※本ページは、”Announcing Exadata System Software 25ai Release 25.2” の翻訳です。
Exadata System Software 25aiの発表
Exadata製品管理およびエンジニアリング・チームは、Exadata System Software 25ai (リリース25.2)が利用可能になったことをお知らせします。これは、オンプレミスとクラウドでExadataを強化する最新のデータ・インテリジェント・ソフトウェアです。このリリースには強力な新機能が含まれており、ExadataのリーダーシップをOracle Databaseの優れたプラットフォームとして拡張しています。このリリースで注目されている内容の概要を次に示します。
- 独自のAIスマート・スキャンの高速化
- 卓越したパフォーマンス
- Exascaleにおけるイノベーション
- セキュリティ、管理性、可観測性に優れたインフラストラクチャ
独自のAIスマート・スキャンの高速化
ネイバーパーティションベクトルインデックスによるAIスマートスキャン
お客様は、既存のビジネス・データでOracle Database 23aiのAI Vector Searchを使用して、検索のコンテキストと関連性を高めます。たとえば、house(家)の参照イメージに最も類似した上位5軒のhouse、および希望する価格範囲内(price)および特定の場所(zipcode)を検索できます。Oracle Database 23aiでは、これらのすべての属性(houseのイメージを含む)を列として同じ表に格納できます。Oracle Databaseでは、イメージの様々な属性をカプセル化するベクトルとしてイメージのセマンティック表現を作成し、ベクトル類似性検索を実行して類似のhouseを検索できます。価格(price)や郵便番号(zipcode)などのリレーショナル属性を使用して結果をフィルタし、希望する上位5軒のhouseを生成できます。
たとえば、price列およびzipcode列とともに、各houseのベクトル表現を含むhouse表に対する問合せは次のように記述できます。
SELECT price FROM houses t WHERE price < 2000000 AND zipcode = 94065 ORDER BY VECTOR_DISTANCE(description_vector, :query_vector) FETCH APPROX FIRST 5 ROWS ONLY;
Oracle Database 23aiは、AI Vector Searchの初期リリース以降、類似性検索を高速化するためのベクトル・データのインデックスをサポートしてきました。Oracle Database 23.7では、ネイバー・パーティション・ベクトル索引(IVF索引)に非ベクトル列を含めることが可能になり、ベクトル検索がさらに最適化されます。これらの列を含めると、データベースはセカンダリROWIDベースの参照をスキップし、I/Oを削減し、検索を高速化できます。前述の例でいうと、Neighbor Partition Vector Indexは、houseのイメージとの類似性を判断するために使用されるベクトルだけでなく、同じ表に格納されているprice列とzipcode列を含めて(included columns)作成できるようになりました。たとえば、索引定義は次のようになります。
CREATE VECTOR INDEX house_idx ON houses(description_vector) INCLUDE (price, zipcode) ORGANIZATION NEIGHBOR PARTITIONS;
Exadata System Software 25.2では、インデックスにIncluded Columns(含まれる列)としてクエリーに必要なすべてのカラムが含まれている場合、データをインデックスから直接取得できるため、クエリーのパフォーマンスが向上します。さらに、Included Columns としてindexに定義された price列およびzipcode列に対するフィルタリング操作は、ベクトル距離とともに、ベクトル索引のみを使用してストレージ・サーバーに高度に並列化された方法でオフロードされます。これにより、以前のデータベース・リリースと比較して、AI Vector Search問合せが最大3倍高速化されます。
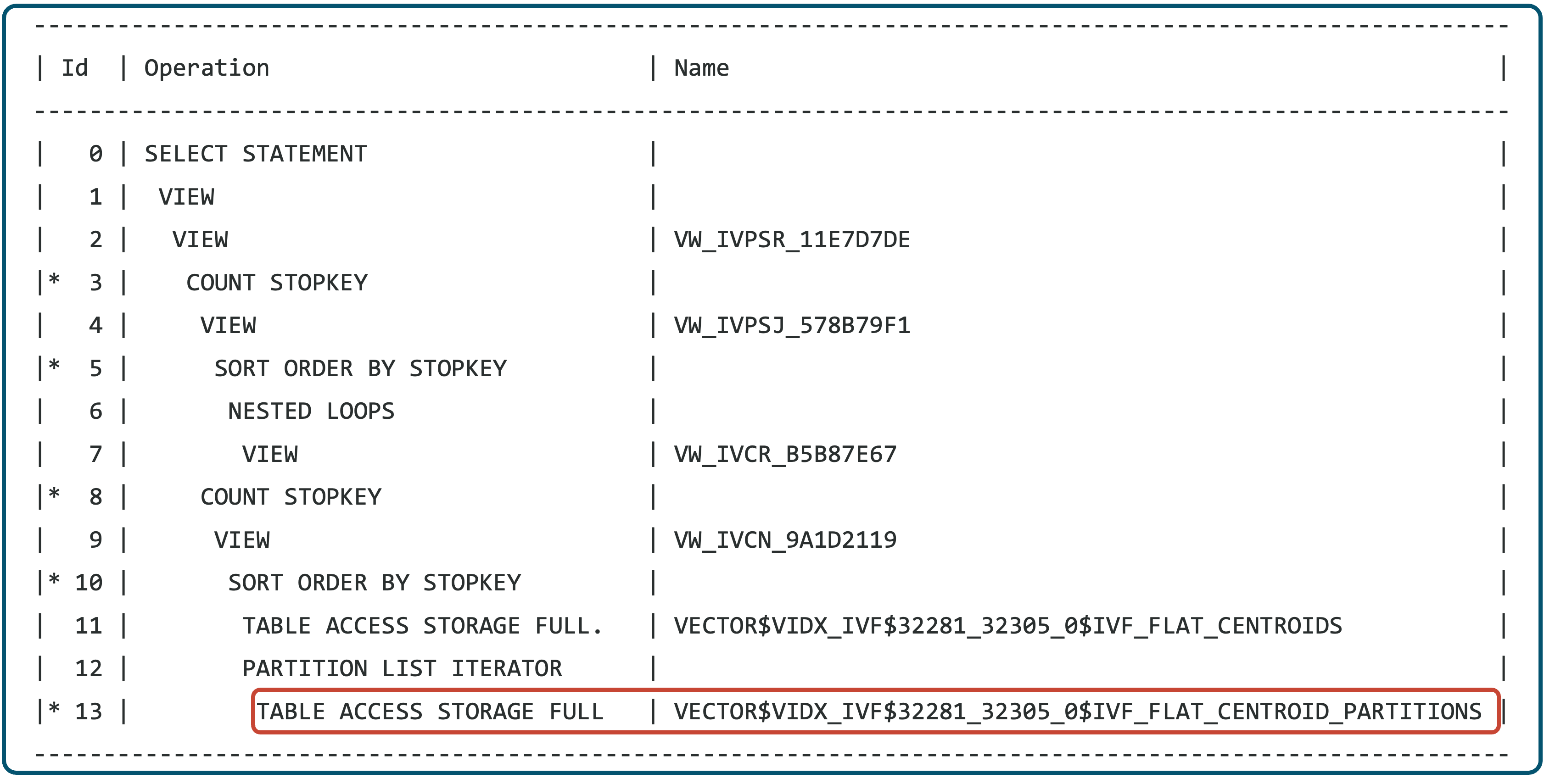
SPARSE ベクトル・データ型に対する問合せの高速化
AIベクトル検索では、スペース効率の高いSPARSEベクトルがよく利用されます。このSPARSEベクトルは、通常、多数の次元がありますが、ゼロ以外の次元値はほとんどないベクトルです。SPARSEベクトルは、SPLADEやBM25などのSPARSEエンコーディング・モデルを使用して作成され、通常はキーワードベースの検索では他のベクトル(DENSEベクトル)よりもパフォーマンスが優れています。SPARSEベクトルの各次元は、特定の語彙のキーワードに対応するベクトルと考えることができます。ドキュメント内のキーワードの出現ごとに、対応する次元値はゼロ以外の値を受け取ります。この値は、ドキュメント内のキーワードの存在と頻度の両方を示します。SPARSEベクトルは、ゼロ以外の値のみが格納されるため、非常に領域効率が高くなります。
たとえば、次の例は、SPARSEベクトル(incident_text列)を持つ表の作成を示しています。この表には、ゼロ以外の値が指定されるディメンションの位置が示されます。

この新しいリリースでは、Oracle Database 23.6で導入されたSPARSEベクトルのベクトル距離計算をシームレスにストレージサーバーにオフロードして問合せを加速します。
卓越したパフォーマンス
一時データのフラッシュ・キャッシュの独自の最適化
分析問合せでは、結合、ソートおよび集計処理の中間結果の書込みに一時データ(TEMP segment)が使用され、Exadataでは、多くの場合、このデータはExadata Smart Flash Cache に書き込まれます。
Exadata System Software 25.2およびOracle Database 23ai以降、Exadataは、このデータをハード・ディスクに永続化させることなく、TEMP I/O書込みによって占有されていたフラッシュ領域を独自にリクレイムします。このインスタント・フラッシュ再利用機能により、ハード・ディスクへの書込みが不要になり、問合せワークロードが多くのRACインスタンスおよびデータベースでスケーリングされる場合でも、効率的な一時データ・キャッシングが保証されます。その結果、分析問合せは1.6倍高速になります。
ストレージ・サーバーのメンテナンス後も高いI/Oパフォーマンスを実現
Exadataは、高い可用性のために複数のストレージ・サーバー上のフラッシュ・キャッシュにデータを同時に自動的にキャッシュします。ソフトウェアの更新やハードウェアの交換などのメンテナンス後は、フラッシュを含むストレージ・サーバーを他のストレージ・サーバーと再同期する必要があり、作業データ・セットへの追加はフラッシュにキャッシュ(リウォーム)する必要があります。データベースからのクエリーで、まだウォーム更新されていないデータをフラッシュからリクエストすると、ストレージ・サーバーによってディスクからフラッシュが自動的に再移入されます。
Exadata System Software 25.2およびOracle Database 23aiでは、フラッシュからの読取りによってフラッシュ・ミスが発生し、そのフラッシュが完全にリウォームされていない場合、ストレージ・サーバーはパートナー・ストレージ・サーバーのフラッシュからデータをフェッチしようとします。フラッシュが再ウォームされると、リモート読取りは不要になります。リモート・ストレージ・サーバー上のフラッシュからのデータの読取りおよび転送は、ローカル・ディスクからの読取りよりもはるかに高速で、ストレージ・サーバーのダウンタイムの前後に一貫して高いパフォーマンスを実現します。
より高速なSQLのためのクリティカルな大規模書込みの優先順位付け
スマート・フラッシュ・キャッシュは、分析、AIおよびミッション・クリティカルなワークロードに対して高いパフォーマンスを実現する上で重要な役割を果たします。Exadata System Software 25.2では、Exadataは、ASMの再同期およびリバランス操作に関連するI/Oなどのタイプの大規模な書込みI/O(Large Writes I/O)よりも、TEMP I/Oおよびフラッシュバック・ログ書込みの優先順位を上げることを自動的に決定します。これにより、アクティブなデータベース問合せには常に、フラッシュ・キャッシュ・リソースに対する最優先度のアクセス権が付与されます。その他の大規模な書込み(Large Writes)は、使用可能なフラッシュ容量がある場合にのみキャッシュされます。
Exascaleにおけるイノベーション
Exadata Exascaleは、クラウド向けの世界で唯一のインテリジェント・データ・アーキテクチャです。Exascaleは、Exadataの長所とクラウドの長所を組み合わせた革新的な飛躍です。この次世代のハイパーエラスティックなマルチテナント・ソフトウェア・アーキテクチャは、AI、分析、ミッションクリティカル、JSON、およびOracle Databaseの混合ワークロードを処理するように設計されています。
Exascaleは、ストレージ管理をコンピュートから分離および簡素化することで、Exadataプラットフォームでコンピュート・リソースとストレージ・リソースを管理する方法を再考し、データベース・スナップショットへの再考されたスペース効率の高いアプローチ、任意の読取り/書込みデータベースまたはプラガブル・データベースからのシン・クローン、Exascaleボリューム、仮想マシンおよびACFSなどのファイルシステムのRDMA対応ストレージなどの革新的な新機能への道を切り開いています。Exascaleは、組織がExadataに期待する業界をリードするデータベースのパフォーマンス、可用性およびセキュリティ標準を保証します。
Exadata System Software 25.2では、Exascaleがさらに最適化され、データの耐久性の向上、インテリジェントなストレージ・プールの空き領域管理の提供、仮想マシンのボリューム管理とスナップショットの簡素化が実現されています。
耐久性を向上させるデルタ追跡による独自の再構築
Exascaleは、常にデータを保護します。デフォルトでは、Exascaleはすべてのファイル・エクステントを3回ミラーリングし、各コピーを異なるディスクおよび異なるストレージ・サーバーに配置します。この高冗長性構成は、ディスクがオフラインになった場合でもデータを保護します。ディスクがオフラインになった場合、Exascaleデルタ・トラッキング機能によって、このようなオフライン・ディスクの変更が別のディスクに自動的に書き込まれ、常に3つのコピーが保持されます。ディスクがオンライン状態に戻ると、デルタがデータの再同期に迅速に適用されます。
重要なことは、デルタ・トラッキングによって、変更された個々のデータベース・ブロックのみが書き込まれることです。つまり、デルタ追跡時に使用されるストレージは、通常、非常に低くなります。ディスクが再同期される場合、エクステント内の変更されたブロックのみを更新する必要があり、8MBのエクステント全体を更新する必要はありません。
ディスクに障害が発生すると、Exascaleは2つのアクションを同時に実行して、高可用性とデータ耐久性を確保します。
- 新しい書込みは、残りのオンライン・ディスクのデルタとして追跡されます。
- システムはすぐに使用可能な他のディスク上のデータ冗長性の再構築を開始します。
障害が発生したディスクがオンラインに戻されると、Exascaleはデルタを自動的に適用して冗長性を迅速にリストアします。Exascaleは、ディスクに障害が発生したとき、またはディスクがオフラインになったときに、これら2つのアクションを実行するため、複数のディスクに障害が発生した場合でも、障害が発生したディスクをオンラインにすることで、すべてのデータをリストアできます。この革新的なアプローチにより、たとえばファームウェアの問題が原因で複数のディスクに障害が発生した場合でも、データの耐久性が向上します。最後に障害が発生したディスクを復活させてデータをリカバリするかわりに、障害が発生したディスクのいずれかが復活した場合、データベース・ブロックをデルタ・トラッキング・データからリカバリできます。
インテリジェントなExascaleストレージ・プールの空き領域管理
Exascaleストレージ・プールには、ディスクに障害が発生した場合に冗長性を正常に再構築するための十分な空き領域が必要です。Exadata System Software 25.2以降では、使用可能な空き領域がしきい値を下回ると、Exascaleによって次のようなアラートが発行されます。
Storage pool '
' has
of free space, but
is required to rebuild redundancy if a disk fails.
これにより、管理者は、古いファイルの削除や領域を解放して再構築を続行できるようにするなどの適切なアクションを実行できます。
また、空き領域が少ないときにディスクに障害が発生した場合、通常は不要なファイルを削除して、十分な領域が解放されるまで、Exascaleはリバランス・アクションを一時停止します。十分な空き領域が使用可能になると、リバランス・プロセスが自動的に再開されます。
Exascale仮想マシン管理
Exascaleは、データベース仮想マシン(VM)イメージの共有ストレージ・サーバーでのRDMA対応ボリュームの使用という強力な新機能をExadataに追加します。ローカル・ストレージから共有ExascaleにVMイメージを移動することで、VMイメージに使用できる領域が大幅に増え、Exadata X10Mおよび新しいデータベース・サーバー上のKVMホスト当たり最大50個のVMを統合し、VMイメージ内に追加または大規模なLinuxファイルシステムを作成できます。
仮想マシンのExascale Volume の集合体となる Exascale Volume Group
Exascale Volume はExascaleファイルであり、RDMAに最適化されたExascale Direct Volume (EDV)プロトコルを介して、VMおよびデータベース・サーバーにブロック・デバイスとしてアタッチできます。
お客様は、VMにアタッチされたExascaleボリュームをExascale Volume Groupにグループ化して、対象のVMでの管理操作を簡素化できるようになりました。
Exascale Volume Group を作成するには、escli mkvolumegroupコマンドを実行します。
@> mkvolumegroup VolGroup Created volume group with id volgrp0001_7797373fc4da4fefaa75c663bee932d7
次に、Exascale Volume Group に Exascale Volume を追加します。
@> chvolumegroup volgrp0001_7797373fc4da4fefaa75c663bee932d7 --attributes volumes=+vol0108_3435ec82b67347479ac65108745bcdaf @> chvolumegroup volgrp0001_7797373fc4da4fefaa75c663bee932d7 --attributes volumes=+vol0109_919f59aa8b1546959afea6c5f8f264e2 @> chvolumegroup volgrp0001_7797373fc4da4fefaa75c663bee932d7 --attributes volumes=+vol0110_a5f6bd18fa674d2c814626f9d575adcd
関連するExascale Volume 全体での一意のポイントインタイム一貫性スナップショット
Exascale Volume Groupを作成する機能により、Exascale Volume Group内のすべてのExascale Volumeのポイントインタイムで一貫性のあるスナップショットを作成できます。これらのスナップショットを使用すると、互いに一貫性のないExascale Volumeごとのスナップショットではなく、すべてのExascale Volumeのバックアップまたはシン・クローンを簡単に作成できます。
Exascale Volume Group スナップショットを作成するには、前の例に示すように、3つのボリュームをVolGroupに追加しました。Exascale Volume Grgoup にExascale Volumeが追加された状況は escli lsvolume コマンドで確認出来ます。
@> lsvolume --filter volumeGroup=volgrp0001_7797373fc4da4fefaa75c663bee932d7 --attributes id,name,vault id name vault vol0108_3435ec82b67347479ac65108745bcdaf vol108 @vm08acfs vol0109_919f59aa8b1546959afea6c5f8f264e2 vol109 @vm08acfs vol0110_a5f6bd18fa674d2c814626f9d575adcd vol110 @vm08acfs
これで、escli mkvolumegroupsnapshotコマンドを使用して、3つのボリュームすべての一貫したスナップショットを同時に取得できるようになりました。
@> mkvolumegroupsnapshot volgrp0001_7797373fc4da4fefaa75c663bee932d7 Created volume group snapshot with id 1:7797373fc4da4fefaa75c663bee932d7_20250627T144849
上記のExascale Volume Group・スナップショットでフィルタしてボリューム・スナップショットを escli lsvolumesnapshotコマンドでリストすると、3つのボリュームすべてにスナップショットがあることが示されます。
@> lsvolumesnapshot --filter volumeGroupSnapshot="1:7797373fc4da4fefaa75c663bee932d7_20250627T144849" id name vol0108_3435ec82b67347479ac65108745bcdaf OS vol0109_919f59aa8b1546959afea6c5f8f264e2 DB_HOME vol0110_a5f6bd18fa674d2c814626f9d575adcd GI_HOME
XSHコマンドでのJSON出力
Exascaleシェル(XSH)は、データベース・仮想マシンからExascaleストレージと対話するための便利なユーティリティです。ファイルのプロパティと属性を表示および変更し、ls、dd、mv、touchなどのコマンドを使用してExascaleに格納されたファイルを作成および操作する簡単なインタフェースを提供します。
共通自動化ユーティリティとのより適切な統合を可能にするために、XSHは–jsonスイッチを追加することでJSON形式で出力を生成できるようになりました。たとえば、xsh ls –detail –jsonコマンドは、JSONでxsh lsコマンドの詳細な出力を提供します。
# xsh ls --detail --json @exadpmvault/…/CDB1/…/DATAFILE/SYSTEM.OMF.60749038
{ "Result" :
{ "Output" : [
{
"name" : "@exadpmvault/…/CDB1/…/DATAFILE/SYSTEM.OMF.60749038",
"usedBy" : "82b1ca80638e4f86bf2e4b3eabc7b6e7:cdb1",
"blockSize" : 8192,
"fileType" : "DATAFILE",
"redundancy" : "high",
"contentType" : "DATA",
"media" : "HC"
}
],
"ErrorCode" : 0,
"errorMsg" : ""
}, …
}
セキュリティ、管理性、可観測性に優れたインフラストラクチャ
SELinuxのデフォルト有効化
今日の急速に進化する脅威環境において、データ・セキュリティは依然として最優先事項です。Security-Enhanced Linux (SELinux)はLinuxセキュリティ・モジュールで、システムが危険にさらされた場合の不正なアクションや破損のリスクを最小限に抑えるために必須アクセス制御を適用します。
Exadata System Software 25.2では、新しいExadataデプロイメントに対してSELinuxがデフォルトで有効になりました。事前構築済みのOracle DatabaseおよびExadata固有のSELinuxポリシーにより、作成、トレーニング、再構成に時間がかかる必要がなくなります。これにより、お客様はポリシーをゼロから構築する負担なく、セキュリティ体制を迅速に強化できます。
デフォルトでは、SELinuxはpemissive モードで動作し、ワークロードを中断することなく、セキュリティ・ポリシーによってブロックされるアクションを記録します。これにより、潜在的なセキュリティの問題を把握しながら、業務の継続性を確保できます。お客様は、サード・パーティまたは環境固有のソフトウェアのカスタム・ポリシーを作成することで、セキュリティをさらに調整できます。モニタリング・ポリシー違反は、標準のSELinuxツールを使用して達成されるため、既存のセキュリティ監視および管理ツールおよびアプリケーションと簡単に統合できます。
最適化されたLinuxでセキュリティを強化
Exadataは、最適化されたOracle Linuxオペレーティング・システムを使用し、Oracle Databaseに必要なパッケージのみを使用します。Exadata System Software 25.2では、Oracleはパッケージの依存関係をさらに簡素化することで、悪意のあるソフトウェアや悪質なアクターの潜在的な攻撃対象領域を最小限に抑え続けています。同時に、Oracleは追加パッケージのリポジトリを提供し続け、特定の要件またはサードパーティの依存関係に必要なパッケージをインストールできます。
Elastic OEDAにより、導入の柔軟性が向上
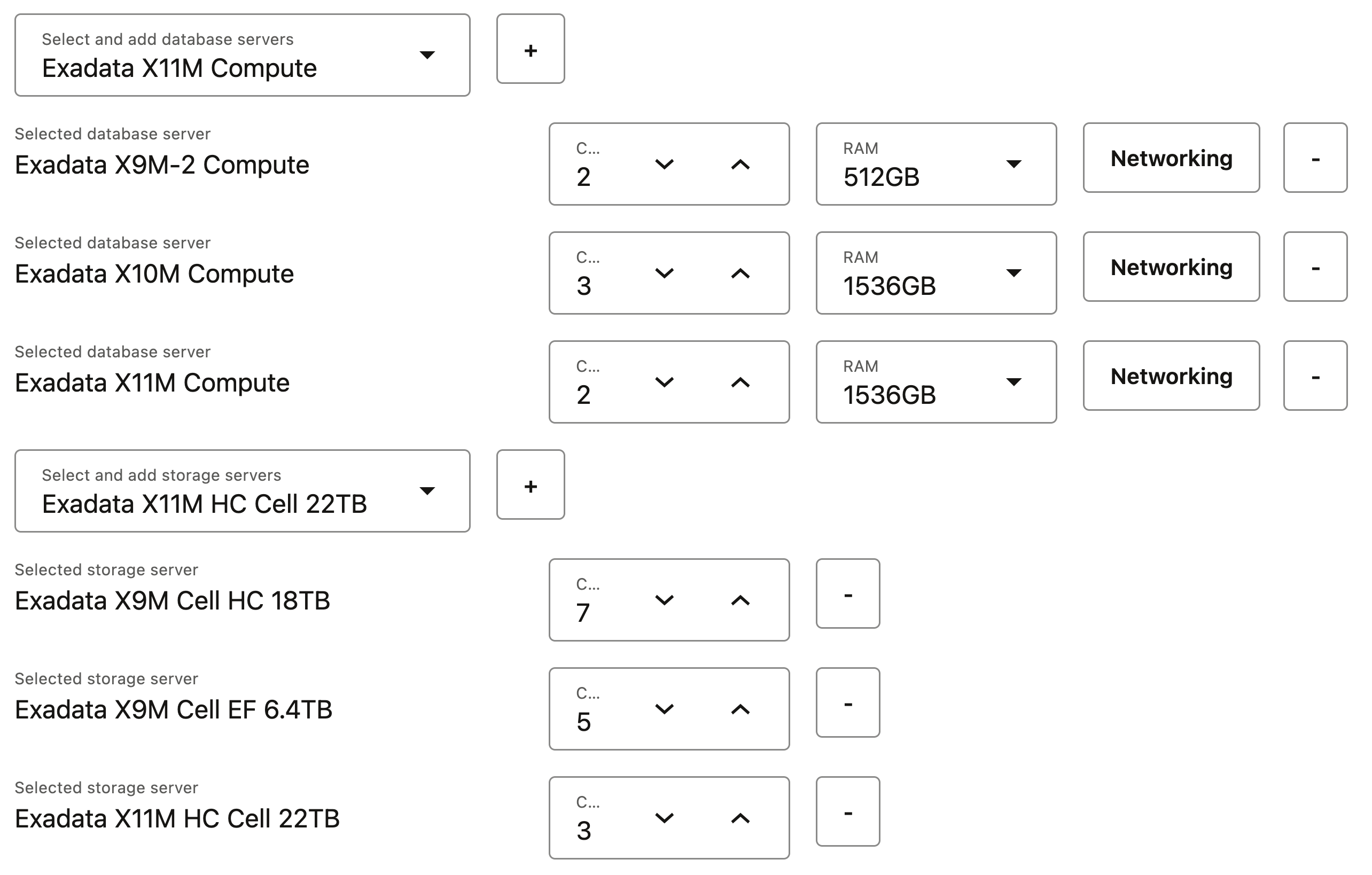
このリリースでは、Oracle Exadata Deployment Assistant (OEDA)が大幅に改善されました。2025年3月のOEDAリリース以降、Exadataデプロイメントに一致するインフラストラクチャをより簡単にモデル化およびデプロイできます。たとえば、上記のイメージは、X9M、X10MおよびX11Mデータベース・サーバー、およびX9M Extreme Flash、X9M High CapacityおよびX11M High Capacityストレージ・サーバーが混在する単一ラック構成を示しています。
最新のOEDAでは、このより柔軟で柔軟なアプローチにより、特に多くのお客様がExascaleを使用してストレージ・プーリング、ボリューム、データベース・スナップショットおよびクローン機能などの高度な機能のメリットを享受しているため、制御とデプロイメントの敏捷性が向上します。
上位のスマート・スキャンSQL文の独自のハイライトにより、可観測性を向上
Exadataのコア機能であるスマート・スキャンは、超高速フラッシュおよびRDMA対応メモリー(XRMEM)にキャッシュされたデータを読み取り、分析およびAIクエリを加速します。この多層キャッシュ戦略は、Exadataのメインステイであり、X11Mで達成されるように、最大100 GB/秒のフラッシュSQLスキャン・スループットを実現しています。
CellSQLStatは、任意のストレージ・サーバーで実行できる新しいユーティリティで、そのストレージ・サーバーでスマート・スキャン問合せがフラッシュ、XRMEMおよびその他のリソースをリアルタイムに使用する方法についてのインサイトを提供します。このユーティリティは、CPUおよびメモリーの消費、ストレージ索引および列キャッシュの節約、フラッシュ・キャッシュおよびXRMEMヒット、および即時スキャン率を示します。CellSQLStatは、ExaWatcherに自動的に含まれます。これにより、履歴分析のためにOSやその他のデータとともに有用なSQLレベルの統計を使用できるようになり、Oracleサポートのデータ収集が簡素化されます。
最終的な思考
Exadata System Software 25ai (リリース25.2)は、次のような重要なイノベーションを提供します。
- Accelerated AI Vector Search: ネイバー・パーティション・ベクトル索引に非ベクトル列を含め、SPARSEベクトルをサポートすることで、より高速なAIスマート・スキャンを提供
- 卓越したパフォーマンス: フラッシュ・キャッシュの最適化、I/Oの優先順位付け、ストレージ・メンテナンス後のシームレスな高可用性を提供
- Exascaleのイノベーション: デルタ・トラッキングとよりスマートな空き領域管理により、データの耐久性を向上させ、ポイントインタイムのボリューム・グループ・スナップショットを可能にし、VMボリューム管理を合理化
- 優れたセキュリティ、管理性および可観測性: デフォルトでSELinuxを有効にすることでセキュリティを強化し、最適化されたOracle Linuxオペレーティング・システムで攻撃対象領域を削減し、Exascale Shell (XSH)でJSON出力サポートを提供し、柔軟なOracle Exadata Deployment Assistant (OEDA)でデプロイメント・オプションを拡張
これらの機能を組み合わせることで、ExadataはOracle Databaseワークロードに最適なプラットフォームであり、ミッションクリティカルな環境のパフォーマンス、スケーラビリティ、可用性、俊敏性、および保護を実現できます。
詳細は、Exadataのドキュメントを参照し、My Oracle SupportからExadata System Software 25aiをダウンロードしてください。
