We saw in this previous post how to import data from PostgreSQL to MySQL Database Service. Using almost the same technique, we will now import data from Amazon Redshift and import it to a MDS instance.
With Redshit we have two options to export the data to CSV files that can be imported to MDS:
- using Redshit’s UNLOAD
- using PostgreSQL’s output to local files
For this article we use the sample database that can be loaded into Redshift at the instance’s creation: tickit:
Redshift Unload
The first method we use is the recommended one in Redshift. However this method requires also a S3 bucket as UNLOAD only works with S3.
I’ve created a S3 bucket (redshiftdump), with an access point called mys3.
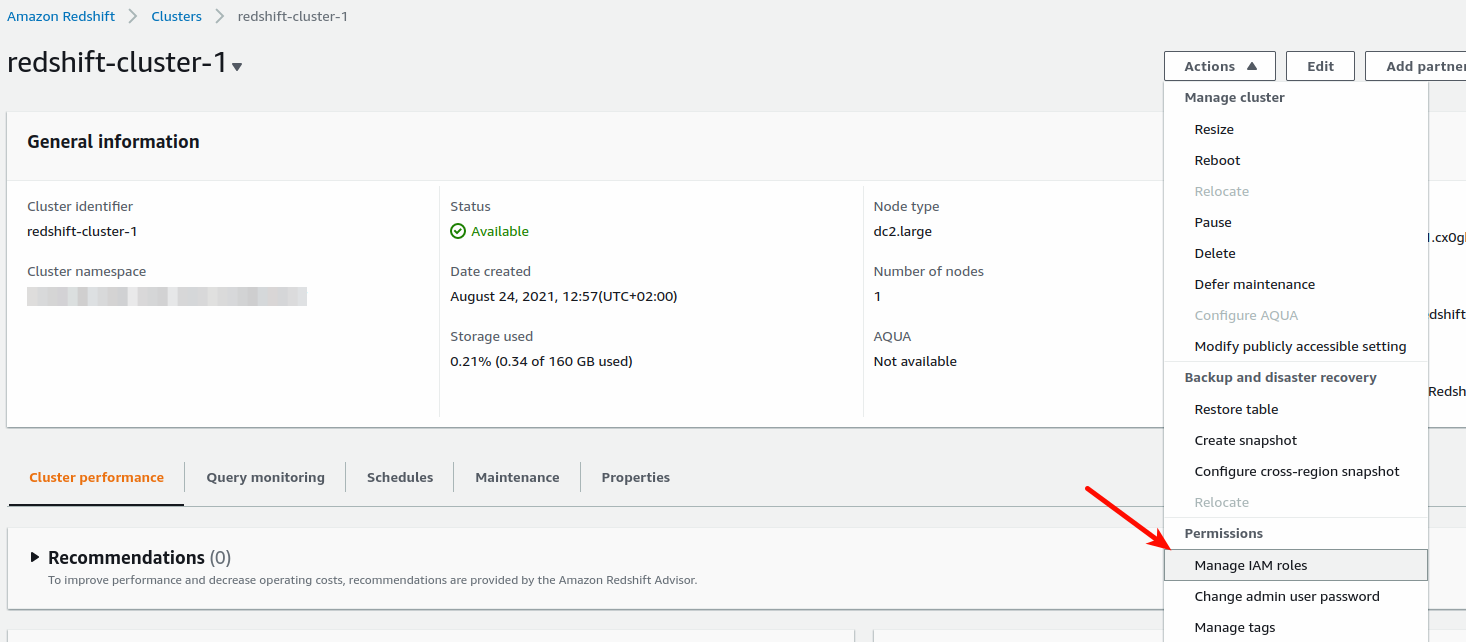
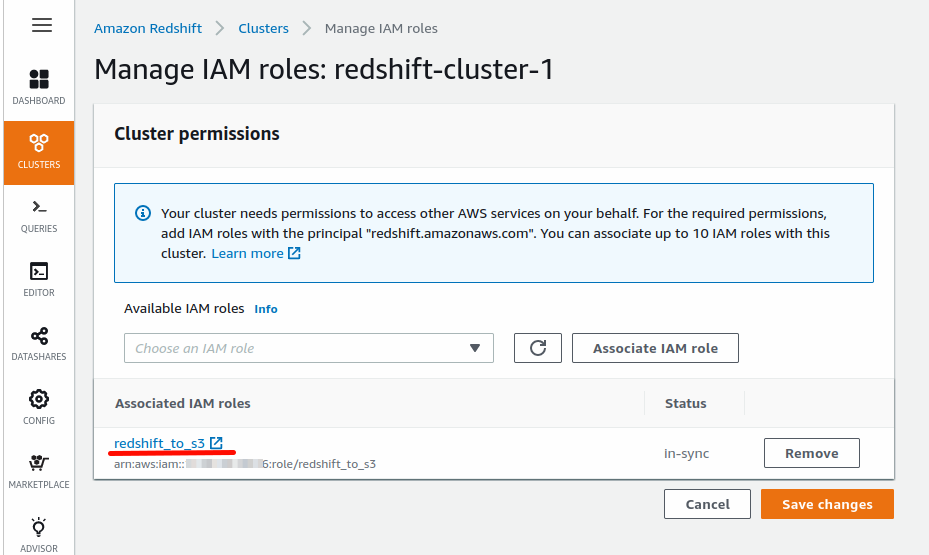
I also need to create a IAM Role (redshift_to_s3) that allows Read & Write access to my S3 bucket and finally I assigned that role also to the Redshift Cluster:
So now we can UNLOAD all the data using Query Editor:
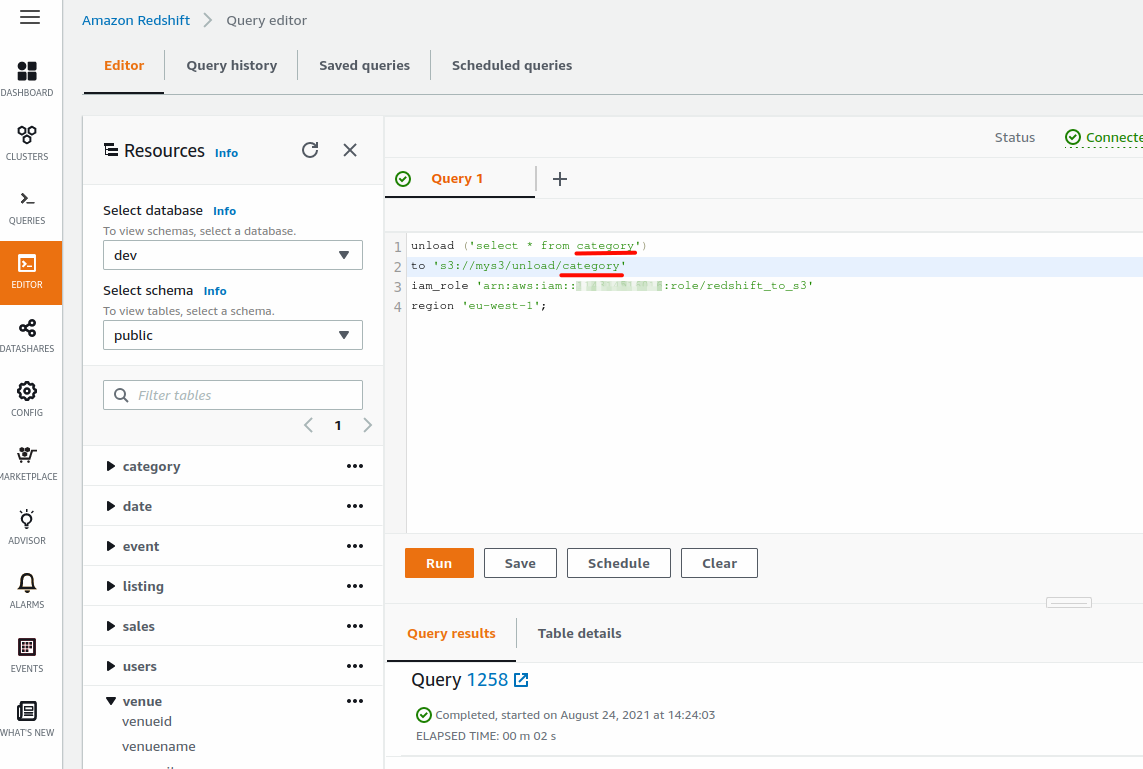
And we repeat the query for all tables we want to export.
Data Structure
Redshift is a fork of PostgreSQL and therefore, we will need to modify a little bit the tables definition to import the data to MySQL.
The definition of the tables in ticktit schema are available directly in the documentation:
create table category( catid smallint not null distkey sortkey, catgroup varchar(10), catname varchar(10), catdesc varchar(50));
This create statement must be modified, we will only change the primary key, so the statement becomes:
create table category( catid smallint not null auto_increment primary key, catgroup varchar(10), catname varchar(10), catdesc varchar(50));
And we do the same for all tables we want to load into MySQL.
It’s recommended to change the integer as primary key to integer unsigned as we won’t use negative values. So for the table users, this field:
userid integer not null distkey sortkey,
becomes
userid integer unsigned not null primary key,
Using S3 with our MySQL Shell compute instance
The data is on S3 but we need to import it on MDS. Usually to import data to a MySQL instance, we use MySQL Shell with importTable() utility.
The recommended way to use this utility with MDS is to use a dedicated compute instance. For large dataset, a large compute instance is recommended to benefit from multiple parallel threads.
It’s also possible to mount S3 as a filesystem on Linux using s3fs-fuse available in EPEL.
$ sudo yum install -y s3fs-fuse
We need first to create an access key. When you have your key, you need the Access Key ID and the Secret Access Key that you add in a file (you concatenate them with a colon ‘:‘‘), I called the file .paswd-s3fs:

Protect your file:
chmod 600 ~/.passwd-s3fs
In S3, we need to create an access point for our bucket:
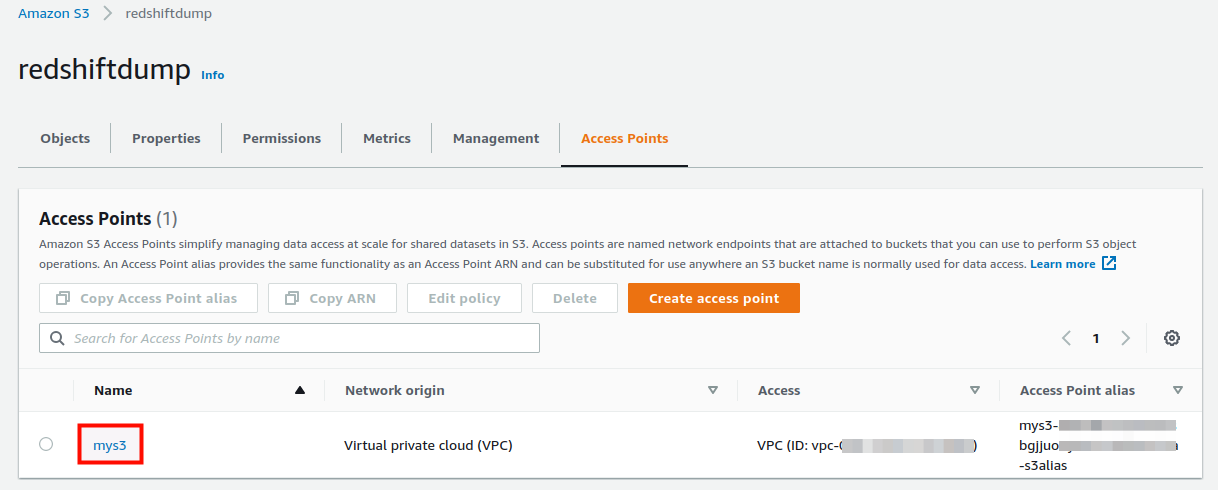
We use it now to mount our bucket and check if the files we have exported from Redshift are available:

Importing the Data
It’s time now to import the data using MySQL Shell, we start with the table category:
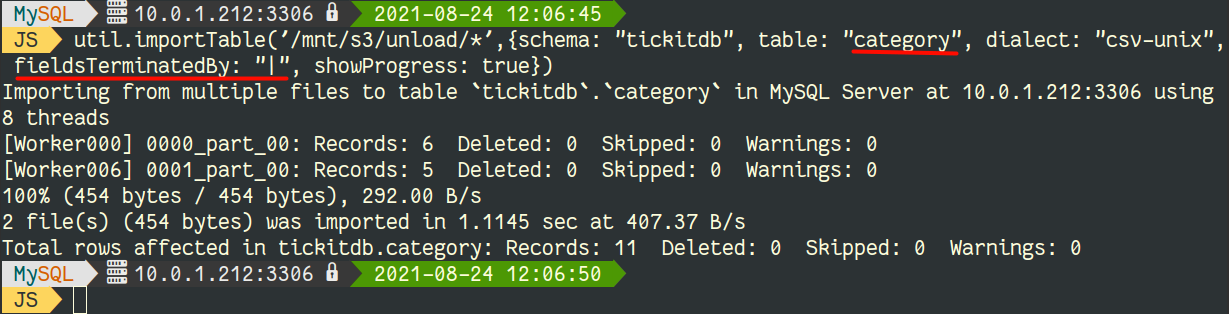
You can notice that fields are separated by ‘|’ when using UNLOAD.
And we can do exactly the same for all tables.
Now if don’t have S3 or we don’t want to mount it on OCI, we have the second option.
Export to local CSV
It’s also possible to connect to Redshift as a traditional PostgreSQL database as explained on this article.
As soon as you have everything ready in AWS (Internet Gateway, Security Group with Inbound Rule allowing Redshift traffic and a Routing Table routing 0.0.0.0/0 to the Internet Gateway), you can connect to Amazon Redshift even from our MySQL Shell Compute instance.
We install PostgreSQL client package:
sudo yum install -y postgresql12
And we can connect to our Redshit cluster and export the data to CSV files like this:
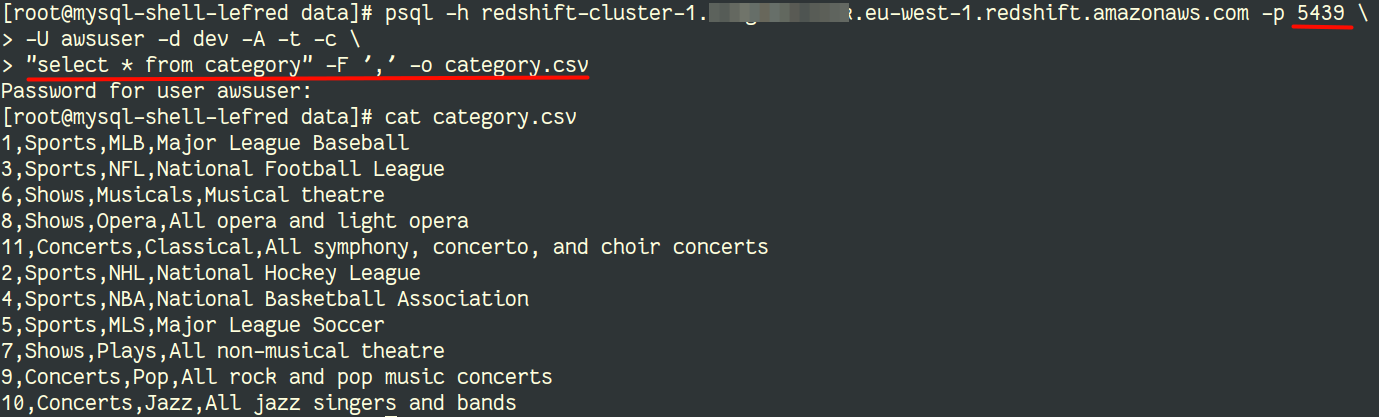
And now you can also import from MySQL Shell the data to the MDS instance the same way using importTable() utility.
Conclusion
Using an OCI Compute Instance with MySQL Shell is the best option to load data from PostgreSQL, Amazon Redshift, and other RDBMS directly to MySQL Database Service.
The import process is straightforward, the export process is a bit more trivial.
Enjoy MySQL and MDS !
