MI300X.8 shape.
- AMD ROCm Version on host 6.2
- Llama 3.1 405B – FP8 quantized model from AMD
- Latest container & parameter recommendations from – powderluv/vllm-docs: Documentation for vLLM Dev Channel releases (github.com)
- vLLM version 0.6.1
- Benchmarking Scripts from vLLM for latency & throughput
Conclusion
LLM model inference is the most common and well adopted use case within enterprises. The results underscore the efficiency of serving large-sized LLM models in a single OCI Compute bare metal instance with eight AMD MI300X GPUs. A single instance of a 405B model can support up to 256 concurrent uses delivering over 7 TPS per user, well above the typical human reading speed of 5 TPS. You can also run multiple smaller model instances in a single Compute node, such as smaller sized LLM models like 70B or 8B, to increase the total throughput of a single node and better manage your compute costs catering your Gen AI workloads.
If you’re excited to repeat this experiment or try new scenarios, review the launch post or reach out to us. In our next post, we plan to share machine learning (ML) finetuning and ML training performance numbers with MI300X for both single-node and multi-node setup. A popular use case where customers fine tune a model using custom datasets and popular open-source foundation model. Stay tuned!
For more information, see the the following references
- AMD MI300X New OCI Shape GA Announcement
- Early LLM serving experience and performance results with AMD Instinct MI300X GPUs (oracle.com)
- AMD Instinct™ MI300X Accelerators


