Limites, desafios e caminhos para evolução

Parte 1 – Recuperação da Informação
O principal valor da busca semântica está na sua capacidade de extrair valor de acervos documentais privados, especialmente em ambientes onde a informação é abundante e pouco estruturada.
Mais do que responder perguntas, a proposta é permitir que o servidor público acesse, de forma simples mas com segurança e auditoria, e usando linguagem natural, o conhecimento que já existe dentro da organização, mas que muitas vezes está disperso em documentos, processos e registros históricos.
Em vários cenários, a busca semântica funciona muito bem, especialmente quando lidamos com bases documentais simples, onde o conteúdo está concentrado e as relações entre os documentos não são relevantes.
Mas essa não é a realidade do SEI.
É a partir desse ponto que os primeiros limites da busca semântica começam a aparecer. Para entender esses limites com mais clareza, é importante observar como ela funciona na prática.
Como a busca semântica funciona
Na maioria das implementações, a busca semântica utiliza uma técnica chamada RAG (Retrieval Augmented Generation), que segue um fluxo de ingestão e pesquisa de documentos relativamente simples.
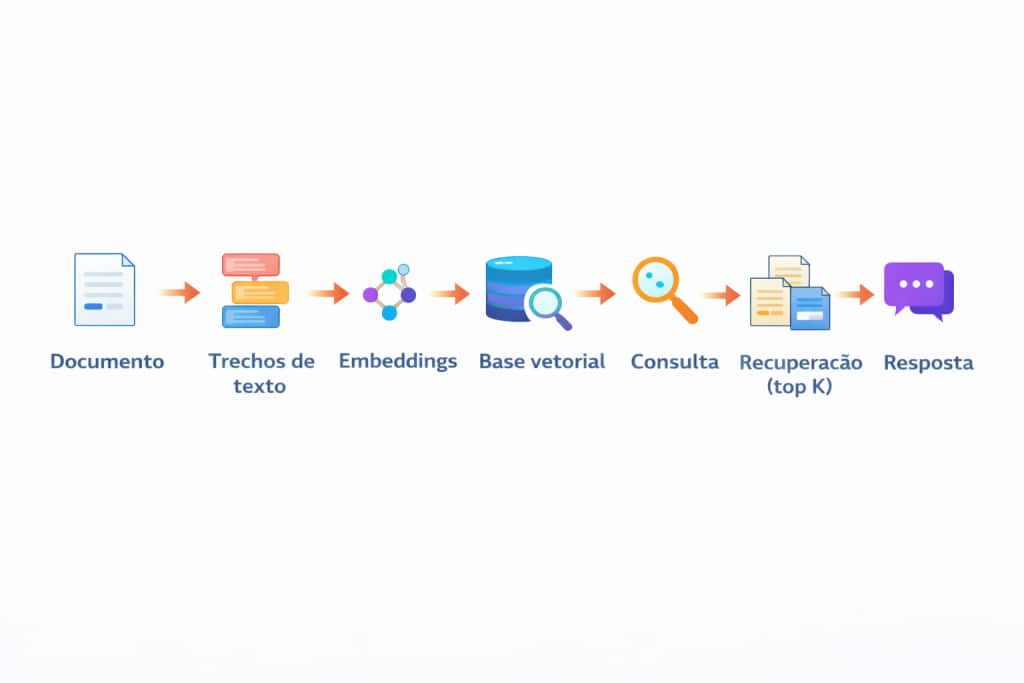
O conteúdo dos documentos é convertido para texto planoou para um formato mais palatável como o Markdown e, em seguida, dividido em pequenos fragmentos por meio de um processo de segmentação (chunking), normalmente com algum nível de sobreposição entre os fragmentos para preservar o contexto local. Cada fragmento é transformado em um vetor (embedding), que representa semanticamente aquele trecho. Esses vetores são armazenados em uma base vetorial (vector store), juntamente com estruturas otimizadas para busca, conhecidas como índices vetoriais. Esses índices permitem acelerar significativamente a recuperação por similaridade, evitando a comparação exaustiva com todos os vetores armazenados e viabilizando consultas eficientes mesmo em bases com grande volume de dados.
Quando o usuário faz uma pergunta, ela também é convertida em vetor e comparada com os vetores armazenados na base, usando os índices previamente criados. O sistema calcula a similaridade (ou distância) entre os vetores e utiliza essa medida como critério de ranking para recuperar os fragmentos mais relevantes (Top K). Por fim, esses fragmentos e seus respectivos metadados são enviados como contexto para o modelo de linguagem gerar a resposta.
Essa abordagem funciona bem quando a pergunta do usuário pode ser atendida com base em similaridade semântica entre a pergunta do usuário e os fragmentos. No entanto, essa premissa nem sempre se sustenta em cenários reais.
Em muitos casos, especialmente em sistemas como o SEI, a recuperação da informação não depende apenas de significado, muitas vezes é necessário pesquisar por termos exatos (full-text search), algo que a similaridade vetorial não garante por si só.
É a partir dessa limitação que surge a necessidade de evoluir a estratégia de recuperação.
Busca híbrida: combinando semântica e textual
Em sistemas como o SEI é comum pesquisar por números de processo, identificadores de documentos e termos exatos específicos de cada unidade organizacional, como siglas e acrônimos. A busca puramente semântica, baseada em vetores, oferece boa generalização, mas pode falhar nesses casos, especialmente diante de pequenas variações na representação do conteúdo.
Por outro lado, a busca textual tradicional garante excelente precisão quando é necessário pesquisar termos exatos, mas perde qualidade quando o usuário não conhece a forma exata da informação ou quando ela é descrita de maneira indireta.
A solução natural é a busca híbrida, que combina mecanismos semânticos e textuais. Uma mesma consulta é processada por diferentes estratégias de recuperação, e os resultados são combinados e reordenados. Isso permite equilibrar significado e precisão, tornando a recuperação mais eficaz em ambientes complexos como o SEI.
Essa evolução resolve parte do problema — mas não todos, como veremos a seguir.
Antes de prosseguirmos, vale lembrar que o SEI já oferece um mecanismo de consulta textual robusto baseado no Apache SOLR que pode ser usado em conjunto com a busca semântica.
Onde a Busca Híbrida se perde
À medida que a complexidade do acervo cresce, o desafio deixa de ser apenas recuperar termos exatos ou trechos semanticamente semelhantes.
Passa a ser necessário compreender como a informação está distribuída entre documentos, processos e suas relações.
Com o aumento dessa complexidade, a organização da informação deixa de seguir um padrão simples e começa a evoluir para ramificações mais complexas.
Podemos entender essa evolução em três níveis de complexidade.
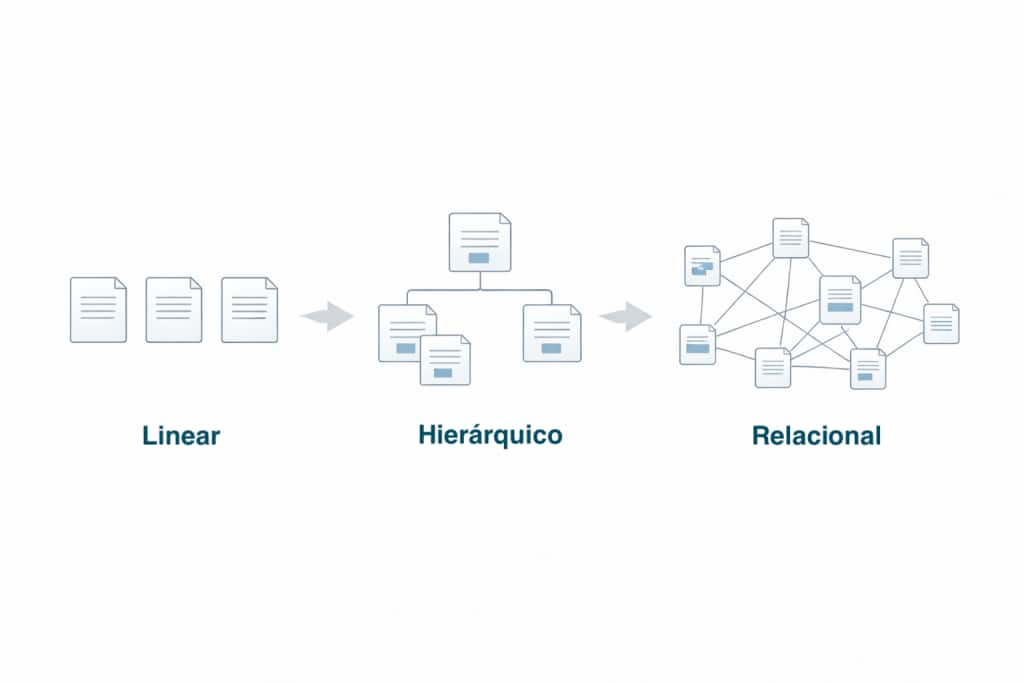
Linear
No nível mais simples, os documentos são essencialmente independentes. Cada texto pode ser lido de forma isolada, e o seu significado está contido nele mesmo.
Nesse cenário, a abordagem baseada em busca híbrida funciona de forma bastante eficiente.
Exemplo
Qual é o objeto da contratação?
Considere um processo administrativo em fase inicial de instrução, no qual o Termo de Referência foi elaborado de forma estruturada, seguindo o padrão adotado pelo órgão. O documento está completo, com seções bem definidas e sem dependência de outros documentos para compreensão do seu conteúdo.
Nesse caso, a resposta está explicitamente descrita em uma seção específica do próprio documento, geralmente intitulada “Objeto”.
Basta recuperar o trecho correto para que o modelo de linguagem consiga responder com precisão, pois toda a informação necessária está contida naquele único fragmento.
Hierárquico
À medida que a estrutura dos documentos se torna mais rica, a independência dos fragmentos começa a diminuir.
Um mesmo documento passa a conter diferentes níveis de informação, como anexos, referências internas e seções com funções distintas.
Ainda assim, com uma estratégia cuidadosa de segmentação, é possível preservar boa parte da coerência necessária. Isso envolve técnicas como o chunking semântico, que divide o texto com base no sentido, e o chunking híbrido, que combina limites semânticos com características estruturais dos próprios documentos. Dessa forma, cada fragmento preserva o significado dentro da estrutura do documento.
Nesse nível, a qualidade do prompt submetido ao modelo de linguagem passa a ter um papel mais relevante.
Aqui vale destacar iniciativas recentes do governo federal que vêm orientando o uso de IA generativa no setor público, incluindo boas práticas para construção de prompts mais claros, objetivos e alinhados ao contexto administrativo. Essas diretrizes reforçam a importância de explicitar intenção, contexto e formato esperado da resposta, fatores que impactam diretamente a qualidade dos resultados em cenários baseados em RAG.
Além disso, a aplicação de técnicas como reescrita de consultas (query rewrite), uso de múltiplas consultas (multi-query) e reordenamento de resultados (reranking) contribuem para melhorar a qualidade da recuperação.
A reescrita de consultas, em particular, passa a desempenhar um papel estratégico ao permitir que uma mesma pergunta seja transformada em diferentes variações, explorando tanto a dimensão semântica quanto a dimensão lexical da busca. Na prática, isso viabiliza a combinação entre busca semântica e correspondência exata, alinhando-se a uma abordagem híbrida de recuperação.
Exemplo
Qual é a justificativa da contratação?
Considere um processo de contratação já mais avançado, contendo Documento de Oficialização de Demanda (DOD), Estudo Técnico Preliminar (ETP), Termo de Referência (TR) e outros documentos complementares. A justificativa da contratação não está concentrada em um único documento, mas distribuída entre diferentes peças que compõem a instrução processual.
Parte da justificativa pode estar descrita no DOD, enquanto aspectos técnicos aparecem no ETP e detalhes adicionais são incorporados ao TR ou a documentos anexos.
Nesse cenário, a busca híbrida continua sendo aplicável, mas exige maior sofisticação na recuperação e na construção do contexto, pois a resposta depende da combinação de múltiplos fragmentos relacionados dentro de uma mesma estrutura processual.
Uma evolução relevante nesse nível é o uso de técnicas como o RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval), que organiza o conteúdo em uma estrutura hierárquica baseada em resumos. Os documentos são progressivamente sintetizados em diferentes níveis de abstração, formando uma árvore de conhecimento.
Esse modelo permite combinar duas perspectivas complementares. Uma visão mais ampla, baseada em resumos de alto nível, ajuda a compreender o contexto geral. Ao mesmo tempo, uma visão detalhada, no nível dos fragmentos originais, garante precisão e rastreabilidade.
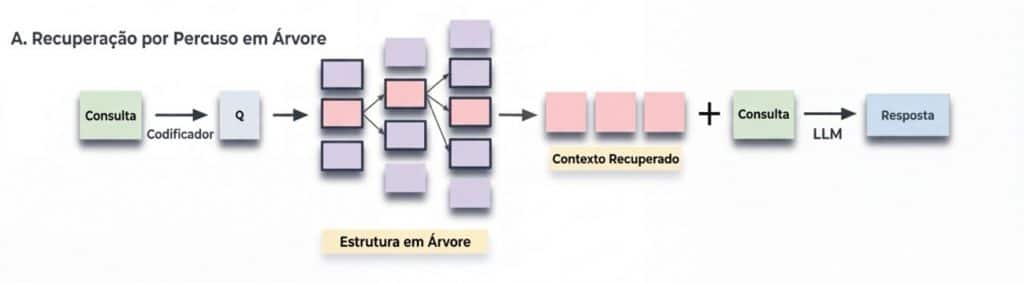
Fonte: https://arxiv.org/html/2401.18059v1
Essa abordagem melhora significativamente a recuperação em cenários hierárquicos. Ainda assim, não resolve o problema quando as dependências deixam de ser estruturais e passam a ser essencialmente relacionais.
Relacional (bem-vindo ao mundo real do SEI)
No SEI, a estrutura da informação evolui para um nível essencialmente relacional.
Documentos fazem referência a outros documentos, que pertencem a processos distintos. Esses processos, por sua vez, se conectam a novos conjuntos de informação.
O significado passa a emergir dessas conexões.
Exemplo
Qual é o motivo principal do cancelamento do edital?
Considere um processo administrativo que foi cancelado após análise jurídica e revisão de sua viabilidade. Ao examinar o processo principal, é possível encontrar um despacho que formaliza o cancelamento. No entanto, esse despacho não apresenta todos os fundamentos da decisão.
Para compreender o motivo do cancelamento, é necessário acessar um parecer jurídico anexado ao processo ou até mesmo consultar outro processo relacionado, no qual estão registradas discussões anteriores, restrições orçamentárias ou impedimentos legais que motivaram a decisão.
Nesse tipo de cenário, a resposta não está contida em um único documento, nem em uma única estrutura hierárquica. Ela depende da navegação entre múltiplos processos e documentos interconectados.
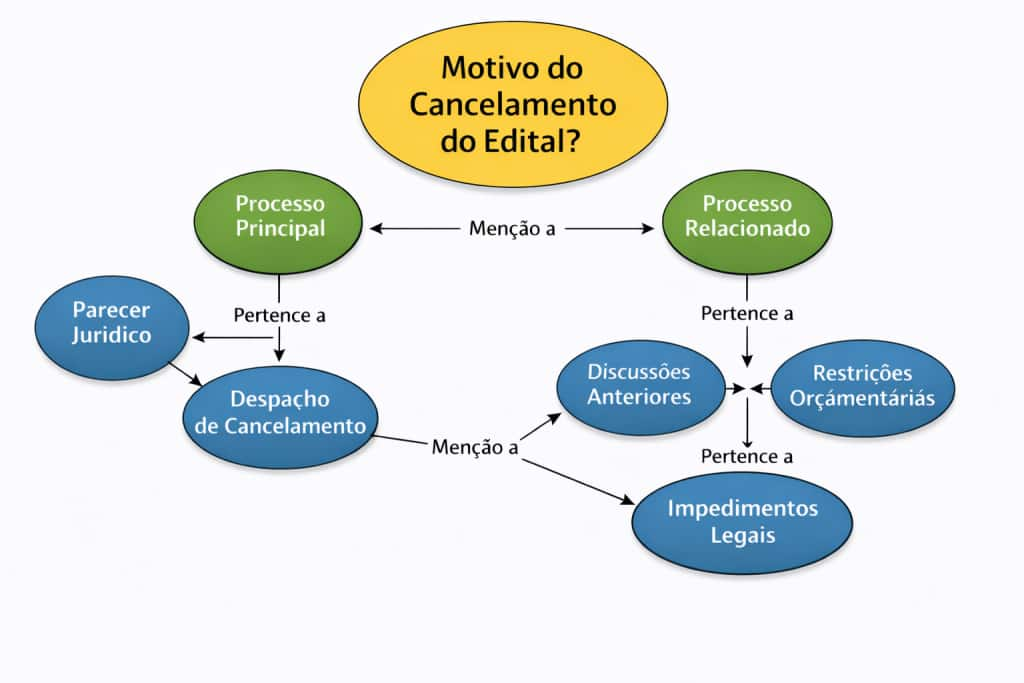
O que importa, nesse contexto, não são apenas os documentos em si, mas a forma como eles se relacionam. Sem navegar por essas relações, a resposta tende a ser incompleta ou enganosamente correta.
É nesse ponto que ocorre a mudança fundamental. O problema deixa de ser apenas de recuperação de informação semântica ou textual e passa a ser navegar pelas conexões.
No contexto do SEI, só encontrar a informação já não é suficiente. É necessário conectar, expandir e reconstruir o contexto a partir de múltiplas fontes interdependentes.
Nesse cenário, a própria estratégia de recuperação precisa evoluir. Diferentes tipos de consulta passam a exigir caminhos distintos de execução, considerando não apenas o conteúdo dos documentos, mas também suas relações e o contexto em que estão inseridos.
É nesse ponto que surge a necessidade de roteamento de consultas (query routing). A partir da interpretação da pergunta do usuário, o sistema pode direcionar a busca para diferentes estratégias, como recuperação semântica, busca textual, navegação entre os relacionamentos ou combinações entre elas.
Esse tipo de abordagem permite tratar de forma mais adequada consultas que envolvem múltiplos processos, dependências indiretas e relações implícitas, ampliando significativamente a capacidade de reconstrução de contexto em cenários complexos como o SEI.
Tornando as conexões explícitas
Resolver esse problema exige tornar explícitas relações que, até então, estavam implícitas nos documentos.
Uma abordagem natural é a construção de um grafo de conhecimento.
Esse grafo pode ser construído durante o processo de ingestão e segmentação, utilizando uma estratégia progressiva.
Por exemplo, o número do processo, identificadores de documentos e links podem ser extraídos com regras determinísticas, como expressões regulares. Esses padrões costumam seguir formatos bem definidos dentro do SEI, o que permite sua identificação de forma confiável.
Além desses padrões, há também informações que podem ser identificadas de forma estruturada no próprio texto. Técnicas de reconhecimento de entidades nomeadas (Named Entity Recognition — NER) permitem extrair entidades como datas, pessoas, unidades administrativas, órgãos e tipos de documento, enriquecendo a compreensão do conteúdo.
A partir desse ponto, é possível avançar para um nível mais complexo de análise. Modelos de linguagem passam a identificar relações que não estão diretamente estruturadas no texto. Por exemplo, quando um fragmento menciona outro processo sem citar explicitamente seu identificador, o modelo pode inferir essa conexão com base no contexto.
Ao combinar busca híbrida com o grafo, cada fragmento recuperado passa a ser um ponto de entrada. O sistema passa a permitir a expansão de contexto por meio da navegação nas conexões do grafo.
O contexto deixa de ser apenas recuperado. Ele passa a ser reconstruído.
Manutenção do grafo: atualização contínua orientada a eventos
O grafo precisa refletir continuamente o estado real do SEI. Caso contrário, há o risco de a busca híbrida operar sobre uma representação defasada da informação, o que pode levar à recuperação de contextos inconsistentes, respostas incorretas ou decisões baseadas em dados já superados.
Para isso, a arquitetura deve adotar um modelo orientado a eventos.
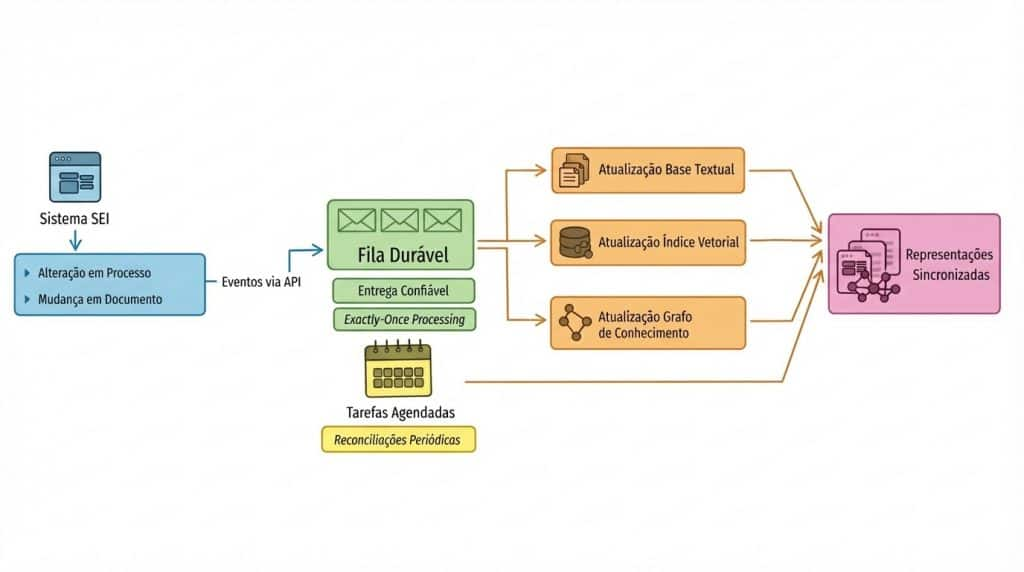
Mudanças no sistema passam a gerar eventos que alimentam um fluxo de processamento responsável por atualizar tanto a base textual e vetorial quanto o grafo. A boa notícia é que o próprio SEI já disponibiliza uma API capaz de gerar eventos a partir de alterações em processos e documentos, o que facilita a implementação desse modelo.
Para garantir consistência em escala, é necessário incorporar um mecanismo robusto de mensageria. Esse mecanismo deve assegurar entrega confiável e processamento com semântica exactly-once. Isso evita inconsistências entre o estado do SEI e suas representações derivadas.
Além disso, o SEI oferece suporte a tarefas agendadas, que podem ser utilizadas para reconciliações após alterações em grande escala. Exemplos incluem mudanças na estrutura organizacional, fusão de unidades, reclassificação de processos ou migrações de dados.
Esse conjunto de estratégias garante que a representação textual, semântica e relacional (grafo) evolua de forma sincronizada com o SEI.
Conclusão
A estratégia de busca híbrida continua sendo poderosa, desde que aplicada no contexto adequado.
Em cenários onde a informação é mais linear ou hierárquica, ela é suficiente para recuperar e organizar o conhecimento de forma eficiente.
No SEI, o desafio é diferente.
A informação não está apenas distribuída em documentos. Ela está distribuída em relações.
Nesse ponto, o problema deixa de ser apenas recuperar termos exatos ou semelhantes semanticamente. Agora, a estrutura do acervo do documental passa a exigir a capacidade de navegar, conectar e reconstruir o contexto a partir de múltiplas fontes interdependentes.
É nesse ponto que a busca híbrida tradicional atinge seus limites.
Para atender às necessidades de pesquisa dos servidores públicos, torna-se necessário complementá-la com uma representação explícita dessas relações.
O uso de grafos de conhecimento deixa de ser um requinte arquitetural e passa a ser um elemento fundamental da solução.
Ao mesmo tempo, essa evolução traz um desafio adicional que não pode ser tratado de forma isolada: segurança e controle de acesso.
Em um ambiente como o SEI, onde documentos possuem diferentes níveis de restrição e visibilidade, não basta apenas recuperar e conectar informações. É essencial garantir que cada usuário tenha acesso apenas ao que está autorizado a visualizar.
Isso implica que o modelo de recuperação, o grafo de conhecimento e o fluxo de geração de respostas precisam estar integrados aos mecanismos de controle de acesso do SEI.
Esse tema, por sua complexidade e impacto arquitetural, será aprofundado na segunda parte desse artigo.
Referências
Guia Prático de Prompt
Comparative Evaluation of Advanced Chunking for Retrieval-Augmented Generation in Large Language Models for Clinical Decision Support
https://pmc.ncbi.nlm.nih.gov/articles/PMC12649634
HybridRAG: Integrating Knowledge Graphs and Vector Retrieval
Augmented Generation for Efficient Information Extraction
https://arxiv.org/pdf/2408.04948
RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING
FOR TREE-ORGANIZED RETRIEVAL
