This post is the second in a series about Routing Guidelines, a new feature available in both MySQL Community and Enterprise Editions that brings smarter and more flexible query routing to MySQL Architectures, including InnoDB Cluster, ClusterSet, and ReplicaSet.
Whether you’re already using MySQL Router or evaluating ways to enhance and simplify application failover and scale workloads more efficiently, Routing Guidelines introduce a new level of control and flexibility. They enable declarative, fine-grained control over routing behavior that adapts in real time – without requiring application changes.
In the first post, we introduced the concept of Routing Guidelines and how they provide a declarative approach to query routing based on:
- Server properties (e.g., replica vs. primary)
- Client session attributes (e.g., database schema, user name, or client attributes)
- MySQL Router specifics (e.g., RW port, hostname).
By storing Routing Guidelines centrally in the topology’s metadata schema, MySQL Router can automatically detect and apply routing changes in real time, eliminating the need for manual configuration updates and minimizing service disruption.
With MySQL Shell’s AdminAPI, Routing Guidelines can be easily and dynamically managed, enabling administrators to create, modify, and remove them as workloads shift, applications demands change, and topologies evolve.
In this post, we’ll explore how to define Routing Guidelines, apply them to real-world query routing scenarios, and manage them efficiently using the AdminAPI.
Let’s dive in and see Routing Guidelines in action – step by step!
Getting Started With Routing Guidelines
Before diving into configuration, it’s essential to understand how Routing Guidelines are managed within MySQL Shell.
MySQL Router operates as a stateless connector, meaning it does not persist rules locally.
Instead, it retrieves them from the metadata schema, ensuring a centralized and consistent query routing configuration across all Routers. This allows Routing Guidelines to be updated dynamically without requiring changes to individual Router instances.
Prerequisites
A few requirements must be in place to ensure that both MySQL Shell and MySQL Router can properly support and apply these rules.
- MySQL Shell 9.2.0 or later.
- MySQL Router 9.2.0 or later.
- An active MySQL InnoDB Cluster, ClusterSet, or ReplicaSet.
- MySQL Router must be bootstrapped against the topology to ensure it can retrieve and apply Routing Guidelines automatically.
- Administrative access to MySQL Shell: typically, this corresponds to a ClusterAdmin account or equivalent, with the ability to execute AdminAPI commands.
With these prerequisites in place, let’s quickly recap how Routing Guidelines are structured before we start managing them in MySQL Shell.
Defining Routing Guidelines – A Quick Recap
Routing Guidelines allow administrators to define how queries should be routed based on various conditions evaluated at connection time.
These guidelines are structured as lists of rules, where each rule specifies a matching condition and a corresponding routing strategy and destinations.
Structure of a Routing Guideline
A Routing Guideline consists of four key fields:
| Field | Description |
|---|---|
| name | A unique name for the Routing Guideline. |
| version | Indicates the JSON syntax version used by the Routing Guideline. This is set automatically by MySQL Shell and Router and is not user-editable. |
| destinations | A set of named destinations that define which servers can be used. |
| routes | A list of routing rules, each containing a match expression and destinations. |
Example: A Simple Guideline
{
"destinations": [
{
"match": "$.server.memberRole = READ_REPLICA",
"name": "ReadReplica"
}
],
"name": "example",
"routes": [
{
"connectionSharingAllowed": true,
"destinations": [
{
"classes": [
"ReadReplica"
],
"priority": 0,
"strategy": "round-robin"
}
],
"enabled": true,
"match": "$.session.targetPort = $.router.port.ro",
"name": "ro"
}
],
"version": "1.0"
}
How this Routing Guideline works
- Destinations define a class of servers where
memberRole = READ_REPLICA, labeled as"ReadReplica". - A single route applies to sessions connecting through the read-only port (
$.router.port.ro), routing them to ReadReplica servers using round-robin.
For a deeper introduction to Routing Guidelines, see the first post in this series.
Managing Routing Guidelines With MySQL Shell
Routing Guidelines are centrally stored in the metadata schema, allowing all MySQL Routers connected to the topology to automatically retrieve and apply them in real time.
Instead of manually modifying Router configurations and manually editing JSON files, MySQL Shell’s AdminAPI provides a dedicated set of commands to manage Routing Guidelines easily and dynamically.
Using AdminAPI to manage Routing Guidelines provides several advantages:
- Dynamic updates without Router restarts – Changes are detected and applied in real time without downtime.
- Centralized and consistent routing logic – All Routers share a unified set of rules stored in the topology’s metadata.
- Built-in validation – AdminAPI ensures Routing Guidelines are well-formed and consistent before applying them, preventing misconfigurations.
- Fine-grained control – Individual routes and destinations can be added, updated, or removed incrementally as application needs change.
- Safe testing and staged rollouts – Guidelines and individual routes can be enabled or disabled independently, making it easier to test new routing logic before deploying.
With this foundation in place, the next section will walk through the process of creating, modifying, and managing Routing Guidelines using MySQL Shell.
Managing Routing Guidelines Step By Step
Now that we’ve covered the basics, let’s dive into how to manage Routing Guidelines using MySQL Shell’s AdminAPI. This section walks through the entire lifecycle of a Routing Guideline: from creating, modifying, and enabling it to exporting, importing, and removing it when needed.
Note: All examples use the Python version of the API. AdminAPI is available in both Python and JavaScript within MySQL Shell.
Creating a Routing Guideline
To start, we need to create a Routing Guideline. MySQL Shell’s AdminAPI provides the following command:
.create_routing_guideline(name[, json][, options])
This command allows defining a Routing Guideline by specifying:
name– The name of the guideline.json(optional) – A JSON document defining the guideline. If omitted, a default Routing Guideline is created based on the topology.options(optional) – Additional parameters.
Creating a Default Routing Guideline
In an InnoDB ClusterSet with Read-Replicas (the most complex topology supported), we can create a default guideline as follows:
mysqlsh-py> rg = clusterset.create_routing_guideline("my_guideline")
What happens here?
- A default Routing Guideline named
"my_guideline"is created. - It follows MySQL Router’s default behavior for this topology.
- The guideline is stored in the metadata so MySQL Router can retrieve it.
- It is not yet active – activating it requires a separate step.
Now that we have created the Routing Guideline, let’s review its structure to understand how queries will be routed.
Reviewing a Routing Guideline
After creating a Routing Guideline, the next step is to inspect its structure and contents. Since Routing Guidelines are stored as JSON documents, AdminAPI provides several commands to view and analyze them efficiently.
Viewing the Full JSON Structure
The most direct way to inspect a Routing Guideline is by retrieving its JSON representation:
<RoutingGuideline>.as_json()
Example:
mysqlsh-py> rg.as_json()
{
"destinations": [
{
"match": "$.server.memberRole = PRIMARY AND ($.server.clusterRole = PRIMARY OR $.server.clusterRole = UNDEFINED)",
"name": "Primary"
},
{
"match": "$.server.memberRole = SECONDARY AND ($.server.clusterRole = PRIMARY OR $.server.clusterRole = UNDEFINED)",
"name": "PrimaryClusterSecondary"
},
{
"match": "$.server.memberRole = READ_REPLICA AND ($.server.clusterRole = PRIMARY OR $.server.clusterRole = UNDEFINED)",
"name": "PrimaryClusterReadReplica"
}
],
"name": "my_guideline",
"routes": [
{
"connectionSharingAllowed": true,
"destinations": [
{
"classes": [
"Primary"
],
"priority": 0,
"strategy": "round-robin"
}
],
"enabled": true,
"match": "$.session.targetPort = $.router.port.rw",
"name": "rw"
},
{
"connectionSharingAllowed": true,
"destinations": [
{
"classes": [
"PrimaryClusterSecondary"
],
"priority": 0,
"strategy": "round-robin"
},
{
"classes": [
"Primary"
],
"priority": 1,
"strategy": "round-robin"
}
],
"enabled": true,
"match": "$.session.targetPort = $.router.port.ro",
"name": "ro"
}
],
"version": "1.0"
}
This returns the complete JSON document defining the guideline, including its name, version, routes, and destinations.
Note: The version field refers to the internal Routing Guideline JSON format version, managed automatically by MySQL Shell and Router to ensure compatibility across releases.
It is not editable by users and does not represent user-defined revisions. If you want to track changes over time or maintain multiple variants, you can copy and rename guidelines (e.g., "guideline_v1", "guideline_v2") to simulate versioning.
Listing Destinations and Routes
Each Routing Guideline defines destinations (groups of servers) and routes (rules that direct queries). To list them, use:
<RoutingGuideline>.destinations()
<RoutingGuideline>.routes()
Example:
mysqlsh-py> rg.destinations()
+---------------------------+-------------------------------------------------------------------------------------------------------------+
| destination | match |
+---------------------------+-------------------------------------------------------------------------------------------------------------+
| Primary | $.server.memberRole = PRIMARY AND ($.server.clusterRole = PRIMARY OR $.server.clusterRole = UNDEFINED) |
| PrimaryClusterSecondary | $.server.memberRole = SECONDARY AND ($.server.clusterRole = PRIMARY OR $.server.clusterRole = UNDEFINED) |
| PrimaryClusterReadReplica | $.server.memberRole = READ_REPLICA AND ($.server.clusterRole = PRIMARY OR $.server.clusterRole = UNDEFINED) |
+---------------------------+-------------------------------------------------------------------------------------------------------------+
3 rows in set (0.0000 sec)
mysqlsh-py> rg.routes()
+------+---------+-----------+-----------------------------------------+------------------------------------------------------------+-------+
| name | enabled | shareable | match | destinations | order |
+------+---------+-----------+-----------------------------------------+------------------------------------------------------------+-------+
| rw | 1 | 1 | $.session.targetPort = $.router.port.rw | round-robin(Primary) | 0 |
| ro | 1 | 1 | $.session.targetPort = $.router.port.ro | round-robin(PrimaryClusterSecondary), round-robin(Primary) | 1 |
+------+---------+-----------+-----------------------------------------+------------------------------------------------------------+-------+
2 rows in set (0.0000 sec)
What these commands do:
destinations()lists all destination groups and their match expressions.routes()displays each routing rule, its match condition, and associated destinations.
Viewing a Comprehensive Summary
For a dynamically generated overview of the Routing Guideline, use:
<RoutingGuideline>.show([options])
This command evaluates the Routing Guideline with the current topology and provides a detailed breakdown of:
- All destinations and routes, including the specific servers in the topology that match each rule.
- Routes that are currently defined, their match conditions, and the destinations they forward queries to.
- Unreferenced servers – nodes in the topology that are not included in any route.
Example:
mysqlsh-py> rg.show()
Routing Guideline: 'my_guideline'
ClusterSet: 'my_clusterset'
Routes
------
- rw
+ Match: "$.session.targetPort = $.router.port.rw"
+ Destinations:
* domus:5000 (Primary)
- ro
+ Match: "$.session.targetPort = $.router.port.ro"
+ Destinations:
* domus:5001, domus:5002 (PrimaryClusterSecondary)
* domus:5000 (Primary)
Destination Classes
-------------------
- Primary:
+ Match: "$.server.memberRole = PRIMARY AND ($.server.clusterRole = PRIMARY OR $.server.clusterRole = UNDEFINED)"
+ Instances:
* domus:5000
- PrimaryClusterSecondary:
+ Match: "$.server.memberRole = SECONDARY AND ($.server.clusterRole = PRIMARY OR $.server.clusterRole = UNDEFINED)"
+ Instances:
* domus:5001
* domus:5002
- PrimaryClusterReadReplica:
+ Match: "$.server.memberRole = READ_REPLICA AND ($.server.clusterRole = PRIMARY OR $.server.clusterRole = UNDEFINED)"
+ Instances:
* domus:5100
* domus:5200
Unreferenced servers
--------------------
- domus:6000
- domus:6001
- domus:6002
- domus:6100
- domus:6200
Modifying a Routing Guideline
Once a Routing Guideline is created, it can be modified to better suit specific application needs.
The AdminAPI provides commands to:
- Add or remove destinations
- Define new routes
- Update existing routes
- Reconfigure routing strategies
Let’s go through these modifications step by step.
Wait… Unreferenced servers?
Did you notice? There are several unreferenced servers!
These are servers that belong to the Replica Cluster and its Read-Replicas, but they aren’t included in the default Routing Guideline so will remain unused until the topology changes.
Why?
By default, MySQL Router uses the Primary Cluster as its target_cluster, meaning that only Primary Cluster members are considered unless explicitly configured otherwise.
The following diagram illustrates the topology and the Router’s routing behavior.
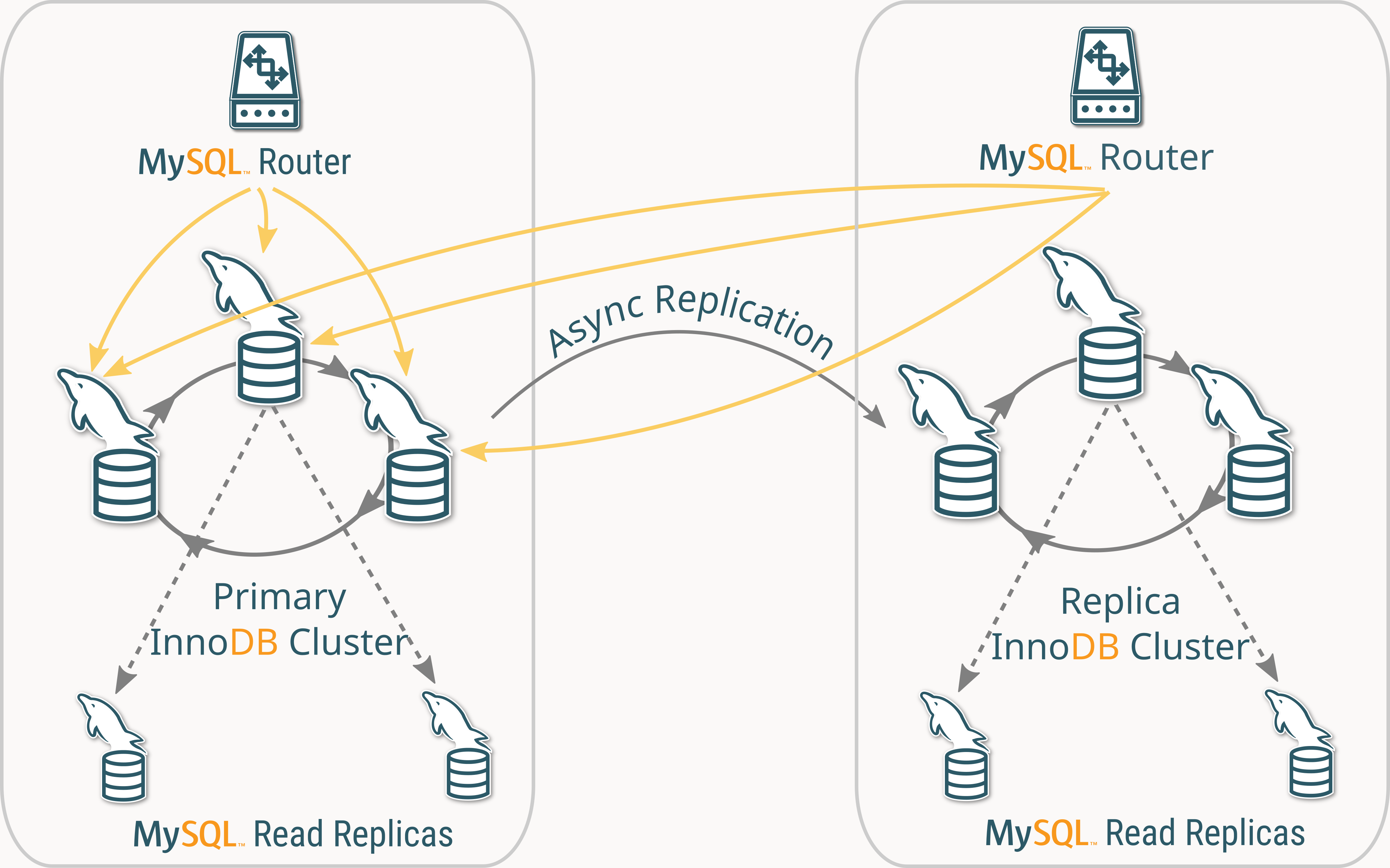
So what if we want to include Replica Clusters in the routing logic? Or fine-tune routing behavior to improve query distribution?
Let’s start by adding new destinations!
Adding Destinations
To expand the Routing Guideline, we need to define new destinations: groups of servers that queries can be routed to based on specific conditions.
To add destinations use:
<RoutingGuideline>.add_destination(name, match[, options])
So let’s add destinations for Replica Cluster nodes and a dedicated backup server group from Secondaries in the Primary Cluster.
Example:
mysqlsh-py> rg.add_destination("ReplicaClusterPrimary", "$.server.memberRole = PRIMARY AND $.server.clusterRole = REPLICA AND $.server.clusterName = 'replica_cluster'")
Destination 'ReplicaClusterPrimary' successfully added.
mysqlsh-py> rg.add_destination("ReplicaClusterSecondary", "$.server.memberRole = SECONDARY AND $.server.clusterRole = REPLICA AND $.server.clusterName = 'replica_cluster'")
Destination 'ReplicaClusterSecondary' successfully added.
mysqlsh-py> rg.add_destination("ReplicaClusterReadReplica", "$.server.memberRole = READ_REPLICA AND $.server.clusterRole = REPLICA AND $.server.clusterName = 'replica_cluster'")
Destination 'ReplicaClusterReadReplica' successfully added.
mysqlsh-py> rg.add_destination("Backups", "$.server.memberRole = SECONDARY AND $.server.clusterRole = PRIMARY AND $.server.version = 90200")
Destination 'Backups' successfully added.
What happens here?
"ReplicaClusterPrimary"includes Primary servers from the Replica Cluster."ReplicaClusterSecondary"includes Secondary servers from the Replica Cluster."ReplicaClusterReadReplica"includes Read-Replica servers from the Replica Cluster."Backups"includes specific Secondary servers in the Primary Cluster running MySQL 9.2.0, designated for backup operations.
Now that we’ve defined these new destinations, we can create routes that take advantage of them.
Adding Routes
We’ve expanded our Routing Guideline with new destinations, the next step is to create routes that determine how queries should be directed to these destinations.
Each route consists of:
- A match condition – Defines when the route applies.
- Destinations – Specifies where the queries should be routed.
- Routing strategy – Determines how destinations are selected.
- Additional options – Controls behavior like connection sharing.
To add routes use:
<RoutingGuideline>.add_route(name, match, destinations, options)
Example:
mysqlsh-py> rg.add_route(
"ro_traffic",
"$.session.targetPort = $.router.port.ro",
[
"round-robin(ReplicaClusterSecondary, ReplicaClusterReadReplica)",
"round-robin(ReplicaClusterPrimary)",
"round-robin(PrimaryClusterReadReplica)",
"round-robin(PrimaryClusterSecondary)",
"round-robin(Primary)"
],
{"connectionSharingAllowed": True, "enabled": True}
)
Route 'ro_traffic' successfully added.
mysqlsh-py> rg.add_route(
"backup_traffic",
"$.session.connectAttrs.program_name = 'mysqldump'",
["first-available(Backups)"],
{"connectionSharingAllowed": True, "enabled": True}
)
Route 'backup_traffic' successfully added.
What happens here?
ro_trafficRoute- Matches read-only traffic (
$.router.port.ro). - Prefers Replica Cluster Secondaries and Read Replicas, distributing queries using round-robin.
- Falls back to Replica Cluster Primary, then Primary Cluster Secondaries, and finally Primary servers.
- Enables connection sharing, allowing sessions to reuse existing connections when possible.
- Matches read-only traffic (
backup_trafficRoute- Matches connections from mysqldump (
$.session.connectAttrs.program_name = 'mysqldump'). - Routes queries exclusively to backup-designated servers (
Backupsdestination). - Uses first-available strategy to select the first available backup server.
- Matches connections from mysqldump (
Let’s review it?
Once the new routes and destinations are added, we can check the updated Routing Guideline:
Example:
mysqlsh-py> rg.show()
Routing Guideline: 'my_guideline'
ClusterSet: 'my_clusterset'
Routes
------
- rw
+ Match: "$.session.targetPort = $.router.port.rw"
+ Destinations:
* domus:5000 (Primary)
- ro
+ Match: "$.session.targetPort = $.router.port.ro"
+ Destinations:
* domus:5001, domus:5002 (PrimaryClusterSecondary)
* domus:5000 (Primary)
- ro_traffic
+ Match: "$.session.targetPort = $.router.port.ro"
+ Destinations:
* domus:6001, domus:6002 (ReplicaClusterSecondary)
* domus:6100, domus:6200 (ReplicaClusterReadReplica)
* domus:6000 (ReplicaClusterPrimary)
* domus:5100, domus:5200 (PrimaryClusterReadReplica)
* domus:5001, domus:5002 (PrimaryClusterSecondary)
* domus:5000 (Primary)
- backup_traffic
+ Match: "$.session.connectAttrs.program_name = 'mysqldump'"
+ Destinations:
* domus:5001, domus:5002 (Backups)
Destination Classes
-------------------
- Primary:
+ Match: "$.server.memberRole = PRIMARY AND ($.server.clusterRole = PRIMARY OR $.server.clusterRole = UNDEFINED)"
+ Instances:
* domus:5000
- PrimaryClusterSecondary:
+ Match: "$.server.memberRole = SECONDARY AND ($.server.clusterRole = PRIMARY OR $.server.clusterRole = UNDEFINED)"
+ Instances:
* domus:5001
* domus:5002
- PrimaryClusterReadReplica:
+ Match: "$.server.memberRole = READ_REPLICA AND ($.server.clusterRole = PRIMARY OR $.server.clusterRole = UNDEFINED)"
+ Instances:
* domus:5100
* domus:5200
- ReplicaClusterPrimary:
+ Match: "$.server.memberRole = PRIMARY AND $.server.clusterRole = REPLICA AND $.server.clusterName = 'replica_cluster'"
+ Instances:
* domus:6000
- ReplicaClusterSecondary:
+ Match: "$.server.memberRole = SECONDARY AND $.server.clusterRole = REPLICA AND $.server.clusterName = 'replica_cluster'"
+ Instances:
* domus:6001
* domus:6002
- ReplicaClusterReadReplica:
+ Match: "$.server.memberRole = READ_REPLICA AND $.server.clusterRole = REPLICA AND $.server.clusterName = 'replica_cluster'"
+ Instances:
* domus:6100
* domus:6200
- Backups:
+ Match: "$.server.memberRole = SECONDARY AND $.server.clusterRole = PRIMARY AND $.server.version = 90200"
+ Instances:
* domus:5001
* domus:5002
Unreferenced servers
--------------------
- None
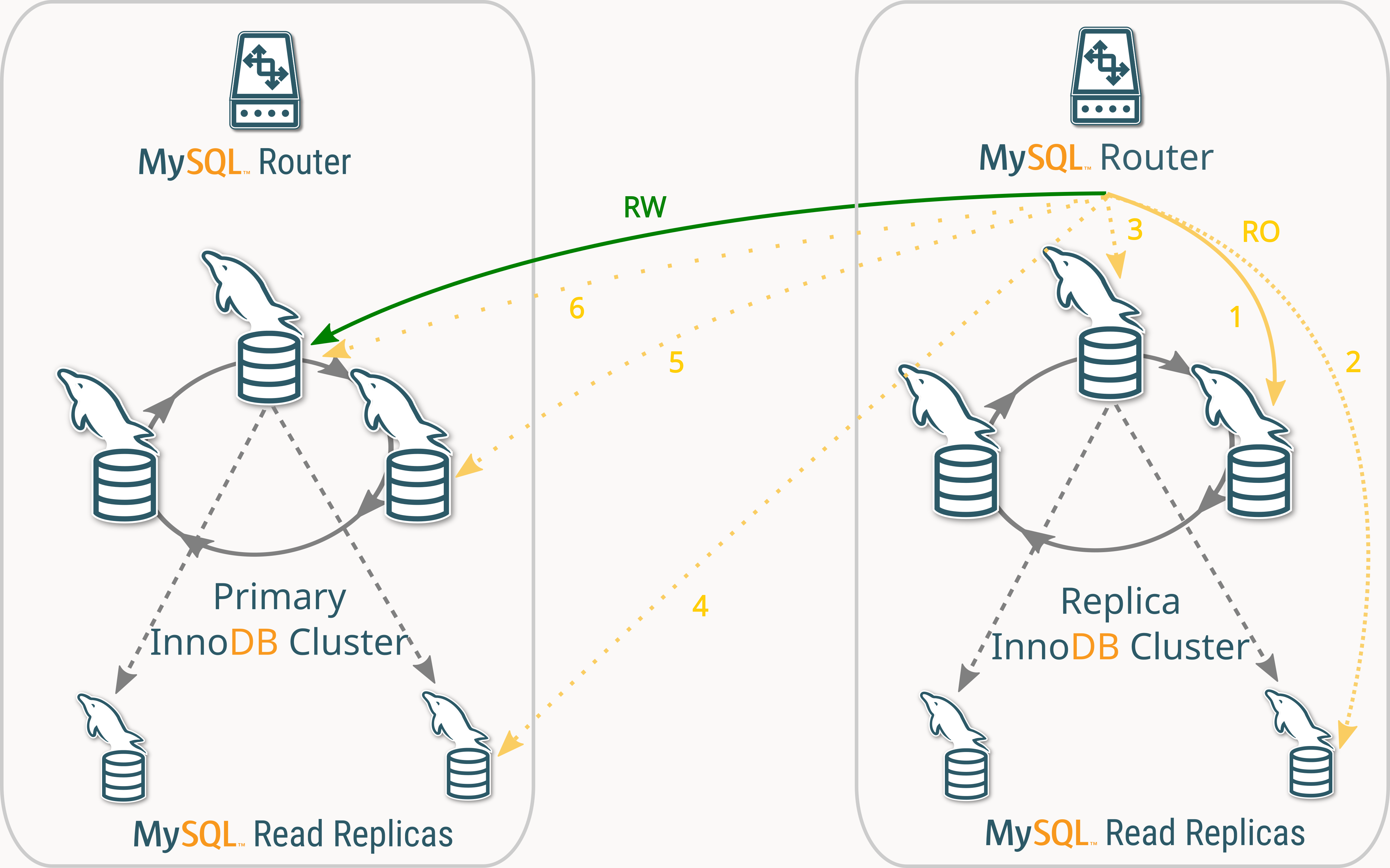
The following diagram illustrates how MySQL Router directs queries based on the defined Routing Guideline.
Read-Write (RW) Traffic
- All RW queries are always sent to the Primary member of the Primary Cluster (
rwroute).
Read-Only (RO) Traffic
RO queries are routed according to the following priority order (ro route):
- Round-robin across the Secondary members of the Replica Cluster (
ReplicaClusterSecondary). - (If none are available) Round-robin across the Read-Replicas of the Replica Cluster (
ReplicaClusterReadReplica). - (If none are available) Use the Primary member of the Replica Cluster (
ReplicaClusterPrimary). - (If none are available) Round-robin across the Read-Replicas of the Primary Cluster (
PrimaryClusterReadReplica). - (If none are available) Round-robin across the Secondary members of the Primary Cluster (
PrimaryClusterSecondary). - (If none are available) Use the Primary member of the Primary Cluster (
Primary).
This setup optimizes read traffic by prioritizing replicas first while ensuring queries always have a fallback option if preferred destinations are unavailable.
Removing Routes and Destinations
As the Routing Guideline evolves, some routes or destinations may no longer be needed. AdminAPI allows us to remove these elements dynamically, ensuring that only the necessary routing rules remain in place.
If a route is no longer required, we can remove it using:
<RoutingGuideline>.remove_route(name)
Example:
mysqlsh-py> rg.remove_route("ro")
Route successfully removed.
Handling Dependencies When Removing Destinations
Consider an illustrative scenario where the Read-Replicas originally part of the Primary Cluster have been moved to the Replica Cluster.
In this case, since these Read-Replicas no longer belong to the Primary Cluster, the destination PrimaryClusterReadReplica becomes irrelevant and should be removed.
To remove a destination that’s no longer required, use the following:
<RoutingGuideline>.remove_destination(name)
Example:
mysqlsh-py> rg.remove_destination("PrimaryClusterReadReplica")
ERROR: Destination 'PrimaryClusterReadReplica' is in use by route(s): ro_traffic
Traceback (most recent call last):
File "<string>", line 1, in <module>
ValueError: Destination in use by one or more Routes
Error? Why is this happening?
- The
ro_trafficroute still referencesPrimaryClusterReadReplicaas a valid destination. - AdminAPI prevents its removal to avoid breaking the Routing Guideline.
Updating Routes and Destinations
To resolve this, we need to update ro_traffic so it no longer references PrimaryClusterReadReplica.
To update a route use:
<RoutingGuideline>.set_route_option(routeName, option, value)
Where option is one of the following:
- match (string): The client connection matching rule.
- destinations (string): A list of destinations using routing strategies in the format `strategy(destination1, destination2, …)`, ordered by priority, highest to lowest
- enabled (boolean): Set to true to enable the route, or false to disable it.
- connectionSharingAllowed (boolean): Set to true to enable connection sharing, or false to disable it.
- order (uinteger): Specifies the position of a route within the Routing Guideline (lower values indicate higher priority).
Example:
mysqlsh-py> rg.set_route_option("ro_traffic", "destinations", [
"round-robin(ReplicaClusterSecondary, ReplicaClusterReadReplica)",
"round-robin(ReplicaClusterPrimary)",
"round-robin(PrimaryClusterSecondary)",
"round-robin(Primary)"
])
Route 'ro_traffic' successfully updated.
In some cases, instead of removing a destination, it may be useful to update its match condition to reflect the new topology.
We can update a destination using:
<RoutingGuideline>.set_destination_option(destinationName, option, value)
Where option is, at the moment, only:
- match (string): The matching rule used to identify servers for this destination class.
Finalizing and Activating the Guideline
Now that the Routing Guideline looks good, it’s time to activate it in the topology so MySQL Router starts using it.
But before making it active, it’s best practice to back up the current state of the guideline. The simplest and recommended approach is to create copies using .copy(). This method is quick, safe, and convenient.
Creating a Copy
Making copies of the guidelines allows us to easily experiment and revert changes if necessary. Instead of changing the active guideline directly, we can create a duplicate.
To create a duplicate, use:
<RoutingGuideline>.copy(name)
Example:
mysqlsh-py> rg.copy("my_guideline_v2")
Routing Guideline 'rg' successfully duplicated with new name 'my_guideline_v2'.
Why make a copy?
- Allows experimenting with new routing rules without affecting production traffic.
- Provides an easy rollback option – we can always revert to
my_guidelineif needed. - Allows comparing different versions side by side before making the final decision.
Exporting as JSON file
Alternatively, we can export the guideline to a JSON file. This method is useful for backing up externally or transferring guidelines between different environments or topologies.
To export a guideline use:
<RoutingGuideline>.export(file)
Example:
mysqlsh-py> rg.export("/home/miguel/rg_bak.json")
Routing Guideline 'rg' successfully exported to '/home/miguel/rg_bak.json'.
Why export it?
- Maintain backups externally or in version-controlled outside the current environment.
- Provides an additional safeguard alongside
.copy(). Allows restoring the guideline later if needed. - Easily transfer guidelines to other environments or topologies.
Activating the Routing Guideline
Once everything is set, we need to activate the Routing Guideline so MySQL Router can start using it.
Routing Guidelines can be applied globally to all MySQL Routers in the topology (default) or activated for a specific Router instance.
To activate a guideline use the guideline option in:
.set_routing_option([router], option, value)
Example:
mysqlsh-py> clusterset.set_routing_option("guideline", "my_guideline")
Routing option 'guideline' successfully updated.
Routing Guideline 'my_guideline' has been enabled and is now the active guideline for the topology.
What happens here?
- All MySQL Routers in the topology automatically detect the change.
- No restart is required – Routers apply the new guideline in real-time.
- Queries will now be routed according to
my_guideline‘s rules.
Example: activating a guideline for a specific router
If we want to activate a guideline only for a specific MySQL Router instance, we provide the Router identifier as the first argument:
mysqlsh-py> clusterset.set_routing_option("domus::my_router", "guideline", "my_guideline")
Routing option 'guideline' successfully updated in router 'domus::my_router'.
Listing the Existing Guidelines
To list all guidelines of the topology while also reviewing which one is active, use:
.routing_guidelines()
Example:
mysqlsh-py> clusterset.routing_guidelines()
+-----------------+--------+------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------+
| guideline | active | routes | destinations |
+-----------------+--------+------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------+
| my_guideline_v2 | 0 | rw,ro_traffic,backup_traffic | Primary,PrimaryClusterSecondary,PrimaryClusterReadReplica,ReplicaClusterPrimary,ReplicaClusterSecondary,ReplicaClusterReadReplica,Backups |
| my_guideline | 0 | rw,ro_traffic,backup_traffic | Primary,PrimaryClusterSecondary,PrimaryClusterReadReplica,ReplicaClusterPrimary,ReplicaClusterSecondary,ReplicaClusterReadReplica,Backups |
+-----------------+--------+------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.0000 sec)
Additional Operations
Importing / Restoring a Routing Guideline
If something goes wrong and we need to restore the previous Routing Guideline, we can import the backup.
To import a guideline from a .json file, use:
.import_routing_guideline(file[, options])
Example:
mysqlsh-py> clusterset.import_routing_guideline("/home/miguel/rg_bak.json")
NOTE: Routing Guideline 'my_guideline' is the guideline currently active in the 'ClusterSet'.
Routing Guideline 'my_guideline' successfully imported.
Retrieving a Routing Guideline
To retrieve a specific Routing Guideline to inspect and/or modify it, use:
.get_routing_guideline([name])
Example:
mysqlsh-py> rg = clusterset.get_routing_guideline("my_guideline")
Cleaning up Old Guidelines
If an older guideline is no longer needed, it can be removed. To remove guidelines use:
.remove_routing_guideline(name)
Example:
mysqlsh-py> clusterset.set_routing_option("guideline", "my_guideline_v2")
Routing option 'guideline' successfully updated.
Routing Guideline 'my_guideline_v2' has been enabled and is now the active guideline for the topology.
mysqlsh-py> clusterset.remove_routing_guideline("my_guideline")
Routing Guideline 'my_guideline' successfully removed.
Renaming a Guideline
If we want to rename a guideline for clarity or versioning purposes, we can use:
<RoutingGuideline>.rename(name)
Example:
mysqlsh-py> rg = clusterset.get_routing_guideline()
mysqlsh-py> rg.rename("guideline_production")
Successfully renamed Routing Guideline 'my_guideline_v2' to 'guideline_production'
Conclusion
With MySQL Shell’s AdminAPI, managing MySQL Routing Guidelines becomes a streamlined and efficient process, enabling dynamic and intelligent query routing without the need for manual MySQL Router reconfiguration.
In this post, we walked through the complete lifecycle of managing Routing Guidelines using AdminAPI – from creation and definition to modification, activation, versioning, and cleanup. When structured effectively, Routing Guidelines optimize performance, scalability, and database resilience across MySQL InnoDB Cluster, ClusterSet, and ReplicaSet environments.
Available in both MySQL Community and Enterprise editions, Routing Guidelines offer a powerful mechanism for controlling how queries are routed, ensuring efficient traffic flow based on workload demands. Whether you’re fine-tuning read distribution, isolating backups, or adapting to topology changes, AdminAPI provides dynamic, precise control over routing behavior.
But how does MySQL Router apply these rules under the hood? In the next post, we’ll explore:
- The internal mechanics of how Router processes and enforces routing rules.
- How MySQL Router dynamically applies changes in real time.
Stay tuned!
For more details, check out the official MySQL documentation, or get started with Routing Guidelines today using MySQL Shell and MySQL Router.
