HeatWave scale-out, high performant similarity search
Enterprises are facing unprecedent challenges with the explosion of unstructured data such as documents in PDF and HTML formats. To analyze this vast amount of unstructured data for business operations, decision making and user experience, enterprises are turning to Generative AI advanced search techniques such as similarity search to extract meaningful insights and to drive innovation.
The need for similarity search
Traditional keyword-based searches often cannot deliver relevant results due to lack of context. For example, if you are looking for “esteemed scientists” you might not receive results about “Nobel prize winning physicists”, even though they are clearly relevant.
Advanced search techniques such as similarity or semantic search, bridge the gap by using machine learning to understand the context behind stored information. Such information is typically stored in vector store where data is converted into numerical representations called vector embeddings (vectors). Vectors capture the context of the data and relationships to other data. This data can be text, video, audio etc.
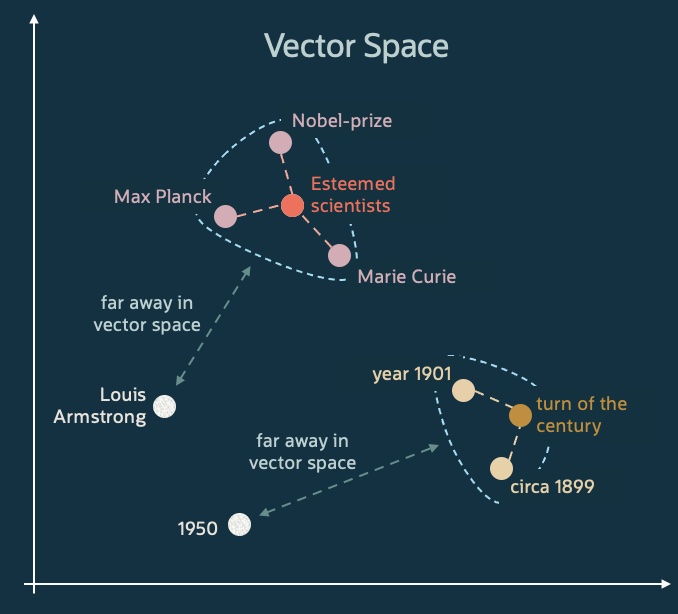
Vectors are points in a multi-dimensional vector space. Each point represents the vector embedding of the corresponding data. Data similar in semantic meaning are closer in vector space. Using the previous example, if user searches for “esteemed scientists”, similarity search will return relevant results such as “Nobel-prize”, “Marie Curie”, and “Max Planck”. This similarity in meaning is derived from the context of the data and is represented by small distances between the vector embeddings of these data.
Similarity search in HeatWave
HeatWave is an innovative, massively parallel, in-memory hybrid columnar processing engine that is architected for high scalability and performance for structured, semi-structured and unstructured data.
With HeatWave vector store, HeatWave in-database embedding generation and HeatWave processing engine, HeatWave provides a rich set of similarity search capabilities for building powerful and intelligent search applications across data lakes, databases, and vector stores.
To process unstructured data, HeatWave has introduced a native VECTOR data type which is used to store and manage vector embeddings. New vector distance functions are now supported which measure the similarity between vectors in a multi-dimensional space by calculating different types of mathematical distance between them. For example, Euclidean distance measures the straight-line distance between two vectors in a multi-dimensional space.
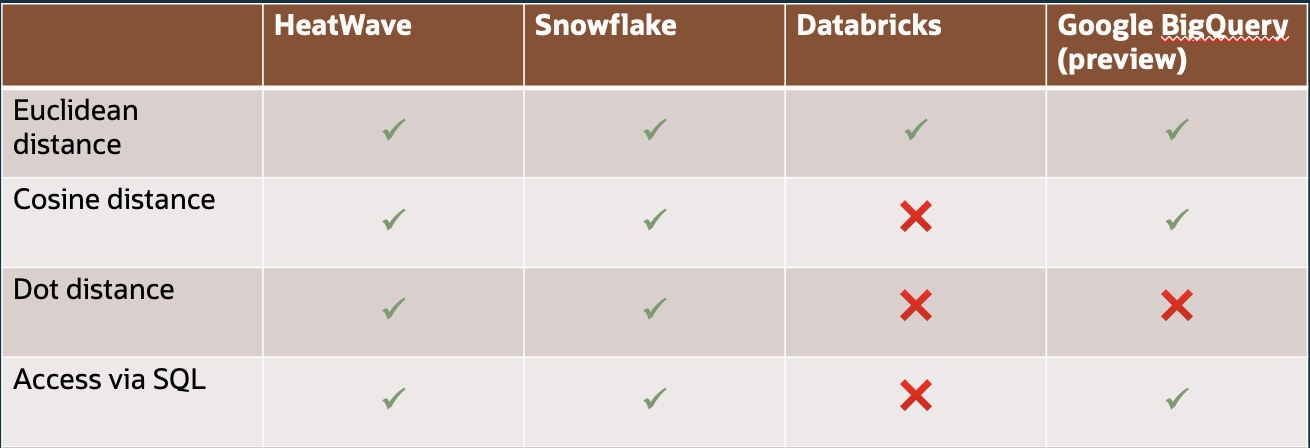
Predictable and exact answers
One of the advantages of HeatWave hybrid columnar engine is that it does not depend on indexes to achieve high performance for analytic query processing. The same applies for creating the embedding for the storage in vector store and processing similarity search. HeatWave performs full table scan for similarity search, which enables search results to be always predictable and exact.
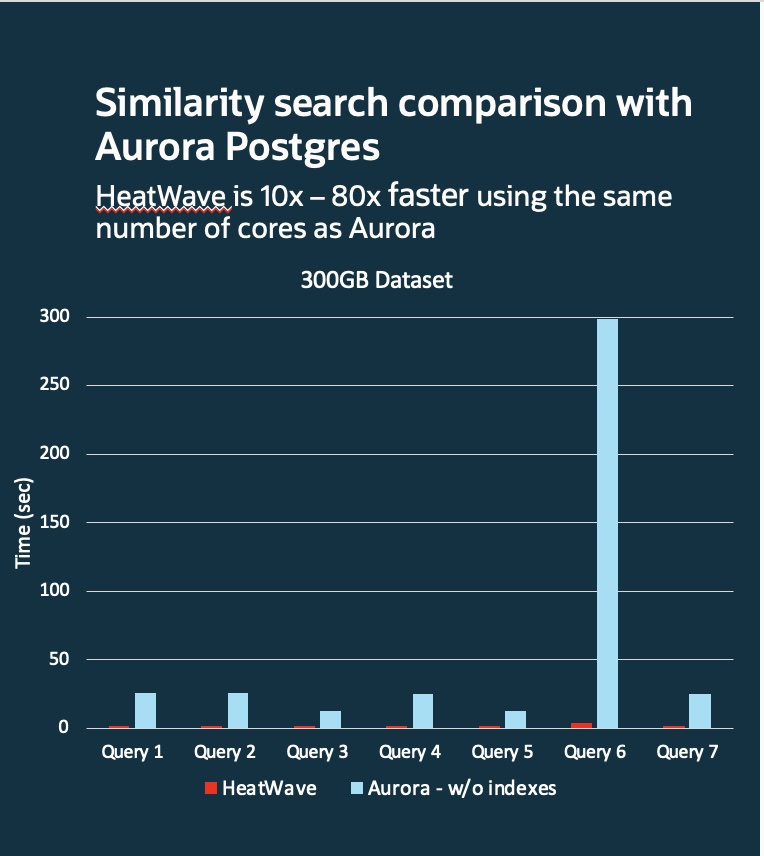
Other solutions such as Aurora Postgres require indexes to achieve better query performance, but search results are not guaranteed to be exact and performance can be unpredictable as indexes may not be applicable especially for complex queries.
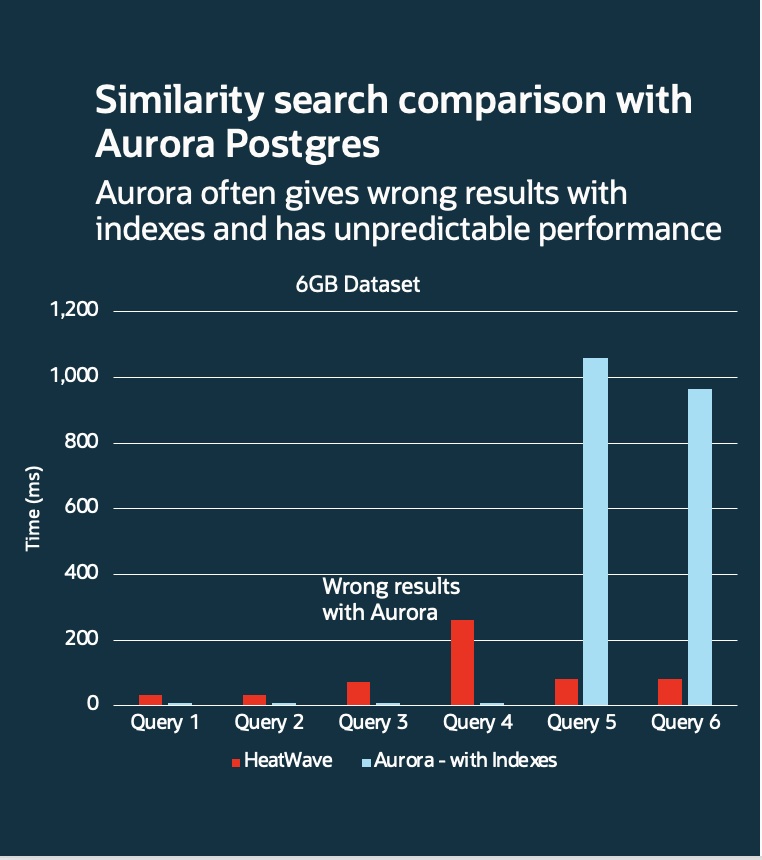
High Performance
Since vector embeddings are stored natively in HeatWave hybrid-columnar format, vectors and similarity search can be processed in HeatWave in-memory processing engine. This enables HeatWave to provide very good performance in near memory bandwidth processing in a single node.
Compared to Snowflake, Databricks, Google BigQuery and Aurora Postgres, HeatWave is much faster and provides the best price performance.
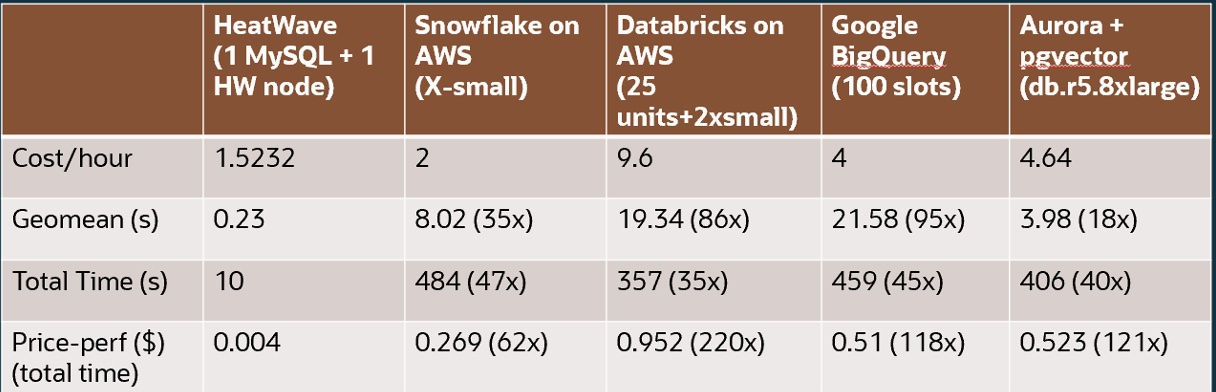
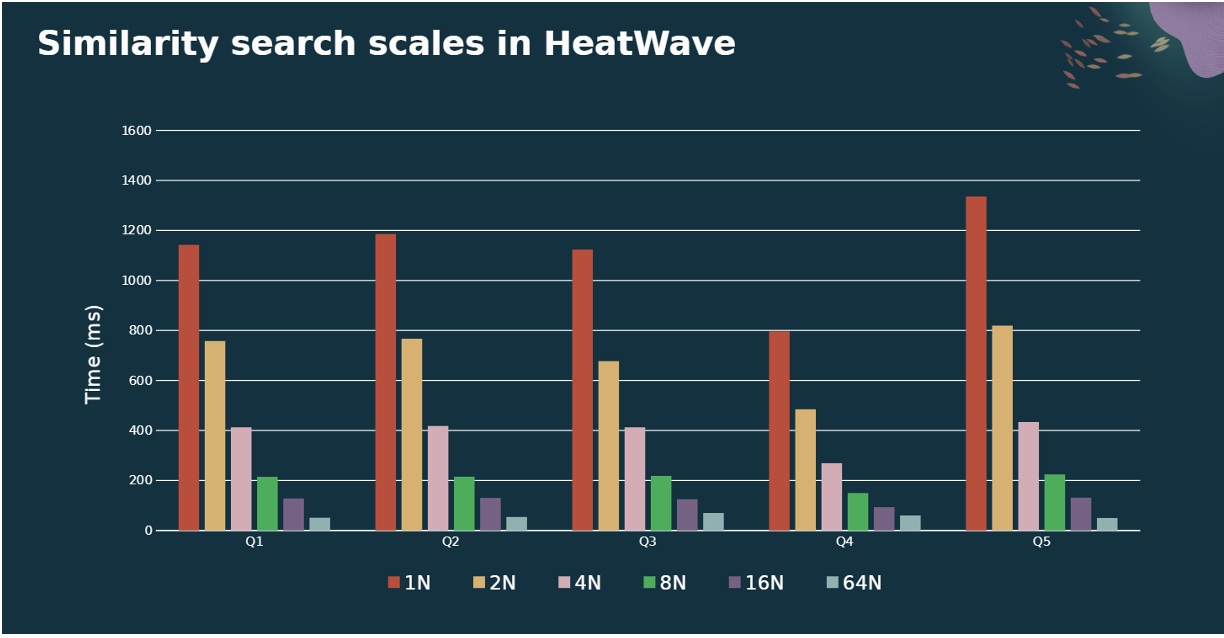
Highly scalable
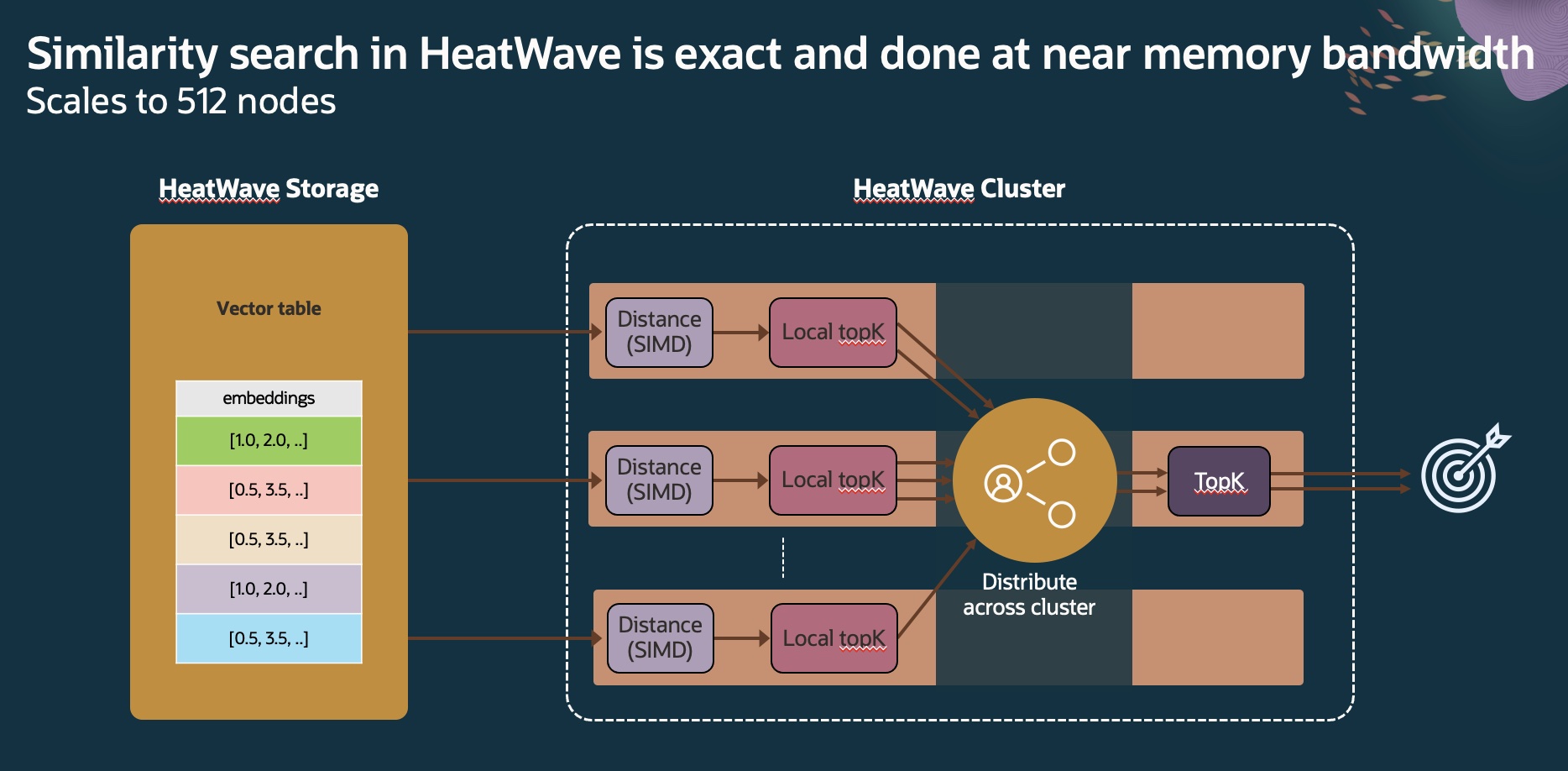
Not only does HeatWave performs similarity search really fast within a single node, it also scales well across nodes. Users can improve similarity search query performance by increasing the cluster size as shown below.
Query across structured, semi-structured data and vector store
The ability to ingest and transform unstructured data, such as PDF files, into structured relational formats is crucial for generating embeddings directly within the database. This enables advanced SQL querying on a mix of structured and unstructured data.
Consider a scenario where we have a repository of Wikipedia articles stored as PDFs in object store. These documents contain a wealth of information but are not immediately usable in native format for relational queries. With HeatWave vector store, these PDFs can be converted into embeddings that encapsulate the semantic essence of the content, then stored in relational tables as vectors. This process not only preserves the rich information in the articles but also transforms it into a format that can be queried alongside traditional relational data.
Now consider a user who maintains a relational database of user profiles within HeatWave. By leveraging HeatWave’s capabilities, the user can perform sophisticated queries that join the relational data from user profiles with the vector store data created from Wikipedia articles. For example, to recommend articles based on a user’s historical preferences, HeatWave can efficiently compute vector distances between user profile data and article embeddings, facilitating highly relevant recommendations. This helps to easily find correlations or insights that are not readily apparent when considering the data is from different data sources and formats.
By harnessing HeatWave’s unique capabilities, users can solve complex application problems that require the integration of diverse data formats.
Examples of HeatWave similarity search
For the examples below, it is assumed that the files from Wikipedia are loaded to HeatWave vector store to create embeddings.
Example 1: Find the 10 most similar articles in Wikipedia to the string “…” using the EUCLIDEAN distance function.
|
mysql> SELECT id, title FROM dbpedia ORDER BY DISTANCE(emb, ‘…’, ‘EUCLIDIAN’) LIMIT 10;
|
Example 2: Find the 10 closest similar articles in Wikipedia to the string “…” where the article text does not match the string pattern “Italian pronunciation:” using the EUCLIDEAN distance function. These types of queries are also very popular in recommender system applications, where recommendations are made after applying one or more filter clauses. HeatWave is highly efficient in executing such queries due to its hybrid columnar data layout and massively parallel architecture.
|
mysql> SELECT id, title FROM dbpedia WHERE text NOT LIKE ‘%Italian pronunciation:%’ ORDER BY DISTANCE(emb, ‘…’, ‘EUCLIDIAN’) LIMIT 10;
|
Example 3: Find Wikipedia articles where the articles are grouped by their titles, and the minimum distance from a user input string is computed for each group. This query involves a more complex aggregation function.
|
mysql> SELECT title, MIN(DISTANCE(emb, @qemb)) FROM dbpedia GROUP BY 1 ORDER BY 2 LIMIT 10;
|
Summary
HeatWave is revolutionizing how enterprises handle the explosion of unstructured data by leveraging its advanced, high-performance similarity search capabilities. By transforming unstructured data such as PDF and HTML documents into structured relational formats and integrating them with machine learning-generated vector embeddings, HeatWave provides advanced semantic search capabilities that are precise and context-aware. HeatWave’s innovative, massively parallel, in-memory hybrid columnar processing engine not only supports high scalability and performance across structured, semi-structured, and unstructured data but also ensures predictable and exact search results without relying on indexes. Comparatively faster and more cost-effective than solutions like Snowflake, Databricks, Google BigQuery, and Aurora Postgres, HeatWave provides an unmatched platform for sophisticated querying and integration of diverse data types, driving forward enterprise decision-making and innovation in the realm of Generative AI.

