With the recent performance enhancements we have made in MySQL and HeatWave there is increased interest in customers using MySQL for more complex queries and more complex workloads and here we are taking another step by improving the semi-join performance. In older versions of MySQL 8.0 we saw the potential for optimizing simple semi-join queries using the group by clause. When possible queries of the form SELECT DISTINCT … FROM t1 WHERE NOT IN(SELECT …) were transformed into an anti-join. However, after this transformation, the optimizer would not use group skip scan for table t1. This resulted in MySQL needing to perform a manual deduplication step later in the execution. In these cases, group skip scan was not chosen since the query was no longer a single table query following the anti-join transformation, and the group skip scan access method was only enabled for single table queries. The same behaviour was seen for queries which were transformed into a semi-join.
In MySQL 8.0.41, we enabled the group skip scan access method for queries using IN, NOT IN, EXIST and NOT EXIST provided the access method was used only for duplicate removal (that is, DISTINCT or GROUP BY without aggregate functions). This change saved both IO and CPU processing time needed to handle the query. Automatically enabled in the latest versions of MySQL, this feature dramatically improved performance as shown in the table data below. And with improved performance, comes a reduced cost and need for more hardware for on-premise customers.
In this blog we analyze two SQL queries covering both semi-join and anti-join transformations that benefit from the new feature.
Performance Numbers
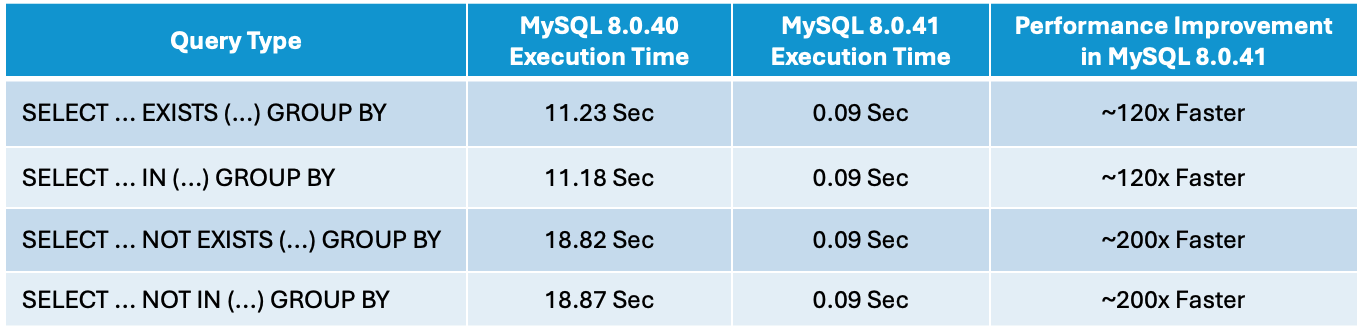
Note: Full SQL queries can be found in the Appendix.
Query Plan – Before and After
To better understand how this enhancement impacts performance, lets compare the explain plan of two SQL queries run on MySQL 8.0.40 where skip scan is not used and MySQL 8.0.41 where skip scan is used.
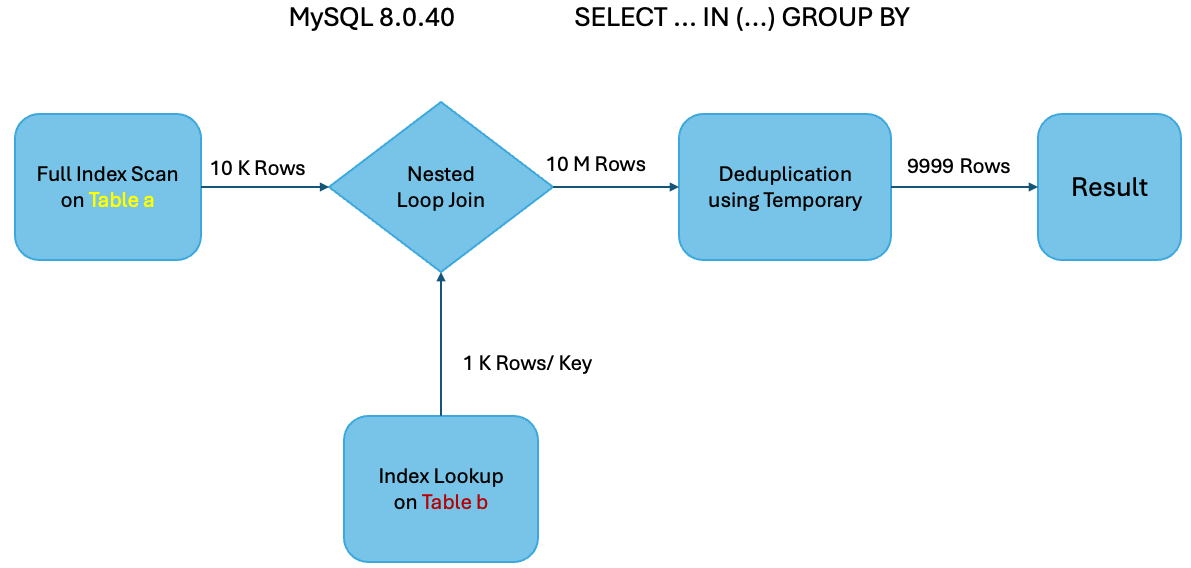
Example 1: EXPLAIN ANALYZE SELECT DISTINCT value FROM b WHERE value IN (SELECT value FROM a);
MySQL 8.0.40
-> Table scan on <temporary> (cost=2.25e+6..2.38e+6 rows=9.99e+6) (actual time=9819..9824 rows=9999 loops=1)
-> Temporary table with deduplication (cost=2.25e+6..2.25e+6 rows=9.99e+6) (actual time=9819..9819 rows=9999 loops=1)
-> Nested loop inner join (cost=1.25e+6 rows=9.99e+6) (actual time=0.109..6667 rows=10e+6 loops=1)
-> Covering index scan on a using ix_value_unique (cost=1019 rows=10000) (actual time=0.0727..3.9 rows=10000 loops=1)
-> Covering index lookup on b using ix_value (value=a.`value`) (cost=25.3 rows=999) (actual time=0.0184..0.347 rows=1001 loops=10000)
MySQL 8.0.41
-> Nested loop inner join (cost=20986 rows=10001) (actual time=0.0716..91.1 rows=9999 loops=1)
-> Covering index skip scan for deduplication on b using ix_value (cost=10380 rows=10001) (actual time=0.0482..67.9 rows=10000 loops=1)
-> Single-row covering index lookup on a using ix_value_unique (value=b.`value`) (cost=0.961 rows=1) (actual time=0.0013..0.00146 rows=1 loops=10000)
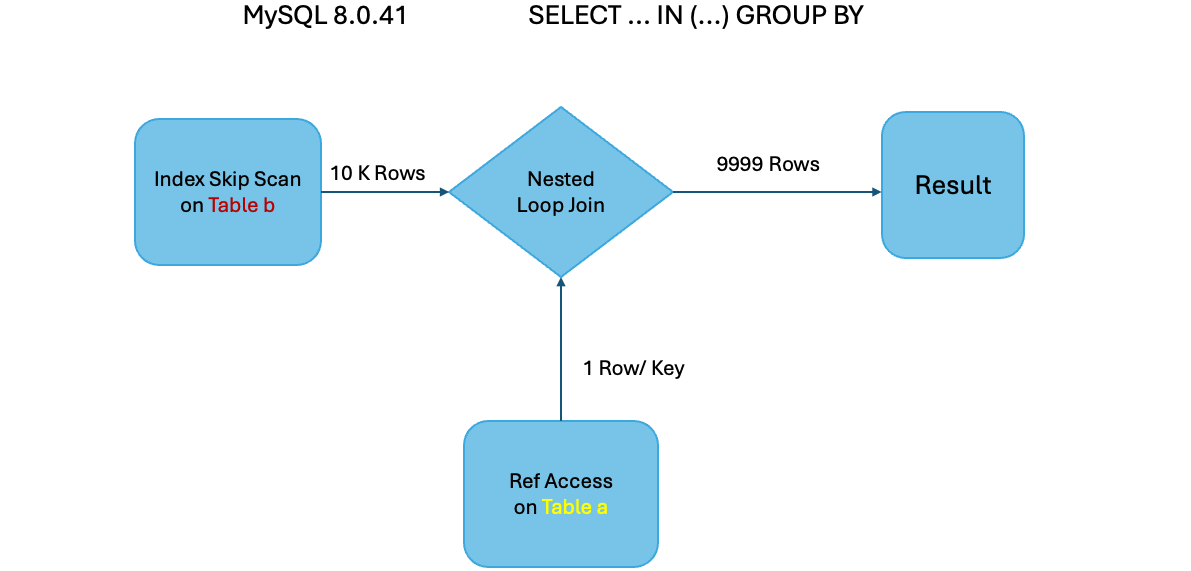
In this example, MySQL 8.0.40 does a full scan on table ‘a’ (with 10K rows) and joins with table ‘b’ (with 10M rows). For each row from table ‘a’, table ‘b’ has 999 matching rows. The resulting ~10M records from the join is further saved into a temporary table for deduplication. Meanwhile, MySQL 8.0.41 does an index skip scan on table ‘b’ (with 10M rows) which results in only reading 10K rows and joined with a single unique row from table a (with 10K rows). This results in 10K records and does not need a temporary table or deduplication as the deduplication has already happened during index skip scan.
Benefits of the new plan in MySQL 8.0.41:
- Avoided deduplication step.
- Avoided temporary table creation.
- Skipped reading 90% of rows from table ‘b’. A saving in both IO and processing time.
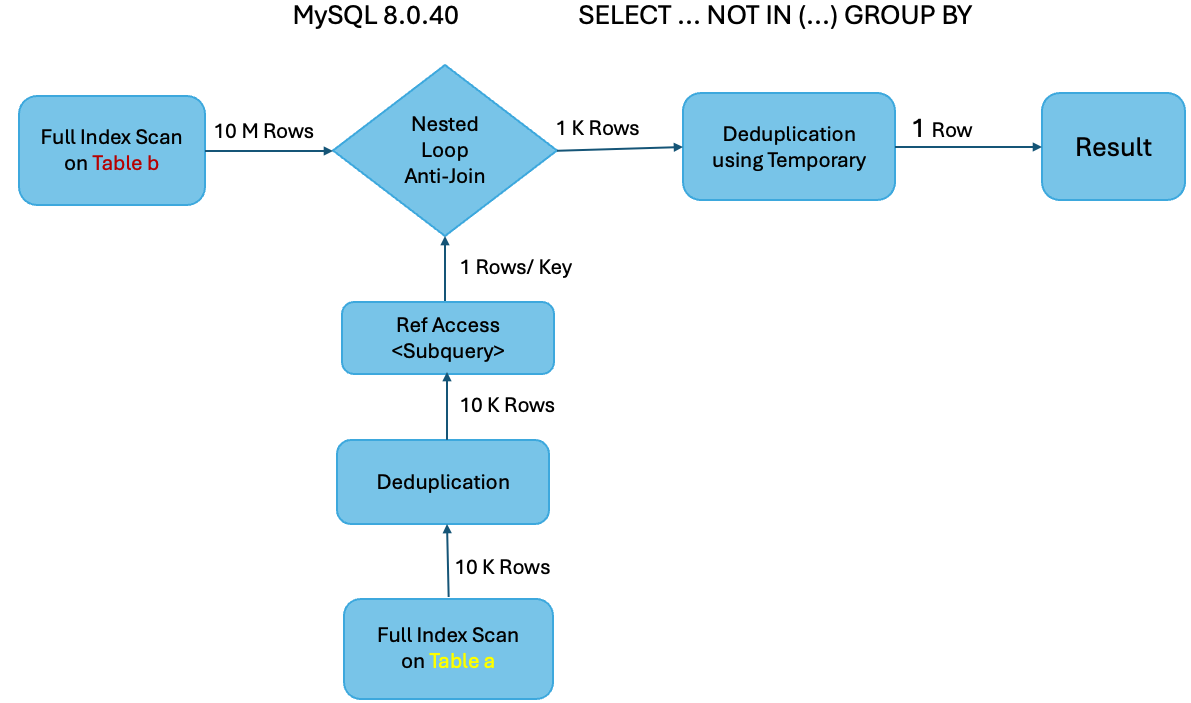
Example 2: EXPLAIN ANALYZE SELECT DISTINCT value FROM b WHERE value NOT IN (SELECT value FROM a);
MySQL 8.0.40
-> Table scan on <temporary> (cost=20e+9..21.2e+9 rows=99.9e+9) (actual time=18455..18455 rows=1 loops=1)
-> Temporary table with deduplication (cost=20e+9..20e+9 rows=99.9e+9) (actual time=18455..18455 rows=1 loops=1)
-> Nested loop antijoin (cost=9.99e+9 rows=99.9e+9) (actual time=10.4..18455 rows=1001 loops=1)
-> Covering index scan on b using ix_value (cost=1.02e+6 rows=9.99e+6) (actual time=0.0523..3264 rows=10e+6 loops=1)
-> Single-row index lookup on <subquery2> using <auto_distinct_key> (value=b.`value`) (cost=2119..2119 rows=1) (actual time=0.00104..0.00104 rows=1 loops=10e+6)
-> Materialize with deduplication (cost=2019..2019 rows=10000) (actual time=10.4..10.4 rows=10000 loops=1)
-> Filter: (a.`value` is not null) (cost=1019 rows=10000) (actual time=0.0365..6.38 rows=10000 loops=1)
-> Covering index scan on a using ix_value_unique (cost=1019 rows=10000) (actual time=0.0356..3.15 rows=10000 loops=1)\n'
MySQL 8.0.41
-> Nested loop antijoin (cost=10e+6 rows=100e+6) (actual time=9.9..265 rows=1 loops=1)
-> Covering index skip scan for deduplication on b using ix_value (cost=10834 rows=10001) (actual time=0.0523..235 rows=10000 loops=1)
-> Single-row index lookup on <subquery2> using <auto_distinct_key> (value=b.`value`) (cost=2019..2019 rows=1) (actual time=0.00242..0.00242 rows=1 loops=10000)
-> Materialize with deduplication (cost=2019..2019 rows=10000) (actual time=9.83..9.83 rows=10000 loops=1)
-> Filter: (a.`value` is not null) (cost=1019 rows=10000) (actual time=0.0406..5.94 rows=10000 loops=1)
-> Covering index scan on a using ix_value_unique (cost=1019 rows=10000) (actual time=0.039..2.67 rows=10000 loops=1)\n'
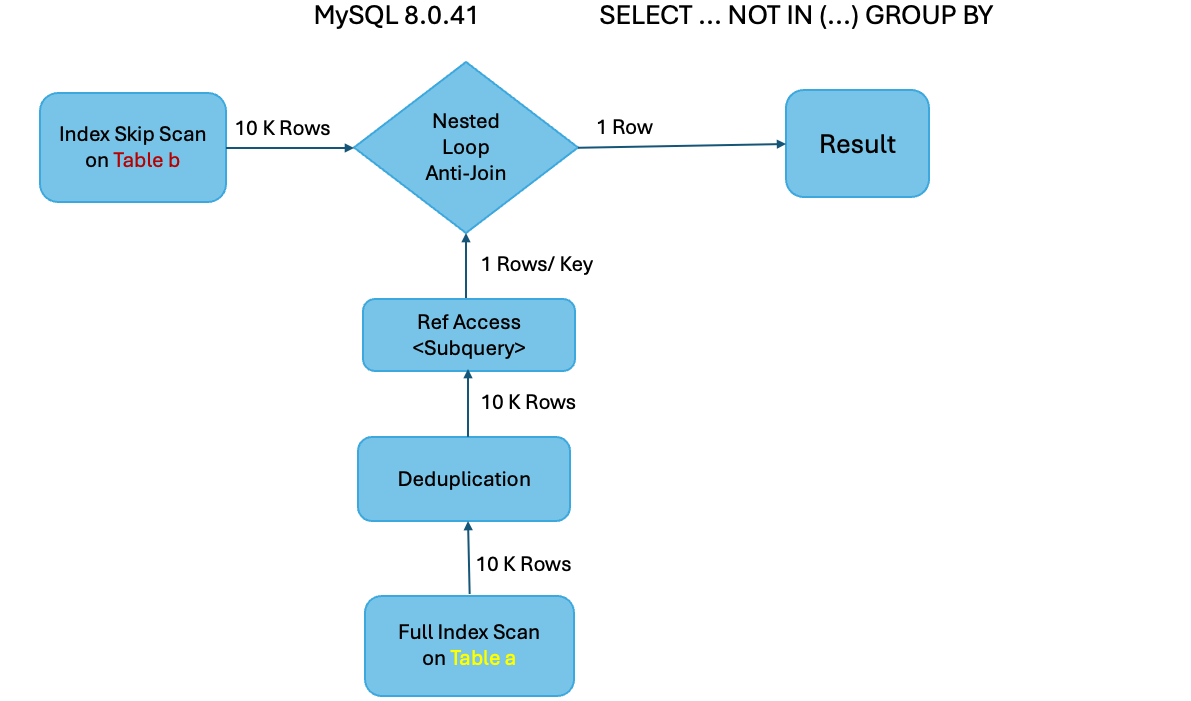
In this example, MySQL 8.0.40 does a full scan on table ‘b’ (with 10M rows) and joins with a single row from the subquery (with 10K rows) result set. The resulting 10K rows are then deduplicated to get the final 1 row. MySQL 8.0.41, on the other hand, does an index range scan on table ‘b’ (with 10M rows) and skips reading duplicate entries which results in reading only 10K rows instead of the 10M done by MySQL 8.0.40. Due to duplicate elimination already done at table scan time, the anti-join will produce just 1 result row avoiding the use of a temporary table and deduplication.
Benefits of the new plan in MySQL 8.0.41:
- Avoided deduplication step.
- Avoided temporary table creation.
- Skipped reading 90% of rows from table ‘b’. A saving in both IO and processing time.
This shows that both example 1 and 2 similarly benefit from the new feature.
Limitations
This optimization is not enabled when aggregates such as MIN(), MAX() are present in the query. As you can observe in the query plan below, it does not use the skip scan when MAX() function is present in the select list.
mysql> EXPLAIN FORMAT=TREE SELECT value, MAX(b_id) FROM b WHERE value IN (SELECT value FROM a) GROUP BY value;
-> Table scan on <temporary>
-> Aggregate using temporary table
-> Nested loop inner join (cost=356066 rows=2.46e+6)
-> Index scan on a using ix_value_unique (cost=1098 rows=10036)
-> Covering index lookup on b using ix_value (value=a.`value`) (cost=10.9 rows=245)
Conclusion
Customers using the latest MySQL versions, including 8.0.41+, 8.4.4+ and 9.2+, can benefit from improved performance on multi-table queries that are transformed into semi-joins or anti-joins internally. By utilizing group skip scan table access method on the primary table, the number of rows needed to generate the result set are greatly reduced. This saves both IO and CPU processing time with query performance being the clear winner. Improved performance also means for on-premise customers a reduced cost and need for extra hardware. With no new settings or flags introduced as part of this feature, customers will automatically reap the benefits.
We are already seeing increased adoptions of MySQL and Heatwave for complex workloads and complex query analytics. Semi-join is a very important operation that is used in many applications and now we have significantly improved its performance so try more complex queries in both MySQL and HeatWave.
Please let us know your thoughts and Thank You for using MySQL!
Appendix
Hardware Configuration
Memory: 377 GB
CPU: Intel(R) Xeon(R) Platinum 8358 CPU @ 2.60GHz
MySQL Server Configuration
Default server configuration for MySQL 8.0.40 is used with both MySQL 8.0.40 and MySQL 8.0.41.
Queries used for the performance data
SELECT DISTINCT value FROM b WHERE value NOT IN (SELECT value FROM a);
SELECT DISTINCT value FROM b WHERE value IN (SELECT value FROM a);
SELECT value FROM b WHERE EXISTS (SELECT value FROM a WHERE a.value = b.value) GROUP BY value;
SELECT DISTINCT value FROM b WHERE NOT EXISTS (SELECT value FROM a WHERE a.value = b.value);
Test Schema & Data
Our sample data consists of 10,000 rows in table a, and 10,000,000 rows in table b.
CREATE TABLE a
(
a_id INTEGER NOT NULL PRIMARY KEY AUTO_INCREMENT,
value VARCHAR(100) NOT NULL COLLATE utf8mb4_bin,
UNIQUE KEY ix_value_unique (value)
);
CREATE TABLE b
(
b_id INTEGER NOT NULL PRIMARY KEY AUTO_INCREMENT,
value VARCHAR(100) NOT NULL COLLATE utf8mb4_bin,
KEY ix_value (VALUE)
);
INSERT INTO a(value)
WITH RECURSIVE DataSource(num, val) AS (
SELECT 1, lpad(1,25,'0')
UNION ALL
SELECT num + 1, lpad(num+1, 25, '0')
FROM DataSource
WHERE num < 10000
)
SELECT val FROM DataSource;
INSERT INTO b(value)
WITH RECURSIVE DataSource(num, val) AS (
SELECT 1, lpad(1,25,'0')
UNION ALL
SELECT num + 1, lpad(mod(num+1,10000),25,'0')
FROM DataSource
WHERE num < 10000000
)
SELECT val FROM DataSource;
ANALYZE TABLE a,b;
Disclaimer: Actual observed improvements depend upon the specific user load, data, configuration, hardware, and operating system employed. This means that the improvements discussed here are specific to the setup used, and this may not correspond exactly to results observed elsewhere.
